mmsegment数据集说明(六)
目录
1、数据集加载
2、加载图片及标记
3、定义自己的数据集
4、数据集操作
4.1、重复数据集
4.2、连接数据集
https://mmsegmentation.readthedocs.io/en/latest/tutorials/customize_datasets.html
1、数据集加载
依据tools/train.py中调用方式,提取单独的数据集加载逻辑。
from mmcv.utils import Config
from mmseg.datasets import build_dataset
def main():
cfg = Config.fromfile("configs/fcn/fcn_r50-d8_512x512_20k_voc12.py")
train_set = build_dataset(cfg.data.train)
print("train_set:", len(train_set))
val_cfg = cfg.data.val
val_cfg.pipeline = cfg.data.train.pipeline
valid_set = build_dataset(val_cfg)
print("valid_set:", len(valid_set))
if __name__ == '__main__':
main()输出:
train_set: 1464
valid_set: 1449只调用数据集生成,不进行数据增广操作,作为调试:
from mmseg.datasets import build_dataset
train_cfg = dict(
type='PascalVOCDataset',
data_root=r'F:\dataset\voc2012',
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/train.txt',
pipeline=[])
train_set = build_dataset(train_cfg)
print("train_set:", len(train_set))
print("train_set[0]:", train_set[0])train_set[0]输出,也即pipeline不为空时的results的输出:
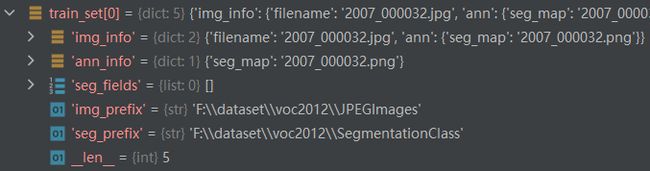
mmsegmentation中,数据集输出用于分割的图片名和标记名称。在之后的pipeline中执行文件的读取及数据增广。
2、加载图片及标记
设置pipeline,读取图像和标记,pipeline执行对results的后处理之后输出。
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
]返回14个字段,其中img、gt_semantic_seg分别为图像和分割标记图:
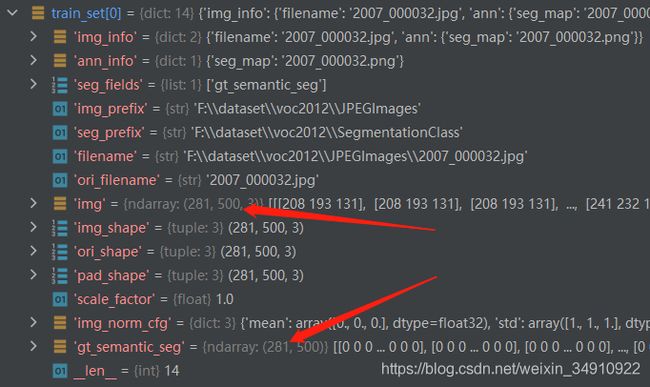
数据集继承关系:PascalVOCDataset->CustomDataset->Dataset。
基类CustomDataset负责实现全部功能,子类PascalVOCDataset覆盖全部参数:CLASSES、PALETTE,并覆盖文件后缀名参数:
def __init__(self, split, **kwargs):
super(PascalVOCDataset, self).__init__(
img_suffix='.jpg', seg_map_suffix='.png', split=split, **kwargs)
assert osp.exists(self.img_dir) and self.split is not None3、定义自己的数据集
详细的数据集操作需要阅读transform,这里定义voc标签最简格式,形如:
├── voc2012_mini
│ ├── imgs
│ │ ├── xxx{img_name.jpg}
│ ├── annotations
│ │ ├── xxx{img_name.png}
│ ├── train.txt
│ ├── valid.txt调用方式:
from mmseg.datasets import build_dataset
def main():
train_cfg = dict(
type='PascalVOCDataset',
data_root=r'F:\data\voc2012_mini',
img_dir='imgs',
ann_dir='annotations',
split='train.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
])
train_set = build_dataset(train_cfg)
print("train_set cnt:", len(train_set))
# print("train_set[0]:", train_set[0])输出:
![]()
4、数据集操作
目前,支持合并和重复数据集。以验证集数据测试。
4.1、重复数据集
我们使用RepeatDataset包装器来重复数据集。例如,假设原始数据集为voc2012_mini的训练集,要重复它,则配置如下所示:
repeat_train_cfg = dict(
type='RepeatDataset',
times=2,
dataset=dict(
type='PascalVOCDataset',
data_root=r'F:\data\voc2012_mini',
img_dir='imgs',
ann_dir='annotations',
split='train.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
])
)
train_set = build_dataset(repeat_train_cfg)
print("train_set:", len(train_set))输出:

4.2、连接数据集
有2种方式连接数据集。
方式1:如果要连接的数据集属于同一类型,但带有不同的注释文件,则可以如下连接数据集配置。
a)可以将两个串联ann_dir。
dataset_A_train = dict(
type='Dataset_A',
img_dir = 'img_dir',
ann_dir = ['anno_dir_1', 'anno_dir_2'],
pipeline=train_pipeline
)b)可以将两个串联split。
dataset_A_train = dict(
type='Dataset_A',
img_dir = 'img_dir',
ann_dir = 'anno_dir',
split = ['split_1.txt', 'split_2.txt'],
pipeline=train_pipeline
)c)可以连接两个ann_dir并split同时进行。
dataset_A_train = dict(
type='Dataset_A',
img_dir = 'img_dir',
ann_dir = ['anno_dir_1', 'anno_dir_2'],
split = ['split_1.txt', 'split_2.txt'],
pipeline=train_pipeline
)在这种情况下,ann_dir_1和ann_dir_2对应于split_1.txt和split_2.txt。
方式2:如果要连接的数据集不同,则可以如下连接数据集配置。
dataset_A_train = dict()
dataset_B_train = dict()
data = dict(
imgs_per_gpu=2,
workers_per_gpu=2,
train = [
dataset_A_train,
dataset_B_train
],
val = dataset_A_val,
test = dataset_A_test
)一个更复杂的例子,重复Dataset_A和Dataset_B由N和M次,分别再串接重复数据集的计算如下。
dataset_A_train = dict(
type='RepeatDataset',
times=N,
dataset=dict(
type='Dataset_A',
...
pipeline=train_pipeline
)
)
dataset_A_val = dict(
...
pipeline=test_pipeline
)
dataset_A_test = dict(
...
pipeline=test_pipeline
)
dataset_B_train = dict(
type='RepeatDataset',
times=M,
dataset=dict(
type='Dataset_B',
...
pipeline=train_pipeline
)
)
data = dict(
imgs_per_gpu=2,
workers_per_gpu=2,
train = [
dataset_A_train,
dataset_B_train
],
val = dataset_A_val,
test = dataset_A_test
)