风起云涌的大数据战场上,早已迎百花齐放繁荣盛景,各大企业加速跑向“大数据时代”。而我们作为大数据的践行者,在这个“多智时代”如何才能跟上大数据的潮流,把握住大数据的发展方向。
前言
大数据起源于2000年左右,也就是互联网高速发展阶段。经过几年的发展,到2008年 Hadoop 成为 Apache 顶级项目,迎来了大数据体系化的快速发展期,到如今 Hadoop 已不单单指一个软件,而成为了大数据生态体系的代名词。
自2014年以来,国内大数据企业层出不穷,可以用“乱花渐欲迷人眼”形容现状,也是在这一年,我国《政府工作报告》首次提出“大数据”,大数据作为一种新兴产业正式登陆中国舞台。之后,又上升至国家战略。自此“大数据”这三个字频繁出现在各大媒体上。
在大数据的发展历程中,互联网企业是布局较早且融合较深的行业之一。因其互联网属性的优势在大数据领域布局较早。
而提到国内互联网大数据企业,就不得不提国内互联网三巨头(百度、阿里、腾讯),三巨头的大数据业务围绕其自身业务发展而成:百度重算法、阿里重电商、腾讯重社交,出于自身战略,三巨头在大数据领域的布局方面各有重心,反映出其企业发展方向的战略和思路。
BAT的大数据产业
BAT 是我国互联网企业中大数据布局较早也是较具有竞争优势的公司。其中,阿里布局大数据产业最早,腾讯次之,百度则最晚。
阿里
阿里大数据发展战略在 2008 年提出,随后围绕电商业务,阿里在数据集群、数据仓库等方面做出了部署。
如今,提到阿里大数据,可以从两方面来作观察:一是以阿里电商业务基础建立起来的阿里数据;二是阿里云。
阿里数据以淘宝、天猫、阿里妈妈等平台为业务线,通过数据采集、数据计算、数据服务、数据应用等环节,形成从数据采集到数据应用的闭环系统
阿里云则主要以在线公共服务的方式,为用户提供云服务器、云数据库、云安全等云计算服以及大数据、人工智能服务、精准定制等基于场景的行业解决方案。创立于 2009年,如今,阿里云已成为全球前三大公共云服务提供商。
另一方面阿里也是十分有远见的,早在15、16年开始做Flink,深耕布局、落地双11、孵化Blink,据称搞了上百人的团队,在国内外的技术会议上不断宣传推广,在2019年开年,阿里以9000万欧元收购了Apache Flink母公司Data Artisans,将Flink收入囊中,目前,Flink 可以称之为 Apache 基金会中最为活跃的项目之一,在 GitHub 上其访问量在 Apache 项目中位居前三。同时,在全球范围内,优步、网飞、微软和亚马逊等国际互联网公司也逐渐开始使用 Apache Flink。

腾讯
2009 年 1 月,腾讯搭建第一个 Hadoop 集群,标志着腾讯大数据之路正式开启。
与阿里不同,腾讯大数据主要围绕其社交、游戏业务展开。坐拥着海量的用户数据。
基于微信、QQ 等社交工具,通过对移动用户的数据分析,建立用户个人画像(如用户的社会关系、性格禀赋、兴趣爱好等)提供相应的营销服务。
工具,工具主要有腾讯移动推送信息“信鸽”,同样也是围绕腾讯的社交用户数据开发而成,提供向用户推送消息的服务。
腾讯云,起步比阿里云晚几年,目前暂时落后于阿里云,但是云计算市场是一个马拉松赛,起步早是一方面,但最终还是要看谁能坚持到最后。
之前看过一篇资讯,中国IT领袖峰会在深圳举行,在一个对话环节。
李彦宏说:“云计算这个东西不客气一点讲它是新瓶装旧酒,没有新东西。”
马化腾说:"云计算让计算能力、处理能力甚至逻辑组件都能够像水和电一样使用,的确是有想象空间的,但可能你过几百年、一千年后才可能实现,现在还是确实过早了。"
马云大概意思:“云计算这个东西应该好好做,今天就应该做,如果阿里巴巴不做云计算,腾讯、百度会把阿里巴巴赶出电子商务门口。“
从对话中能看出马云的眼光很好。李彦宏和马化腾虽都是技术出身,但没有一个教师出身的马云眼光长远。
另一点,腾讯相比其他巨头在技术方面要低调不少。技术大牛很少出来做报告,更不会向百度、阿里那样主动包装宣传技术大牛。其技术虽然低调,但执行力很强。据腾讯的程序员朋友说封闭开发、集体加班是常有的事情。但配套的重金激励也能跟上。重金之下必有勇夫!

百度
BAT 中,百度大数据战略提出时间最晚,但举措频频。
2013 年,百度成立深度学习实验室(IDL),发力人工智能。
2014 年,百度对外宣布开放“大数据引擎”,以开放云、数据工厂和百度大脑三个为核心组件,
通过平台化和接口化的方式,对外开放其大数据存储、分析和智能化处理等核心能力。作为全球首个开放大数据引擎,百度“大数据引擎”已与政府、非政府组织、制造、医疗、金融、零售和教育等传统领域展开合作。
同年 8 月,百度与联合国宣布启动战略合作,共建大数据联合实验室 (bdl),探索利用大数据解决全球
性问题的创新模式。
2017 年 3 月 2 日,百度揭牌深度学习技术及应用国家工程实验室,“国字号”AI实验室落户百度。
可以看出,百度不同于阿里和腾讯基本以自身业务布局大数据,其大数据布局侧重于新方向,在人工智能上尤其突出。不过,梳理百度大数据的数据产品可以发现,其大数据产品涉及数据分析、数据风控、数据营销等,布局较广。

大数据领域分析
大数据技术发展到如今,已经形成了完备的体系结构及应用方向,技术迭代速度非常快,新框架层出不穷,大数据应用方向不断细化,从业人员越来越多。
大数据时代,数据量大,数据源异构多样,数据时效性等特征催生了大量的新技术需求。在这样的需求下,诞生了规模化并行处理(MPP) 的分布式计算框架;面向海量的非结构化数据,出现了 Hadoop、Spark等生态体系的分布式批处理框架;面对时效性及实时处理的需求,出现了Flink、Spark Streaming等分布式流处理框架。
下图为 Apache 生态下的大数据框架:

未来在 Apache 中孵化成功的大数据框架会越来越多,大数据生态体系会越来越完善,也意味着大数据的门槛会越来越低,入行的人越来越多。所以为了我们不被时代所淘汰,需要不断学习,前期学习广度,后期专注深度。潜心一技,练到极致!
应用层面
大数据在应用层面划分了以下几个大类:金融大数据、营销大数据、交通物流大数据、医疗大数据、教育大数据、文娱大数据等。
我们接下来以大数据科研及大数据企业两方面进行分析:
1. 大数据科研
自 2012 年大数据广泛实际应用以来,产业界和学术界在大数据技术与应用方面的研究创新不断取得突破,大数据领域的论文发表数量快速增长。
以下为 2012-2020年全球大数据论文发表数量及各国占比:


数据来源:Web of Science,2020年10月
从上图可以看出,论文发表数量在2018年达到顶峰,是2012年的5.4倍,年增长率为 32.5%,随后2019年论文数量开始下降,2020年全年数量预计较去年还会近一步下滑,这也说明随着科学研究的不断进展,大数据的相关理论体系逐渐成熟,未来学术论文发表增长速度或将放缓。
从国家来看,中国和美国仍然是大数据学术研究的核心地带。发表的论文数量遥遥领先于其他国家。未来在大数据领域,应该还是以中国和美国为首,带领大数据技术走向更高的水平。
再来看国内大数据产业的发展状况,根据工业和信息化部发布的数据显示,2019年我国以云计算、大数据技术为基础的平台类技术服务收入2.2万亿元,其中,典型云服务和大数据服务收入达3284亿元,提供服务的企业达2977家,由此可见,大数据产业发展日益壮大。
2. 大数据企业
大数据企业数量增长统计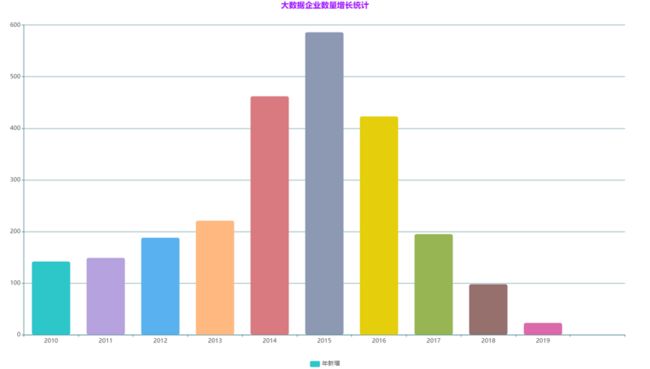
数据来源:中国信息通信研究院,2020年10月
从上图可以看出国内大数据企业在 2014 年、2015 年呈现爆发式增长,而在 2016 年
后又有回落,这与大数据在我国的发展状况相对应。2014 年被称为大数据元年,随后在国家政策的支持下,各大数据企业应运而生,之后随着创业者的冷静,大数据企业也趋于减少。
是否有国资背景
数据来源:数据观
大数据行业虽然有国家政策的支持,但大部分还是以私企为主,具有国资背景的企业较少,只占总体的 13%。
大数据企业地域分布
数据来源:中国信息通信研究院,2020年10月
由表中数据可以得出,北京是大数据企业的“高发区”,占比为35%,其次是广东(18%),之后是上海(16%),然后是浙江(8%),所以我国大数据企业主要分布在北京、广东、上海、浙江等经济发达省份。
大数据行业应用企业类型分布
数据来源:中国信息通信研究院,2020年10月
从图中可以看出大数据涉及的行业是非常广泛的,其中以金融、医疗健康、政务为大数据行业应用的主要类型。除此之外依次是互联网,教育,交通运输,电子商务等。
大数据获投轮次分布
数据来源:中国信息通信研究院,2020年10月
从上图看出获 天使轮、A 轮 融资企业较多,说明我国大数据企业数量虽然众多,但大部分处于初级阶段,技术能力、技术落地能力有待提高。另一方面也说明投资机构对大数据市场依然充满信息,对未来估值抱有很大期望。
大数据未来发展趋势
以下观点来源:中国信息通信研究院
1. 以控制成本为主要理念
大数据自诞生以来始终沿袭着基于Hadoop或者MPP的分布式框架,形成了具备存储、计算、处理、分析等能力的完整平台,大数据分布式框架采用存储与计算耦合,使数据在自身存储的节点上完成计算,以降低交互。
但是实际业务中数据存储与计算能力要求不同且各自独立的。在存储与计算耦合的情况下,当二者之一出现瓶颈时,资源的横向扩展必然导致存储或计算能力的冗余,造成难以避免的额外成本。
存储与计算分离有效控制成本。存储与计算在数据的生命周期中剥离开,形成两个独立的资源集合。两个资源集合之间互不干涉又通力协作,使得单位资源的成本尽量减少,同时兼具充分的弹性以供横向扩展。这种模式应是未来的发展方向。
目前国内外众多厂商已深入进行了存算分离的实践。国内像阿里云使用自身 EMR+OSS产品代替原生 Hadoop 存储架构,整体费用预估下降 50% 。华为使用自身 FusionInsight+EC,存储利用率从 33% 提升至 91.6%。
国外像 Snowflake 公司提出的数据仓库服务化(DaaS),将分析能力以云服务的形式在AWS等云平台上提供按次计费的服务。
2. 自动化智能化需求紧迫
目前大数据领域的数据管理依赖人工操作,成本巨大。在基于机器学习的人工智能不断进步的情况下,更加自动化智能化的数据管理平台将会助力数据管理工作高效进行。
其中以 数据建模、数据标签、主数据发现、数据标准应用成为主要的应用方向。
3. 图分析需求旺盛
以社交网络、用户行为、网页链接关系等为代表的数据,往往需要通过“图”的形态以最原始、最直观的方式展现其关联性。
所以专注于图结构数据的图分析技术成为数据分析技术的新方向。与图分析相关的技术成为热点的产品方向,其中以图数据库、图计算引擎、知识图谱三项技术为主。
根据 DB-Engines 排名分析,图数据库关注热度在2013-2020年间增长了10倍,关注度增长排名第一。国内阿里云、华为、腾讯、百度等厂商及部分初创公司已布局这一领域。
4. 隐私计算技术热度上升
在数据合规流通需求旺盛的环境下,隐私计算技术发展火热,隐私计算为实现安全合规的数据流通带来了可能。
目前隐私计算主要分为多方安全计算和可信硬件两大流派。其中多方安全计算基于密码学理论;可信硬件依赖对安全硬件的信赖。
此外,还有联邦学习、共享学习等通过多种技术手段平衡安全性和性能的隐私保护,也为跨企业机器学习和数据挖掘提供新的解决思路。
参考来源:中国信息通信研究院[大数据白皮书(2020年)];数据观(www.cbdio.com)