py-faster-rcnn文件读取
py-faster-rcnn文件读取
环境:caffe,python版本;[代码链接]//github.com/rbgirshick/py-faster-rcnn>
本篇文章主要介绍rbg大神的faster-rcnn模型进行训练时数据库读取与生成部分。 faster-rcnn代码的主要目录结构如下:
├── caffe-fast-rcnn 本次项目所用的caffe版本
├── data
│ ├── demo
│ └── scripts //获取数据的脚本
├── experiments
│ ├── cfgs
│ ├── logs //存放日志文件
│ └── scripts //存放训练脚本
├── lib
│ ├── datasets
├── models
│ ├── coco
│ └── pascal_voc //pascal_voc和coco是两种数据集的格式
│ ├── VGG16
│ │ ├── faster_rcnn_alt_opt //alt_opt和end2end以及fast_rcnn是三种训练方法
│ │ ├── faster_rcnn_end2end
│ │ └── fast_rcnn
│ ├── VGG_CNN_M_1024
│ └── ZF //ZF VGG16 和M_1024是三种训练模型
└── tools由于本片文章主要讲解训练的数据如何以及数据库的生成,我们打开数据训练模型的脚本。
py-faster-rcnn/experiments/scripts/faster_rcnn_end2end.sh
time ./tools/train_net.py --gpu ${GPU_ID} \ #time计算执行train_net.py所需时间,训练时传进来6个参数
--solver models/${
PT_DIR}/${
NET}/faster_rcnn_end2end/solver.prototxt \
--weights data/imagenet_models/${
NET}.v2.caffemodel \
--imdb ${
TRAIN_IMDB} \ #TRAIN_IMDB = "voc_2007_trainval"
--iters ${
ITERS} \
--cfg experiments/cfgs/faster_rcnn_end2end.yml \
${EXTRA_ARGS}
imdb 参数为voc_2007_trainval,指出调用的训练集的名字。然后转到py-faster-rcnn/tools/train_net.py文件的104行。可以看到combined_roidb函数传入数据集的名字然后返回数据集,imdb是整个项目的数据库包含比如图片的路径,图片名称的索引接下来我们还会详细讲解。
imdb, roidb = combined_roidb(args.imdb_name) #args.imdb_name = "voc_2007_trainval"接下来我们看combined_roidb函数的定义
def combined_roidb(imdb_names): #imdb_names='voc_2007_trainval'
def get_roidb(imdb_name): #imdb_name = 'voc_2007_trainval'
imdb = get_imdb(imdb_name) #通过工厂类获取数据库信息
print 'Loaded dataset `{:s}` for training'.format(imdb.name) #加载数据集用于训练 imdb.name = voc_2007_trainval
imdb.set_proposal_method(cfg.TRAIN.PROPOSAL_METHOD) #cfg.TRAIN.PROPOSAL_METHOD = 'selective_search'
print 'Set proposal method: {:s}'.format(cfg.TRAIN.PROPOSAL_METHOD) #设置训练方法
roidb = get_training_roidb(imdb)#获得训练数据
return roidb
roidbs = [get_roidb(s) for s in imdb_names.split('+')] #列表生成式 s = "voc_2007_trainval"
roidb = roidbs[0]
if len(roidbs) > 1:
for r in roidbs[1:]:
roidb.extend(r)
imdb = datasets.imdb.imdb(imdb_names)
else:
imdb = get_imdb(imdb_names)
return imdb, roidb
该函数首先进入get_imdb函数中,
def get_imdb(name): # name = 'voc_2007_trainval
if not __sets.has_key(name):
raise KeyError('Unknown dataset: {}'.format(name))
return __sets[name]()
# __sets是一个字典,key是数据集的名称,value是一个函数指针。该函数返回一个set字典,通过下面的内容可以看到set字典是存储的匿名函数的指针,也就是set字典中的key值存放的是数据集的名称,value值存放的是pascal_voc构造函数的指针,所以get_lmdb函数返回的是pascal_voc类,所以imdb就是pascal_voc类的实例。
__sets[name] = (lambda split=split, year=year: pascal_voc(split, year))我们转到py-faster-rcnn/lib/datasets/pascal_voc.py文件中,该文件定义了pascal_voc类,该类中定义的图片的读取路径,读取标签xml路径,读取图片索引index,图片索引是所有图片的名字,事先存放在trainval.txt文件,imdb读取图片索引后,生成一个列表,这个根据列表元素可一返回图片的名字,这是imdb初始化完成,但是imdb的成员roidb还是空的,并没有数据填充,返回到train_net.py文件中看到,roidb的初始化在get_training_roidb中。
print 'Set proposal method: {:s}'.format(cfg.TRAIN.PROPOSAL_METHOD) #设置训练方法
roidb = get_training_roidb(imdb)#获得训练数据
return roidbroidb其实是一个imdb的一个成员,是一个list列表,列表中的每个元素是一个字典,字典中包括了图片的路径,图片的高度,图片的宽度,等相关属性。roidb的存储结构如下图,
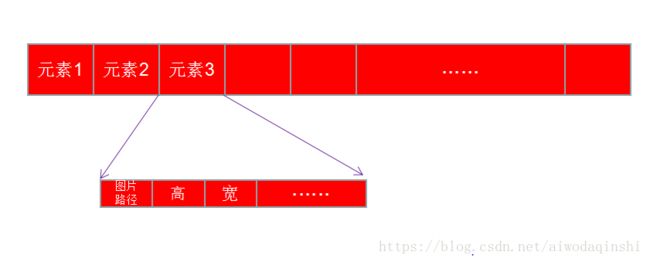
这样我们能看到训练传入的数据部分其实就是imdb.roidb。模型根据roidb中的相关信息就可以找到图片的位置,以及xml的位置。
这样当我们需要训练自己的数据的时候,我们可以有两个更改方法。
1.数据图片部分不动,将源代码中读取图片路径和xml文件路径的函数进行适当的更改。
2.代码部分不动,当图片以原项目中的格式存放,原项目中的数据存放形式有pascal_voc和coco两种形式,可以任选一种组织形式。以上两种方式中更推荐第二种更改办法,本项目代码结构较为复杂,函数以及文件的之间的耦合度较高,更改起来较为复杂,我们应该将更多的精力放在后期模型参数整定上面。