爬虫案例-多线程与单线程爬取图片
爬虫案例-多线程与单线程爬取图片
一、先使用单线程完成这个案例:
说明:为了方便,没有对采用懒加载的网站进行爬取,而是对一个普通的网站进行爬取
1.确定目标和思路分析:
今天的幸运儿是: http://www.bbsnet.com/doutu
下面是这个网站的截图:
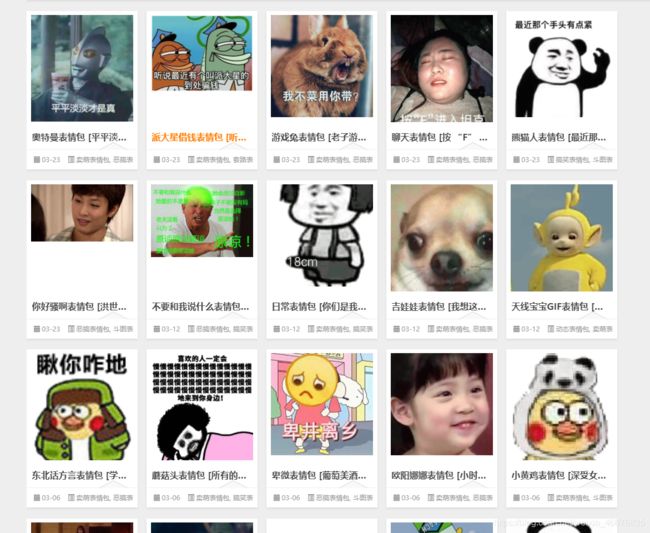
接下来,我们首先获取所示第一页的所有图片集合对应url,然后再分别打开它们,去下载其中的图片。当然,仅仅获取一页是不够的,我们需要想获取多少页就获取多少也才行。
下面开始正文:
2.优先写出大体框架:
1>导入模块:
#导入基本的模块
import requests
from lxml import etree
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from urllib import request
2>大体框架:
这里我们采用类的方式来写程序,因为这样方便后面我们使用多线程来书写代码。
class MySpider(object):
def __init__(self):
#第一页网址
self.url = 'http://www.bbsnet.com/doutu/page/1'
#基础的headers参数
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
#selenium模块的driver生成
self.driver_path = r'D:\CHROM\chrome\chromedriver.exe'
self.options = Options()
self.options.add_argument('--headless')
self.options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(executable_path=self.driver_path, options=self.options)
def main(self):
#获取每一个图片集合的url
info_dict = self.get_target_urls()
#获取每一个url中的图片
info_dict_new = self.get_target_images(info_dict)
#下载和处理
self.load_images(info_dict_new)
上面的代码只是针对的第一页,当然我们只要能够爬取第一页的内容,其他的页数自然也是手到擒来。
说明: 关于selenium,大家应该都清楚,但是为了防止有些人不了解这个模块,还是说一句,这个模块就是模拟人类使用浏览器的过程,这个模块默认会展示出模拟的过程,所以为了减少这个过程,加上了下面的三行代码(如果想要观察这个过程,这三行代码可以去掉,但是需要在其下面的代码中删除options参数):
3.获取第一页中每一个图片的url,即get_target_urls()函数:
1>给出代码:
def get_target_urls(self):
#十分基础的获取网页源代码方法
response = requests.get(self.url, headers=self.headers)
text = response.content.decode('utf-8')
#采用lxml库解析
html = etree.HTML(text)
#获取标题
titles = html.xpath('//h2/a/text()')
#获取url
urls = html.xpath('//h2/a/@href')
#以字典的形式返回
info_dict = {
'titles':titles,
'url':urls
}
return info_dict
2>分析:
首先我们打开网站,然后鼠标对准任意一张图片的标题栏,右击选择检查,可以得到以下图片显示的信息:

好的,接下来我们需要获取所有的a标签里面的href属性里的值,而这是一件比较容易的事情,而这里我采取的是lxml库来解析这个网页源代码。方法如下:
#采用lxml库解析
html = etree.HTML(text)
#获取标题
titles = html.xpath('//h2/a/text()')
#获取url
urls = html.xpath('//h2/a/@href')
为了方便大家理解,我把**//h2/a/text()**代码获取思路放在下图中:

然后为了方便起见,我使用字典来存储这个结果,下面给出结果的示例:

4.获取对应图片集合里所有图片,即get_target_images()函数:
1>先给出代码:
def get_target_images(self,info_dict):
target_urls = info_dict['url']
info_dict_new = {
'title':info_dict['titles'],
'images':[]
}
for url in target_urls:
#requests加载不出来数据,采用selenium处理
# response = requests.get(url,headers=self.headers,timeout=5)
# text = response.content.decode('utf-8')
# print(text)
self.driver.get(url)
time.sleep(1)
text = self.driver.page_source
html = etree.HTML(text)
#获取图片的下载地址
srcs_url = html.xpath('//div[@id="post_content"]//p//img/@src')
#返回所有图片地址
info_dict_new['images'].append(srcs_url)
return info_dict_new
2>分析:
我最开始采用的是requests方式获取网页源代码,但是我发现失败了,一直获取的结果如下:

我最开始觉得可能遇到了懒加载的问题,但是想了想觉得不是,因为懒加载就是滚轮往下滑动,图片就加载出来,但是我发现这个网站并不是懒加载,因为我一打开网站,所有图片就全都加载出来了,大家也可以去试试。然后我怀疑可能是网速的问题,或者说requests.get()之后,网站并没有加载完成,只是加载出来了框架,所以获取的才是图片中的结果。(其实这个我也不是很清楚,希望有人能够解惑)
于是我决定采用selenium来解决问题,果然selenium不愧是模拟人类的行为,轻轻松松获取到了我们需要的网页源代码,但是从我上面的代码大家可以看出来,并没有用其他的方式,只是让它多加载了1秒钟,所以这就证明了不是懒加载的问题。
好的,下面开始获取所有的图片下载地址:
首先鼠标放在任何一张图片,鼠标右键选择审查元素,然后可以得到以下图片的信息:
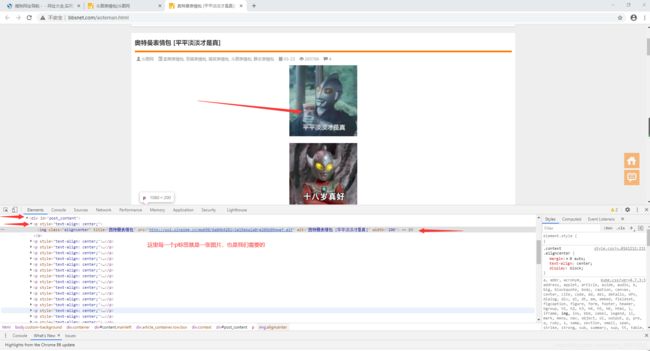
显然,我们需要获取所有的p标签下的img子标签里的src属性,这里我们继续采用lxml库来解析,即以下代码:
html = etree.HTML(text)
#获取图片的下载地址
srcs_url = html.xpath('//div[@id="post_content"]//p//img/@src')
而为了读取数据方便,我仍然采用的是字典形式,为了大家能够直观的感受到这个字典的形式,下面给出它的示例图片:

5.下载图片:
1>给出代码:
def load_images(self,info_dict_new):
nums = 0
title_num = 0
images_url = info_dict_new['images'] # 结构为 : [[xxxxxxxx,xx,xx,x,x,x],[],[],[].........]
title = info_dict_new['title']
for urls in images_url:
for url in urls:
request.urlretrieve(url,'./images/' + title[title_num] + str(nums) + '.jpg') #这里希望大家有一个images的目录
nums+=1
title_num += 1
2>分析:
下载图片其实非常简单,因为有一个库叫做urllib,里面有一个方法是: urllib.request.urlretrieve(),可以十分方便的下载图片到指定路径,所以也没什么好说,只是说一下,图片名字的问题,为了避免因为名字重复而导致最后只有一张图片,所以加上了数字后缀,名字示例如下:

6.完善代码:
1>分析:
上面基本上完成了这个程序的所有过程,只差最后一步了,就是添加多页爬取的功能。
好的,开始吧!
首先我们看网页,如果大家认真观察网页地址栏,可以发现下面的规律:
这是第一页的图片:

这是第二页的图片:

相信细心的朋友们已经发现了规律,如下:
http://www.bbsnet.com/doutu/page/1 这是第一页的网址
http://www.bbsnet.com/doutu/page/2 这是第二页的网址
显然,我们只需要在程序最初添加点控制语句即可非常简单的爬取到多页信息。
2>完善代码:
# 完整代码如下:
import requests
from lxml import etree
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from urllib import request
class MySpider(object):
def __init__(self):
self.url = 'http://www.bbsnet.com/doutu/page/{nums}'
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
self.driver_path = r'D:\CHROM\chrome\chromedriver.exe'
self.options = Options()
self.options.add_argument('--headless')
self.options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(executable_path=self.driver_path, options=self.options)
def main(self):
pages = int(input('请输入需要爬取多少页:'))
for page in range(1,pages+1):
url = self.url.format(nums=page)
#获取每一个图片集合的url
info_dict = self.get_target_urls(url)
#获取每一个url中的图片
info_dict_new = self.get_target_images(info_dict)
#下载和处理
self.load_images(info_dict_new)
def get_target_urls(self,url):
response = requests.get(url, headers=self.headers)
text = response.content.decode('utf-8')
#采用lxml库解析
html = etree.HTML(text)
#获取标题
titles = html.xpath('//h2/a/text()')
#获取url
urls = html.xpath('//h2/a/@href')
#以字典的形式返回
info_dict = {
'titles':titles,
'url':urls
}
return info_dict
def get_target_images(self,info_dict):
target_urls = info_dict['url']
info_dict_new = {
'title':info_dict['titles'],
'images':[]
}
for url in target_urls:
# # requests加载不出来数据,采用selenium处理
# response = requests.get(url,headers=self.headers,timeout=5)
# text = response.content.decode('utf-8')
# print(text)
# break
self.driver.get(url)
time.sleep(1)
text = self.driver.page_source
html = etree.HTML(text)
#获取图片的下载地址
srcs_url = html.xpath('//div[@id="post_content"]//p//img/@src')
#返回所有图片地址
info_dict_new['images'].append(srcs_url)
#暂时只爬取一个
break
return info_dict_new
def load_images(self,info_dict_new):
nums = 0
title_num = 0
images_url = info_dict_new['images'] # 结构为 : [[xxxxxxxx,xx,xx,x,x,x],[],[],[].........]
title = info_dict_new['title']
for urls in images_url:
for url in urls:
request.urlretrieve(url,'./images/' + title[title_num] + str(nums) + '.jpg') #这里希望大家有一个images的目录
nums+=1
title_num += 1
if __name__ == '__main__':
spider = MySpider()
spider.main()
结果如下:
这里建议大家测试时尽量少爬取点图片,这样结果才能更快的看到
7.分析与总结:
当我们爬取少量图片时多线程和单线程无太大区别,但是当爬取的图片达到一定量时,显然是多线程占优势,下面我们开始使用多线程完成这个案例。
二、使用多线程完成这个案例:
说明:上面已经给大家详细分析了单线程爬取的思路和代码分析,下面主要着重于使用多线程实现,而不着重如何爬取
1.使用多线程的思路:
使用多线程只要是使用python自带的queue来实现。即几个线程去获取url,然后几个线程去下载图片。
2.开始实现:
1>首先创建两个类,一个生产者(获取url),一个消费者(下载图片)
第一个类:
代码如下:
class MySpider_one(threading.Thread):
def __init__(self):
super(MySpider_one,self).__init__()
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
self.driver_path = r'D:\CHROM\chrome\chromedriver.exe'
self.options = Options()
self.options.add_argument('--headless')
self.options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(executable_path=self.driver_path, options=self.options)
def run(self):
while True:
if Queue_pages.empty():
break
url = Queue_pages.get()
#获取每一个图片集合的url
info_dict = self.get_target_urls(url)
#获取每一个url中的图片
self.get_target_images(info_dict)
def get_target_urls(self,url):
response = requests.get(url, headers=self.headers)
text = response.content.decode('utf-8')
#采用lxml库解析
html = etree.HTML(text)
#获取url
urls = html.xpath('//h2/a/@href')
info_dict = {
'url':urls
}
return info_dict
def get_target_images(self,info_dict):
target_urls = info_dict['url']
for url in target_urls:
self.driver.get(url)
time.sleep(1)
text = self.driver.page_source
html = etree.HTML(text)
#获取图片的下载地址
srcs_url = html.xpath('//div[@id="post_content"]//p//img/@src')
for src in srcs_url:
Queue_images.put(src)
# 获取标题
titles = html.xpath('//div[@id="post_content"]//p//img/@title')
for title in titles:
Queue_title.put(title)
#暂时只爬取一个
break
观察上面的代码,其实与单线程的区别就是把下载图片的函数丢掉了,然后加入了三个Queue,其中一个Queue存放页数,一个Queue存放url,一个Queue存放title。而我们直到线程之间共享全局变量,所以我们完全可以在全局变量处定义这三个Queue,然后呢分析一下这几行代码:
def run(self):
while True:
if Queue_pages.empty():
break
url = Queue_pages.get()
#获取每一个图片集合的url
info_dict = self.get_target_urls(url)
#获取每一个url中的图片
self.get_target_images(info_dict)
首先需要判断一下释放所有的页都有线程爬取,如果所有页都有线程爬取,则可以停止爬取了。
第二个类:
代码如下:
class MySpider_two(threading.Thread):
def run(self):
while True:
if Queue_images.empty():
break
url = Queue_images.get()
title = Queue_title.get()
self.load(url,title)
def load(self,url,title):
nums = random.randint(0,100)
request.urlretrieve(url,'./images_two/'+title+ str(nums) + '.jpg')
观察上面的 代码其实挺好理解的,只要你对多线程的Queue比较熟悉。
这里值得说明的是,因为title的Queue里面一个title对应多个图片的url(下载地址),所以对于给每一个图片起名字这个任务我没有很好的办法解决,只好导入一个随机模块,然后随机生成名字,当然这个是有坏处的,但是我暂时也没有更好的办法解决了。
2>调用与实现:
下面完成调用:
if __name__ == '__main__':
#一个线程去获取url,另外一个线程下载
start_time = time.time()
Queue_pages = queue.Queue()
Queue_pages.put('http://www.bbsnet.com/doutu/page/1')
Queue_pages.put('http://www.bbsnet.com/doutu/page/2')
Queue_pages.put('http://www.bbsnet.com/doutu/page/3')
Queue_pages.put('http://www.bbsnet.com/doutu/page/4')
Queue_pages.put('http://www.bbsnet.com/doutu/page/5')
Queue_pages.put('http://www.bbsnet.com/doutu/page/6')
Queue_images = queue.Queue()
Queue_title = queue.Queue()
t_list_one = []
t_list_two = []
#这里我选择先执行完一个线程,再去执行完另外一个线程,主要是为了方便计算消耗的时间
for i in range(5):
t1 = MySpider_one()
t1.start()
t_list_one.append(t1)
for t in t_list_one:
t.join()
for i in range(5):
t2 = MySpider_two()
t2.start()
t_list_two.append(t2)
for t in t_list_two:
t.join()
其实上面的代码很基础,没有什么好讲解的,如果大家对于多线程有不懂的,可以看我昨天写的博客。
3.完整代码展示:
import requests
from lxml import etree
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import queue
import threading
from urllib import request
import random
'''
url : http://www.bbsnet.com/doutu
'''
class MySpider_one(threading.Thread):
def __init__(self):
super(MySpider_one,self).__init__()
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
self.driver_path = r'D:\CHROM\chrome\chromedriver.exe'
self.options = Options()
self.options.add_argument('--headless')
self.options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(executable_path=self.driver_path, options=self.options)
def run(self):
while True:
if Queue_pages.empty():
break
url = Queue_pages.get()
#获取每一个图片集合的url
info_dict = self.get_target_urls(url)
#获取每一个url中的图片
self.get_target_images(info_dict)
def get_target_urls(self,url):
response = requests.get(url, headers=self.headers)
text = response.content.decode('utf-8')
#采用lxml库解析
html = etree.HTML(text)
#获取url
urls = html.xpath('//h2/a/@href')
info_dict = {
'url':urls
}
return info_dict
def get_target_images(self,info_dict):
target_urls = info_dict['url']
for url in target_urls:
self.driver.get(url)
time.sleep(1)
text = self.driver.page_source
html = etree.HTML(text)
#获取图片的下载地址
srcs_url = html.xpath('//div[@id="post_content"]//p//img/@src')
for src in srcs_url:
Queue_images.put(src)
# 获取标题
titles = html.xpath('//div[@id="post_content"]//p//img/@title')
for title in titles:
Queue_title.put(title)
#暂时只爬取一个
break
class MySpider_two(threading.Thread):
def run(self):
while True:
if Queue_images.empty():
break
url = Queue_images.get()
title = Queue_title.get()
self.load(url,title)
def load(self,url,title):
nums = random.randint(0,100)
request.urlretrieve(url,'./images_two/'+title+ str(nums) + '.jpg')
if __name__ == '__main__':
#一个线程去获取url,另外一个线程下载
start_time = time.time()
Queue_pages = queue.Queue()
Queue_pages.put('http://www.bbsnet.com/doutu/page/1')
Queue_pages.put('http://www.bbsnet.com/doutu/page/2')
Queue_pages.put('http://www.bbsnet.com/doutu/page/3')
Queue_pages.put('http://www.bbsnet.com/doutu/page/4')
Queue_pages.put('http://www.bbsnet.com/doutu/page/5')
Queue_pages.put('http://www.bbsnet.com/doutu/page/6')
Queue_images = queue.Queue()
Queue_title = queue.Queue()
t_list_one = []
t_list_two = []
for i in range(5):
t1 = MySpider_one()
t1.start()
t_list_one.append(t1)
for t in t_list_one:
t.join()
for i in range(5):
t2 = MySpider_two()
t2.start()
t_list_two.append(t2)
for t in t_list_two:
t.join()
print('cost:', time.time() - start_time)
结果:

4.分析与总结:
1>单线程与多线程的时间差:
以下载6页中的第一个图片集合为例,单线程耗时:35.66601610183716,多线程耗时:23.11021089553833。所以效率差别可见一斑。
2>总结:
首先我知道我多线程没有写得很清楚,因为关于多线程,我在我的另外一篇博客上写了一点,不懂的朋友可以去看看。然后为了方便大家理解Queue,我再给大家演示一下Queue和多线程之间共享全局变量的特点:
import queue
import threading
import time
class Thread_one(threading.Thread):
def run(self):
print('进入one')
for i in range(3):
Queue.put(i)
time.sleep(2)
class Thread_two(threading.Thread):
def run(self):
print('进入two')
while True:
if Queue.empty():
break
print(Queue.get())
time.sleep(2)
if __name__ == '__main__':
Queue = queue.Queue()
t1 = Thread_one()
t2 = Thread_two()
t1.start()
t2.start()
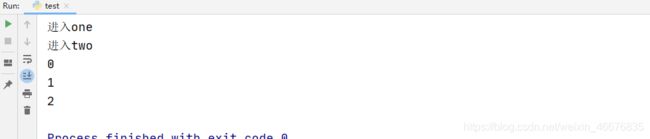
上面代码思路是验证两个线程中一个给Queue插入元素,一个输出元素,将它们同时运行,你会发现,虽然开始线程2中的Queue没有元素,但是随着线程1的运行,便开始慢慢打印出线程1放入的数据。
结果如下:
完成时间: 2020/10/28 18:36