TensorFlow: A System for Large-Scale Machine Learning
介绍
TensorFlow优势:
支持大规模训练和推理:可使用数百个支持GPU的的服务器进行快速训练。
支持多种平台:大到大型分布式集群,小到移动设备。
灵活、通用:支持实验、研究新的机学习模型,支持系统级别的优化。
表示:
使用统一的数据流图来表示算法中的计算、算法所操作的状态。
与传统的数据流系统不同,TensorFlow允许顶点表示拥有或更新可变状态的计算。
边承载着张量,即多维数组,TensorFlow透明地在分布式计算之间插入适当的通信。
通过在单一编程模型中将计算和状态管理统一起来,TensorFlow允许程序员实验不同的并行化方案,例如,为减少网络拥堵,可将计算卸载到保持了共享状态的服务器上。
还制定了各种协调协议,回应了最近矛盾的结果:异步复制在可扩展学习中是必须的。
背景&动力
要求
1、分布式执行
为什么需要分布式执行?通常,训练数据越多,机器学习算法效果越好。
a、数据集规模较大
图像分类模型—-包含136千兆字节的数字图像的公共ImageNet数据集
语言模型—包含80万字的词汇One Billion Word Benchmark
催生了数据并行的训练方式:以分布式文件系统保存数据,通过一组工作节点处理行数据的不同子集。
b、参数量大
当前最先进的图像分类模型ResNet,使用230万浮点参数将图像分类到1000个类别之一。One Billion Word Benchmark,已被用来训练具有10.4亿参数的语言模型。
分布式执行的好处:
通过多个进程共享模型,增加可用网络带宽,以便多个工作节点同时读取和更新模型。
如何有效使用分布式:
用于模型训练的分布式系统必须有效使用网络。许多可扩展的算法训练模型使用小批量梯度下降,其中工作者读取当前版本的模型和一个小批处理输入示例,计算模型更新以减少那些例子上的损失函数,并将更新应用于模型。当每个工作节点以最新的模型作为起点时,小批量方法是最有效,这需要将大量数据以低延迟传输到工作节点。
2、加速支持
为什么需要加速支持?
机器学习算法的计算通常较为昂贵。例如矩阵乘法和多维卷积,都是高度并行化的,但具有许多数据依赖性,这些数据依赖性需要紧密耦合的实现。
通用的加速支持:
最近的通用GPU提供了大量的、可以在本地内存上操作的内核。 例如,单个NVIDIA Titan X GPU卡具有6 TFLOPS峰值性能。
通用加速支持的效果:
2012年,不同图像分类任务使用16,000个CPU内核耗时三天,使用两个GPU耗时六天。 从那时起,GPU供应商已经创新地支持机器学习:NVIDIA的cuDNN库用于基于GPU的神经网络训练加速了几种流行的图像模型,当版本R4代替R2时,快了2-4倍。
深度学习中的专用加速支持:
Google建立了专门用于机器学习的Tensor处理单元—TPU,与替代方案相比,每瓦性能提高了一个数量级。 Movidius深度学习加速器使用具有自定义矢量处理单元的低功耗Myriad 2处理器,加速了许多机器学习和计算机视觉算法。 Ovtcharov et al为采用现场可编程门阵列(FPGA)的卷积模型取得了显著的性能改进,并节省了功率。
TensorFlow中的加速支持:
因为很难预测下一个用于执行机器学习算法的流行体系结构,我们要求TensorFlow使用针对通用设备抽象的便携式程序模型,并且当新的架构出现时,可将TensorFlow上的操作为了该新架构而专门化。
3、训练 & 推理支持
为什么需要训练&推理支持:
训练、可扩展和高性能推理是在生产中使用模型的一个要求。根据应用的性质,可能需要推理以在交互式服务中产生低延迟的结果,或在断开的移动设备上执行。
如何实现推理训练&支持:
如果该模型很大,可能需要多个服务器来参与每个推理计算,因此需要分布式计算支持。当可以使用相同的代码来定义一个模型同时进行训练和推理时,对开发者很有利。训练和推理需要相近的性能,所以我们喜欢一个通用的、可同时用于训练和推理的优化系统。 因为推理可能是计算密集型的(例如,图像分类模型可能每个图像执行50亿FLOPS),也许会用到GPU加速。
4、扩展性
扩展性的好处:
单机机器学习框架具有可扩展的编程模型,使得用户可用新的方法提高现有技术水平。如对抗学习和深度加强学习。我们寻求一个具有相同能力的系统,允许用户扩展相同的代码以在生产中运行。
如何实现扩展性:
系统必须支持可表达的控制流和“有状态”结构,同时满足其他要求。
相关工作
1、单机框架
许多机器学习任务都只是在配置了GPU的单机上运行。比如,高性能的Caffe在多核CPU、GPU上训练特定的卷积神经网络。Theano允许程序员将模型表达为数据流,并为训练模型生成编译好的代码。Torch在科学计算中很重要,支持在命令执行和内存使用上的细粒度控制。然而,TensorFlow支持分布式执行,其模型近似于Theano中的数据流表达。
2、批量数据流系统
采用了批量数据流系统的框架:
自MapReduce起,批量数据流系统被大量应用于机器学习中。许多最近的系统的致力于提高表达性和性能上。DradLINQ添加高层次的查询语言,相对于MapReduce可支持更复杂的算法。Spark相对于DradLINQ来说,支持将之前算过的数据进行缓存,所以在迭代是机器学习中效果更好。 Dandelion相对于DradLINQ来说,可为GPU、FPGA生成代码。
批量数据流的主要限制:
非批量数据流系统—Naiad
尽管不是一个批量数据流系统,Naiad通过流运算、状态节点、结构化的时间戳(实时数据流)强化了数据流模型,这使得它可同时处理增量更新和迭代式计算。Naiad通过循环数据流图来表达迭代,同可变状态一起,使得它可实现协调时间为毫秒级别的算法。Naid是为稀疏、离散的数据而设计的,不支持GPU,但我们借鉴了3.4节中的实时数据流迭代。
3、参数服务器
什么是参数服务器:
受分布式key-valu存储的启发,参数服务器使用一个服务器集合来管理共享状态,该共享状态被一个数据并行的机器集合更新。不像标准的key-value存储,参数服务器中的写操作是专门用于参数更新的:它通常是一个关联和交换的组合器。如加分配(+ =),即应用于当前参数值并将更新传入以产生新的参数值。
有哪些参数服务器:
参数服务器是一种可扩展的主题模型架构,前代系统DistBe-lief 展示了一个类似的架构,可应用于深度神经网络训练。 Adam项目演示了一种高效的用于训练卷积神经网络的参数服务器架构,Li等人的“参数服务器”在一致性模型、容错和弹性重缩放中增加了创新。 虽然lier怀疑参数服务器可与GPU加速兼容,然而Cui et al最近显示了GeePS,一个与GPU一起使用的专门化参数服务器,可以实现中等规模的集群加速。
MXNet是最近的用于扩展训练参数服务器系统,支持GPU加速,并包括具有许多语言接口的灵活编程模型。 虽然MXNet部分满足我们可扩展性要求,参数服务器是“特权”代码,这使得研究人员很难定制大型模型的处理。
TensorFlow中的参数服务器:
参数服务器架构满足我们的大多数需求要求,我们的DistBelief使用类似Caffe模型那样定义好格式的参数服务器,效果很好。 我们发现这个架构在可扩展方面不够充分,因为添加新的优化算法或者使用非常规模型架构时,需要我们的用户修改参数服务器的实现,而参数服务器的性能使用C ++。虽然一些使用该系统的从业者已经习惯于做出这些变,但大多数习惯使用高级语言来编写模型,如Python和Lua。高性能参数服务器的复杂性是进入的一个障碍。 使用TensorFlow,允许用户自定义在系统的所有部分中运行的代码。
TensorFlow执行模型
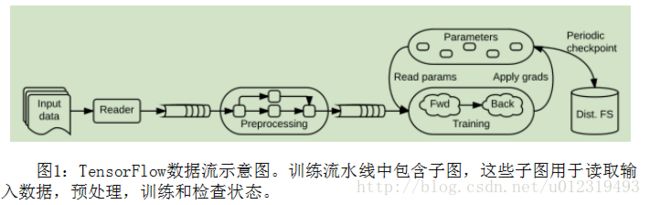
TensorFlow使用单个数据流图表来表示在机器学习算法中的所有计算和状态,包括各个数学运算、参数及其更新规则、输入处理(图1)。 数据流使得子计算之间的通信变得明确,因此易于并行执行独立计算,并且将计算跨越多个分布式设备。
TensorFlow数据流与批处理系统有两个方面的不同:
•支持重叠子图上的并发执行。
•单个顶点可具有可变状态,这些状态在图的不同执行之间共享。
参数服务器架构中的关键—可变状态。因为当训练大模型时,可对大量参数就地更新,并快速将这些更新传播到并行训练中。具有可变状态的数据流使TensorFlow能够模拟参数服务器的功能,同时具有额外的灵活性,因为可在托管共享模型参数的机器上执行任意数据流子图。 因此,用户已经能够尝试不同的优化算法、一致性方案和并行化策略。
数据流图中的元素
在TensorFlow图中:
顶点—–一个原子计算单位。 因为TensorFlow是为数学计算设计的,所以将顶点处的计算称为算子(operation)。
边—-张量,即多维数组,表示计算中的所有数据。
张量(Tensors): 在TensorFlow中,所有数据建模都为张量(密集的n维数组),具有少量的原始类型,如int32,float32或string。 张量代表了在许多机器学习算法中常见数学运算的输入和结果:例如,矩阵乘法采用两个2-D张量产生一个2-D张量; 小批量2-D卷积取两个4-D张量并产生另一个4-D张量。
所有张量都是密集的。以便系统的底层可简单实现存储分配和串行化,减少框架开销。 为了表示稀疏张量,TensorFlow提供了两个备选方案:将数据编码为长度可变的string,或使用元组(例如,具有m个非零值的n-D稀疏张量元素可以表示为m×n的索引矩阵和长为m的向量)。 张量可以是一个或多个维度,可表示元素数量不同的稀疏张量,代价是更复杂的形状推断成本。
算子(operation): 一个算子以m≥0张量作为输入,n≥0张量作为输出。 算子有一个命名的“类型”(如Const,MatMul或Assign),并具有零个或多个确定其行为的编译时属性。 一个算子在编译时可以是通用的和可变的:其属性确定其输入和输出的预期类型和数量。
例如,最简单的算子Const没有输入和单个输出。 Const有一个属性T以确定其输出类型,属性Value确定产生的值。 AddN是可变的:它有一个类型属性T和整数属性N,N定义接受多少个(类型为T的)输入。
状态算子:变量(variables): 算子可以包含在每次执行中被读取和/或写入的可变状态。 Variable算子拥有一个可变缓冲区,在训练时存储模型的共享参数。 Variable没有输入,产生一个引用句柄,用于读写缓冲区。 Read算子以一个引用句柄作为输入,输出变量的值作为密度张量。 有几个操作可以修改底层缓冲区:例如,AssignAdd使用引用句柄r和张量值x,在执行时更新State’[r]←State [r] + x。 后续的Read(r)运算产生State’[r]值。
状态算子:队列(queues) TensorFlow包括几个队列实现,支持更多的高级协调形式。 最简单的队列是FIFOQueue,拥有一个内部张量队列,支持并发访问。 类似Variable,FIFOQueue算子产生一个引用句柄,可以被标准队列操作之一消耗,例如Enqueue和Dequeue。 这些操作分别将输入推送到队列的尾部,或弹出并输出head元素。 如果队列已满,Equeue将被阻塞。如果给定队列为空,Dequeue将被阻塞。在输入预处理管道中使用队列时,这种阻塞提供反压力;它还支持同步。
部分和并发执行
TensorFlow使用数据流图表来表示应用程序中的所有计算,用于执行图的API允许客户端指定哪个子图应该被执行。 子图以声明方式的指定:客户端选择零个或多个边将输入张量送入数据流,以及一个或多个边从数据流中提取输出张量;运行时进行后修剪图直到包含必要的操作集合。 每次调用API都称为步骤(step),并且TensorFlow支持同一个图上的多个并发步骤,状态算子协调各个步骤。
好处:部分和并发执行为TensorFlow提供了灵活性。 添加可变状态和通过队列的协调使得可以在“无特权”代码中指定各种各样的模型架构,这使高级用户能够在不修改TensorFlow运行时内部的情况下进行实验。
部署分布式 :数据流简化了分布式执行,因为它使子计算之间的通信明确了。原则上,相同的TensorFlow程序可以部署到:分布式GPU集群,用于训练;TPU集群,用于服务;移动电话,用于移动推断。
算子分布式:每个算子驻留在特定设备上,例如一个CPU或GPU上。设备负责为每个操作分配内核。TensorFlow允许为单个操作注册多个内核。 对于许多操作,如元素操作符(Add,Sub等),使用单个内核就可以使用不同的编译器为CPU和GPU编译。
如何实现算子分布式:放置算法为每个算子计算可行的设备集合,计算必须被共同定位的算子集合,并选择每个共同定位组都满意的设备。状态操作和操作他们的状态必须在同一个设备上,这导致了隐式的共置约束。 此外,用户可以指定部分设备偏好,例如“一个特定任务中的任何设备”或“任务中的任何一个GPU”,并且运行时将遵守这些约束。 一个典型的训练应用将使用客户端程序结构来添加约束,例如,参数分布于一组“PS”任务中。
算子分布式过程:一旦图中的算子被放置好,并且部分子图已经计算了一个步骤,TensorFlow就将算子分区到每个设备子图。 设备d的每个设备子图包含所有的分配给d的操作,以及附加的Send和Recv算子,以替换跨设备边界的边。 一旦张量可用,Send就将单个输入发送到指定的设备,用 rendezvous key命名该值。 Recv有单个输出,并阻塞直到指定的rendezvous key在本地可用,然后生成其值。
优化分布式:目的—以低延迟重复执行大的子图。 一旦一个步骤图被修剪,放置和分区好,其子图就被缓存在它们各自的设备中。 客户端session维护从步骤定义到缓存子图的映射,这样就可通过对所参与的每个任务的一个小消息来发起大图形上的分布式。 这个模型喜欢静态的,可重用的图形,但也支持使用动态控制流的动态计算。
动态控制流
TensorFlow中的大多数评估是严格的:所有输入到算子中的必须在算子执行之前计算。 高级算法—例如高效训练循环神经网络—需要动态控制流动,对效率的评估就不用那么严格了。
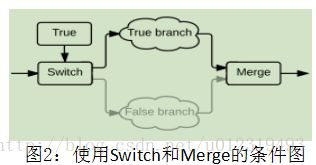
TensorFlow支持使用Switch和Merge算子的条件控制流。Switch就像一个解复用器:它获取数据输入并控制输入,选择两个输出中哪一个应该产生值。 Switch输出不接收特殊的死亡值,该值递归地通过图的其余部分传播,直到遇到Merge操作。Merge就像一个复用器:它最多将一个non-dead输入转发到输出,如果两个输入都死亡时产生死亡输出。
Switch和Merge也支持迭代。TensorFlow中的循环基于Switch和Merge,具有额外的结构约束:基于实时数据流来简化分布式执行状态。像实时数据流,TensorFlow支持多个并发迭代和嵌套循环,但是可简化内存管理,通过对每个算子做出限制:每次迭代产生单个值。
可扩展性的案例研究
微分与优化
许多学习算法使用随机梯度下降(SGD)的一些变体训练一组参数,需要计算关于这些参数的成本函数的梯度,然后基于这些梯度更新参数。我们为TensorFlow实现了一个自动微分表达式的用户级库。 用户可以,例如,将神经网络定义为层和损失函数的组合,并且库将得到反向传播。
微分算法执行宽度优先搜索以识别从目标操作(例如,损失函数)到一组参数的所有后向路径,并对每条路径贡献进行部分梯度求和。用户经常针对一些操作来专门化梯度,他们已经实现了一些优化,如批量标准化和梯度削减,以加速训练,挺高健壮性。 我们扩展了微分条件和迭代子计算的算法,并开发了在长序列上迭代(并累加中间值)时管理GPU存储器(类似于GeePS)的技术。
TensorFlow用户也可以实验范围广泛的优化算法,在每个训练步骤中计算新的参数值。 SGD(逻辑回归)容易在参数服务器中实现:对于每个参数 W,梯度∂L/∂W和学习率α,更新规则为W’← W − α × ∂L/∂W。 参数服务器可以通过使用 - =作为写入操作来实现SGD,在训练步骤之后将α×∂L/∂W写入每个W.
然而,还有更多的高级优化难以表达为单个写操作。例如,Momentum算法基于每个参数多次迭代的梯度来累积“速度”,然后根据该累积更新参数;许多这一算法的细化已被提出。为了在DistBelief中实现Momentum,我们必须修改C ++代码的参数服务器来改变参数的表示,并在写操作中执行任意代码;这样的修改超出了我们大多数的用户。而在TensorFlow中,可以使用Variable算子和原始数学运算在TensorFlow中进行构建而不需要修改底层系统,易于实验新算法。
处理大模型
通过分布式表示达到降维的目的:
在高维数据上训练模型,如文本语料库中的词的模型,通常使用分布式表示,将一个训练样例作为跨多个神经元的活动模式,这可以通过反向传播学习到。 例如,在语言模型中,训练样例可以是稀疏向量,其中非零条目对应于词的ID,每个字的分布式表达就成为较低维的向量。
通过乘以一个稀疏矩阵达到降维的目的:
推理是通过对n×d嵌入矩阵乘以一批b稀疏向量,其中n是词汇表中的词的数量,d是期望的维度,以产生更小的b×d密集矩阵表示;对于训练,大多数优化算法仅修改通过稀疏乘法读取的嵌入矩阵中的行。
降维的必要性:在许多处理稀疏数据的TensorFlow模型中,n×d可以等于千兆字节的参数:例如,大的语言模型使用超过10^9个参数,800,000词的词汇表,我们有文档模型的经验,其中参数占用几TB。这样的模型太大,无法复制到工作节点的每一个使用,甚至不能存储在单个主机上的RAM中。
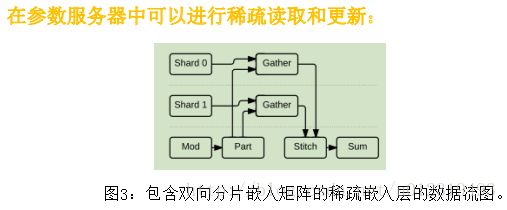
在TensorFlow图中实现了稀疏嵌入层作为原始操作的组合。图3显示了嵌入层的简化图,该图被两个参数服务器任务分割。 这个子图的核心算子是Gather,从一个张量中提取一个稀疏行集合,TensorFlow 与该算子上的变量共享该算子。 动态分区(Part)操作将入索引分成大小可变的张量,该张量包含为每个分片指定的索引,并且动态静态(Stitch)操作将来自每个分片的部分结果重新组合成单个结果张量。 这些操作中的每一个都有一个相应的梯度,因此它支持自动微分,结果是一组稀疏更新算子,只对最初从每个分片收集的值进行操作。
将任意计算卸载到托管共享参数的设备:
例如,分类模型通常使用softmax分类器,该分类器将最终输出乘以包含c列的权重矩阵,其中c是类的数量;对于语言模型,c是词汇的规模,可能很大。 用户已经尝试了几种方案来加速softmax计算。 第一个类似于项目Adam中的优化,权重被分割在几个任务上,并且乘法和梯度计算被分片共同定位。 更高效的训练是使用采样softmax,它在一个例子的真实类和一组随机抽样的假类的基础上执行稀疏乘法。
容错
容错的必要性:
训练模型可能需要几个小时或几天,甚至使用大量的机器。期望能够使用非专用资源来训练模型,例如使用诸如Mesos或Borg的集群管理器,其不保证在训练过程期间相同资源的可用性。因此,TensorFlow作业很可能在训练过程中遇到故障,我们需要某种形式的容错。
不需要太强的容错:
然而,故障不常见,以致于仅个别操作需要容错,因此像Spark的RDD这样的机制将会带来很大的开销,而无益处。没有必要使每个写入的参数都状态持久,因为可以从输入数据重新计算任何更新,并且许多学习算法不需要强一致性。虽然训练状态不使用强一致性,但依靠一个像Chubby或ZooKeeper系统,将任务ID映射到IP地址上。
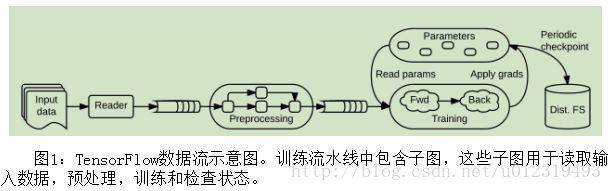
如何实现容错:使用原子操作(图1),在TensorFlow中实现了用户级检查点:Save将一个或多个张量写入检查点文件,Restore从检查点文件读取一个或多个张量。典型配置是将任务中的每个Variable连接到相同的Save算子,每个任务一个Save,以最大化到分布式文件系统的I/O带宽。 Restore从文件中读取命名的张量,一个标准的Assign将恢复的值存储在其相应的变量中。 在训练期间,典型的客户端周期性地运行所有Save算子以产生新的检查点; 当客户端启动时,它会尝试Restore最近的检查点。
TensorFlow包括用于构建恰当图结构的客户端库,并根据需要调用Save和Restore。 此行为是可自定义的:用户可以对模型中的变量子集应用不同的策略,或者定制检查点保留方案。 例如,许多用户在自定义评估度量中保留得分最高的检查点。 实现也是可重用的:它可以用于模型微调和无监督预训练,这是转移学习的形式,其中在一个任务上训练的模型参数(例如,识别一般图像) 被用作另一任务(例如,识别狗的特定品种)的起点。 将检查点和参数管理变得可编程操作,可以增加灵活性。
检查点库不会尝试产生一致的检查点:当训练和检查点同时执行,检查点可能包括来自训练步骤更新的,全部或一些或无。 这对于通过异步梯度下降训练的模型没有问题。 一致的检查点需要额外的同步,以确保检查点设置不会与更新操作同时运行。
同步复制的协调
同步的引出:SGD对于异步是稳健的,并且先前的系统使用异步参数更新训练深度神经网络,其被认为是可扩展的,因为它们在落后者的存在下仍保持高吞吐量。 增加的吞吐量是以使用陈旧数据的训练步骤为代价的。 一些人最近重新考虑了同步训练不可扩展的假设。 由于GPU支持数百台而不是数千台机器进行训练,因此也许在相同机器上同步训练模型,比异步训练时间更少。
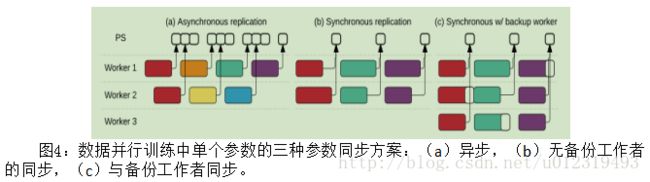
TensorFlow图使用户能够改变在训练模型时读取和写入参数的方式,并实现了三个选择:
1、在异步情况下(图4(a)),每个工作者在步骤开始时读取当前值,并将其梯度最终应用于不同的当前值:确保了高利用率,但是各个步骤使用旧信息,不是很有效。
2、同步情况使用队列协调执行:阻塞队列作为一个障碍,以确保所有工作者读取相同的参数版本,第二个队列累积多个梯度更新,为了以原子方式应用它们。 简单的同步版本(图4(b))在应用它们之前累积所有工作者的更新,但是慢工作者限制总吞吐量。
3、为了缓解落后者,实现了备份工作(图4(c)),这与MapReduce备份任务类似。 而MapReduce被动启动备份任务 - 在检测到落后者之后 - 我们的备份工作者主动运行,并且聚集将采用n个更新中的前m个。 利用SGD的随机抽取训练数据,每个工作者可处理不同的随机批次。 吞吐量提高到15%。
实现
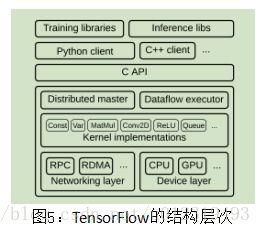
C语言API将各种语言的用户级与核心库分离。
为了可移植性和性能,核心TensorFlow库用C ++中实现:它运行在几个操作系统上,包括Linux,Mac OS X,Android和iOS;x86和各种基于ARM的CPU架构; 和NVIDIA的Kepler,Maxwell和Pascal GPU微架构。实现是开源的,已经接受了几个外部贡献,使TensorFlow能够在其他架构上运行。
分布式主机:分布式主机将用户请求转换为跨一组任务的执行。 给定图和步骤,对图进行剪枝和分区,以获得每个参与设备的子图,并缓存这些子图,以在后续步骤中重用。 由于主机能看到一个步骤计算的全部,可应用标准优化,例如公共子表达式消除和常数折叠;剪枝是消除死代码的一种形式。 然后协调跨一组任务的经优化的子图的执行。
数据流执行器:每个任务中的数据流执行器处理来自主机的请求,并调度包含本地子图的内核的执行。我们优化数据流执行器,以低开销地运行大、细粒度的图;每秒调度大约2,000,000个空操作。数据流执行器将内核分派给本地设备,并且在可能时并行运行内核。
内核:运行时包含200多个标准操作,包括数学,数组操作,控制流和状态管理操作。 许多操作内核是使用Eigen :: Tensor实现的,它使用C ++模板为多核CPU和GPU生成高效的并行代码;也使用像cuDNN这样的库来实现更高效、专门化的内核。 还实现了对量化的支持,这能加速诸如移动设备和高吞吐量数据中心应用中的推断,使用gemmlowp低精度矩阵乘法库加速量化计算。
传输:为每对源和目标设备类型专门化了Send和Recv算子。本地CPU和GPU设备之间的传输使用cudaMemcpyAsync()API,以重叠计算和数据传输; 两个本地GPU之间的传输使用DMA,以缓解主机上的压力。 对于任务之间的传输,TensorFlow支持多种协议,包括基于TCP的gRPC、基于聚合以太网的RDMA。对GPU到GPU通信的优化还在考察中。
编程语言:在用户级代码中,完全用C语言API实现了功能。 通常,用户通过组建标准操作来构建更高级的抽象,例如神经网络层,优化算法和分片嵌入计算。TensorFlow支持多种客户端语言,优先支持Python和C ++,用户最熟悉这些语言。随着功能的成熟,通常将它们移植到C ++,以便用户可以从所有客户端语言访问优化后的实现。
内核融合:如果将子计算表示为算子的组合是困难的或低效的,用户可以注册用C ++编写的提供有效实现的额外内核。 对于某些性能要求苛刻的算子,例如ReLU和Sigmoid激活函数及对应的梯度,手动实现内核融合比较好。目前正在研究使用Halide和其他基于编译器的技术实现内核自动融合。
其它工具:在生产中用于运行时推断的服务基础设施:可视化仪表板—使用户能够跟踪训练运行的进度,图形可视化器—帮助用户理解模型中的连接,分布式分析器—跟踪跨越多个设备和任务的计算的执行。
评估
专注于系统性能指标,而不是学习目标,如时间精度。 TensorFlow是一种允许机器学习从业者和研究人员实验新技术的系统,并且该评估表明系统:
(i)具有很小的开销。
(ii)可以使用大量计算来加速实际应用。
单机标准
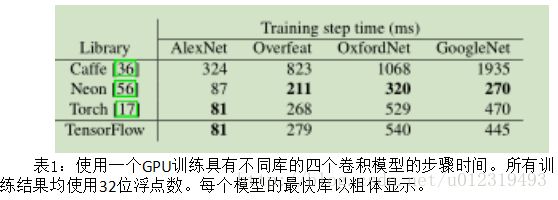
小规模性能不足:表1显示TensorFlow实现了比Caffe更短的步骤时间,并且性能在最新版本的Torch 的6%以内。TensorFlow和Torch之所以性能相近,是因为两者使用相同版本的cuDNN库,该库实现了在训练中关键路径上的卷积和池化操作;Caffe使用开源实现完成这些操作,比cuDNN更简单但效率较低。 Neon库通在汇编语言中手动优化卷积内核,在三个模型上优于TensorFlow;原则上,可以在TensorFlow中也可以,但还没有这样做。
同步复制微基准
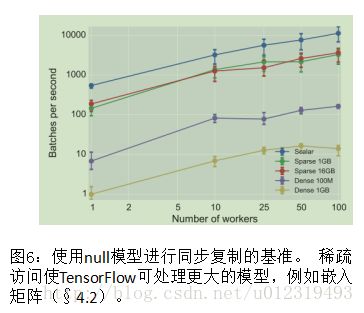
使用附加机器进行扩展时,协调的性能是主要限制因素。 图6显示了TensorFlow为不同大小的模型每秒执行一定量的空训练步骤,以及增加的同步工作器数量。 在空训练步骤中,工作者从16个PS任务获取共享模型参数,执行平常计算,并且发送参数的更新。
图6中的“梯状(Scalar)”曲线显示了同步训练步骤可期望的最佳性能,因为仅从每个PS任务仅获取一个4字节值。单个工作节点时步骤时间中值是1.8ms,100个工作节点时增长到8.8ms。 这些时间度量了同步机制的开销,并在共享集群上运行时,捕获所预期的一些噪声。
使用附加机器进行扩展时,协调的性能是主要限制因素。 图6显示了TensorFlow为不同大小的模型每秒执行一定量的空训练步骤,以及增加的同步工作器数量。 在空训练步骤中,工作者从16个PS任务获取共享模型参数,执行平常计算,并且发送参数的更新。
图6中的“梯状(Scalar)”曲线显示了同步训练步骤可期望的最佳性能,因为仅从每个PS任务仅获取一个4字节值。单个工作节点时步骤时间中值是1.8ms,100个工作节点时增长到8.8ms。 这些时间度量了同步机制的开销,并在共享集群上运行时,捕获所预期的一些噪声。
“密集(Dense)”曲线显示了当工作者获取整个模型时,空步骤的性能。 用大小为100MB和1GB的模型重复实验均匀分配在16个PS任务中的参数的步骤时间中值。从一个工作节点时的147ms增加到100个工作节点时的613ms。 对于1GB,它从一个工作节点时1.01秒增加到100个工作节点时7.16秒。
对于大型模型,训练步骤通常仅访问参数的子集,”稀疏(Sparse)”曲线显示了嵌入查找操作的吞吐量。 每个工作者从包含1GB或16GB数据的大型嵌入矩阵中读取32个随机选择的条目。 如预期,步骤时间不随嵌入查找操作的规模而变化,TensorFlow的步骤时间变化范围为:5到20ms。
图像分类
专注于谷歌的Inception-v3模型,在ILSVRC 2012图像分类挑战中实现了
78.8%的准确性;相同的技术也适用于其他深层卷积模型,如微软的ResNet— TensorFlow用户已经实现。考察使用多个副本训练Inception-v3模型的可扩展性。用17个PS任务配置TensorFlow作业,并更改工作任务的数量。每个工作任务都有一个NVIDIA K40 GPU和5个IvyBridge内核,一个PS任务有8个IvyBridge内核。考察协调对训练性能的影响,使用多达200个工作节点来验证同步训练近期有前途的结果。如果同步训练够高效,一个模型如Inception-V3将以更少的步骤完成训练,并且收敛到比异步训练更高的精度。
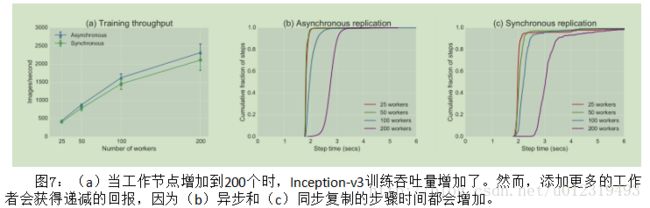
当工作节点数量增加到200,训练吞吐量提高到每秒2,300张图像,但是收益递减(图7(a))。图7(b)和(c)解释了扩展的限制:当添加更多的工作节点时,步骤时间增加,因为在网络接口和更新的聚合中,对PS任务产生更多的争用。对于所有配置,同步步骤比异步步骤更长,因为所有工作者必须等待最慢的工作者赶上,才能开始下一步。 虽然同一工作节点上,同步步长中值比异步步长长大约10%,但高于第90个百分数,同步性能急剧下降,因为落后者不成比例地拖尾了。
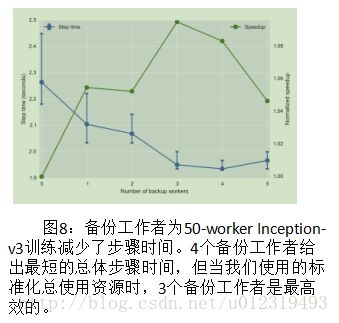
为了减少尾部延迟,可以添加备份工作者。图8显示了将备份工作节点添加到包含50个工作节点的初始训练中时,对步骤时间的影响。当额外备份工作者数<=4时,可降低步骤时间中值,因为落后者影响步骤的概率降低。添加第五个备份工作者会略微降低性能,因为第51个工作者(即,其结果被丢弃的第一个)很可能是非落后者。
图8还为每个配置绘制了“归一化加速度”,定义为t(b)/t(0)×50/(50 + b)(其中t(b)是b个备份工作者步骤时间的中值。虽然增加4个备份工作者实现了最短总步骤时间(1.93s),但3个实现了最高归一化加速度(9.5%),因此训练相同质量的模型需要更少的聚合GPU时间。
语言模型
语言模型用来在给定一个单词序列时,预测最可能的下一个单词。 因此,语言模型是预测文本,语音识别和翻译应用程序的组成部分。 在这个实验中,研究TensorFlow如何训练一个循环神经网络(即LSTM-512-512)来为Billion Word Benchmark文本建模。 词汇量|V| 限制了训练的性能,因为最后一层必须将输出状态解码为类别的概率。 结果参数也许很大(|V|×d,d为输出状态维度),因此使用4.2节中处理大型模型的技术:使用最常见的40,000词—而不是全部的800,000词 — 为了在较小的配置上实验。

图9显示了针对不同数量的PS和工作者任务,两个softmax上的训练吞吐量,以每秒词数计量。全softmax(虚线)将每个输出乘以分割在PS任务上的512×40,000权重矩阵。 添加更多PS任务可提高吞吐量,因为TensorFlow可以利用分布式模型并行性,对PS任务执行乘法和梯度计算,如Project Adam。 添加第二个PS任务比从4个增加到32个或32个到256个工作者更有效。 因为LSTM计算主导训练步骤。
采样softmax(实线)减少了传送的数据和在PS任务处执行的计算。不像密集权重矩阵,它将输出乘以包含了真类和随机伪类的权重的随机稀疏矩阵。我们为每个批次采样512个类,使softmax的数据传输和计算减少了22%。
结论
描述了:TensorFlow系统及基于数据流的可扩展的编程模型。
核心思想:TensorFlow的数据流表示参数服务器系统上的现有工作,并提供统一的编程模型,允许用户将大规模异构系统应用于生产和实验新方法,证明了TensorFlow的高性能和可扩展性。
完善:还未确定对大多数用户来说都很好用的默认策略。进一步的自动优化研究应该弥合这一差距。在系统级别上,正在积极开发用于自动布局,内核融合,内存管理和调度的算法。此外,预计一些TensorFlow应用程序将需要更强的一致性,所以正在研究如何在用户级构建此类策略。最后,有用户已经开始懊恼于静态数据流图形的局限,特别是对于深度增强学习等算法。因此,应提供一个透明而高效地使用分布式资源的系统,即使当计算结构动态展开时。
参考文献
TensorFlow: A System for Large-Scale Machine Learning
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, etc.