复合索引(又称为联合索引),是在多个列上创建的索引。创建复合索引最重要的是列顺序的选择,这关系到索引能否使用上,或者影响多少个谓词条件能使用上索引。复合索引的使用遵循最左匹配原则,只有索引左边的列匹配到,后面的列才能继续匹配。本文主要探究复合索引的创建顺序与使用情况。
(一)复合索引的概念
在单个列上创建的索引我们称为单列索引,在2个以上的列上创建的索引称为复合索引。在单个列上创建索引相对简单,通常只需要考虑列的选择率即可,选择性越好,代表数据越分散,创建出来的索引性能也就更好。通常,某列选择率的计算公式为:
selectivity = 施加谓词条件后返回的记录数 / 未施加谓词条件后返回的记录数
可选择率的取值范围是(0,1],值越小,代表选择性越好。
对于复合索引(又称为联合索引),是在多个列上创建的索引。创建复合索引最重要的是列顺序的选择,这关系到索引能否使用上,或者影响多少个谓词条件能使用上索引。复合索引的使用遵循最左匹配原则,只有索引左边的列匹配到,后面的列才能继续匹配。
(二)什么情况下会使用复合索引的列
复合索引遵循最左匹配原则,只有索引中最左列匹配到,下一列才有可能被匹配。如果左边列使用的是非等值查询,则索引右边的列将不会被查询使用,也不会被排序使用。
实验:哪些情况下会使用到复合索引
复合索引中的哪些字段被使用到了,是我们非常关心的问题。网络上一个经典的例子:
-- 创建测试表
CREATE TABLE t1(
c1 CHAR(1) not null,
c2 CHAR(1) not null,
c3 CHAR(1) not null,
c4 CHAR(1) not null,
c5 CHAR(1) not null
)ENGINE innodb CHARSET UTF8;
-- 添加索引
alter table t1 add index idx_c1234(c1,c2,c3,c4);
--插入测试数据
insert into t1 values('1','1','1','1','1'),('2','2','2','2','2'),
('3','3','3','3','3'),('4','4','4','4','4'),('5','5','5','5','5');
需要探索下面哪些查询语句使用到了索引idx_c1234,以及使用到了索引的哪些字段?
(A) where c1=? and c2=? and c4>? and c3=?
(B) where c1=? and c2=? and c4=? order by c3
(C) where c1=? and c4=? group by c3,c2
(D) where c1=? and c5=? order by c2,c3
(E) where c1=? and c2=? and c5=? order by c2,c3
(F) where c1>? and c2=? and c4>? and c3=?
A选项:
mysql> explain select c1,c2,c3,c4,c5 from t1 where c1='2' and c2='2' and c4>'1' and c3='2'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | t1 | NULL | range | idx_c1234 | idx_c1234 | 12 | NULL | 1 | 100.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
使用的索引长度为12,代表4个字段都使用了索引。由于c1、c2、c3都是等值查询,所以后面的c4列也可以用上。
注:utf8编码,一个索引长度为3,这里12代表4个字段都用到该索引。
B选项:
mysql> explain select c1,c2,c3,c4,c5 from t1 where c1='2' and c2='2' and c4='2' order by c3; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-----------------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_c1234 | idx_c1234 | 6 | const,const | 1 | 20.00 | Using index condition | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-----------------------+
使用的索引长度为6,代表2个字段使用了索引。根据最左使用原则,c1、c2使用了索引。因为查询中没有c3谓词条件,所以索引值使用到c2后就发生了中断,导致只使用了c1、c2列。这里SQL使用了order by排序,但是在执行计划Extra部分未有filesort关键字,说明在索引中按照c3字段顺序读取数据即可。
这里特别留意,虽然索引中的c3字段没有放在索引的最后,但是确实使用到了索引中c2字段的有序特性,因为执行计划的Extra部分未出现"fileasort"关键字。这是为什么呢?这里用到了MySQL5.6版本引入的Index Condition Pushdown (ICP) 优化。其核心思想是使用索引中的字段做数据过滤。我们来整理一下不使用ICP和使用ICP的区别:
如果没有使用ICP优化,其SQL执行步骤为:
1.使用索引列c1,c2获取满足条件的行数据。where c1='2' and c2='2'
2.回表查询数据,使用where c4='2'来过滤数据
3.对数据排序输出
如果使用了ICP优化,其SQL执行步骤为:
1.使用索引列c1,c2获取满足条件的行数据。where c1='2' and c2='2'
2.在索引中使用where c4='2'来过滤数据
3.因为数据有序,直接按顺序取出满足条件的数据
C选项:
mysql> explain select c2,c3 from t1 where c1='2' and c4='2' group by c3,c2; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------------------------------------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_c1234 | idx_c1234 | 3 | const | 2 | 14.29 | Using where; Using index; Using temporary; Using filesort | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-----------------------------------------------------------+
使用的索引长度为3,代表1个字段使用了索引。根据最左使用原则,c1使用了索引。因为查询中没有c2谓词条件,所以索引值使用到c1后就发生了中断,导致只使用了c1列。该SQL执行过程为:
1.在c1列使用索引找到c1='2'的所有行,然后回表使用c4='2'过滤掉不匹配的数据
2.根据上一步的结果,对结果中的c3,c2联合排序,以便于得到连续变化的数据,同时在数据库内部创建临时表,用于存储group by的结果。
C选项扩展:
mysql> explain select c2,c3 from t1 where c1='2' and c4='2' group by c2,c3; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_c1234 | idx_c1234 | 3 | const | 2 | 14.29 | Using where; Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+
使用的索引长度为3,代表1个字段使用了索引。根据最左使用原则,c1使用了索引。
D选项:
mysql> explain select c2,c3 from t1 where c1='2' and c5='2' order by c2,c3; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+------------------------------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_c1234 | idx_c1234 | 3 | const | 2 | 14.29 | Using index condition; Using where | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+------------------------------------+
使用的索引长度为3,代表1个字段都使用了索引。根据最左使用原则,c1使用了索引。因为查询中没有c2谓词条件,所以索引值使用到c1后就发生了中断,导致只使用了c1列。
D选项扩展:
mysql> explain select c2,c3 from t1 where c1='2' and c5='2' order by c3,c2; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_c1234 | idx_c1234 | 3 | const | 2 | 14.29 | Using index condition; Using where; Using filesort | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+----------------------------------------------------+
使用的索引长度为3,代表1个字段都使用了索引。根据最左使用原则,c1使用了索引。因为查询中没有c2谓词条件,所以索引值使用到c1后就发生了中断,导致只使用了c1列。
E选项:
mysql> explain select c1,c2,c3,c4,c5 from t1 where c1='2' and c2='2' and c5='2' order by c2,c3; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+------------------------------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_c1234 | idx_c1234 | 6 | const,const | 2 | 14.29 | Using index condition; Using where | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+------------------------------------+
使用的索引长度为6,代表2个字段都使用了索引。根据最左使用原则,c1、c2使用了索引。这里SQL使用了order by排序,但是在执行计划Extra部分未有filesort关键字,说明在索引中按照c3字段顺序读取数据即可(c2是常量)。
F选项:
mysql> explain select c1,c2,c3,c4,c5 from t1 where c1>'4' and c2='2' and c3='2' and c4='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | t1 | NULL | range | idx_c1234 | idx_c1234 | 3 | NULL | 1 | 20.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
使用的索引长度为3,代表1个字段都使用了索引。根据最左使用原则,c1使用了索引。这里c1使用了不等值查询,导致后面的c2查询无法使用索引。该案例非常值得警惕,谓词条件中含有等值查询和范围查询时,如果范围查询在索引前面,则等值查询将无法使用索引;如果等值查询在前面,范围查询在后面,则都可以使用到索引。
(三)如何创建复合索引
复合索引创建的难点在于字段顺序选择,我的观点如下:
- 如果存在等值查询和排序,则在创建复合索引时,将等值查询字段放在前面,排序放在最后面;
- 如果存在多个等值查询,则选择性好的放在前面,选择性差的放在后面;
- 如果存在等值查询、范围查询、排序。等值查询放在最前面,范围查询和排序需根据实际情况决定索引顺序;
此外,《阿里巴巴Java开发手册-2020最新嵩山版》中有几个关于复合索引的规约,我们可以看一下:
1.如果有order by的场景,请注意利用索引的有序性。order by后的字段是组合索引的一部分,并且放在组合索引的最后,避免出现filesort的情况,影响查询性能。
正例:where a=? b=? order by c; 索引a_b_c
反例:索引如果存在范围查询,那么索引有序性将无法使用。如:where a>10 order by b; 索引a_b无法排序。
2.建复合索引的时候,区分度最高的在最左边,如果where a=? and b=?,a列的值几乎接近唯一值,那么只需建单列索引idx_a即可。
说明:存在等号和非等号混合判断条件时,在建索引时,请把等号条件的列前置。如:where c>? and d=?,那么即使c的区分度
更高,也必须把d放在索引的最前列,即创建索引idx_d_c。
实验:应该如何创建复合索引
在有的文档里面讲到过复合索引的创建规则:ESR原则:精确(Equal)匹配的字段放在最前面,排序(Sort)条件放中间,范围(Range)匹配的字段放在最后面。接下来我们来探索一下该方法是否正确。
例子:存在员工表employees
mysql> show create table employees;
+-----------+-------------------------------
| Table | Create Table
+-----------+-------------------------------------
| employees | CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
+-----------+-------------------------------------
-- 数据量约30万行
mysql> select count(*) from employees;
+----------+
| count(*) |
+----------+
| 300024 |
+----------+
现在需要查询1998年后入职的first_name为"Ebbe"员工,并按照出生日期升序排序。
其SQL语句如下:
select emp_no,birth_date,first_name,last_name,gender,hire_date from employees where hire_date >= '1998-01-01' and first_name = 'Ebbe' order by birth_date;
为了优化该SQL语句的性能,需要在表上创建索引,为了保证where与order by都使用到索引,决定创建复合索引,有如下创建顺序:
(A)hire_date,first_name,birth_date
(B)hire_date,birth_date,first_name
(C)first_name,hire_date,birth_date
(D)first_name,birth_date,hire_date
(E)birth_date,first_name,hire_date
(F)birth_date,hire_date,first_name
确认哪种顺序创建索引是最优的。
Note:
1.date类型占3个字节的空间,hire_date和 birth_date都占用3个字节的空间。
2.first_name是变长字段,多使用2个字节,如果允许为NULL值,还需多使用1个字节,占用16个字节
A选项:hire_date,first_name,birth_date
create index idx_a on employees(hire_date,first_name,birth_date);
其执行计划如下:
+----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+ | 1 | SIMPLE | employees | NULL | range | idx_a | idx_a | 19 | NULL | 5678 | 10.00 | Using index condition; Using filesort | +----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+
这里key_len长度为19,令人不解,hire_date是非等值查询,理论上key_len应该为3,通过使用MySQL workbench查看执行计划,也可以发现索引只使用了hire_date列(如下图)。为什么会是19而不是3呢?实在令人费解,思考了好久也没有想明白,如有知道,望各位大神不吝解答。
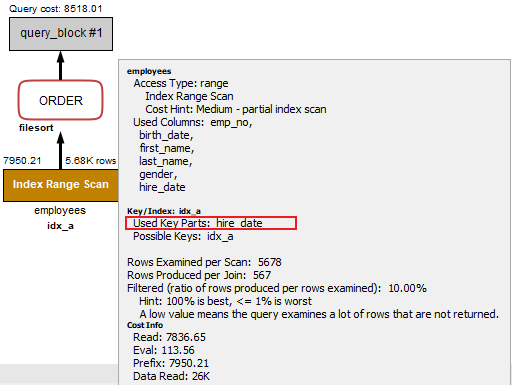
B选项:hire_date,birth_date,first_name
为避免干扰,删除上面创建的索引idx_a,然后创建idx_b。
create index idx_b on employees(hire_date,birth_date,first_name);
其执行计划如下:
+----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+ | 1 | SIMPLE | employees | NULL | range | idx_b | idx_b | 3 | NULL | 5682 | 10.00 | Using index condition; Using filesort | +----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+
这里key_len长度为3,hire_date是非等值查询,导致后面的索引列无法使用到。
C选项:first_name,hire_date,birth_date
为避免干扰,删除上面创建的索引idx_b,然后创建idx_c。
create index idx_c on employees(first_name,hire_date,birth_date);
其执行计划如下:
+----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+ | 1 | SIMPLE | employees | NULL | range | idx_c | idx_c | 19 | NULL | 5 | 100.00 | Using index condition; Using filesort | +----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+---------------------------------------+
这里key_len长度为19,first_name是等值查询,可以继续使用hire_date列,因为hire_date列是非等值查询,导致索引无法继续使用birth_date。
D选项:first_name,birth_date,hire_date
为避免干扰,删除上面创建的索引idx_c,然后创建idx_d。
create index idx_d on employees(first_name,birth_date,hire_date);
其执行计划如下:
+----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | employees | NULL | ref | idx_d | idx_d | 16 | const | 190 | 33.33 | Using index condition | +----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-----------------------+
这里key_len长度为16,first_name是等值查询,在谓词过滤中未使用birth_date,导致只有first_name列使用上索引,但是birth_date列用于排序,上面执行计划显示SQL最终并没有排序,说明数据是从索引按照birth_date有序取出的。
E选项:birth_date,first_name,hire_date
为避免干扰,删除上面创建的索引idx_d,然后创建idx_e。
create index idx_e on employees(birth_date,first_name,hire_date);
其执行计划如下:
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299468 | 3.33 | Using where; Using filesort | +----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
这里未使用到索引,说明排序列放在复合索引的最前面是无法被使用到的。
F选项:birth_date,hire_date,first_name
为避免干扰,删除上面创建的索引idx_e,然后创建idx_f。
create index idx_f on employees(birth_date,hire_date,first_name);
其执行计划如下:
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299468 | 3.33 | Using where; Using filesort | +----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
与E选项一样,这里未使用到索引,说明排序列放在复合索引的最前面是无法被使用到的。
通过上面的6个索引测试,我们发现,等值查询列和范围查询列放在复合索引前面,复合索引都能被使用到,只是使用到的列可能不一样。哪种方式创建索引最好呢?MySQL的查询优化器是基于开销(cost)来选择最优的执行计划的,我们不妨来看看上面的6个索引的执行开销。
索引 开销cost
---------- ------------
idx_a 8518
idx_b 8524
idx_c 13
idx_d 228
idx_e 78083
idx_f 78083
通过上面的开销,可以看到:
- idx_a和idx_b:索引使用范围查询字段开头,导致索引只能使用到第一列,无法消除排序,导致开销较大;
- idx_c和idx_d:索引使用等值查询字段开头,范围查询和排序位于后面,开销是最小的;
- idx_e和idx_f :索引使用排序字段开头,导致索引无法被使用到,走的全表扫描,开销巨大。
更进一步,idx_c和idx_d如何选择呢?idx_c使用索引进行等值查询+范围查询,然后对数据进行排序;idx_d使用索引进行等值查询+索引条件下推查询,然后按照顺序直接获取数据。两种方式各有优劣,我们不妨再来看一个例子:
把上面6个索引都加到表上,看看如下SQL会选择哪个索引。
mysql> show index from employees; +-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | employees | 0 | PRIMARY | 1 | emp_no | A | 299468 | NULL | NULL | | BTREE | | | | employees | 1 | idx_a | 1 | hire_date | A | 5355 | NULL | NULL | | BTREE | | | | employees | 1 | idx_a | 2 | first_name | A | 290745 | NULL | NULL | | BTREE | | | | employees | 1 | idx_a | 3 | birth_date | A | 299468 | NULL | NULL | | BTREE | | | | employees | 1 | idx_b | 1 | hire_date | A | 6237 | NULL | NULL | | BTREE | | | | employees | 1 | idx_b | 2 | birth_date | A | 297591 | NULL | NULL | | BTREE | | | | employees | 1 | idx_b | 3 | first_name | A | 299468 | NULL | NULL | | BTREE | | | | employees | 1 | idx_c | 1 | first_name | A | 1260 | NULL | NULL | | BTREE | | | | employees | 1 | idx_c | 2 | hire_date | A | 293517 | NULL | NULL | | BTREE | | | | employees | 1 | idx_c | 3 | birth_date | A | 299468 | NULL | NULL | | BTREE | | | | employees | 1 | idx_d | 1 | first_name | A | 1218 | NULL | NULL | | BTREE | | | | employees | 1 | idx_d | 2 | birth_date | A | 294525 | NULL | NULL | | BTREE | | | | employees | 1 | idx_d | 3 | hire_date | A | 298095 | NULL | NULL | | BTREE | | | | employees | 1 | idx_e | 1 | birth_date | A | 4767 | NULL | NULL | | BTREE | | | | employees | 1 | idx_e | 2 | first_name | A | 292761 | NULL | NULL | | BTREE | | | | employees | 1 | idx_e | 3 | hire_date | A | 299468 | NULL | NULL | | BTREE | | | | employees | 1 | idx_f | 1 | birth_date | A | 4767 | NULL | NULL | | BTREE | | | | employees | 1 | idx_f | 2 | hire_date | A | 297864 | NULL | NULL | | BTREE | | | | employees | 1 | idx_f | 3 | first_name | A | 299468 | NULL | NULL | | BTREE | | | +-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
SQL1
mysql> explain select emp_no,birth_date,first_name,last_name,gender,hire_date from employees where hire_date >= '1998-01-01' and first_name = 'Ebbe' order by birth_date; +----+-------------+-----------+------------+-------+-------------------------+-------+---------+------+------+----------+---------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+-------------------------+-------+---------+------+------+----------+---------------------------------------+ | 1 | SIMPLE | employees | NULL | range | idx_a,idx_b,idx_c,idx_d | idx_c | 19 | NULL | 5 | 100.00 | Using index condition; Using filesort | +----+-------------+-----------+------------+-------+-------------------------+-------+---------+------+------+----------+---------------------------------------+
这里MySQL自动选择了idx_c,是因为first_name+hire_date两个字段已经将数据过滤了只有5行,由于数据少,排序非常快。反之,如果选择idx_d,则需要先通过first_name字段过滤出符合条件的190行数据,然后再使用hire_date筛选数据,工作量较大。
SQL2
mysql> explain select emp_no,birth_date,first_name,last_name,gender,hire_date from employees where hire_date >= '1980-01-01' and first_name = 'Ebbe' order by birth_date; +----+-------------+-----------+------------+------+-------------------------+-------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+-------------------------+-------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | employees | NULL | ref | idx_a,idx_b,idx_c,idx_d | idx_d | 16 | const | 190 | 50.00 | Using index condition | +----+-------------+-----------+------------+------+-------------------------+-------+---------+-------+------+----------+-----------------------+
如果选择idx_c,first_name+hire_date两个字段通过索引过滤数据之后,数据量较大,导致排序非常慢。MySQL自动选择了idx_d,通过索引的first_name列过滤数据,并通过索引条件下推过滤hire_date字段,然后从索引中有序的取出数据,相对来说,由于使用idx_d无需排序,速度会更快。
(四)复合索引总结
1.复合索引的创建,如果存在多个等值查询,则将选择性好的列放在最前面,选择性差的列放在后面;
2.复合索引的创建,如果涉及到等值查询和范围查询,不管非等值查询的列的选择性如何好,等值查询的字段要放在非等值查询的前面;
3.复合索引的创建,如果涉及到等值查询和范围查询和排序(order by、group by),则等值查询放在索引最前面,范围查询和排序哪个在前,哪个在后,需要根据实际场景决定。如果范围查询在前,则无法使用到索引的有序性,需filesort,适用于返回结果较少的SQL,因为结果少则排序开销小;如果排序在前,则可以使用到索引的有序性,但是需要回表(或者索引条件下推)去查询数据,适用于返回结果较多的SQL,因为无需排序,直接取出数据。
4.复合索引的创建,一定不能把order by、group by的列放在索引的最前面,因为查询中总是where先于order by执行;
5.使用索引进行范围查询会导致后续索引字段无法被使用,如果有排序,无法消除filesort排序。例子:a_b_c索引,where a>? and b = ? order by c,则a可以被使用到,b无法被使用,c字段需filesort。
总结
到此这篇关于MySQL复合索引的文章就介绍到这了,更多相关MySQL复合索引内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!