自然语言处理系列六》中文分词》中文分词原理
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
文章目录
- 自然语言处理系列六
-
- 中文分词
-
- 中文分词原理
- 总结
自然语言处理系列六
中文分词
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文的词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比英文要复杂得多、困难得多。
中文分词原理
词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,中文分词不是以字为单位,而是以词为单位,在这种情况我们需要通过各种算法找到切分词的最佳分割标记,自然语言处理的基础步骤就是分词,分词的结果对中文信息处理至为关键。比如我们通过百度搜索关键词”陈敬雷分布式机器学习实战“,大家猜想一下中文分词的结果应该是什么结果呢?首先陈敬雷是我的人名,应该单独作为一个词,在中文分词里面有个原理,如果人名的会把人名识别出来,这个过程本身也叫作命名实体识别,在比如”陈敬雷分布式机器学习实战“,结果会自然的把充电了么这个公司名识别出来,这是公司名识别,也属于命名实体识别。命名实体识别我们在后面的章节中会详解讲到。这里给大家说的意思呢,就是中文分词如果发现句子中有人名,公司名等等类实体的时候会单独识别出词。然后接着”陈敬雷分布式机器学习实战“百度输入的关键词继续讲,分布式机器学习实战是我写的另外一本人工智能科学与技术丛书,书名也会识别出来,道理也是一样的。但是这个书名没有在词典库或者没有识别出来的话,会作为一个常规的分词,他可能会拆分为分布式、 机器、 学习、实战四个词,那么整体的分词结果就是陈敬雷、分布式、 机器、 学习、实战五个词了。另外如果我的名字陈敬雷如果没有识别出来,可能会拆分为单字陈、敬、雷,这样分词结果就是陈、敬、雷、分布式、 机器、 学习、实战七个词了。然后搜索引擎在所有文章中查找包含其中这些词的文章,那么搜索到的这些文章里,陈、敬、雷这三个字不一定挨着,是分散开的,分散开的文章就可能不是我的名字的相关文章,就是搜索结果不精准。同理分布式、 机器、 学习、实战这几个词在文章中也没有紧挨着,搜索结果也可能不是我写的书的相关文章。
那么如果是分成两个词陈敬雷、分布式机器学习实战,就会非常精准的搜索到相关文章,因为结果保证了陈敬雷和分布式机器学习实战这些字是紧挨着的。可见中文分词的结果对搜索引擎检索准确率的重要性。我们看下百度的实际搜索结果如图所示:
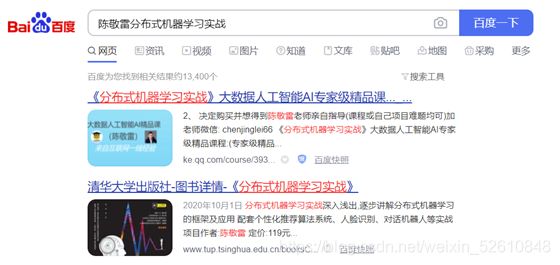
从图中看到,第一个结果是我在腾讯课堂上面讲的精品课,也是针对我写的这本《分布式机器学习实战(人工智能科学与技术丛书)》的配套视频课程,第二个结果是清华大学出版社官网的书籍详情页。可以看到百度的中文分词非常精准,有了精准分词的基础,搜索结果自然也就非常的精准检索到我们想要的文章。当然搜索排序结果和精准分词有关外,还和词频其他很多因素有关,过程是非常复杂的。后面的章节我们还会对搜索引擎的原理做更加详细的讲解。
我们先来看下中文分词的实现有几种方式,简单来说,中文分词根据实现特点大致可分为两个类别:基于词典的分词方法、基于统计的分词方法。
- 基于词典的分词方法
基于词典的分词方法首先会建立一个充分大的词典,然后依据一定的策略扫描句子,若句子中的某个子串与词典中的某个词匹配,则分词成功。
常见的扫描策略有:正向最大匹配、逆向最大匹配、双向最大匹配和最少词数分词。
1)正向最大匹配
对输入的句子从左至右,以贪心的方式切分出当前位置上长度最大的词,组不了词的字单独划开。其分词原理是:词的颗粒度越大,所能表示的含义越精确。
2)逆向最大匹配
原理与正向最大匹配相同,但顺序不是从首字开始,而是从末字开始,而且它使用的分词词典是逆序词典,其中每个词条都按逆序方式存放。在实际处理时,先将句子进行倒排处理,生成逆序句子,然后根据逆序词典,对逆序句子用正向最大匹配。
3)双向最大匹配
将正向最大匹配与逆向最大匹配组合起来,对句子使用这两种方式进行扫描切分,如果两种分词方法得到的匹配结果相同,则认为分词正确,否则,按最小集处理。
4)最少词数分词
即一句话应该分成数量最少的词串,该方法首先会查找词典中最长的词,看是不是所要分词的句子的子串,如果是则切分,然后不断迭代以上步骤,每次都会在剩余的字符串中取最长的词进行分词,最后就可以得到最少的词数。
总结:基于词典的分词方法简单、速度快,效果也还可以,但对歧义和新词的处理不是很好,对词典中未登录的词没法进行处理。
- 基于统计的分词方法
基于统计的分词方法是从大量已经分词的文本中,利用统计学习方法来学习词的切分规律,从而实现对未知文本的切分。随着大规模语料库的建立,基于统计的分词方法不断受到研究和发展,渐渐成为了主流。
常用的统计学习方法有:隐马尔可夫模型(HMM)、条件随机场(CRF)和基于深度学习的方法。
1)HMM和CRF
这两种方法实质上是对序列进行标注,将分词问题转化为字的分类问题,每个字有4种词位(类别):词首(B)、词中(M)、词尾(E)和单字成词(S)。由字构词的方法并不依赖于事先编制好的词典,只需对分好词的语料进行训练即可。当模型训练好后,就可对新句子进行预测,预测时会针对每个字生成不同的词位。其中HMM属于生成式模型,CRF属于判别式模型。
2)基于深度学习的方法
神经网络的序列标注算法在词性标注、命名实体识别等问题上取得了优秀的进展,这些端到端的方法也可以迁移到分词问题上。与所有深度学习的方法一样,该方法需要较大的训练语料才能体现优势,代表为BiLSTM-CRF。
总结:基于统计的分词方法能很好地处理歧义和新词问题,效果比基于词典的要好,但该方法需要有大量人工标注分好词的语料作为支撑,训练开销大,就分词速度而言不如前一种。在实际应用中一般是将词典与统计学习方法结合起来,既发挥词典分词切分速度快的特点,又利用了统计分词结合上下文识别生词、自动消除歧义的优点。
上面给大家讲了中文分词的原理,下面自然语言处理系列会接着更详细的讲解具体实现和主流的开源分词工具。
总结
此文章有对应的配套视频,其它更多精彩文章请大家下载充电了么app,可获取千万免费好课和文章,配套新书教材请看陈敬雷新书:《分布式机器学习实战》(人工智能科学与技术丛书)
【新书介绍】
《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:深入浅出,逐步讲解分布式机器学习的框架及应用配套个性化推荐算法系统、人脸识别、对话机器人等实战项目
【新书介绍视频】
分布式机器学习实战(人工智能科学与技术丛书)新书【陈敬雷】
视频特色:重点对新书进行介绍,最新前沿技术热点剖析,技术职业规划建议!听完此课你对人工智能领域将有一个崭新的技术视野!职业发展也将有更加清晰的认识!
【精品课程】
《分布式机器学习实战》大数据人工智能AI专家级精品课程
【免费体验视频】:
人工智能百万年薪成长路线/从Python到最新热点技术
从Python编程零基础小白入门到人工智能高级实战系列课
视频特色: 本系列专家级精品课有对应的配套书籍《分布式机器学习实战》,精品课和书籍可以互补式学习,彼此相互补充,大大提高了学习效率。本系列课和书籍是以分布式机器学习为主线,并对其依赖的大数据技术做了详细介绍,之后对目前主流的分布式机器学习框架和算法进行重点讲解,本系列课和书籍侧重实战,最后讲几个工业级的系统实战项目给大家。 课程核心内容有互联网公司大数据和人工智能那些事、大数据算法系统架构、大数据基础、Python编程、Java编程、Scala编程、Docker容器、Mahout分布式机器学习平台、Spark分布式机器学习平台、分布式深度学习框架和神经网络算法、自然语言处理算法、工业级完整系统实战(推荐算法系统实战、人脸识别实战、对话机器人实战)、就业/面试技巧/职业生涯规划/职业晋升指导等内容。
【充电了么公司介绍】
充电了么App是专注上班族职业培训充电学习的在线教育平台。
专注工作职业技能提升和学习,提高工作效率,带来经济效益!今天你充电了么?
充电了么官网
http://www.chongdianleme.com/
充电了么App官网下载地址
https://a.app.qq.com/o/simple.jsp?pkgname=com.charged.app
功能特色如下:
【全行业职位】 - 专注职场上班族职业技能提升
覆盖所有行业和职位,不管你是上班族,高管,还是创业都有你要学习的视频和文章。其中大数据智能AI、区块链、深度学习是互联网一线工业级的实战经验。
除了专业技能学习,还有通用职场技能,比如企业管理、股权激励和设计、职业生涯规划、社交礼仪、沟通技巧、演讲技巧、开会技巧、发邮件技巧、工作压力如何放松、人脉关系等等,全方位提高你的专业水平和整体素质。
【牛人课堂】 - 学习牛人的工作经验
1.智能个性化引擎:
海量视频课程,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习课程。
2.听课全网搜索
输入关键词搜索海量视频课程,应有尽有,总有适合你的课程。
3.听课播放详情
视频播放详情,除了播放当前视频,更有相关视频课程和文章阅读,对某个技能知识点强化,让你轻松成为某个领域的资深专家。
【精品阅读】 - 技能文章兴趣阅读
1.个性化阅读引擎:
千万级文章阅读,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习文章。
2.阅读全网搜索
输入关键词搜索海量文章阅读,应有尽有,总有你感兴趣的技能学习文章。
【机器人老师】 - 个人提升趣味学习
基于搜索引擎和智能深度学习训练,为您打造更懂你的机器人老师,用自然语言和机器人老师聊天学习,寓教于乐,高效学习,快乐人生。
【精短课程】 - 高效学习知识
海量精短牛人课程,满足你的时间碎片化学习,快速提高某个技能知识点。
上一篇:自然语言处理系列五》新词发现与短语提取》短语提取
下一篇:自然语言处理系列七》中文分词》规则分词