【AI视野·今日CV 计算机视觉论文速览 第185期】Tue, 15 Sep 2020
AI视野·今日CS.CV 计算机视觉论文速览
Tue, 15 Sep 2020
Totally 84 papers
上期速览✈更多精彩请移步主页

Daily Computer Vision Papers
| High-Resolution Deep Image Matting Authors Haichao Yu, Ning Xu, Zilong Huang, Yuqian Zhou, Humphrey Shi 图像抠像是图像和视频编辑与合成的关键技术。按照惯例,深度学习方法使用整个输入图像和一个关联的trimap来使用卷积神经网络来推断alpha遮罩。这样的方法在图像消光方面设置了最先进的技术,但是由于硬件限制,它们在现实世界的消光应用中可能会失败,因为现实世界中用于消光的输入图像大多具有很高的分辨率。在本文中,我们提出了HDMatt,这是第一种基于深度学习的图像抠像方法,用于高分辨率输入。更具体地讲,HDMatt以新颖的模块设计以基于补丁的裁剪和缝合方式为高分辨率输入运行消光,以解决不同补丁之间的上下文相关性和一致性问题。与独立计算每个补丁的基于香草补丁的推理相比,我们使用由给定的trimap指导的新提出的Cross Patch Contextual模块CPC显式地对cross patch上下文相关性进行建模。大量的实验证明了该方法的有效性及其对于高分辨率输入的必要性。我们的HDMatt方法还在Adobe Image Matting和AlphaMatting基准上设置了最新的性能水平,并在更真实的高分辨率图像上产生了令人印象深刻的视觉效果。 |
| Adaptive Text Recognition through Visual Matching Authors Chuhan Zhang, Ankush Gupta, Andrew Zisserman 在这项工作中,我们的目标是解决文档中文本识别的泛化和灵活性问题。我们引入了一个新模型,该模型利用了语言中字符的重复性质,并将视觉表示学习和语言建模阶段分离了。通过这样做,我们将文本识别变成形状匹配问题,从而实现外观的通用性和类的灵活性。我们在不同字母的合成数据集和实际数据集上评估了该新模型,并表明该模型可以应对传统体系结构无法解决的挑战,而无需进行昂贵的重新培训,包括i可以在没有新示例的情况下将其推广到看不见的字体ii可以灵活地使用。只需更改提供的示例即可更改类的数量,并且iii可以通过提供新的字形集将其推广到尚未接受过训练的新语言和新字符。对于所有这些情况,我们都显示出对最新模型的重大改进。 |
| GIA-Net: Global Information Aware Network for Low-light Imaging Authors Zibo Meng, Runsheng Xu, Chiu Man Ho 由于低信噪比,在低光照条件下获取可感知的图像非常具有挑战性。最近,U Nets在低光成像方面显示出令人鼓舞的结果。但是,由于缺乏全局颜色信息,香草U Nets生成的图像带有伪影,例如颜色不一致。在本文中,我们提出了一种具有全局信息意识的GIA模块,该模块能够提取全局信息并将其集成到网络中,以改善弱光成像的性能。 GIA模块可以以可忽略的额外学习参数或计算成本插入到普通U网中。此外,GIA网络是在大规模的现实世界低光成像数据集上构建,训练和评估的。实验结果表明,提出的GIA Net在四个指标(包括可测量感知相似性的深度指标)方面优于现有方法。已经进行了广泛的消融研究,以通过利用全局信息来验证建议的GIA Net在低光成像方面的有效性。 |
| Collaborative Attention Mechanism for Multi-View Action Recognition Authors Yue Bai, Zhiqiang Tao, Lichen Wang, Sheng Li, Yu Yin, Yun Fu 多视图动作识别MVAR利用来自不同视图的互补时间信息来增强学习过程。注意是一种有效的机制,已被广泛用于对时间数据进行建模。但是,大多数现有的MVAR方法仅利用注意力来提取视图特定模式。他们忽略了挖掘潜在的相互支持信息关注空间的潜力。为了充分利用多视图协作的优势,我们提出了一种协作注意力机制CAM。它检测多视图输入之间的注意力差异,并自适应地集成互补的帧级别信息,以使彼此受益。具体来说,我们通过将长期短期记忆LSTM扩展为互助RNN MAR来利用递归神经网络RNN。 CAM利用特定于视图的视图模式来引导另一种视图并释放可能难以自行探索的潜在信息。在三个动作数据集上进行的大量实验表明,我们的CAM在每个单视图下均能获得更好的结果,并提高了多视图性能。 |
| Zero-shot Synthesis with Group-Supervised Learning Authors Yunhao Ge, Sami Abu El Haija, Gan Xin, Laurent Itti 灵长类动物的视觉认知能力优于人工神经网络,因为它能够设想具有不同属性(包括姿势,位置,颜色,纹理等)的视觉对象(甚至是新引入的对象)。属性,我们提出了一系列目标函数,以示例组的形式表达,作为一种新颖的学习框架,我们称之为“小组监督学习GSL”。 GSL将输入分解为具有可交换组件的分解表示,这些组件可以重组以合成新样本,并通过示例组内的相似性挖掘进行训练。例如,可以分解并重组红色小船蓝色汽车的图像,以合成红色汽车的新颖图像。我们描述了GSL允许的通用数据集类别。我们提出了一种基于自动编码器的实施方案,即使用我们的学习框架训练的团体监督零击合成网络GZS Net,即使在训练过程中未见到此类示例,也可以生产出高质量的红色汽车。除了开源的新数据集之外,我们还在现有基准上测试我们的模型和学习框架。我们定性和定量地证明了使用GSL训练的GZS Net优于最新方法 |
| Beyond Weak Perspective for Monocular 3D Human Pose Estimation Authors Imry Kissos, Lior Fritz, Matan Goldman, Omer Meir, Eduard Oks, Mark Kliger 我们考虑了具有蒙皮多人线性SMPL模型的单眼视频对3D关节位置和方向预测的任务。我们首先使用现成的姿态估计算法来推断2D关节的位置。我们使用SPIN算法,并根据深度回归神经网络估算身体姿势,形状和相机参数的初始预测。然后,我们坚持使用SMPLify算法,该算法接收这些初始参数,并对它们进行优化,以使从SMPL模型推断出的3D关节将适合2D关节的位置。该算法涉及将3D关节投影到2D图像平面的步骤。常规方法是遵循弱透视假设,该假设使用临时焦距。通过对Wild 3DPW数据集中的3D姿势进行实验,我们表明使用具有正确相机中心和近似焦距的全透视投影可以提供令人满意的结果。我们的算法为3DPW挑战赛赢得了入围作品,在关节定位精度方面排名第一。 |
| Improving Inversion and Generation Diversity in StyleGAN using a Gaussianized Latent Space Authors Jonas Wulff, Antonio Torralba 现代的生成对抗网络能够根据生活在低维学习潜在空间中的潜在矢量创建人造的逼真图像。已经表明,可以将各种各样的图像投影到该空间中,包括在训练生成器的领域之外的图像。但是,尽管在这种情况下,生成器会再现图像的像素和纹理,但重构的潜矢量是不稳定的,并且较小的扰动会导致明显的图像失真。在这项工作中,我们建议对潜在空间中的数据分布进行显式建模。我们表明,在简单的非线性操作下,数据分布可以建模为高斯模型,因此可以使用足够的统计量来表示。这产生了一个简单的高斯先验,我们用它来规范图像在潜空间中的投影。生成的投影位于潜在空间的更平滑且性能更好的区域中,如对真实图像和生成图像使用插值性能所示。此外,潜在空间分布的高斯模型使我们能够研究发生器输出中伪像的起源,并提供了一种在保持所生成图像多样性的同时减少这些伪像的方法。 |
| A Study of Human Gaze Behavior During Visual Crowd Counting Authors Raji Annadi, Yupei Chen, Viresh Ranjan, Dimitris Samaras, Gregory Zelinsky, Minh Hoai 在本文中,我们描述了关于人类如何在视觉人群计数过程中分配注意力的研究。使用眼动仪,我们收集了负责计算人群图像中人数的人类参与者的凝视行为。分析了十个人参与者在三十个人群图像上收集的凝视行为,我们观察到了一些常见的视觉计数方法。对于少量人群的图像,方法是对人群中的所有人员或人群进行枚举,这解释了不同人类参与者的注视密度图之间的高度相似性。对于大量人群的图像,我们的参与者倾向于将注意力集中在图像的某一部分,计算该部分的人数,然后推断到其他部分。在计数准确性方面,与当前最先进的计算机算法相比,我们的人类参与者不擅长计数任务。有趣的是,存在一种趋势,即所有人群图像中的人数都被低估了。注视行为数据和图像可以从以下位置下载 |
| Fast Implementation of 4-bit Convolutional Neural Networks for Mobile Devices Authors Anton Trusov, Elena Limonova, Dmitry Slugin, Dmitry Nikolaev, Vladimir V. Arlazarov 量化的低精度神经网络非常受欢迎,因为它们需要较少的计算资源来进行推理并可以提供高性能,这对于实时和嵌入式识别系统至关重要。然而,它们的优势对于FPGA和ASIC器件是显而易见的,而通用处理器体系结构并不总是能够高效地执行低位整数计算。用于移动中央处理器的最常用的低精度神经网络模型是8位量化网络。然而,在许多情况下,可以使用较少的比特进行加权和激活,唯一的问题是有效实现的困难。我们为量化神经网络引入4位矩阵乘法的有效实现,并在移动ARM处理器上执行时间测量。与标准浮点乘法相比,它的速度提高了2.9倍,比8位量化速度快了1.5倍。我们还演示了用于MIDV 500数据集上OCR识别的4位量化神经网络。 4位量化可提供95.0精度和48个总体推理加速,而8位量化网络可提供95.4精度和39个加速。结果表明,4位量化非常适合移动设备,产生了足够好的精度和较低的推理时间。 |
| Unsupervised Domain Adaptation by Uncertain Feature Alignment Authors Tobias Ringwald, Rainer Stiefelhagen 无监督域适应UDA处理模型从具有标签数据的给定源域到未标签目标域的适应。在本文中,我们利用模型的固有预测不确定性来完成域自适应任务。不确定性通过蒙特卡洛(Monte Carlo)落差测量,并用于我们提出的基于不确定度的滤波和特征对齐UFAL,该方法结合了不确定性特征损失UFL函数和基于不确定度的滤波UBF方法,用于欧氏空间中特征的对齐。我们的方法超越了最近提出的架构,并在多个具有挑战性的数据集上达到了最先进的结果。代码可在项目网站上找到。 |
| EfficientSeg: An Efficient Semantic Segmentation Network Authors Vahit Bugra Yesilkaynak, Yusuf H. Sahin, Gozde Unal 没有预先训练的权重和很少的数据的深度神经网络训练表明需要更多的训练迭代。还众所周知,对于语义分割任务,较深层的模型比浅层模型更成功。因此,我们介绍了EfficientSeg体系结构,它是U Net的一种可扩展的可扩展版本,尽管它的深度,也可以有效地进行训练。我们评估了Minicity数据集上的EfficientSeg体系结构,并使用相同的参数计数51.5 mIoU优于U Net基线得分40 mIoU。我们最成功的模型获得了58.1 mIoU的得分,并在ECCV 2020 VIPriors挑战的语义细分中排名第四。 |
| Scene-Graph Augmented Data-Driven Risk Assessment of Autonomous Vehicle Decisions Authors Shih Yuan Yu, Arnav V. Malawade, Deepan Muthirayan, Pramod P. Khargonekar, Mohammad A. Al Faruque 尽管自动驾驶系统ADS取得了令人瞩目的进步,但在复杂的路况下导航仍然是一个具有挑战性的问题。有大量证据表明,评估各种决策的主观风险水平可以提高正常和复杂驾驶情况下的ADS安全性。但是,现有的基于深度学习的方法通常无法对交通参与者之间的关系进行建模,并且在面对复杂的现实世界场景时可能会遭受损失。此外,这些方法缺乏可传递性和可解释性。为了解决这些限制,我们提出了一种新颖的数据驱动方法,该方法使用场景图作为中间表示。我们的方法包括一个多关系图卷积网络,一个长期短期记忆网络以及用于对驾驶行为的主观风险进行建模的注意层。为了训练我们的模型,我们将该任务表述为有监督的场景分类问题。我们考虑一个典型的用例来证明我们的模型的能力变化。我们证明,在大型96.4 vs. 91.2和小型91.8 vs. 71.2合成数据集上,我们的方法均比现有方法具有更高的分类准确性,也说明了我们的方法甚至可以从较小的数据集中有效学习。我们还表明,在真实数据集上进行测试时,在合成数据集上训练的模型达到87.8的平均准确度,而在同一合成数据集上训练的最新模型达到70.3的准确度,表明我们的方法可以有效地传递知识。最后,我们证明了使用空间和时间注意层分别将模型的性能提高了2.7和0.7,并增加了其可解释性。 |
| Adaptive Label Smoothing Authors Ujwal Krothapalli, A. Lynn Abbott 本文涉及运用客观性措施来提高卷积神经网络CNN的标定性能。客观性是在给定图像中存在来自任何类别的物体的可能性的度量。 CNN已被证明是非常好的分类器,并且通常可以很好地定位对象,但是,通常用于训练分类CNN的损失函数不会惩罚无法定位对象的问题,也不会考虑给定图像中对象的相对大小。我们提出了一种新颖的对象定位方法,该方法结合了训练期间的客观性和标签平滑化的思想。与以前的方法不同,我们根据图像内的相对对象大小计算自适应的平滑因子。我们使用ImageNet和OpenImages给出了广泛的结果,以证明与使用硬目标训练的CNN相比,使用自适应标签平滑训练的CNN在预测中不太可能过于自信。我们还使用类激活图来显示定性结果,以说明这些改进。 |
| Completely Self-Supervised Crowd Counting via Distribution Matching Authors Deepak Babu Sam, Abhinav Agarwalla, Jimmy Joseph, Vishwanath A. Sindagi, R. Venkatesh Babu, Vishal M. Patel 密集人群计数是一项艰巨的任务,需要数百万个头部注释来训练模型。尽管现有的自我监督方法可以学习良好的表示,但它们需要一些标记数据才能将这些特征映射到密度估计的最终任务。我们通过提出的完全自我监督的范例来缓解此问题,该范例甚至不需要单个标记的图像。除了大量未标记的人群图像之外,训练所需的唯一输入是给定数据集的人群计数的近似上限。我们的方法基于自然人群遵循幂定律分布的想法,可以利用该定律分布产生误差信号进行反向传播。首先通过自我监督对密度回归器进行预训练,然后通过优化两者之间的Sinkhorn距离使预测的分布与先验匹配。实验表明,这可以有效地学习人群特征并提供显着的计数性能。此外,我们还在较少的数据设置中建立了我们方法的优势。我们的方法的代码和模型可在以下位置获得 |
| Synbols: Probing Learning Algorithms with Synthetic Datasets Authors Alexandre Lacoste, Pau Rodr guez, Fr d ric Branchaud Charron, Parmida Atighehchian, Massimo Caccia, Issam Laradji, Alexandre Drouin, Matt Craddock, Laurent Charlin, David V zquez 通过引入基准数据集推动了现有算法的局限性,推动了机器学习领域的进步。因此,使数据集的设计能够测试学习算法的特定特性和失败模式是一个引起人们高度关注的问题,因为它直接影响了该领域的创新。从这个意义上讲,我们引入了Synbols Synthetic Symbols工具,该工具可快速生成具有在低分辨率图像中呈现的大量潜在特征的新数据集。 Synbols利用了Unicode标准中可用的大量符号和开放字体社区提供的广泛的艺术字体。我们工具的高级界面提供了一种语言,可用于快速生成潜在特征上的新分布,包括各种类型的纹理和遮挡。为了展示Synbols的多功能性,我们使用它来剖析标准学习算法在各种学习设置中的局限性和缺陷,包括监督学习,主动学习,分布外泛化,无监督表示学习和对象计数。 |
| Adaptive Convolution Kernel for Artificial Neural Networks Authors F. Boray Tek, lker am, Deniz Karl 许多深度神经网络是通过使用固定大小和单个大小的堆叠卷积层(通常是3乘3内核)构建的。本文介绍了一种用于训练卷积核大小以在单个层中提供大小可变的核的方法。该方法利用了可微分的,因此反向传播可训练的高斯包络,该包络可以在基本网格中增长或收缩。我们的实验在简单的两层网络,更深的残差网络和U Net架构中将建议的自适应层与普通卷积层进行了比较。流行的图像分类数据集(例如MNIST,MNIST CLUTTERED,CIFAR 10,Fashion和Faces in the Wild)中的结果表明,自适应内核可以对普通卷积内核提供统计学上显着的改进。 Oxford Pets数据集中的分割实验表明,用单个7 x 7自适应层替换U形网络中的单个普通卷积层可以提高其学习性能和泛化能力。 |
| P-DIFF: Learning Classifier with Noisy Labels based on Probability Difference Distributions Authors Wei Hu, QiHao Zhao, Yangyu Huang, Fan Zhang 学习带有噪声标签的深度神经网络DNN分类器是一项具有挑战性的任务,因为DNN由于其强大的功能而很容易过度适合这些噪声标签。在本文中,我们提出了一种非常简单但有效的训练范式,称为P DIFF,它可以训练DNN分类器,但明显减轻了嘈杂标签的不利影响。我们提出的概率差异分布隐式反映了训练样本干净的概率,然后在训练过程中利用该概率对相应样本进行加权。即使没有事先对训练样本的噪声率的了解,P DIFF也可以实现良好的性能。在基准数据集上进行的实验还表明,P DIFF优于现有的样本选择方法。 |
| 4Seasons: A Cross-Season Dataset for Multi-Weather SLAM in Autonomous Driving Authors Patrick Wenzel, Rui Wang, Nan Yang, Qing Cheng, Qadeer Khan, Lukas von Stumberg, Niclas Zeller, Daniel Cremers 我们提出了一个新颖的数据集,涵盖了自动驾驶的季节性和挑战性感知条件。除其他功能外,它还可以研究视觉里程表,全局位置识别以及基于地图的重新定位跟踪。数据是在不同的场景下以及在各种天气条件和光照下(包括白天和黑夜)收集的。这导致了在九种不同环境中超过350公里的录音,这些环境包括城市中的多层停车场,包括通往乡村和高速公路的隧道。通过提供直接立体视觉惯性里程计与RTK GNSS的融合,我们可以提供高达厘米级精度的全局一致参考姿势。完整的数据集位于 |
| PRAFlow_RVC: Pyramid Recurrent All-Pairs Field Transforms for Optical Flow Estimation in Robust Vision Challenge 2020 Authors Zhexiong Wan, Yuxin Mao, Yuchao Dai 光流估计是一项重要的计算机视觉任务,旨在估计两个帧之间的密集对应关系。 RAFT循环所有对场变换当前代表了光流估计中的最新技术。它具有出色的泛化能力,并且在多个基准测试中均获得了出色的结果。为了进一步提高鲁棒性并实现准确的光流估计,我们提出了基于金字塔网络结构的PRAFlow金字塔循环所有对流。由于计算限制,我们提出的网络结构仅使用两个金字塔层。在每一层,RAFT单元用于估计当前分辨率下的光流。我们的模型在几个模拟和真实图像数据集上进行了训练,使用相同的模型和参数提交给多个排行榜,并在ECCV 2020研讨会“稳健视觉挑战”的光流任务中获得第二名。 |
| DeepWriteSYN: On-Line Handwriting Synthesis via Deep Short-Term Representations Authors Ruben Tolosana, Paula Delgado Santos, Andres Perez Uribe, Ruben Vera Rodriguez, Julian Fierrez, Aythami Morales 这项研究提出了DeepWriteSYN,这是一种通过深度短期表示的在线手写合成方法。它包括两个模块,一个是可选的且可互换的时间分段,它将笔迹分为由单个或多个串联笔画组成的短时间段,以及这些短时笔迹段的在线合成,这是基于序列到变分自动编码器的VAE。所提出的方法的主要优点在于,合成可以在较短的时间段内进行,该时间段可以从一个字符分数到完整的字符,并且可以在可配置的手写数据集上训练VAE。这两个属性为我们的合成器提供了很大的灵活性,例如,如我们的实验所示,DeepWriteSYN可以生成与给定人口或给定主题内的自然变化相对应的给定手写结构的真实笔迹变化。这两种情况分别是通过实验分别针对单个数字和手写签名而开发的,在两种情况下均取得了显着效果。 |
| Deep intrinsic decomposition trained on surreal scenes yet with realistic light effects Authors Hassan Sial, Ramon Baldrich, Maria Vanrell 由于地面实况数据集的弱点(太小或存在非现实问题),固有图像的估计仍然是一项艰巨的任务。另一方面,端到端深度学习架构开始取得有趣的结果,我们认为,如果不忽略重要的物理提示,则可以改善这些结果。在这项工作中,我们提出了一个双重框架:一种灵活的图像生成方法,可以克服一些经典的数据集问题,例如更大的尺寸以及相干的照明外观;以及一种灵活的体系结构,可以通过固有损耗来绑定物理属性。我们的建议是通用的,具有较低的计算时间,并且可以达到最新的结果。 |
| AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results Authors Dario Fuoli, Zhiwu Huang, Shuhang Gu, Radu Timofte, Arnau Raventos, Aryan Esfandiari, Salah Karout, Xuan Xu, Xin Li, Xin Xiong, Jinge Wang, Pablo Navarrete Michelini, Wenhao Zhang, Dongyang Zhang, Hanwei Zhu, Dan Xia, Haoyu Chen, Jinjin Gu, Zhi Zhang, Tongtong Zhao, Shanshan Zhao, Kazutoshi Akita, Norimichi Ukita, Hrishikesh P S, Densen Puthussery, Jiji C V 本文回顾了与ECCV 2020上的AIM 2020研讨会相关的视频极端超分辨率挑战。学习到的视频超分辨率VSR的常见缩放因子不会超出因子4。在该地区,尤其是在HR视频中,丢失的信息可以得到很好的恢复,高频内容主要由纹理细节组成。这项挑战中的任务是将视频的极端因素提高到16,这会导致更严重的性能下降,进而影响视频的结构完整性。低分辨率LR域中的单个像素对应于高分辨率HR域中的256个像素。由于这种大量的信息丢失,很难准确地恢复丢失的信息。设置轨道1是为了衡量这项艰巨任务的最新技术,其中通过PSNR和SSIM来测量对地面真实性的保真度。通过产生合理的高频成分,可以在保真度方面取得较高的质量。因此,磁道2的目的是生成视觉效果令人愉悦的结果,并根据用户的感知对结果进行排名,并通过用户研究进行评估。与单图像超分辨率SISR相比,VSR可以从时域中受益于附加信息。但是,这也带来了额外的要求,因为生成的帧需要在时间上保持一致。 |
| Unsupervised learning for vascular heterogeneity assessment of glioblastoma based on magnetic resonance imaging: The Hemodynamic Tissue Signature Authors Javier Juan Albarrac n 本文主要研究血流动力学组织签名HTS方法的研究和发展,该方法是一种无监督的机器学习方法,通过灌注MRI分析描述胶质母细胞瘤的血管异质性。 HTS基于栖息地的概念。栖息地定义为病变的子区域,具有描述特定生理行为的特定MRI轮廓。 HTS方法将胶质母细胞瘤内的四个生境描述为高血管生成肿瘤HAT生境,作为增强型肿瘤最灌注的区域,低血管生成肿瘤LAT生境,作为血管生成特征较低的增强型肿瘤区域,可能是浸润性周围性水肿IPE栖息地,作为与肿瘤相邻的非增强区域,具有较高的灌注指数和血管周围性水肿VPE栖息地,是病变部位的剩余水肿,具有最低的灌注曲线。 |
| Accurate and Lightweight Image Super-Resolution with Model-Guided Deep Unfolding Network Authors Qian Ning, Weisheng Dong, Guangming Shi, Leida Li, Xin Li 基于深度神经网络的DNN方法在单图像超分辨率SISR中取得了巨大的成功。但是,现有的最先进的SISR技术被设计成缺乏透明性和可解释性的黑匣子。此外,由于黑匣子设计,视觉质量的提高通常是以增加模型复杂性为代价的。在本文中,我们提出并倡导一种针对SISR的可解释方法,即模型引导的深度展开网络MoG DUN。为了突破相干性障碍,我们选择使用一个建立良好的图像,然后命名为非局部自回归模型,并用其指导我们的DNN设计。通过将深度降噪和非局部正则化作为可训练的模块集成在深度学习框架中,我们可以将基于模型的SISR的迭代过程展开为构建模块的多阶段级联,该模块具有三个相互关联的模块去噪,非局部AR和重建。这三个模块的设计都利用了最新的优势,包括密集的跳过连接以及快速的非本地实现。除了可解释性之外,MoG DUN还可以精确地产生更少的混叠伪像,在减少模型参数的情况下计算效率高,并且能够处理多种退化。通过在几个流行的数据集和各种降级方案上进行的广泛实验,证明了所提出的MoG DUN方法相对于现有技术的图像SR方法(包括RCAN,SRMDNF和SRFBN)的优越性。 |
| Prior Knowledge about Attributes: Learning a More Effective Potential Space for Zero-Shot Recognition Authors Chunlai Chai, Yukuan Lou, Shijin Zhang 零镜头学习ZSL旨在通过学习可见的类别和已知属性来准确识别看不见的类别,但是先前的研究忽略了属性的相关性,这导致分类结果混乱。为了解决这个问题,我们建立了一个属性相关势空间生成ACPSG模型,该模型使用图卷积网络和属性相关来生成更具区分性的势空间。结合潜在的辨别空间和用户定义的属性空间,我们可以更好地对看不见的类进行分类。无论是传统的ZSL还是广义的ZSL,我们的方法都优于一些基准数据集上现有的现有技术方法。 |
| Cascade Network for Self-Supervised Monocular Depth Estimation Authors Chunlai Chai, Yukuan Lou, Shijin Zhang 通过使用单眼相机获得真实场景深度图是一种典型的计算机视觉问题,这是近年来受到广泛关注的问题。但是,训练此模型通常需要大量的人工标记样本。为了解决这个问题,一些研究人员使用自我监督的学习模型来克服此问题并减少对手动标记数据的依赖。但是,这些方法的准确性和可靠性尚未达到预期的标准。本文提出了一种新的基于级联网络的自我监督学习方法。与以前的自我监督方法相比,我们的方法具有更高的准确性和可靠性,并通过实验证明了这一点。我们展示了一个级联神经网络,它将目标场景分为不同视距的部分,并分别训练它们以生成更好的深度图。我们的方法分为以下四个步骤。第一步,我们使用自我监督模型来粗略估计场景的深度。在第二步中,将第一步中生成的场景深度用作标记,以将场景划分为不同的深度部分。第三步是使用具有不同参数的模型来生成目标场景中不同深度部分的深度图,第四步是融合深度图。通过消融研究,我们证明了每个组件的有效性,并在KITTI基准测试中显示了高质量的最新技术成果。 |
| Residual Learning for Effective joint Demosaicing-Denoising Authors Yu Guo, Qiyu Jin, Gabriele Facciolo, Tieyong Zeng, Jean Michel Morel 图像去马赛克和去噪是彩色图像生产流程中的关键步骤。经典处理序列包括先应用去噪,然后再去马赛克。但是,此顺序会导致过度平滑和令人不快的棋盘效果。而且,改变该顺序是非常困难的,因为一旦图像被去马赛克,噪声的统计特性将发生巨大变化。对于高度依赖统计假设的传统降噪模型而言,这是极具挑战性的。在本文中,我们试图解决这个棘手的问题。确实,这里我们通过首先应用去马赛克,然后使用自适应降噪来反转传统的CFA处理流程。为了获得无噪声图像的高质量去马赛克,我们将传统算法的优势与深度学习相结合。这是通过训练卷积神经网络CNN来学习传统算法的残差来实现的。为了提高图像去马赛克的性能,我们提出了一种改进的Inception体系结构。以受过训练的去马赛克技术为基本组件,我们将其应用于嘈杂的图像,并使用另一个CNN来学习包括去马赛克图像伪像在内的残留噪声,从而可以重建全彩色图像。实验结果清楚地表明,该方法无论在数量上还是在视觉质量上都优于几种先进的方法。 |
| Learning from Multimodal and Multitemporal Earth Observation Data for Building Damage Mapping Authors Bruno Adriano, Naoto Yokoya, Junshi Xia, Hiroyuki Miura, Wen Liu, Masashi Matsuoka, Shunichi Koshimura 地球观测技术(例如光学成像和合成孔径雷达SAR)提供了出色的手段来连续监测不断增长的城市环境。值得注意的是,在海啸和地震等大规模灾害中,响应时间非常紧迫,两种数据形式的图像可以相互补充,以准确传达灾害后的全部破坏情况。但是,由于天气和卫星覆盖等多种因素的影响,通常无法确定哪种数据形式将首先用于快速的灾难响应工作。因此,可以利用所有可访问的EO数据集的新颖方法对于灾难管理至关重要。在这项研究中,我们已经开发了用于建筑物损伤映射的全局多传感器和多时间数据集。我们将地震,海啸和台风这三种灾害类型的建筑破坏特征包括在内,并考虑了三种建筑破坏类别。全球数据集包含高分辨率的光学图像和在每次灾难之前和之后获取的高分辨率至中分辨率的多波段SAR数据。使用这个综合的数据集,我们分析了五个数据模态场景,分别用于损伤映射单模光学和SAR数据集,交叉模态灾难前光学和灾难后SAR数据集以及模式融合场景。我们基于深度卷积神经网络算法定义了用于受损建筑物的语义分割的损坏映射框架。我们将我们的方法与另一种先进的损伤模型基线模型进行比较。结果表明,我们的数据集与深度学习网络一起,为所有数据模式场景提供了可接受的预测。 |
| RelativeNAS: Relative Neural Architecture Search via Slow-Fast Learning Authors Hao Tan, Ran Cheng, Shihua Huang, Cheng He, Changxiao Qiu, Fan Yang, Ping Luo 尽管卷积神经网络CNN在计算机视觉中取得了巨大的成功,但是手动设计CNN既费时又容易出错。在旨在自动化高性能CNN设计的各种神经体系结构搜索NAS方法中,可区分的NAS和基于种群的NAS由于其独特的特性而引起了越来越多的关注。为了在克服两者的缺点的同时从优点中受益,这项工作提出了一种新颖的NAS方法RelativeNAS。作为高效搜索的关键,RelativeNAS以成对的方式在快速学习者(即具有相对较高准确性的网络和慢速学习者)之间执行联合学习。此外,由于RelativeNAS仅需要低保真度性能估计来区分快速学习者和慢学习者的每一对,因此节省了用于训练候选架构的某些计算成本。提议的RelativeNAS带来了几个独特的优势:1它在imageNet上实现了最先进的性能,错误率最高的为24.88,即分别比DARTS和AmoebaNet B的性能高出1.82和1.122。仅用一个1080Ti GPU就花费了九个小时来获得发现的细胞,即比DARTS和AmoebaNet分别快3.75倍和7875x 3,它提供了在CIFAR 10上获得的发现的细胞可以直接转移到对象检测,语义分割和关键点检测上,从而在PASCAL VOC上产生73.1 mAP的竞争性结果,在Cityscapes上分别为78.7 mIoU和在MSCOCO上为68.5 AP。该代码位于 |
| 3D Object Detection and Tracking Based on Streaming Data Authors Xusen Guo, Jiangfeng Gu, Silu Guo, Zixiao Xu, Chengzhang Yang, Shanghua Liu, Long Cheng, Kai Huang 由于深度学习的发展,用于3D对象检测的最新方法已取得了巨大的进步。但是,先前的研究大多基于单个帧,导致帧之间信息的利用有限。在本文中,我们尝试在流数据中利用时间信息,并探索基于3D流的对象检测和跟踪。为了实现这一目标,我们建立了一个基于关键帧的3D对象检测双向网络,然后通过基于时间信息的基于运动的插值算法将预测传播到非关键帧。与逐帧范例相比,我们的框架不仅显示出在对象检测方面的显着改进,而且在KITTI对象跟踪基准中被证明具有竞争优势,MOTA分别为76.68和MOTP为81.65。 |
| One-bit Supervision for Image Classification Authors Hengtong Hu, Lingxi Xie, Zewei Du, Richang Hong, Qi Tian 本文提出了一种位监督,这是一种在图像分类的情况下从不完整注释中学习的新设置。我们的设置不是在每个样本的准确标签上训练模型,而是要求模型使用每个样本的预测标签进行查询,并从答案中了解猜测是否正确。这提供了是或否的信息,更重要的是,对每个样本进行注释比从许多候选类中查找准确的标签容易得多。在一点点监督下训练模型有两个关键,它们可以提高猜测的准确性并利用错误的猜测。为此,我们提出了一种多阶段训练范例,该范例将否定标签抑制功能整合到了现成的半监督学习算法中。在三个流行的图像分类基准中,我们的方法声称在利用有限数量的注释中具有更高的效率。 |
| GINet: Graph Interaction Network for Scene Parsing Authors Tianyi Wu, Yu Lu, Yu Zhu, Chuang Zhang, Ming Wu, Zhanyu Ma, Guodong Guo 最近,使用超出局部卷积的图像区域进行上下文推理已显示出场景解析的巨大潜力。在这项工作中,我们探索如何通过建议图交互单元GI单元和语义上下文损失SC损失来整合语言知识,以在图像区域上促进上下文推理。 GI单元能够在高级语义上增强卷积网络的特征表示,并自适应地学习每个样本的语义一致性。具体而言,首先将基于数据集的语言知识合并到GI单元中,以促进视觉图上的上下文推理,然后将视觉图的演变表示形式映射到每个局部表示形式,以增强区分场景分析的能力。通过SC损失进一步改善了GI单元,以增强基于示例的语义图的语义表示。我们进行了完整的消融研究,以证明我们方法中每个组件的有效性。特别是,拟议的GINet在包括Pascal Context和COCO Stuff在内的流行基准上均优于最新方法。 |
| SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition Authors Liangzhi Li, Bowen Wang, Manisha Verma, Yuta Nakashima, Ryo Kawasaki, Hajime Nagahara 可解释的人工智能正在引起关注。然而,大多数现有方法是基于梯度或中间特征的,它们不直接参与分类器的决策过程。在本文中,我们提出了一种基于时隙关注的轻量级分类器,称为SCOUTER,可实现透明而准确的分类。与其他基于注意的方法的两个主要区别包括:SCOUTER的解释涉及每个类别的最终置信度,提供了更直观的解释; b所有类别都有其对应的肯定或否定解释,这说明了图像为何属于某个类别或为什么图片不属于某个类别。我们为SCOUTER设计了一种新的损失,该损失控制模型的行为以在正面和负面解释以及解释区域的大小之间切换。实验结果表明,SCOUTER可以在对大型数据集保持良好准确性的同时提供更好的视觉解释。 |
| Accelerating COVID-19 Differential Diagnosis with Explainable Ultrasound Image Analysis Authors Jannis Born, Nina Wiedemann, Gabriel Br ndle, Charlotte Buhre, Bastian Rieck, Karsten Borgwardt 控制COVID 19大流行很大程度上取决于快速,安全和高度可用的诊断工具的存在。与CT或X射线相比,超声具有许多实际优势,可以用作全球通用的一线检查技术。我们为COVID 19提供了最大的可公开获得的美国肺部超声数据集,其中包括来自三类COVID 19,细菌性肺炎和由医学专家策划和批准的健康对照的106个视频。在此数据集上,我们进行了深度学习方法对COVID 19的鉴别诊断的价值的深入研究。我们提出了一种基于帧的卷积神经网络,可以正确地将COVID 19 US视频分类,灵敏度为0.98 0.04,特异性为0.91。基于08框架的灵敏度为0.93 0.05,特异性为0.87 0.07。我们进一步将类别激活图用于肺部生物标记物的时空定位,随后我们与医学专家进行了蒙眼研究,从而在环场景中对人类进行了验证。为了实现可扩展性和鲁棒性,我们对消融研究进行了比较,比较了基于移动友好的,基于帧和视频的架构,并通过无意和认知不确定性估计显示了最佳模型的可靠性。我们希望为社区努力铺平道路,以提供一种易于使用,高效且可解释的筛查方法,并且我们已开始着手对该方法的临床验证。数据和代码是公开可用的。 |
| Multi-channel MRI Embedding: An EffectiveStrategy for Enhancement of Human Brain WholeTumor Segmentation Authors Apurva Pandya, Catherine Samuel, Nisargkumar Patel, Vaibhavkumar Patel, Thangarajah Akilan 医学图像处理中最重要的任务之一是大脑的整个肿瘤分割。它有助于更快地进行临床评估和早期发现脑瘤,这对于挽救患者的生命至关重要。因为,如果在早期发现脑瘤,它们通常可能是恶性或良性的。脑瘤是大脑中异常细胞的集合或大量。人类的头颅骨非常严密地包围着大脑,在该受限区域内的任何生长都会引起严重的健康问题。脑肿瘤的检测需要仔细而复杂的分析以进行手术计划和治疗。大多数医生采用磁共振成像MRI诊断此类肿瘤。已知使用MRI手动诊断肿瘤大约很耗时,每个样本最多需要18个小时。因此,肿瘤的自动分割已成为该问题的最佳解决方案。研究表明,该技术可提供更好的准确性,并且比手动分析更快,从而使患者在正确的时间接受治疗。我们的研究引入了一种称为多通道MRI嵌入的有效策略,以改善基于深度学习的肿瘤分割的结果。使用U Net编码器解码器EnDec模型对Brats 2019数据集进行的实验分析显示了显着改进。嵌入策略以2的优势超越了现有技术的水平,而没有任何时序开销。 |
| Cosine meets Softmax: A tough-to-beat baseline for visual grounding Authors Nivedita Rufus, Unni Krishnan R Nair, K. Madhava Krishna, Vineet Gandhi 在本文中,我们为自动驾驶提供了一个简单的可视化基础基线,其性能优于现有方法,同时保留了最少的设计选择。我们的框架通过嵌入代表给句短语的文本,使多个图像ROI特征之间的余弦距离上的交叉熵损失最小。我们使用经过训练的网络来获取初始嵌入,并在文本嵌入之上学习转换层。我们对Talk2Car数据集进行实验,并达到68.7的AP50精度,比之前的最新水平提高了8.6。我们的研究建议,通过在更简单的替代方案中展现希望,重新考虑采用成熟的注意力机制或多阶段推理或复杂的度量学习损失功能的更多方法。 |
| Pairwise-GAN: Pose-based View Synthesis through Pair-Wise Training Authors Xuyang Shen, Jo Plested, Yue Yao, Tom Gedeon 三维人脸重建是计算机视觉中的流行应用之一。但是,即使是最先进的模型,也仍然需要正面作为输入,这限制了其在野外的使用场景。在面部识别中也发生类似的难题。已经出现了旨在从单侧姿势面部图像恢复正面的新研究。该领域的最新技术是基于CycleGAN的人脸转换生成对抗网络。这启发了我们的研究,该研究探索了正面面部合成中两个来自像素变换的模型的性能,Pix2Pix和CycleGAN。我们在Pix2Pix上对五个不同的损失函数进行了实验,以改善其性能,然后在额叶面部合成中提出了新的Pairwise GAN网络。成对GAN使用两个并行的U Net作为生成器,使用PatchGAN作为鉴别器。还讨论了详细的超参数。基于人脸相似性比较的定量测量,我们的结果表明,与默认Pix2Pix模型相比,具有L1损失,梯度差损失和身份损失的Pix2Pix在平均相似性方面可提高2.72。此外,在平均相似性方面,Pairwise GAN的性能比CycleGAN好5.4,比Pix2Pix好9.1。 |
| A Review of Visual Descriptors and Classification Techniques Used in Leaf Species Identification Authors K. K. Thyagharajan, I. Kiruba Raji 植物对生命至关重要。植物科学的主要研究领域包括植物物种识别,使用高光谱图像进行杂草分类,监测植物健康和追踪叶片生长以及叶片信息的语义解释。植物学家通过区分叶片的形状,尖端,基部,叶缘和叶脉,叶片的质地以及复叶的小叶的排列,可以轻松地识别植物种类。由于对专家的需求和对生物多样性的需求不断增长,因此需要一种智能系统来识别和表征叶片,以便仔细检查特定物种,影响它们的疾病,叶片生长方式等。鉴于特征提取是计算机视觉中的一项关键技术,我们回顾了叶片特征提取中的几种图像处理方法。由于计算机无法理解图像,因此需要通过分别分析图像的形状,颜色,纹理和瞬间将它们转换为特征。看起来相同的图像可能会在几何和光度变化方面有所差异。在我们的研究中,我们还将讨论某些机器学习分类器,以分析不同种类的叶子。 |
| Semantic Segmentation of Surface from Lidar Point Cloud Authors Aritra Mukherjee, Sourya Dipta Das, Jasorsi Ghosh, Ananda S. Chowdhury, Sanjoy Kumar Saha 在用于机器人导航的SLAM同时定位和映射领域中,映射环境是一项重要的任务。在这方面,激光雷达传感器可以实时生成点云格式的近乎准确的环境3D地图。尽管数据足以提取与SLAM相关的信息,但是在点云中处理数百万个点在计算上非常昂贵。提出的方法提出了一种快速算法,可用于从云中实时提取语义标记的表面片段,以用于直接导航或更高级别的上下文场景重构。首先,来自旋转的激光雷达的单次扫描用于在线生成二次采样的浊点网格。所生成的网格还用于基于估计的曲面段的那些点的曲面法线计算。提出了一种新颖的表示表面片段的描述符,并利用该描述符在分类器的帮助下确定了片段语义标签的表面类别。这些语义表面片段可以进一步用于场景中对象的几何重构,或者可以用于机器人的优化轨迹规划。将所提出的方法与点云分割方法的数量和最先进的语义分割方法进行比较,以在速度和准确性方面强调其有效性。 |
| Calibration Venus: An Interactive Camera Calibration Method Based on Search Algorithm and Pose Decomposition Authors Wentai Lei, Mengdi Xu.Feifei Hou, Wensi Jiang 在许多应用摄像机的场景中,例如机器人定位和无人驾驶,摄像机校准是最重要的前功之一。由于其可重复性和操作优势,基于平板的交互式校准方法在相机校准领域正变得越来越流行。然而,现有的方法基于主观经验从固定的预定义姿势数据集中选择建议,这会导致一定程度的单方面性。而且,它们没有向用户提供关于如何将板放置在指定姿势的明确说明。 |
| Improving Deep Video Compression by Resolution-adaptive Flow Coding Authors Zhihao Hu 1 , Zhenghao Chen 2 , Dong Xu 2 , Guo Lu 3 , Wanli Ouyang 2 , Shuhang Gu 2 1 College of Software, Beihang University, China, 2 School of Electrical and Information Engineering, The University of Sydney, Australia, 3 School of Computer Science Technology, Beijing Institute of Technology, China 在基于学习的视频压缩方法中,通过开发新的运动矢量MV编码器来压缩像素级光流图是至关重要的问题。在这项工作中,我们提出了一个新的框架,称为“分辨率自适应流编码RaFC”,以有效地全局和局部压缩流图,其中,对于流的输入流图和输出运动特征,我们使用多分辨率表示而不是单分辨率表示。中压编码器。为了全局处理复杂或简单的运动模式,我们的帧级别方案RaFC帧会自动为每个视频帧确定最佳的流图分辨率。为了局部处理不同类型的运动模式,我们称为RaFC块的块级方案还可以为每个局部运动特征块选择最佳分辨率。此外,速率失真准则同时应用于RaFC帧和RaFC块,并选择最佳运动编码模式以进行有效的流编码。在四个基准数据集HEVC,VTL,UVG和MCL JCV上进行的全面实验清楚地证明了在组合RaFC帧和RaFC块进行视频压缩后,我们整个RaFC框架的有效性。 |
| SSKD: Self-Supervised Knowledge Distillation for Cross Domain Adaptive Person Re-Identification Authors Junhui Yin, Jiayan Qiu, Siqing Zhang, Zhanyu Ma, Jun Guo 由于源域和目标域之间的巨大差异,域自适应人员识别ID是一项具有挑战性的任务。为了减少域差异,现有方法主要尝试通过聚类算法为未标记的目标图像生成伪标记。但是,聚类方法往往会带来嘈杂的标签,并且未充分利用未标记图像中丰富的细颗粒细节。在本文中,我们试图通过从未标记图像的多个增强视图中捕获特征表示来提高标签的质量。为此,我们提出了一种自我监督的知识蒸馏SSKD技术,该技术包含两个模块,即身份学习和软标签学习。身份学习探索了未标记样本之间的关系,并通过聚类来预测它们的一个热门标记,从而为可信赖的高清晰图像提供准确的信息。软标签学习将标签视为分布,并以自我监督的方式使图像与若干相关类关联以训练对等网络,其中,缓慢发展的网络是获取软标签的核心,作为对可靠图像的温和约束。最终,两个模块可以通过相互增强并系统地集成来自未标记图像的标签信息来抵抗re ID的标签噪声。在几个适应性任务上的大量实验表明,所提出的方法在很大程度上优于现有方法。 |
| Semi-supervised dictionary learning with graph regularization and active points Authors Khanh Hung Tran, Fred Maurice Ngole Mboula, Jean Luc Starck, Vincent Prost 在最近的十年中,有监督的字典学习引起了人们的极大兴趣,并且在图像分类方面显示出显着的性能改进。但是,一般而言,有监督的学习需要在每个班级使用大量带标签的样本才能获得可接受的结果。为了处理每个班级只有几个标记样本的数据库,使用了半监督学习,该训练在训练阶段也利用了未标记样本。实际上,未标记的样本可以帮助规范学习模型,从而提高分类准确性。在本文中,我们一方面提出了一种基于两大支柱的半监督字典学习新方法,即使用局部线性嵌入将原始数据的流形结构保存到稀疏代码空间中,这可以看作稀疏代码的正则化。另一方面,我们在稀疏代码空间中训练了一个半监督分类器。我们表明,我们的方法比现有的半监督词典学习方法更好。 |
| Interpretation of smartphone-captured radiographs utilizing a deep learning-based approach Authors Hieu X. Le, Phuong D. Nguyen, Thang H. Nguyen, Khanh N.Q. Le, Thanh T. Nguyen 近来,能够自动有效地解释医学图像的计算机辅助诊断系统CAD已经成为近期学术关注的新兴主题。对于射线照相,已经开发了几种基于深度学习的系统或模型来研究多标签疾病识别任务。但是,他们都没有经过培训可以处理智能手机拍摄的胸部X光片。在这项研究中,我们提出了一个系统,该系统包括一系列在新发布的CheXphoto数据集上训练的基于深度学习的神经网络,以解决此问题。拟议的方法取得了令人鼓舞的结果,AUC为0.684,F1平均得分为0.699。据我们所知,这是第一篇发表的研究,表明能够处理智能手机拍摄的射线照片。 |
| Synthesizing brain tumor images and annotations by combining progressive growing GAN and SPADE Authors Mehdi Foroozandeh, Anders Eklund 训练分割网络需要大量带注释的数据集,但是手动注释既耗时又昂贵。我们在这里研究是否可以将噪声对图像GAN和图像对图像GAN的组合用于合成现实的脑肿瘤图像以及相应的肿瘤注释标签,从而大幅增加训练图像的数量。图像到图像GAN的噪声用于合成新的标签图像,而图像到图像GAN从标签图像生成相应的MR图像。我们的结果表明,这两种GAN可以合成看起来很逼真的标签图像和MR图像,并且添加合成图像可以提高分割效果,尽管效果很小。 |
| PolSAR Image Classification Based on Robust Low-Rank Feature Extraction and Markov Random Field Authors Haixia Bi, Jing Yao, Zhiqiang Wei, Danfeng Hong, Jocelyn Chanussot 极化合成孔径雷达PolSAR图像分类已在各种遥感应用中进行了深入研究。但是,今天它仍然是一项艰巨的任务。一个重要的障碍在于PolSAR成像过程中嵌入的斑点效应,这极大地降低了图像的质量,并使分类更加复杂。为此,我们提出了一种新颖的PolSAR图像分类方法,该方法通过低秩LR特征提取消除斑点噪声,并通过Markov随机场MRF增强平滑先验。具体而言,我们采用基于高斯的鲁棒LR矩阵分解混合技术,以同时提取判别特征并消除复杂噪声。然后,通过对所提取的特征应用带数据增强的卷积神经网络来获得分类图,其中隐含了局部一致性,从而减轻了标签不足的问题。最后,我们通过MRF细化分类图以增强上下文平滑度。我们对两个基准PolSAR数据集进行了实验。实验结果表明,该方法具有良好的分类性能和较好的空间一致性。 |
| Coding Facial Expressions with Gabor Wavelets (IVC Special Issue) Authors Michael J. Lyons, Miyuki Kamachi, Jiro Gyoba 我们提出了一种从数字图像中提取有关面部表情信息的方法。该方法使用多方位,多分辨率的Gabor过滤器集对面部表情图像进行编码,这些Gabor过滤器在地形上是有序的并且与面部大致对齐。人类观察者将从该代码得出的相似性空间与从图像的语义等级得出的相似性空间进行比较。有趣的是,图像衍生的相似性空间的低维度结构与情感的绕线模型共享组织特征,这暗示了面部表情的分类和维度表示之间的桥梁。我们的结果还表明,有可能在输入阶段基于地形链接的面部图像的多方向,多分辨率Gabor编码构造面部表情分类器。所提出的代码所表现出的明显的心理合理性在人机界面的设计中也可能有用。 |
| Deep Detection for Face Manipulation Authors Disheng Feng, Xuequan Lu, Xufeng Lin 由于近年来基于深度学习的面部操纵技术的巨大进步,区分真实面孔与视觉逼真的假面孔变得越来越具有挑战性。在本文中,我们介绍了一种深度学习方法来检测面部操作。它包括两个阶段的特征提取和二进制分类。为了更好地区分假面孔和真实面孔,我们在第一阶段采用了三重态损失函数。然后,我们设计一个简单的线性分类网络,以将学习到的对比特征与真实的假脸联系起来。在公共基准数据集上的实验结果证明了该方法的有效性,并表明在大多数情况下,该方法产生的性能要优于最新技术。 |
| An approach to human iris recognition using quantitative analysis of image features and machine learning Authors Abolfazl Zargari Khuzani, Najmeh Mashhadi, Morteza Heidari, Donya Khaledyan 虹膜模式是每个人独特的生物学特征,使其成为人类识别的宝贵而强大的工具。本文通过四个步骤提出了一种有效的虹膜识别框架。 1使用相对总变化结合粗虹膜定位进行虹膜分割,2使用形状密度,FFT,GLCM,GLDM和小波进行特征提取,3使用内核PCA进行特征约简,4使用多层神经网络进行分类以对2000个虹膜图像进行分类来自200名志愿者的CASIA Iris Interval数据集。结果证实了该方案可以提供可靠的预测,准确率高达99.64。 |
| A Unified Approach to Kinship Verification Authors Eran Dahan, Yosi Keller 在这项工作中,我们提出了一种基于深度学习的亲属验证方法,该方法使用统一的多任务学习方案共同学习所有亲属关系。这使我们可以更好地利用亲属验证所特有的小型训练集。我们引入一种新颖的方法来融合亲属图像的嵌入,以避免过度拟合,这是训练此类网络的常见问题。为训练集图像导出自适应采样方案,以解决亲属验证数据集中的固有不平衡。彻底的消融研究证明了我们方法的有效性,该方法在应用于野外家庭,FG2018和FG2020数据集时,通过实验证明其性能优于当代最新的亲属验证结果。 |
| Exploring the Hierarchy in Relation Labels for Scene Graph Generation Authors Yi Zhou, Shuyang Sun, Chao Zhang, Yikang Li, Wanli Ouyang 通过为每个关系分配单个标签,当前方法将关系检测公式化为分类问题。根据这种表述,谓词类别被视为完全不同的类别。但是,与对象标签(其中不同的类具有明确的边界)不同,谓词通常在语义上有重叠。例如,在垂直关系中坐着和站着有共同的含义,但是如何垂直放置这两个对象的细节不同。为了利用谓词类别的固有结构,我们建议首先构建语言层次结构,然后利用层次结构导引特征学习HGFL策略来学习粗粒度级别和细粒度级别的更好的区域特征。此外,我们还提出了层次指导模块HGM,以利用粗粒度级别来指导细粒度级别特征的学习。实验表明,所提出的简单而有效的方法可以在不同数据集中场景图生成任务的Recall 50方面大幅度提高多达33个相对增益,从而改善了几种现有的基线水平。 |
| Map-merging Algorithms for Visual SLAM: Feasibility Study and Empirical Evaluation Authors Andrey Bokovoy, Kirill Muraviev, Konstantin Yakovlev 同时定位和制图,尤其是仅依赖于视频数据vSLAM的同时定位和制图,是一个具有挑战性的问题,已在机器人技术和计算机视觉中进行了广泛研究。最新的vSLAM算法能够构建足够准确的地图,从而使移动机器人能够自主导航未知环境。在这项工作中,我们对与vSLAM相关的重要问题(即地图合并)感兴趣,该问题可能会出现在各种实际重要的场景中,例如在多机器人覆盖场景中。此问题询问是否可以将不同的vSLAM映射合并为一致的单个表示形式。我们研究了现有的2D和3D地图合并算法,并在真实的模拟环境中进行了广泛的实证评估。进行了定性和定量比较,并报告和分析了获得的结果。 |
| Learning semantic Image attributes using Image recognition and knowledge graph embeddings Authors Ashutosh Tiwari, Sandeep Varma 传统上,从文本中提取结构化知识已用于知识库的生成。但是,可以在此过程中利用其他信息源(例如图像)来建立更完整和更丰富的知识库。图像内容和知识图嵌入的结构化语义表示可以提供图像实体之间语义关系的唯一表示。这些年来,将知识图中的已知实体链接起来并使用语言模型学习开放世界图像吸引了很多兴趣。在本文中,我们提出了一种共享学习方法,通过将知识图嵌入模型与图像的识别属性相结合来学习图像的语义属性。提出的模型前提可以帮助我们理解图像实体之间的语义关系,并通过知识图嵌入模型为所提取的实体隐式提供链接。在使用具有有限数据的自定义用户定义知识库的限制下,所提出的模型提出了显着的准确性,并为早期方法提供了新的替代方法。提议的方法是弥合从大量数据中学习的框架与使用有限的谓词来推断新知识的框架之间的差距的一步。 |
| Revisiting the Threat Space for Vision-based Keystroke Inference Attacks Authors John Lim, True Price, Fabian Monrose, Jan Michael Frahm 基于视觉的击键推断攻击是一种旁道攻击,攻击者使用光学设备在其移动设备上记录用户并推断其击键。过去已经研究了这些攻击的威胁空间,但我们认为,这种威胁空间的定义特征(即攻击者的实力)已经过时。以前的工作没有使用经过深度神经网络训练的视觉系统来研究对手,因为这些模型需要大量的训练数据,并且整理此类数据集的成本很高。为了解决这个问题,我们创建了一个大型综合数据集来模拟按键推理攻击的攻击场景。我们表明,首先对合成数据进行预培训,然后对现实生活数据采用转移学习技术,可以提高我们的深度学习模型的性能。这表明这些模型能够从我们的综合数据中学习丰富,有意义的表示形式,并且对综合数据进行训练可以帮助克服针对基于视觉的按键推断攻击而拥有小型,真实生活数据集的问题。对于这项工作,我们专注于单个按键分类,其中输入是按键的框架,而输出是预测的按键。在对我们的综合数据进行CNN预先训练,并在对抗域适应框架中对一小部分现实生活数据进行训练之后,我们能够获得95.6的准确性。模拟器源代码 |
| A CNN Based Approach for the Near-Field Photometric Stereo Problem Authors Fotios Logothetis, Ignas Budvytis, Roberto Mecca, Roberto Cipolla 在不同光源下使用几幅图像重建对象的3D形状是一项非常具有挑战性的任务,尤其是在考虑诸如光传播和衰减,透视图几何形状和镜面光反射之类的现实假设时。解决光度立体PS问题的许多工作通常会放松大多数上述假设。特别是它们忽略了镜面反射和全局照明效果。在这项工作中,我们提出了第一种基于CNN的方法,该方法能够处理光度立体中的这些现实假设。我们将深层神经网络的最新改进用于远场光度学立体声,并使它们适应近场设置。我们通过采用迭代过程进行形状估计来实现此目的,该过程有两个主要步骤。首先,我们训练每个像素的CNN,以根据反射率样本预测表面法线。其次,我们通过积分法线场来计算深度,以迭代地估计光的方向和衰减,该深度用于补偿输入图像以计算下一次迭代的反射率样本。据我们所知,这是第一个能够从高镜面物体准确预测3D形状的近场框架。在合成和实际实验中,我们的方法都优于竞争性的近场光度立体方法。 |
| Micro-Facial Expression Recognition Based on Deep-Rooted Learning Algorithm Authors S. D. Lalitha, K. K. Thyagharajan 面部表情是观察人类情绪的重要线索。面部表情识别已经吸引了许多研究人员多年,但是仍然是一个具有挑战性的话题,因为表情特征会随着头部姿势,环境以及所涉及的不同人物的变化而变化很大。在这项工作中,涉及三个主要步骤来提高微面部表情识别的性能。首先,自适应同态滤波用于面部检测和旋转校正过程。其次,使用微面部特征提取测试图像空间分析的外观变化。运动信息的特征用于面部图像序列中的表情识别。本文提出了一种有效的基于微表情的深度学习MFEDRL分类器,通过学习最佳特征参数来更好地识别自发微表情。该方法包括两个损失函数,如交叉熵损失函数和中心损失函数。然后,将使用识别率和错误度量来评估算法的性能。仿真结果表明,所提方法的预测性能在准确性和均值方面均优于卷积神经网络CNN,深层神经网络DNN,人工神经网络ANN,支持向量机SVM和k最近邻KNN等现有分类器。绝对误差MAE。 |
| Removing the Background by Adding the Background: Towards Background Robust Self-supervised Video Representation Learning Authors Jinpeng Wang, Yuting Gao, Ke Li, Yiqi Lin, Andy J. Ma, Xing Sun 通过从未标记的数据构造替代监督信号,自我监督学习在改善深度神经网络的视频表示能力方面显示出巨大潜力。然而,当前的一些方法倾向于遭受背景欺骗问题,即,预测高度依赖于视频背景而不是运动,从而使得模型容易受到背景变化的影响。为了缓解该问题,我们建议通过添加背景来消除背景影响。也就是说,给定视频,我们随机选择一个静态帧,并将其添加到其他所有帧中,以构建一个分散注意力的视频样本。然后,我们迫使模型拉近分散注意力视频的特征和原始视频的特征,从而显式地限制模型以抵抗背景影响,而将注意力更多地放在运动变化上。另外,为了防止静态帧过多地干扰运动区域,我们限制了该特征与反转视频的时间翻转特征一致,从而迫使模型更多地关注运动。我们称我们的方法为时间敏感性背景擦除TBE。在UCF101和HMDB51上进行的实验表明,与HMDB51和UCF101数据集上的最新方法相比,TBE带来了6.4和4.8的改进。值得注意的是,我们方法的实现是如此简单和整洁,并且可以作为大多数SOTA方法的附加正则化术语而添加,而无需付出太多努力。 |
| Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion Authors Jinpeng Wang, Yuting Gao, Ke Li, Xinyang Jiang, Xiaowei Guo, Rongrong Ji, Xing Sun 我们期望视频表示学习能够捕获的一个重要因素是物体运动,尤其是与图像表示学习相反。但是,我们发现在当前的主流视频数据集中,某些动作类别与发生动作的场景高度相关,从而使模型趋向于退化为仅对场景信息进行编码的解决方案。例如,受过训练的模型可能只是因为看到了场地而忽略了对象在场地上作为啦啦队长跳舞,因此可以将视频预测为正在踢足球。这违背了我们对视频表示学习的初衷,可能会给不容忽视的不同数据集带来场景偏差。为了解决这个问题,我们建议通过两个简单的操作将场景和运动DSM分离,以便更好地关注模型对运动信息的关注。具体来说,我们为每个视频构造一个正向剪辑和一个负向剪辑。与原始视频相比,正片负片的运动不受空间局部干扰和时间局部干扰的影响,但场景不受干扰。我们的目标是将正片拉近,同时将负片推到潜在空间中的原始片段。这样,可以减小场景的影响,同时可以进一步提高网络的时间敏感性。我们在具有不同主干和不同预训练数据集的两个任务上进行了实验,发现我们的方法优于SOTA方法,分别对使用同一主干的UCF101和HMDB51数据集的动作识别任务有了明显的8.1和8.8改进。 |
| Multi-Spectral Image Synthesis for Crop/Weed Segmentation in Precision Farming Authors Mulham Fawakherji, Ciro Potena, Alberto Pretto, Domenico D. Bloisi, Daniele Nardi 有效的感知系统是农用机器人的基本组件,因为它使它们能够正确感知周围的环境并进行有针对性的操作。最新的方法利用最先进的机器学习技术来学习目标任务的有效模型。但是,这些方法需要大量标记数据进行训练。解决此问题的最新方法是通过对抗网络(GAN)进行数据增强,将整个合成场景添加到训练数据中,从而扩大和丰富其信息内容。在这项工作中,我们针对通用数据增强技术提出了一种替代解决方案,将其应用于精准农业中的作物杂草分割的基本问题。从真实图像开始,我们通过将最相关的对象类别(即作物和杂草)替换为其合成的对应对象来创建半人工样本。为此,我们使用条件GAN cGAN,其中通过调节生成对象的形状来训练生成模型。此外,除了RGB数据外,我们还考虑了近红外NIR信息,生成了四通道多光谱合成图像。在三个可公开获得的数据集上进行的定量实验表明,i我们的模型能够生成逼真的植物多光谱图像,并且ii在训练过程中使用此类合成图像可改善现有技术语义分割的卷积性能。网络。 |
| Smoothness Sensor: Adaptive Smoothness-Transition Graph Convolutions for Attributed Graph Clustering Authors Chaojie Ji, Hongwei Chen, Ruxin Wang, Yunpeng Cai, Hongyan Wu 群集技术试图将具有类似属性的对象分组到群集中。聚类属性图的节点(其中每个节点都与一组要素属性相关联)引起了极大的关注。图卷积网络GCN代表了一种有效的方法,可以将节点属性和结构信息的两个互补因子进行集成,以进行属性图聚类。但是,GCN的过度平滑会产生无法区分的节点表示,因此图形中的节点倾向于被分组为更少的群集,并且由于导致的性能下降而带来了挑战。在这项研究中,我们提出了一种基于自适应平滑过渡图卷积的用于属性图聚类的平滑度传感器,该传感器可感测图形的平滑度,并在平滑度饱和后自适应终止当前的卷积,以防止过度平滑。此外,作为图水平平滑度的一种替代方法,提出了一种新颖的,精细的,按节点获得的节点水平平滑度评估,其中根据给定节点的邻域条件以一定的图卷积顺序计算平滑度。另外,设计了一种自我监督标准,同时考虑了群集内的紧密度和群集之间的间隔,以指导整个神经网络训练过程。实验表明,就四个基准数据集的三个不同指标而言,所提出的方法明显优于其他12个现有基准水平。此外,一项广泛的研究揭示了其有效性和效率的原因。 |
| Monitoring Spatial Sustainable Development: semi-automated analysis of Satellite and Aerial Images for Energy Transition and Sustainability Indicators Authors Tim De Jong Statistics Netherlands , Stefano Bromuri Open Universiteit Nederland , Xi Chang Open Universiteit Nederland , Marc Debusschere Statbel , Natalie Rosenski Destatis , Clara Schartner Destatis , Katharina Strauch IT.NRW , Marion Boehmer IT.NRW , Lyana Curier Statistics Netherlands 本报告介绍了在ESS合并成员国的地统计和地理空间信息的ESS行动下进行的DeepSolaris项目的结果。在该项目期间,对几种深度学习算法进行了评估,以检测遥感数据中的太阳能电池板。该项目的目的是评估是否可以开发适用于欧盟不同成员国的深度学习模型。一方面将两个遥感数据源视为航空影像,另一方面将其视为卫星影像。评估了两种深度学习模型,分别是分类模型和对象检测模型。对于深度学习模型的评估,我们使用跨站点评估方法对深度学习模型进行评估,该模型在一个地理区域内进行训练,然后在以前算法未见的不同地理区域上进行评估。此外,还进行了两次跨站点评估,其中两次在荷兰接受培训的深度学习模型都在德国进行了评估,反之亦然。尽管深度学习模型能够成功检测太阳能电池板,但错误检测仍然是一个问题。此外,以跨边界方式评估时,模型性能会急剧下降。因此,训练一个可以在欧盟不同国家/地区可靠运行的模型是一项艰巨的任务。话虽如此,这些模型检测到了当前太阳能电池板寄存器中不存在的相当多的太阳能电池板,因此已经可以按原样使用以帮助减少检查这些寄存器中的体力劳动。 |
| Abstractive Information Extraction from Scanned Invoices (AIESI) using End-to-end Sequential Approach Authors Shreeshiv Patel, Dvijesh Bhatt 机器学习和深度学习领域的最新发展使我们能够生成更高精度的OCR模型。光学字符识别OCR是从文档和扫描的图像中提取文本的过程。为了简化文档数据,我们对收款人姓名,总金额,地址等数据感兴趣。提取的信息有助于全面了解数据,这对于快速文档搜索,数据库中的高效索引,数据分析,使用AIESI,我们可以省去人工从扫描文档中提取关键参数的工作。从扫描的发票中提取抽象信息AIESI是从扫描的收据中提取信息(例如日期,总额,收款人姓名等)的过程。在本文中,我们提出了一种改进的方法,可以使用Word wise BiLSTM集成发票中的所有视觉和文本特征,以提取关键发票参数。 |
| Generator Versus Segmentor: Pseudo-healthy Synthesis Authors Zhang Yunlong, Lin Xin, Sun Liyan, Zhuang Yihong, Huang Yue, Ding Xinghao, Liu Xiaoqing, Yu Yizhou 伪健康合成被定义为从病理图像合成对象特定的健康图像,其应用范围从分割到异常检测。近年来,提出用于伪健康合成的现有基于GAN的方法旨在消除合成图像与健康图像之间的全局差异。在本文中,我们讨论了这些方法的问题,分别是样式转移和工件。为了解决这些问题,我们考虑了病变与正常组织之间的局部差异。为了实现这一目标,我们提出了一种对抗训练机制,可以交替训练生成器和分段器。分割器受过训练以区分合成病变,即合成图像中与病理组织中的病变相对应的正常组织中的区域,而生成器受过训练以通过将病变区域转变成无病变的形态并保持正常而欺骗分割器同时组织。在公共数据集BraTS和LiTS上进行的定性和定量实验结果表明,该方法通过保留样式并去除伪像而优于最新方法。我们的实施可在以下位置公开获得 |
| Short-Term and Long-Term Context Aggregation Network for Video Inpainting Authors Ang Li, Shanshan Zhao, Xingjun Ma, Mingming Gong, Jianzhong Qi, Rui Zhang, Dacheng Tao, Ramamohanarao Kotagiri 视频修复旨在恢复视频的缺失区域,并具有许多应用程序,例如视频编辑和对象删除。然而,现有方法或者遭受不正确的短期上下文聚合的困扰,或者很少探索长期帧信息。在这项工作中,我们提出了一种新颖的上下文聚合网络,可以有效地利用短期和长期帧信息进行视频修复。在编码阶段,我们提出边界感知的短期上下文聚合,它从邻居帧中将与缺失区域的边界上下文紧密相关的局部区域对齐并聚合到目标帧中。此外,我们提出了动态长期上下文聚合,以使用长期帧特征对编码阶段生成的特征图进行全局优化,这些特征在整个修复过程中会动态更新。实验表明,该方法优于最新方法,修复效果更好,修复速度更快。 |
| YOLObile: Real-Time Object Detection on Mobile Devices via Compression-Compilation Co-Design Authors Yuxuan Cai, Hongjia Li, Geng Yuan, Wei Niu, Yanyu Li, Xulong Tang, Bin Ren, Yanzhi Wang 物体检测技术的快速发展和广泛应用引起了对物体检测器的准确性和速度的关注。然而,当前的对象检测工作的当前状态要么是使用大型模型的精度导向,而是导致高等待时间,要么是使用轻量模型的速度导向,但牺牲了精度。在这项工作中,我们提出了YOLObile框架,该框架是通过压缩编译协同设计在移动设备上进行实时对象检测的。针对任何内核大小,提出了一种新颖的块打孔修剪方案。为了提高移动设备上的计算效率,采用了GPU CPU协作方案以及高级编译器辅助的优化。实验结果表明,我们的修剪方案以49.0 mAP达到YOLOv4压缩率的14倍。在我们的YOLObile框架下,我们在Samsung Galaxy S20上使用GPU实现了17 FPS推理速度。通过合并我们提出的GPU CPU协作方案,推理速度提高到19.1 FPS,并且比原始YOLOv4快5倍。 |
| RGB2LIDAR: Towards Solving Large-Scale Cross-Modal Visual Localization Authors Niluthpol Chowdhury Mithun, Karan Sikka, Han Pang Chiu, Supun Samarasekera, Rakesh Kumar 通过将地面RGB图像与呈现为深度图像的地理参考空中LIDAR 3D点云进行匹配,我们研究了大规模跨模态视觉本地化的重要但尚未探索的问题。先前的工作在较小的数据集上进行了演示,因此无法扩展到大规模应用。为了进行大规模评估,我们引入了一个新的数据集,其中包含550K对,覆盖143 km 2的RGB区域和空中LIDAR深度图像。我们提出了一种新颖的基于联合嵌入的方法,该方法有效地结合了两种模态的外观和语义提示,以处理剧烈的跨模态变化。在建议的数据集上进行的实验表明,我们的模型在从14km 2区域收集的50K个位置对的大型测试集中的匹配中获得了5分的中位数排名。这表示在性能和规模上比以前的工作有了重大进步。我们以定性的结论来强调这一任务的挑战性以及所提出模型的好处。我们的工作为进一步研究跨模式视觉本地化奠定了基础。 |
| AttnGrounder: Talking to Cars with Attention Authors Vivek Mittal 我们提出了Attention Grounder AttnGrounder,这是用于视觉接地任务的单阶段端到端可训练模型。视觉接地旨在基于给定的自然语言文本查询来定位图像中的特定对象。与以前的为每个图像区域使用相同文本表示形式的方法不同,我们使用视觉文本注意模块,该模块将给定查询中的每个单词与对应图像中的每个区域相关联,以构造区域相关的文本表示形式。此外,为了提高模型的定位能力,我们使用视觉文本注意模块在所引用的对象周围生成注意蒙版。使用使用提供的地面真实坐标生成的矩形遮罩将注意遮罩训练为辅助任务。我们在Talk2Car数据集上评估了AttnGrounder,并显示出比现有方法提高了3.26。 |
| A Progressive Sub-Network Searching Framework for Dynamic Inference Authors Li Yang, Zhezhi He, Yu Cao, Deliang Fan 已经开发了许多技术(例如模型压缩)来使深度神经网络DNN推理更有效。尽管如此,DNN仍然缺乏出色的运行时动态推理功能,无法使用户权衡准确性和计算复杂性,即基于动态需求和环境在模型部署后目标硬件上的延迟。这种研究方向最近引起了极大的关注,其中一种实现是通过多目标函数来训练目标DNN,该目标函数由来自多个子网的交叉熵项组成。我们在这项工作中的调查表明,动态推理的性能高度依赖于子网抽样的质量。为了构建动态DNN并以最低的搜索成本搜索多个高质量子网,我们提出了一种渐进式子网搜索框架,该框架嵌入了多种有效技术,包括可训练的噪声排名,信道组和微调阈值设置,网重新选择。所提出的框架使目标DNN具有更好的动态推理能力,通过对不同网络结构的综合实验,胜过CIFAR 10和ImageNet数据集的先前工作。以ResNet18为例,与相同模型大小的ImageNet数据集相比,我们提出的方法与先前流行的普遍可简化网络相比,动态推理精度更高,最大可达4.4,平均可达2.3。 |
| Inverse mapping of face GANs Authors Nicky Bayat, Vahid Reza Khazaie, Yalda Mohsenzadeh 生成对抗网络GAN从随机潜在向量合成逼真的图像。尽管许多研究探索了GAN的各种训练配置和体系结构,但对生成模型进行反演以提取给定输入图像的潜在向量的问题尚未得到充分研究。尽管每个给定的随机向量仅存在一个生成的图像,但是从图像到其恢复的潜在向量的映射可以具有多个解决方案。我们训练ResNet架构来恢复给定脸部的潜在向量,该潜在向量可用于生成与目标几乎相同的脸部。我们使用感知损失将面部细节嵌入恢复的潜在向量中,同时使用像素损失来保持视觉质量。关于潜矢量恢复的绝大多数研究仅在生成的图像上表现良好,我们认为我们的方法可用于确定真实人脸与包含大多数重要面部样式细节的潜空间矢量之间的映射。此外,我们提出的方法项目以高保真度和速度为其潜在空间生成了面孔。最后,我们展示了我们的方法在真实面孔和生成面孔上的性能。 |
| KSM: Fast Multiple Task Adaption via Kernel-wise Soft Mask Learning Authors Li Yang, Zhezhi He, Junshan Zhang, Deliang Fan 深度神经网络DNN在学习新任务时可能会忘记有关早期任务的知识,这被称为文本灾难性遗忘。尽管最近的持续学习方法能够缓解玩具大小的数据集上的灾难性问题,但将其应用于现实世界中的问题时,仍有一些问题尚待解决。最近,基于快速掩模的学习方法例如。背负引用Mallya2018piggyback旨在通过快速学习仅二进制二进制智能掩码,同时保持骨干模型固定来解决这些问题。但是,二进制掩码对新任务的建模能力有限。 Hung2019compacting的最新工作提出了一种基于压缩增长的方法CPG,该方法通过部分训练主干模型来提高新任务的准确性,但是训练成本较高,因此无法部署到流行的最新边缘移动学习中。这项工作的主要目标是在持续学习环境中同时实现快速,高精度的多任务适应。因此,我们提出了一种新的训练方法,称为textit内核智能软掩码KSM,该方法使用相同的主干模型为每个任务学习内核智能混合二进制和实值软掩码。可以将这种软掩码视为二进制掩码和适当缩放的实数值张量的叠加,这提供了更丰富的表示能力,而无需低级内核支持即可满足低硬件开销的目标。我们针对多个基准数据集验证了KSM的最新技术水平,例如Piggyback,Packnet,CPG等,在准确性和培训成本上均显示出良好的改进。 |
| Deep Hiearchical Multi-Label Classification Applied to Chest X-Ray Abnormality Taxonomies Authors Haomin Chen, Shun Miao, Daguang Xu, Gregory D. Hager, Adam P. Harrison CXR是至关重要的且非常普通的诊断工具,导致对CAD解决方案的深入研究。但是,尊重和纳入临床分类法的高分类准确性和有意义的模型预测对于CAD可用性至关重要。为此,我们提出了一种用于CXR CAD的深层HMLC方法。与其他分层系统不同,我们表明,首先训练网络以直接对条件概率进行建模,然后用无条件概率对其进行完善,这对于提高性能至关重要。此外,我们还针对无条件概率公式化了数值稳定的交叉熵损失函数,从而改善了性能。最后,我们证明了HMLC可以作为管理丢失或不完整标签的有效手段。据我们所知,我们是第一个将HMLC应用于医学成像CAD的公司。我们广泛评估了我们从PLCO数据集的CXR臂中检测异常标签的方法,该臂包括198,000多个手动注释的CXR。使用完整标签时,我们报告的平均AUC为0.887,是该数据集迄今报告的最高值。这些结果得到了PadChest数据集的辅助实验的支持,在该实验中,我们还报告了分别在强平坦分类器上的AUC和AP分别有1.2和4.1的显着改进。最后,我们证明了我们的HMLC方法可以更好地处理标记不完整的数据。这些性能的改进,再加上分类学预测的内在作用,表明我们的方法代表了CXR CAD向前迈出的有益一步。 |
| 3D Reconstruction and Segmentation of Dissection Photographs for MRI-free Neuropathology Authors Henry Tregidgo, Adria Casamitjana, Caitlin Latimer, Mitchell Kilgore, Eleanor Robinson, Emily Blackburn, Koen Van Leemput, Bruce Fischl, Adrian Dalca, Christine Mac Donald, Dirk Keene, Juan Eugenio Iglesias 神经影像与神经病理学的关联NTNC承诺能够将病理学的微观特征转移到MRI体内成像中,从而最终增强临床护理。传统上,NTNC需要进行体积MRI扫描,该扫描可以离体或在死亡前的很短时间内获取。不幸的是,离体MRI既困难又昂贵,而且很少有足够质量的近期验尸扫描。为了弥合这一差距,我们介绍了从脑解剖照片中3D重建和分割全脑图像体积的方法,这些照片通常是在许多脑库和神经病理学部门获得的。通过联合注册框架可实现3D重建,该框架使用MRI以外的参考体积。该体积可以代表手头的样品(例如表面3D扫描),也可以代表一般人群的概率图集。此外,我们提出了一种贝叶斯方法,将3D重建的摄影量分割成36个神经解剖结构,这对于照片内部和照片之间的亮度不均匀具有鲁棒性。我们使用Dice得分和体积相关性,在具有24个大脑的数据集上评估我们的方法。结果表明,在许多体积分析中,夹层摄影是离体MRI的有效替代品,为无MRI NTNT(包括回顾性数据)开辟了道路。该代码位于 |
| Label-Free Segmentation of COVID-19 Lesions in Lung CT Authors Qingsong Yao, Li Xiao, Peihang Liu, S. Kevin Zhou 带注释的图像的稀缺性阻碍了自动解决方案的构建,从而无法从CT可靠地诊断和评估COVID 19。为了减轻数据注释的负担,我们在此提出了一种通过像素水平异常模型在CT中分割COVID 19病变的无标签方法,该模型从正常的CT肺部扫描中挖掘了相关知识。我们的建模灵感来自于观察发现,位于病变所在区域的高强度范围内的气管和血管部分表现出很强的模式。为了促进在像素水平上学习此类模式,我们使用了一系列令人惊讶的简单操作来合成病变,并将合成的病变插入正常的CT肺部扫描中以形成训练对,从中我们学习一个常态转换网络NormNet,它将异常转变为图像恢复正常。我们在三个不同的数据集上进行的实验验证了NormNet的有效性,该性能明显优于各种无监督的异常检测UAD方法。 |
| Automatic elimination of the pectoral muscle in mammograms based on anatomical features Authors Jairo A. Ayala Godoy, Rosa E. Lillo, Juan Romo 数字化乳房X线检查是用于早期检测人乳腺组织异常的最流行技术。通过计算方法分析乳房X光照片时,胸肌的存在可能会影响乳腺病变检测的结果。这个问题在中斜肌MLO中尤为明显,在MLO中,胸肌占了乳房X线照片的大部分。因此,识别和消除胸肌是改善乳房组织自动识别的必要步骤。在本文中,我们提出了一种基于解剖特征的方法来解决这个问题。我们的方法包括两个步骤:1去除噪音元素(例如标签,标记,划痕和楔形物)的过程,以及2基于Beta分布的强度转换的应用。用来自乳腺图像分析协会微型MIAS数据库的322幅乳腺X线照片和一组84幅乳腺X线照片测试了该新方法,先前已针对其计算了面积归一化误差。结果表明该方法具有很好的性能。 |
| A Multisensory Learning Architecture for Rotation-invariant Object Recognition Authors Murat Kirtay, Guido Schillaci, Verena V. Hafner 这项研究通过采用由iCub机器人构建的新型数据集,提出了一种用于对象识别的多传感器机器学习架构,该机器人配备了三个摄像头和一个深度传感器。所提出的体系结构结合了卷积神经网络以形成表示形式,即灰度彩色图像的特征和用于处理深度数据的多层感知器算法。为此,我们旨在学习不同模式(例如颜色和深度)的联合表示,并将其用于识别对象。我们通过对使用不同传感器的输入和最先进的数据融合技术(即决策级融合)分别训练的模型进行基准测试得出的结果进行基准测试,从而评估所提出架构的性能。结果表明,与使用来自单一模态和决策级多模态融合方法的输入的模型相比,我们的体系结构提高了识别精度。 |
| VC-Net: Deep Volume-Composition Networks for Segmentation and Visualization of Highly Sparse and Noisy Image Data Authors Yifan Wang, Guoli Yan, Haikuan Zhu, Sagar Buch, Ying Wang, Ewart Mark Haacke, Jing Hua, Zichun Zhong 我们工作的动机是提出一种新的可视化指导的计算范例,以结合直接3D体积处理和体积渲染线索以进行有效的3D探索,例如在体内提取和可视化微观结构。但是,由于其高稀疏,嘈杂和复杂的拓扑变化,提取和可视化高保真3D血管结构仍然具有挑战性。在本文中,我们提出了一种端到端的深度学习方法VC Net,该方法通过将最大强度投影MIP生成的图像成分嵌入3D体积图像学习中以增强性能,从而可靠地提取3D微血管。核心新颖之处在于自动利用体积可视化技术MIP来增强深度学习级别的3D数据探索。 MIP嵌入功能可以增强局部血管信号,并适应血管的几何可变性和可扩展性,这在微血管跟踪中至关重要。提出了一种多流卷积神经网络,分别学习3D体积和2D MIP特征,然后通过将MIP特征不投影到3D体积嵌入空间中来探索它们在联合体积组成嵌入空间中的相互依赖性。提出的框架可以更好地捕获小型微血管并改善血管连通性。据我们所知,这是第一个构建联合卷积嵌入空间的深度学习框架,在该框架中,可以探索并协同集成基于体积渲染的2D投影和3D体积计算出的血管概率。将实验结果与传统3D血管分割方法以及公共和实际患者微脑血管图像数据集上的深度学习现状进行了比较。我们的方法证明了在强大的MR动脉造影和静脉造影诊断血管疾病中的潜力。 |
| Mathematical Morphology via Category Theory Authors Hossein Memarzadeh Sharifipour, Bardia Yousefi 数学形态学为图像处理领域贡献了许多有利可图的工具。这些方法中的某些被认为是许多应用程序中数据处理的基本但最重要的基础。在本文中,我们利用范畴论中的极限和共极限保函,修改了形态学运算的基础,例如膨胀和腐蚀。采用众所周知的图像矩阵表示形式,称为Mat的矩阵类别可以表示为图像。通过将Mat扩展到各种半环(例如布尔和最大半环)上,可以使用Mat中的分类张量积来得出二进制和灰度图像的经典定义。进行扩张操作后,可以使用著名的张量hom附加来达到腐蚀。这种方法使我们能够使用除布尔和最大半环以外的不同半环来定义由矩阵表示的两个图像之间的新型扩张和腐蚀。从范畴论的形态学操作观点也可以阐明数学形态学是线性逻辑模型的主张概念。 |
| Towards the Quantification of Safety Risks in Deep Neural Networks Authors Peipei Xu, Wenjie Ruan, Xiaowei Huang 当将深度神经网络应用于关键领域时,已经引起了人们对深度神经网络的安全关注。在本文中,我们通过要求将网络决策与人类感知保持一致来定义安全风险。为了启用用于量化安全风险的通用方法,我们定义了通用安全属性并将其实例化以表示各种安全风险。为了量化风险,我们采用安全规范球的最大半径,其中不存在安全风险。最大安全半径的计算被简化为它们各自的Lipschitz度量的计算,即要计算的量。除了已知的对抗性示例,可达性示例和不变性示例外,在本文中,我们还确定了新的一类风险不确定性示例,人类可以在其中轻松辨别,但网络不确定。我们开发了一种算法,该算法受无导数优化技术的启发,并通过基于GPU的张量并行化来加速,以支持有效地计算指标。我们对几个基准神经网络进行评估,包括ACSC Xu,MNIST,CIFAR 10和ImageNet网络。实验表明,我们的方法在紧密性和计算效率上可以在安全性量化上达到竞争性能。重要的是,作为一种通用方法,我们的方法可以应对多种安全风险,并且不受神经网络结构的限制。 |
| Extracting Optimal Solution Manifolds using Constrained Neural Optimization Authors Gurpreet Singh, Soumyajit Gupta, Matthew Lease 约束优化解决方案算法仅限于基于点的解决方案。实际上,必须满足单个或多个目标,其中目标函数和约束都可以是非凸的,从而导致多个最优解。现实世界中的场景包括作为隐函数的相交曲面,高光谱分解和帕累托最优前沿。当面对非凸形式时,局部或全局凸化是一种常见的解决方法。但是,这种方法通常仅限于严格的功能类别,与之相反的功能导致对原始问题的次优解决方案。我们提出了将最佳集合提取为近似流形的神经解决方案,其中未修改的,非凸的目标和约束定义为建模者指导的,领域已知的L 2损失函数。由于建模人员可以根据特定领域中已知的分析形式来确认结果,因此可提高解释性。我们提出了综合和现实的案例来验证我们的方法,并在准确性和计算效率方面与已知的求解器进行基准标记比较。 |
| Attention Cube Network for Image Restoration Authors Yucheng Hang, Qingmin Liao, Wenming Yang, Yupeng Chen, Jie Zhou 近年来,深度卷积神经网络CNN已被广泛用于图像复原中并获得了巨大的成功。但是,大多数现有方法仅限于局部接受域和对不同类型信息的平等对待。此外,现有的方法总是使用多监督方法来聚合不同的特征图,这不能有效地聚合分层的特征信息。为了解决这些问题,我们提出了一个用于图像恢复的注意力多维数据集网络A CubeNet,以实现更强大的特征表达和特征相关学习。具体而言,我们从空间维度,渠道维度和层次维度三个维度设计了一种新颖的注意力机制。自适应空间注意力分支ASAB和自适应通道注意力分支ACAB组成了自适应双重注意力模块ADAM,它可以捕获远程空间和通道方面的上下文信息,以扩展接收范围并区分不同类型的信息,从而实现更有效的特征表示。此外,自适应分层注意模块AHAM可以捕获远程分层上下文信息,以根据全局上下文按权重灵活地聚合不同的特征图。 ADAM和AHAM协作在注意力结构中形成注意力,这意味着ASAB和ACAB会增强AHAM的输入。实验证明,在定量比较和视觉分析方面,我们的方法优于最新的图像恢复方法。 |
| How Much Can We Really Trust You? Towards Simple, Interpretable Trust Quantification Metrics for Deep Neural Networks Authors Alexander Wong, Xiao Yu Wang, Andrew Hryniowski 建立可信赖的深度神经网络的关键步骤是信任量化,在此我们要问一个问题:我们可以信任一个深度神经网络多少?在这项研究中,我们通过引入一套用于度量的度量标准,朝着简单,可解释的度量标准迈出了一步在回答一系列问题时,根据其行为评估深度神经网络的总体可信度。我们进行了一次思想实验,探讨了与信任有关的关于信任与信任的两个关键问题:1我们对拥有非常自信的错误回答的演员有多少信任,以及2我们对犹豫不决给出正确答案的演员有多信任?所获得的洞察力,我们引入问题答案信任的概念,以基于正确和不正确答案场景下的自信行为来量化单个答案的可信度,并引入信任密度的概念来表征单个答案场景的整体信任度。我们进一步介绍了信任谱的概念,用于代表针对正确和错误回答的问题的可能答案场景的整体信任。最后,我们介绍NetTrustScore,这是一个概括总体可信赖性的标量指标。这套指标与过去研究信任与信心之间关系的社会心理学研究相吻合。利用这些指标,我们可以量化几种知名的深度神经网络体系结构的图像识别的可信度,以更深入地了解信任在哪里破裂。拟议的指标绝不是完美的,但希望是将对话推向更好的指标,以帮助指导从业者和监管者生产,部署和认证深度学习解决方案,这些解决方案可以在现实世界的关键任务场景中运行。 |
| Multi-Channel Potts-Based Reconstruction for Multi-Spectral Computed Tomography Authors Lukas Kiefer, Stefania Petra, Martin Storath, Andreas Weinmann 我们考虑在多光谱X射线计算机断层扫描CT的设置中,通过光子计数和能量鉴别探测器执行的测量来重建多通道图像。我们的目标是利用已知在多光谱CT图像的通道之间存在的强结构相关性。为此,在联合重建所有通道之前,我们采用多通道Potts。该先验产生具有强相关通道的分段常数解。特别地,边缘被强制为在整个频道上具有相同的空间位置,这比基于TV的方法更具优势。我们在变体Potts模型的上下文中在两个框架中考虑了Potts先验,在扰动基本迭代最小二乘法求解器迭代的Potts优势方法中考虑了b。我们确定乘数ADMM方法的交替方向方法以及特别适合的Potts高级共轭梯度方法。在数值实验中,我们在实际模拟的多光谱CT数据上将基于Potts先验的方法与现有的TV类型方法进行了比较,并获得了复合固体的改进重建方法。 |
| Segmentation of Lungs in Chest X-Ray Image Using Generative Adversarial Networks Authors Faizan Munawar, Shoaib Azmat, Talha Iqbal, Christer Gr nlund, Hazrat Ali 胸部X射线CXR是一种低成本的医学成像技术。与MRI,CT和PET扫描相比,它是识别许多呼吸系统疾病的常用程序。本文介绍了使用生成对抗网络GAN在给定的CXR上执行肺分割的任务。 GAN通常通过学习从一个域到另一个域的映射来生成现实数据。在我们的工作中,训练了GAN的生成器以生成给定输入CXR的分段掩码。鉴别器区分地面真相和生成的掩码,并通过对抗损失度量更新生成器。目的是为输入CXR生成遮罩,与地面真值遮罩相比,这些遮罩要尽可能逼真。使用分别称为D1,D2,D3和D4的四个不同的鉴别器对模型进行训练和评估。在三个不同的CXR数据集上的实验结果表明,所提出的模型能够获得0.9740的骰子得分和0.943的IOU得分,这比其他已报道的最新技术水平要好。 |
| Efficient Folded Attention for 3D Medical Image Reconstruction and Segmentation Authors Hang Zhang, Jinwei Zhang, Rongguang Wang, Qihao Zhang, Pascal Spincemaille, Thanh D. Nguyen, Yi Wang 近来,基于深度神经网络的3D医学图像重建MIR和分割MIS已经取得了可喜的成果,并且注意力机制已经被进一步设计为捕获全局上下文信息以提高性能。但是,大尺寸的3D体积图像对传统注意力方法提出了巨大的计算挑战。在本文中,我们提出了一种折叠注意力FA方法,以提高传统注意力方法在3D医学图像上的计算效率。主要思想是我们使用具有四个排列的张量折叠和展开操作来构建四个小的子亲和力矩阵,以近似原始亲和力矩阵。通过FA的四个连续的子关注模块,特征张量中的每个元素都可以聚合来自所有其他元素的空间通道信息。与传统的注意力方法相比,FA在准确性方面有一定程度的提高,可以大大降低计算复杂度和GPU内存消耗。我们证明了我们的方法在3D MIR和MIS的两个具有挑战性的任务上的优越性,即定量药敏图谱和多发性硬化病灶分割。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
Interesting:
利用级联方式实现深度估计, 将深度图的不同深度区域分离出来进行独立训练实现更为精细的结果预测。首先粗略预测深度,而后基于这个深度分层,并对不同深度区域层进行预测,最后将结果融合。主要是基于不同深度的精度应该由不同的模型来描述这样的考虑。(from 浙江大学)
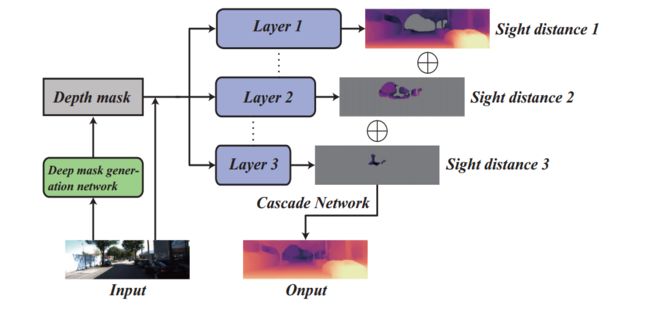
模型的具体细节,首先用基础网络来生成不同距离的区域,而后利用后处理的不同层来处理不同深度,最后进行融合:
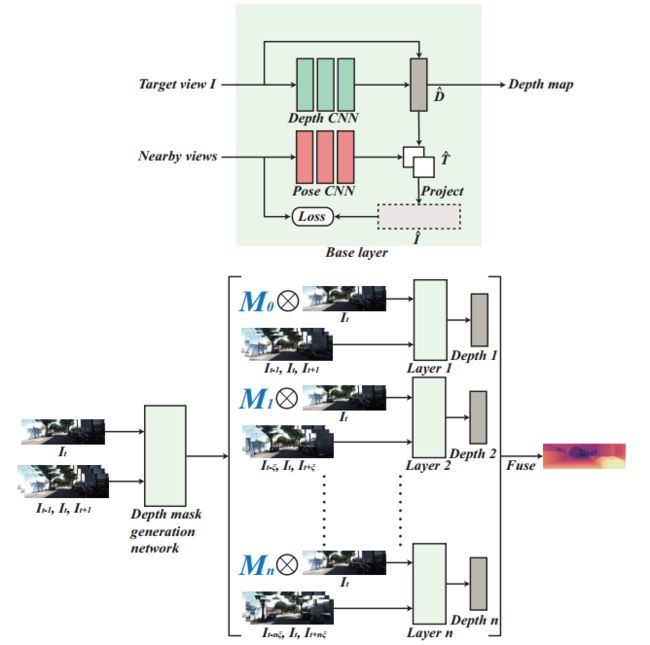
不同深度下的mask:

这个论文启发了,可以针对不同的区域使用不同的模型来处理。利用粗糙的前处理来划分区域,随后利用特异性的模型来进行进一步处理。
这个技巧可以与不同训练批次使用不同学习率(开始大后面小)、不同层使用不同权重一起结合使用。
以及权重轮训(随训练变化),一开始的时候某些阶段权重大、后期训练则让权重向更后端倾斜。
AIM 2020 Challenge 大比例超分辨率算法汇总, (from 苏黎世理工与悉尼大学等)
各个优胜团队的算法框架

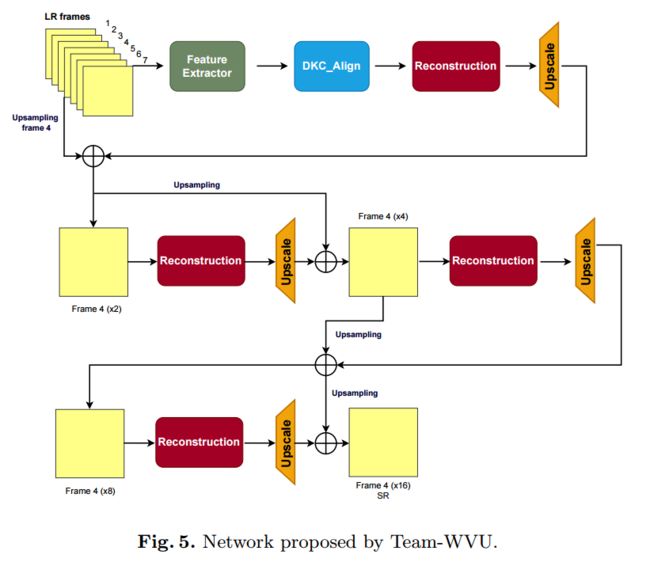
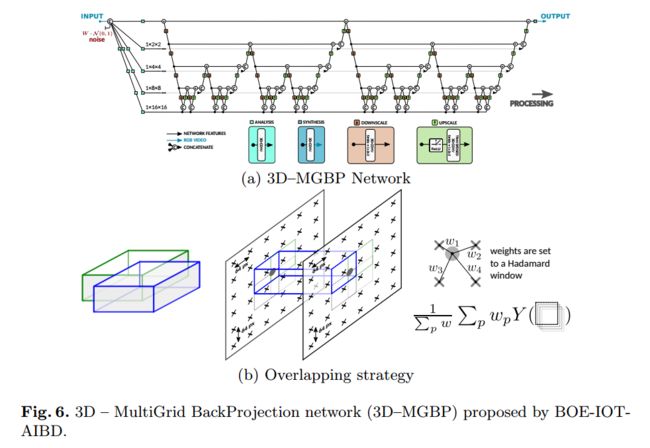
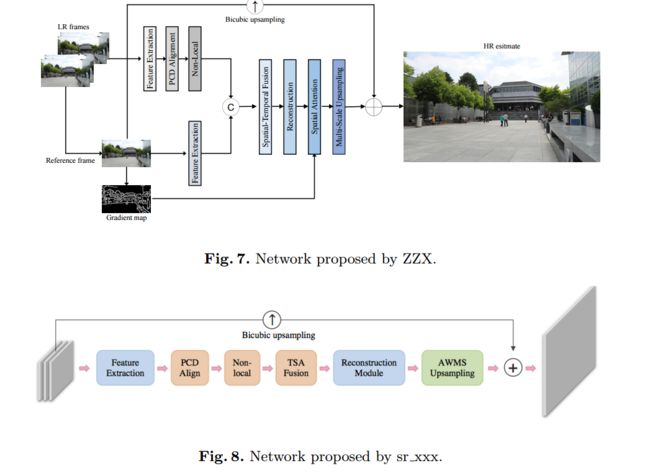
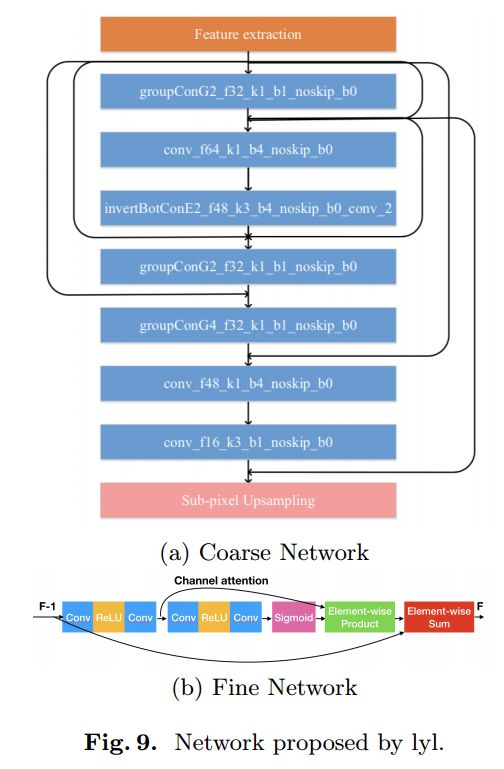
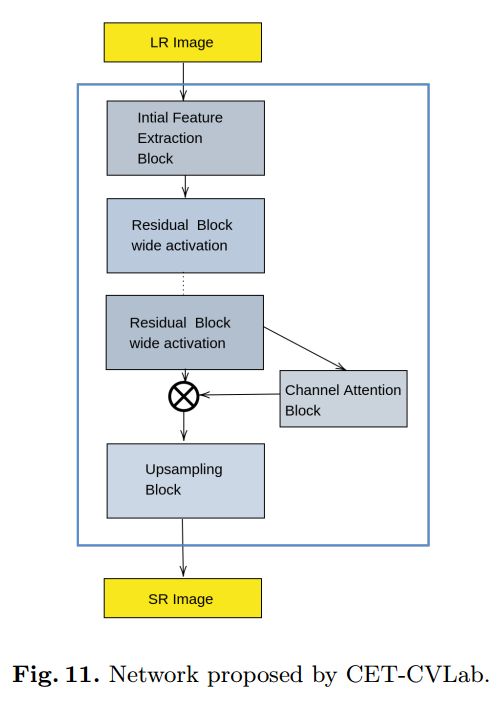

, (from )
, (from )
, (from )
pic from pexels.com