启动 群集_Redis群集
会不会有那么一天,生活可以简单到每天清早踏上一辆载着鲜花的脚踏车,微笑着穿过窄窄的街巷,为爱花的人送去芬芳,为需要知识的你送去帮助。
简介
在现在的互联网大潮中,NoSOL可谓家喻户晓,Redis作为NoSOL大军中极其重要的一员,是我们走向架构道路的一条必经之路。本章的目标,就是了解关系型数据库与非关系型数据库的区别,掌握Redis的安装与群集部署等相关知识。
本章重点
Redis 安装配置
Redis 群集工作原理
Redis 群集部署
一,Redis介绍
Redis 数据库是一个非关系型数据库,在正式学习Redis之前,我们先来了解关系型数据库与非关系型数据库的概念。
1.关系型数据库与非关系型数据库
数据库按照其结构可以分为关系型数据库与其他数据库,而这些其他数据库我们将其统称为非关系型数据库。
关系型数据库
关系型数据库是一个结构化的数据库,创建在关系模型基础上,一般面向记录。它借助于集合代数等数学概念和方法来处理数据库中的数据.关系模型指二维表格模型,因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。现实世界中,各种实体与实体之间的各种联系都可以用关系模型来表示,SQL(Structured Query Language,结构化查询语言)语句就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作。
主流的关系型数据库包括Oracle.MySOL、SOL Server、Microsoft Access、DB2等。
非关系型数据库
NoSQL(NoSQL=Not Only SQL).意思是“不仅仅是SOL”,是非关系型数据库的总称。主流的NoSQL数据库有Redis.MongBD、Hbase.CouhDB等。以上这些数据库,它们的存储方式,存储结构以及使用的场景都是完全不同的。所以我们认为它是一个非关系型数据库的集合,而不是像关系型数据库一样,是一个统称。换言之,主流的关系型数据库以外的数据库,都是非关系型的。NoSQL数据库凭借着其非关系型、分布式,开源和横向扩展等优势,被认为是下一代数据库产品。
非关系型数据库产生背景
关系型数据库已经诞生很久了,而且我们一直在使用,没有什么问题。面对这样的情况,为什么还会产生非关系型数据库?下面我们就来介绍一下非关系型数据库产生的背景。
随着Web2.0网站的兴起,关系型数据库在应对Web2.0网站,特别是海量数据和高并发的SNS(Social Networking Services,即社交网络服务)类型的Web2.0纯动态网站时,暴露出很多难以解决的问题。例如以下三高问题。
1)High performance——对数据库高并发读写需求Web2.0网站会根据用户的个性化信息来实时生成动态页面和提供动态信息,因此,无法使用动态页面静态化技术。所以数据库的并发负载非常高,一般会达到10000次/s以上的读写请求。关系型数据库对于上万次的查询请求还是可以勉强支撑的,当出现上万次的写数据请求时,硬盘I/O就已经无法承受了。对于普通的BBS网站,往往也会存在高并发的写数据请求,如明星鹿晗在微博上公布恋情,结果因为流量过大而引发微博瘫痪。
2)Huge Storage——对海量数据高效存储与访问需求
类似于Facebook、Friendfeed这样的SNS网站,每天会产生大量的用户动态信息。例如Friendfeed,一个月就会产生2.5亿条用户动态信息,对于关系型数据库来说,在一个包含2.5亿条记录的表中执行SOL查询,效率是非常低的。
3)High Scalability&&High Availability——对数据库高可扩展性与高可用性需求在Web架构中,数据库是最难进行横向扩展的。当应用系统的用户量与访问量与日俱增时,数据库是没办法像Web服务一样,简单地通过添加硬件和服务器节点来扩展其性能和负载能力的。尤其对于一些需要24h对外提供服务的网站来说,数据库的升级与扩展往往伴随着停机维护与数据迁移,其工作量是非常庞大的。
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给Web2.0的数据库发展带来新的思路。让关系型数据库关注在关系上,非关系型数据库关注在存储上。
二,Redis 基础
了解了关系型数据库与非关系型数据库之后,我们重点来学习非关系型数据库Redis的相关知识。
1.Redis简介
Redis是一个开源的、使用C语言编写、支持网络、可基于内存亦可持久化的日志型,key-value(键值对)数据库,是目前分布式架构中不可或缺的一环。
Redis 服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis 进程,而Redis的实际处理速度则完全依靠于主进程的执行效率。若在服务器上只运行一个Redis 进程,当多个客户端同时访问时,服务器的处理能力会有一定程度的下降:若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。也就是说,在实际生产环境中,需要根据实际的需求来决定开启多少个Redis 进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程;若CPU资源比较紧张,采用单进程即可。
Redis具有以下几个优点:
具有极高的数据读写速度,数据读取的速度最高可达到110000次/s.数据写入速度最高可达到81000次/s。
支持丰富的数据类型,不仅仅支持简单的key-value数据类型,还支持Strings.Lists.Hashes.Sets及Ordered Sets等数据类型操作。
支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
原子性,Redis所有操作都是原子性的。
支持数据备份,即master-salve模式的数据备份。
Redis作为基于内存运行的数据库,缓存是其较常应用的场景之一,除此之外,Redis常见应用场景还包括获取最新N个数据的操作,排行榜类应用、计数器应用、存储关系、实时分析系统、日志记录等,
2.Redis安装部署
Redis的安装相对于其他服务来说比较简单,首先需要到Redis 官网(https://www.redis.io)下载相应的源码软件包,然后上传至Linux系统的服务器中进行解压.安装。本章中以redis-3.2.9.tar.gz为例进行Redis安装和配置的讲解。
通常情况下在Linux系统中进行源码编译安装,需要先执行./configure 进行环境检查与配置,从而生成Makefile文件,再执行make&&make install 命令进行编译安装。而Redis源码包中直接提供了Makefile文件,所以在解压完软件包后,可直接进入解压后的软件包目录,执行make与make install命令进行安装即可。



在安装过程中,若想更改默认的安装路径,可使用以下命令格式来进行安装操作。
make PREFIX=安装路径 install
make install只是安装了二进制文件到系统中,并没有启动脚本和配置文件。软件包中默认提供了一个install_server.sh脚本文件,通过该脚本文件可以设置Redis服务所需要的相关配置文件。当脚本运行完毕,Redis服务就已经启动,默认侦听端口为6379。

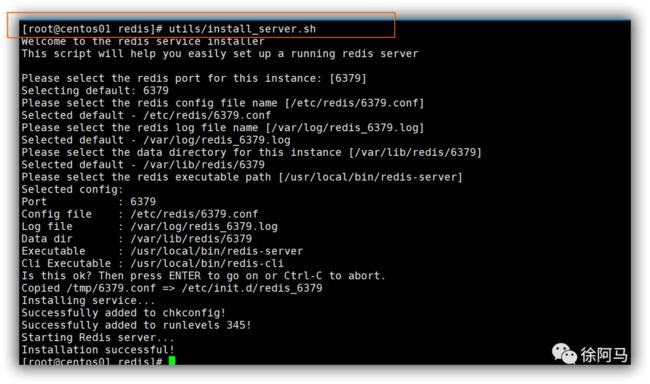

安装完成后,可通过Redis的服务控制脚本/etc/init.d/redis_6379来对Redis 服务进行控制,如停止Redis 服务、启动Redis 服务、重启Redis服务、查看Redis 运行状态。

3.配置参数
Redis 主配置文件为/etc/redis/6379.conf,由注释行与设置行两部分组成。与大多数Linux配置文件样,注释性的文字以“#”开始,包含了对相关配置内容进行的说明和解释。注释行与空行以外的内容即为设置行。可根据生产环境的需求调整相关参数,如:







除了上述配置参数外,Redis 主配置文件中还包含很多其他的配置参数,具体内容如下:

三,Redis命令工具
Redis 软件提供了多个命令工具,当Redis安装时,所包含的软件工具会同时被安装到系统中,在系统中可以直接使用。这些命令工具的作用分别如下所示:
redis-server:用于启动Redis的工具。
edis-benchmark:用于检测Redis在本机的运行效率。
redis-check-aof:修复AOF持久化文件。
redis-check-rob:修复RDB持久化文件。
redis-setinel;redis-server文件的软链接。
本小节我们只讲解 redis-cli.redis-benchmark命令工具的使用。
1.redis-cli命令行工具
Redis 数据库系统也是一个典型的C/S(客户端/服务器端)架构的应用,要访问Redis 数据库需要使用专门的客户端软件。Redis 服务的客户端软件就是其自带的redis-cli命令行工具。使用redis-cli连接指定数据库,连接成功后会进入提示符为“远程主机IP地址:端口号>”的数据库操作环境。
用户可以输入各种操作语句对数据库进行管理,如执行ping命令可以检测Redis服务是否启动。

在进行数据库连接操作时,可以通过选项来指定远程主机上的Redis数据库,命令语法为redis-cli -h host -p port -a password,其中,-h指定远程主机,-p指定Redis服务的端口号,-a指定密码。
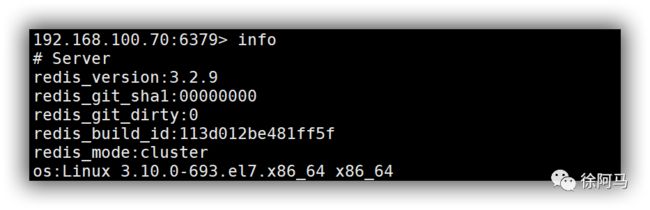
若不添加任何选项,表示连接本机上的Redis数据库;若未设置数据库密码,可以省略-a选项。例如,执行以下命令可连接到主机为192.168.10.161、端口为6379的Redis数据库,并查看Redis 服务的统计信息。若要退出数据库操作环境,执行“exit”或“quit”命令即可返回原来的Shell环境。
2.redis-benchmark测试工具
redis-benchmark 是官方自带的Redis 性能测试工具,可以有效地测试Redis服务的性能。基本的测试语法为
redis-benchmark [option] [option value] 常用选项如下所示。
-h:指定服务器主机名。
-p:指定服务器端口。
-s:指定服务器socket。
-c:指定并发连接数。
-n:指定请求数。
-d:以字节(B)的形式指定SET/GET值的数据大小。
-k:1=keep alive 0=reconnect。
-r:SET/GET/NCR 使用随机key.SADD使用随机值。
-P:通过管道传输请求。
-q:强制退出redis。仅显示query/sec值。
--csv;以CSV格式输出。>-1:生成循环,永久执行测试。
-t:仅运行以逗号分隔的测试命令列表。
3.Redis数据库常用命令
前面提到,Redis 数据库采用key-value(键值对)的数据存储形式。所使用的命令是set与get命令。
set:存放数据,基本的命令格式为set key value。
get:获取数据,基本的命令格式为get key。
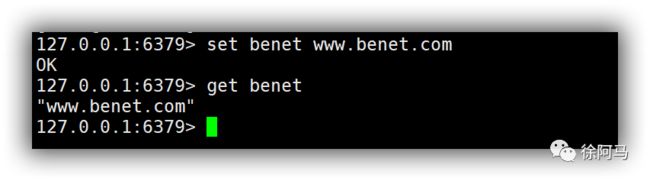
例如,在Redis的命令行模式下执行“set benet www.benet.com",表示在当前数据库下存放一个key为benet,value为www.benet.com的数据,而执行“get benet“命令即可查看刚才存放的数据。
除了数据存储与获取命令,Redis数据库还包含其它常见的数据管理命令。
key相关命令
在Redis 数据库中,与key相关的命令主要包含以下几种。
1)keys
使用keys命令可以取符合规则的键值列表,通常情况可以结合*、?等选项来使用。
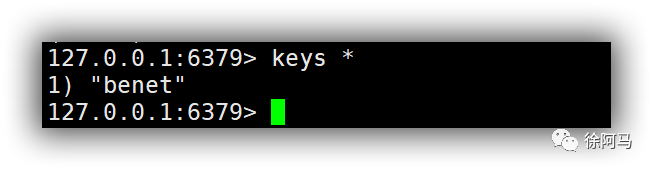
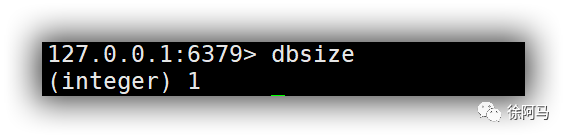
2)统计符合规则的键值列表的个数
3)exists
使用exists命令可以判断键值是否存在。
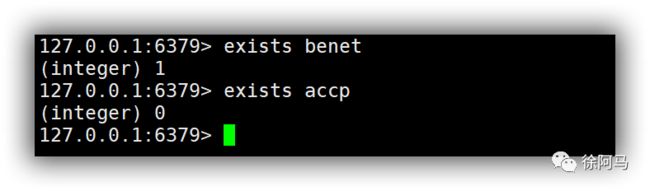
如果存在,返回1,不存在,返回0
4)rename
修改key名字

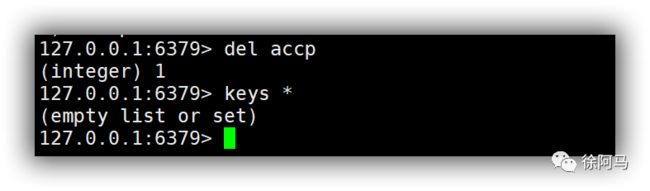
5)del
使用del命令可以删除当前数据库的指定key。
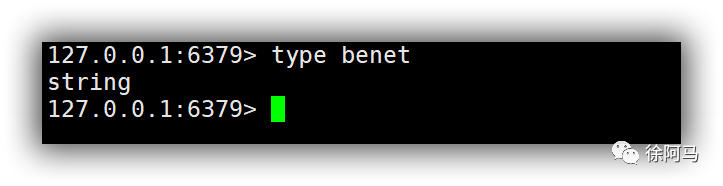
6)type
使用type命令可以获取key对应的value值类型。
多数据库常用命令
1.多数据库间切换
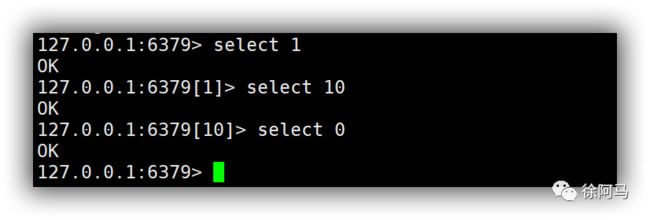
Redis 支持多数据库,Redis在没有任何改动的情况下默认包含16个数据库,数据库名称是用数字0~15来依次命名的。使用select命令可以进行Redis的多数据库之间的切换,命令格式为“select index”。其中,index表示数据库的序号。而使用redis-cli连接Redis数据库后,默认使用的是序号为0的数据库。
如下所示,使用select命令切换数据库后,会在前端的提示符中显示当前所在的数据库序号,如“127.0.0.1:6379[10]>”表示当前使用的是序号为10的数据库;若当前使用的数据库是序号为0的数据库,提示符中则不显示序号,如“127.0.0.1:6379>”表示当前使用的是序号为0的数据库。
2.多数据库间移动数据
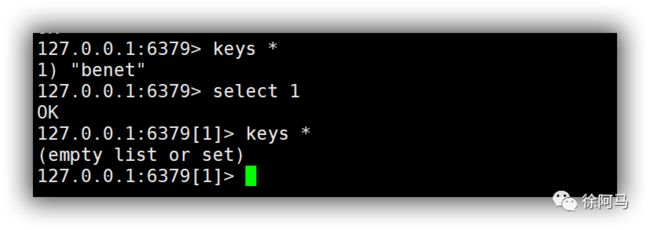
Redis的多数据库在一定程度上是相对独立的。例如,在数据库0上面存放的benet的数据,在其他的1~15的数据库上是无法查看到的。
Redis数据库提供了一个move命令,其可以进行多数据库的数据移动。命令的基本语法格式为
“move key dbindex”.其中,key表示当前数据库的目标键,db index表示目标数据库的序号。具体操作方法如下所示。
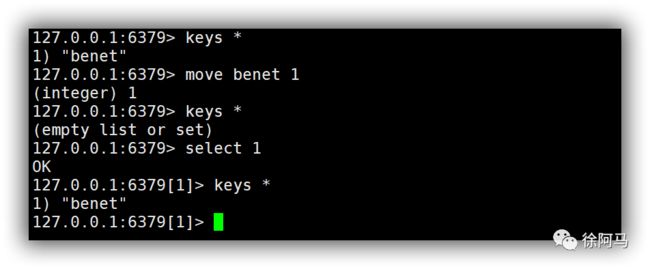
3.清除数据库内数据
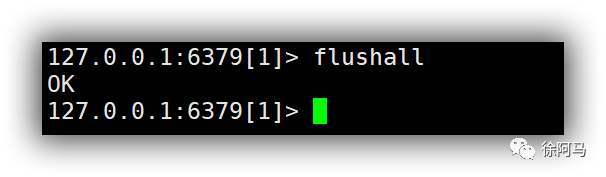
Redis 数据库的整库数据删除主要分为两个部分:清空当前数据库的数据,使用FLUSHDB命令实现;清空所有数据库的数据,使用FLUSHALL命令实现。但是,数据清空操作比较危险,生产环境下一般不建议使用。
四,Redis 群集
Redis 3.0版本以上开始支持cluster,采用的是hash slot(hash槽),可以将多个Redis实例整合在一起,形成一个群集,也就是将数据分散到群集的多台机器上。
Redis群集原理
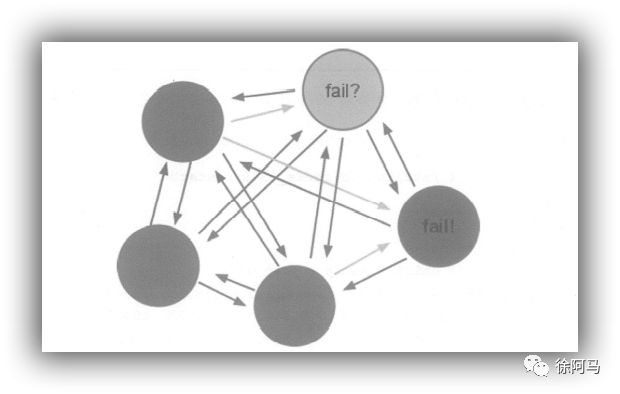
Redis Cluster是一个无中心的结构,如图所示。每个节点都保存数据和整个群集的状态。每个节点都会保存其他节点的信息,知道其他节点所负责的槽,并且会与其他节点定时发送心跳信息,能够及时感知群集中异常的节点。

当客户端向群集中任一节点发送与数据库键有关的命令时,接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己。如果键所在的槽正好指派给了当前节点,那么节点直接执行这个命令;如果键所在的槽并没有指派给当前节点,那么节点会向客户端返回一个MOVED错误,指引客户端转向(redirect)正确的节点,并再次发送之前想要执行的命令。
群集角色有Master和Slave。Master 之间分配slots,一共16384个slot。Slave向它指定的Master同步数据,实现备份。当其中的一个Master 无法提供服务时,该Master的Slave 将提升为Master.以保证群集间slot的完整性。当其中的某一个Master 和它的Slave都失效,导致了slot 不完整,群集失效,这时就需要人工去处理了。
群集搭建好后,群集中的每个节点都会定期地向其他节点发送PING消息,如果接收PING消息的节点没有在规定的时间内返回PONG消息,那么发送PING消息的节点就会将其标记为疑似下线(probable fail,PFAL)。各个节点会通过互相发送消息的方式来交换群集中各个节点的状态信息。如果在一个群集里面,半数以上的主节点都将某个主节点x报告为疑似下线,那么这个主节点x将被标记为已下线(FAIL),同时会向群集广播一条关于主节点×的FAIL消息,所有收到这条FAlL消息的节点都会立即将主节点×标记为已下线。
当需要减少或者增加群集中的机器时,我们需要将已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点),并且将相关槽所属的键值对从源节点移动到目标节点。
Redis群集的重新分片操作是由Redis的群集管理软件redis-trib负责执行的,不支持自动的分片。
而且需要自己计算从哪些节点上迁移多少Slot。在重新分片的过程中,群集不需要下线,并且源节点和目标节点都可以继续处理命令请求。
1.架构细节
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
(2)节点的失效(fail)在群集中超过半数的主(master)节点检测失效时才生效。
(3)客户端与redis 节点直连,不需要中间代理(proxy)层,客户端不需要连接群集所有节点,连接群集中任何一个可用节点即可。
(4)redis-cluster 把所有的物理节点映射到[0-16383]slot 上,cluster 负责维护nodeslotkey。
2.Redis-cluster选举
如图所示,选举过程是群集中所有master参与,如果半数以上master 节点与当前master节点通信超时(cluster-node-timeout),认为当前master 节点挂掉。以下两种情况为整个群集不可用(cluster_state:fail),当群集不可用时,所有对群集的操作都不可用,收到((error)CLUSTERDOWN.The cluster is down)错误。
如果群集任意master 挂掉,且当前master没有slave.则群集进入fail状态,也可以理解成群集的slot映射[O-16383]不完整时进入fail状态。
如果群集中超过半数的master挂掉,无论是否有slave.群集都进入fail状态。
默认情况下,每个群集的节点都使用两个TCP端口,一个是6379,一个是16379,6379服务于客户端的连接,16379用于群集总线,即使用二进制协议的节点到节点通信通道。节点使用群集总线进行故障检测.配置更新、故障转移授权等。如果开启了防火墙,需要开放这两个端口。
五,Redis 群集部署
理解了Redis原理之后,我们来学习Redis群集具体的部署。在本章中我们使用6台服务器搭建Redis 群集,其中3台为master,3台为slave。6台服务器的P地址为:192.168.100.10/24~~192.168.100.60/24;服务器系统均为CentOS系统。群集部署的具体操作步骤主要分为以下几个。
1.安装Redis并修改配置文件
在每一台服务器上都要安装Redis,按照前面的方法安装即可,然后修改配置文件如下。其中每台服务器都要修改,只是IP地址不同而已,其他配置都一样。







在每台服务器上重启redis服务,并查看6379和16379端口是否已经正常开启。

2.使用脚本创建群集
创建群集要用到ruby的一个脚本,在创建群集前,需要先安装ruby的运行环境和ruby的Redis客户端。该操作在其中一台服务器上进行即可。gem命令是提前下载的redis-3.2.0.gem软件包提供的,直接上传即可使用。



使用脚本创建群集
![]()

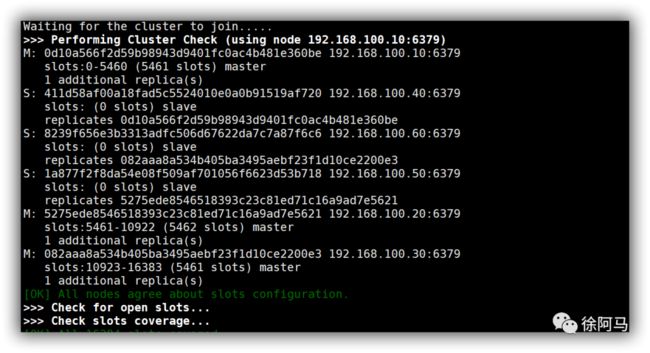
查看群集节点
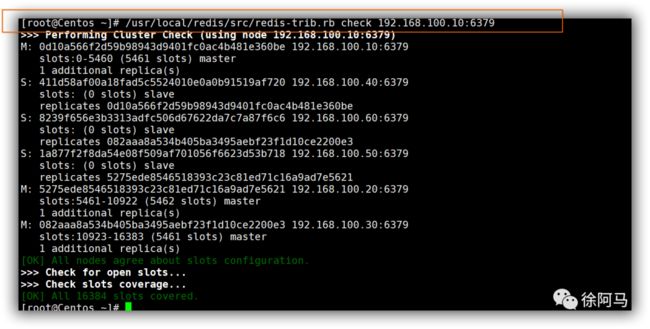
3.测试群集
登录Redis群集,设置键值测试。这里需要跟“-c”参数来激活群集模式。
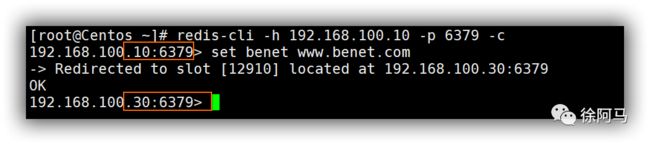
上述过程可以看到登录的是群集中任意一台服务器。当创建键值时,重定向到其他的服务器上,是按照slot分配的。
故事很短,道理很长,学无止境,不忘初心,砥砺前行
微信搜索 “徐阿马” 关注公众号,期待你的关注!
