golang性能优化笔记(二)
背景
基于前次的文章,继续对这个库进行力所能及的优化。
现在,我们对于golang优化的基础有了一些基础的理解。
比如:
- 结合benchmark与pprof
- 清理了代码中出现的重复逻辑
- 初步探索了栈与指针对于内存和性能的影响
我们继续来对代码进行优化,具体方法如下:
Benchmark
首先,为了更好的理解我们之前的结果,很体力活的为每个函数都加了Benchmark测试。
指针转化
BenchmarkSm2P256FromBig-16 3303530 361 ns/op 128 B/op 2 allocs/op
BenchmarkSm2P256ToBig-16 6051643 199 ns/op 32 B/op 1 allocs/op
这里我们发现反复的指针和类型转化会在代码中消耗很多内存,cpu操作,时间。因此第一步我们把非必要的类型转化都避免了。
before
func somefunc(a type a) type b{
Ia = convert(a)
Ia.add
....
return convert'(Ia)
}
after
func somefunc(a type a) type b{
...
return a.add
}
另外一种是通过特殊值做等效处理。 比如代码中有指针转换后,转化后的对象调用equals 的函数。
我们可以进行逻辑等效转化
before
return covert(A).Equals(covert(B))
after
return A - B == 0
栈(一)
当然, 随着我们清理了指针,我们也进行了调整
func sum (*sum, *a, *b) -> func sum(a,b) sum
这里的考虑是减少寄存器和主存的交互,当然这里从效果上来看是对的。后边会不会继续更新,有待商榷。
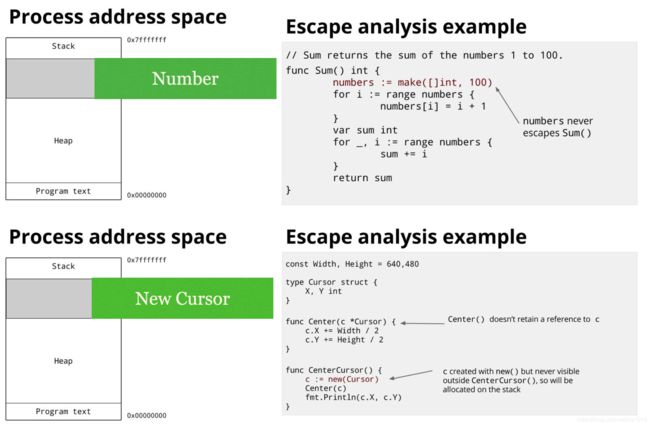
这里我们发现改前代码中,存在如下情况,那么参考逃逸分析如上,发现有类似如下图的逃逸可能。

因此把代码进行了调整,把临时数据尽可能放在栈上。
栈(二)
然后我们发现了一个问题如下:(这是优化中版本发现的一个问题)
BenchmarkSm2P256PointAdd-16 100000000 11.2 ns/op 0 B/op 0 allocs/op
BenchmarkSm2P256PointSub-16 19156359 58.5 ns/op 0 B/op 0 allocs/op
这里我们发现, sub(a-b) = sum(a+(0-b))
BenchmarkSm2P256Add-16 52931374 20.6 ns/op 0 B/op 0 allocs/op
BenchmarkSm2P256Sub-16 45872376 25.9 ns/op 0 B/op 0 allocs/op
也就是这里多了一步sub,缺多了40多ns, 于是怀疑我们多有一步栈调用(这里看到数值上升,是因为我们采用了实际数据进行对比)也就是减少函数调用,但是我们发现加法减法之间的时间差减小了。
BenchmarkSm2P256PointAdd-16 459354 2454 ns/op 0 B/op 0 allocs/op
BenchmarkSm2P256PointSub-16 468586 2451 ns/op 0 B/op 0 allocs/op
栈(三)
我们观察一段代码, 这段代码的每个函数的cpu操作数为 2 + 2 +1 = 5, 但是实际上这段代码的cpu操作数为10。 目前没有想到好的优化方案。同时侧面证明了,反复的指针和类型转化会在代码中消耗很多内存,cpu操作,时间。 感受一下程序积存栈出入的时间损耗吧。
xa := sm2P256FromBig(x) // 2
xb := sm2P256FromBig(y) // 2
xz := sm2P256Mul(xa, xb) // 0
sm2P256ToBig(xz) //1
特殊值(一)
通过数学计算和函数参考,对内部函数进行优化。
比如P256Scalar 这个函数, 实际上是计算a*b, b in [0,1,2,3,4,5,6,7,8]
BenchmarkSm2P256Mul-16 8314744 135 ns/op 0 B/op 0 allocs/op
乘法需要135ns左右。加法位运算大概20ns
BenchmarkSm2P256Add-16 58533414 20.2 ns/op 0 B/op 0 allocs/op
参考了数学逻辑,实现了 3a, 4a, 8a 三个独立特殊的位运算的基础上。
修改了里本来的乘法逻辑为:
b 0 return 0
b 1 return a
b 2 return a + a (20 ns)
b 3 位运算 3a
b 4 位运算 4a
b 5 4a + a
b 6 3a + 3a
b 7 3a + 4a ?? 或者 8a - a
b 8 位运算 8a
结果
上次:
BenchmarkSM2Sign-16 4339 285344 ns/op 5404 B/op 117 allocs/op
BenchmarkSM2Sign-16 3986 276869 ns/op 5429 B/op 117 allocs/op
BenchmarkSM2Sign-16 4404 276076 ns/op 5431 B/op 117 allocs/op
BenchmarkSM2Sign-16 3960 274832 ns/op 5422 B/op 117 allocs/op
BenchmarkSM2Sign-16 3876 277349 ns/op 5413 B/op 117 allocs/op
BenchmarkSM2Verify-16 808 1461962 ns/op 78744 B/op 1628 allocs/op
BenchmarkSM2Verify-16 829 1450970 ns/op 77440 B/op 1594 allocs/op
BenchmarkSM2Verify-16 811 1447418 ns/op 77846 B/op 1601 allocs/op
BenchmarkSM2Verify-16 812 1420193 ns/op 74632 B/op 1538 allocs/op
BenchmarkSM2Verify-16 832 1436850 ns/op 76475 B/op 1572 allocs/op
现在:
BenchmarkSM2Sign-16 3775 269895 ns/op 5445 B/op 117 allocs/op
BenchmarkSM2Sign-16 3973 273791 ns/op 5422 B/op 117 allocs/op
BenchmarkSM2Sign-16 3822 275578 ns/op 5445 B/op 117 allocs/op
BenchmarkSM2Sign-16 3914 271936 ns/op 5421 B/op 117 allocs/op
BenchmarkSM2Sign-16 3950 276252 ns/op 5405 B/op 117 allocs/op
BenchmarkSM2Verify-16 1022 1111437 ns/op 9192 B/op 173 allocs/op
BenchmarkSM2Verify-16 988 1116904 ns/op 9200 B/op 174 allocs/op
BenchmarkSM2Verify-16 1042 1101868 ns/op 9063 B/op 172 allocs/op
BenchmarkSM2Verify-16 1006 1126834 ns/op 9087 B/op 173 allocs/op
BenchmarkSM2Verify-16 1035 1105716 ns/op 8847 B/op 172 allocs/op
至此我们的优化:
BenchmarkSM2Sign 270000/300000 = 90%
BenchmarkSM2Verify 1100000/1600000 = 68%