若面试官问“如何设计一个消息中间件”,该如何回答?重点要理解RabbitMQ在于routing,而Kafka在于streaming
前言
作为以一个专业技术软件开发人员,又加上软件技术更新速度日新月异,稍不注意,自己用的技术已经过时了,后端前几年还是struts2、hibernate、springmvc……稍不留心现在都是spring的天下了;前端前几年,还是ajax、js、easyui……稍不留心都使用vuejs、angularjs、reactjs……
整天趴在电脑前的你,有没有发现,突然去面个试,发现自己这么low有没有……所以作为技术人员,没事,出去面试一下,也是对自己的技术栈的预警哈!可以用面试驱动学习,学习的动力就是面试,学会享受面试官问我时,我都嘴角一翘,微微一笑的那种不羁。
作为工作将近10年的老兵,上次面试一个工作6年左右的软件开发的王工,问他“如何设计一个消息中间件”,搞得他一脸懵逼,两眼无神,不知从何说起,万般思绪……
为什么要问他“如何设计一个消息中间件”
消息中间件最突出的特点,就是提供数据传输的可靠性和高效性,主要解决分布式的系统数据传输需求。以用户数据整合应用阶段而言,最重要的一点,就是将数据从一点传输到另一点。现在市场上已有相应的数据整合工具,这些数据整合工具中通常多包含这几部分模块:数据抽取模块、数据加工模块、数据传输模块、数据加载模块,而其中数据传输模块多由消息中间件担当,并在数据整合过程中发挥着不可替代的作用。随着SOA应用时代的临近,针对越来越多的应用系统,趋向于准备采用SOA技术,消息中间件产品,也向此技术路线靠拢,以满足越来越多的复杂业务集成过程中的数据整合需求,为SOA技术的真正应用,做好底层数据交换的铺垫。
由于先前我和他聊到了kafka,他说他用kafka比较熟悉……听他讲完对kafka,速度如何快与吞吐量如何超高?如何保证百万级写入速度以及保证不丢失不重复消费?如何做到不丢失不重复消费?
再加上,他面试的是软件开发工程师高级,所以问他“如何设计一个消息中间件”,主要出于一下几点目的:
- 看他对简单问题的发散能力
- 看他对中间件的了解及理解的深度
- 看他阐述问题的思路及逻辑能力
- 看他在以前工作中,如何使用消息中间件
- 看他编码及解决问题的能力
- 看他软件开发能力的深厚程度……
若是我如何回答?
都是从普通的程序员,一步一步走过来的,没有难为面试者的意思,也没有固定答案……当然,要答到面试者的心坎里,那就更好了……
对比各类消息队列
消息队列中间件(简称消息中间件)是指利用高效可靠的消息传递机制,进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下提供应用解耦、弹性伸缩、冗余存储、流量削峰、异步通信、数据同步等等功能,其作为分布式系统架构中的一个重要组件,有着举足轻重的地位。
目前开源的消息中间件有很多,比如ActiveMQ、RabbitMQ、Kafka、RocketMQ、ZeroMQ等,有些大厂在长期的使用过程中积累了一定的经验,其消息队列的使用场景也相对稳定固化,但是绝大多数公司还是不会选择重复造轮子,那么选择一款合适自己的消息中间件显得尤为重要。
- ActiveMQ是Apache出品的、采用Java语言编写的完全基于JMS1.1规范的面向消息的中间件,为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信。不过由于历史原因包袱太重,目前市场份额没有后面三种消息中间件多,其最新架构被命名为Apollo,号称下一代ActiveMQ。
- RabbitMQ是采用Erlang语言实现的AMQP协议的消息中间件,最初起源于金融系统,用于在分布式系统中存储转发消息。RabbitMQ发展到今天,被越来越多的人认可,这和它在可靠性、可用性、扩展性、功能丰富等方面的卓越表现是分不开的。
- RocketMQ是阿里开源的消息中间件,目前已经捐献个Apache基金会,它是由Java语言开发的,具备高吞吐量、高可用性、适合大规模分布式系统应用等特点,经历过双11的洗礼,实力不容小觑。
- ZeroMQ号称史上最快的消息队列,基于C语言开发。ZeroMQ是一个消息处理队列库,可在多线程、多内核和主机之间弹性伸缩,虽然大多数时候我们习惯将其归入消息队列家族之中,但是其和前面的几款有着本质的区别,ZeroMQ本身就不是一个消息队列服务器,更像是一组底层网络通讯库,对原有的Socket API上加上一层封装而已。
- Kafka起初是由LinkedIn公司采用Scala语言开发的一个分布式、多分区、多副本且基于zookeeper协调的分布式消息系统,现已捐献给Apache基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark、Flink等都支持与Kafka集成。
目前市面上的消息中间件还有很多,比如腾讯系的PhxQueue、CMQ、CKafka,又比如基于Go语言的NSQ,有时人们也把类似Redis的产品也看做消息中间件的一种。
根据具体场景来设计合适的消息中间件
在想如何设计一个消息中间件之前,以先问我们自己一个问题:是否真的需要自研设计一个消息中间件?
若要自研,我们的具体场景是什么?采用什么语言设计?若采用Java,可不可以,对Java中的ArrayBlockingQueue做一个简单的封装,或者基于文件、数据库、Redis等底层存储封装而形成一个消息中间件。亦或者,根据Kafka或者RabbitMQ的可扩展性,来选择性的扩展……
根据功能维度扩展消息中间件
功能维度,这个直接决定了你能否最大程度上的实现开箱即用,进而缩短项目周期、降低成本等。如果一款消息中间件的功能,达不到想要的功能,那么就需要进行二次开发,这样会增加项目的技术难度、复杂度以及增大项目周期等。
- 优先级队列
优先级队列不同于先进先出队列,优先级高的消息具备优先被消费的特权,这样可以为下游提供不同消息级别的保证。
不过这个优先级也是需要有一个前提的:如果消费者的消费速度大于生产者的速度,并且消息中间件服务器(一般简单的称之为Broker)中没有消息堆积,那么对于发送的消息设置优先级,也就没有什么实质性的意义了,因为生产者刚发送完一条消息就被消费者消费了,那么就相当于Broker中至多只有一条消息,对于单条消息来说优先级是没有什么意义的。
- 延迟队列
当你在网上购物的时候,是否会遇到这样的提示:“三十分钟之内未付款,订单自动取消”?这个是延迟队列的一种典型应用场景。
延迟队列存储的是对应的延迟消息,所谓“延迟消息”是指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。
延迟队列一般分为两种:基于消息的延迟和基于队列的延迟。
基于消息的延迟是指为每条消息设置不同的延迟时间,那么每当队列中有新消息进入的时候,就会重新根据延迟时间排序,当然这也会对性能造成极大的影响。
实际应用中大多采用基于队列的延迟,设置不同延迟级别的队列,比如5s、10s、30s、1min、5mins、10mins等,每个队列中消息的延迟时间都是相同的,这样免去了延迟排序,所要承受的性能之苦,通过一定的扫描策略(比如定时)即可投递超时的消息。
- 死信队列
由于某些原因消息无法被正确的投递,为了确保消息不会被无故的丢弃,一般将其置于一个特殊角色的队列,这个队列一般称之为死信队列。
与此对应的还有一个“回退队列”的概念,试想如果消费者在消费时发生了异常,那么就不会对这一次消费进行确认(Ack),进而发生回滚消息的操作,之后消息始终会放在队列的顶部,然后不断被处理和回滚,导致队列陷入死循环。为了解决这个问题,可以为每个队列设置一个回退队列,它和死信队列都是为异常的处理提供的一种机制保障。实际情况下,回退队列的角色,可以由死信队列和重试队列来扮演。
- 重试队列
重试队列其实可以看成是一种回退队列,具体指消费端消费消息失败时,为防止消息无故丢失而重新将消息回滚到Broker中。
与回退队列不同的是,重试队列一般分成多个重试等级,每个重试等级一般也会设置重新投递延时,重试次数越多,投递延时就越大。
举个例子:消息第一次消费失败,入重试队列Q1,Q1的重新投递延迟为5s,在5s过后重新投递该消息;如果消息再次消费失败则入重试队列Q2,Q2的重新投递延迟为10s,在10s过后再次投递该消息。
以此类推,重试越多次重新投递的时间就越久,为此需要设置一个上限,超过投递次数,就入死信队列。
重试队列与延迟队列有相同的地方,都是需要设置延迟级别,它们彼此的区别是:延迟队列动作由内部触发,重试队列动作由外部消费端触发;延迟队列作用一次,而重试队列的作用范围会向后传递。
- 消费模式
消费模式分为推(push)模式和拉(pull)模式。
推模式是指由Broker主动推送消息至消费端,实时性较好,不过需要一定的流制机制,来确保服务端推送过来的消息不会压垮消费端。
而拉模式是指消费端主动向Broker端请求拉取(一般是定时或者定量)消息,实时性较推模式差,但是可以根据自身的处理能力,而控制拉取的消息量。
- 广播消费
消息一般有两种传递模式:点对点(P2P,Point-to-Point)模式和发布/订阅(Pub/Sub)模式。
对于点对点的模式而言,消息被消费以后,队列中不会再存储,所以消息消费者不可能消费到已经被消费的消息。
虽然队列可以支持多个消费者,但是一条消息只会被一个消费者消费。
发布订阅模式,定义了如何向一个内容节点发布和订阅消息,这个内容节点称为主题(topic),主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,而消息订阅者则从主题中订阅消息。
主题使得消息的订阅者与消息的发布者互相保持独立,不需要进行接触,即可保证消息的传递,发布/订阅模式在消息的一对多广播时采用。
RabbitMQ是一种典型的点对点模式,而Kafka是一种典型的发布订阅模式。
但是RabbitMQ中可以通过设置交换器类型,来实现发布订阅模式而达到广播消费的效果,Kafka中也能以点对点的形式消费,你完全可以把其消费组(consumer group)的概念看成是队列的概念。
不过对比来说,Kafka中因为有了消息回溯功能的存在,对于广播消费的力度支持比RabbitMQ的要强。
- 消息回溯
一般消息在消费完成之后,就被处理了,之后再也不能消费到该条消息。
消息回溯正好相反,是指消息在消费完成之后,还能消费到之前被消费掉的消息。
对于消息而言,经常面临的问题是“消息丢失”,至于是真正由于消息中间件的缺陷丢失,还是由于使用方的误用,而丢失一般很难追查,如果消息中间件本身具备消息回溯功能的话,可以通过回溯消费复现“丢失的”消息,进而查出问题的源头之所在。
消息回溯的作用远不止与此,比如还有索引恢复、本地缓存重建,有些业务补偿方案也可以采用回溯的方式来实现。
- 消息堆积+持久化
流量削峰,是消息中间件的一个非常重要的功能,而这个功能其实得益于其消息堆积能力。
从某种意义上来讲,如果一个消息中间件不具备消息堆积的能力,那么就不能把它看做是一个合格的消息中间件。
消息堆积分内存式堆积和磁盘式堆积。
RabbitMQ是典型的内存式堆积,但这并非绝对,在某些条件触发后,会有换页动作,来将内存中的消息换页到磁盘(换页动作会影响吞吐),或者直接使用惰性队列,来将消息直接持久化至磁盘中。
Kafka是一种典型的磁盘式堆积,所有的消息都存储在磁盘中。
一般来说,磁盘的容量会比内存的容量要大得多,对于磁盘式的堆积其堆积能力就是整个磁盘的大小。
从另外一个角度讲,消息堆积也为消息中间件提供了冗余存储的功能。援引纽约时报的案例(https://www.confluent.io/blog/publishing-apache-kafka-new-york-times/),其直接将Kafka用作存储系统。
- 消息追踪
对于分布式架构系统中的链路追踪(trace)而言,大家一定不会陌生。
对于消息中间件而言,消息的链路追踪(以下简称消息追踪)同样重要。对于消息追踪,最通俗的理解,就是要知道消息从哪来,存在哪里以及发往哪里去。
基于此功能下,我们可以对发送或者消费完的消息进行链路追踪服务,进而可以进行问题的快速定位与排查。
- 消息过滤
消息过滤,是指按照既定的过滤规则为下游用户提供指定类别的消息。
就以kafka而言,完全可以将不同类别的消息发送至不同的topic中,由此可以实现某种意义的消息过滤,或者Kafka还可以根据分区对同一个topic中的消息进行分类。
不过更加严格意义上的消息过滤,应该是对既定的消息,采取一定的方式,按照一定的过滤规则,进行过滤。
同样以Kafka为例,可以通过客户端,提供的ConsumerInterceptor接口,或者Kafka Stream的filter功能进行消息过滤。
- 多租户
也可以称为多重租赁技术,是一种软件架构技术,主要用来实现多用户的环境下,公用相同的系统或程序组件,并且仍可以确保,各用户间数据的隔离性。
RabbitMQ就能够支持多租户技术,每一个租户表示为一个vhost,其本质上是一个独立的小型RabbitMQ服务器,又有自己独立的队列、交换器及绑定关系等,并且它拥有自己独立的权限。
vhost就像是物理机中的虚拟机一样,它们在各个实例间,提供逻辑上的分离,为不同程序,安全保密使用允许的数据,它既能将同一个RabbitMQ中的众多客户区分开,又可以避免队列和交换器等命名冲突。
- 多协议支持
消息是信息的载体,为了让生产者和消费者都能理解所承载的信息(生产者需要知道如何构造消息,消费者需要知道如何解析消息),它们就需要按照一种统一的格式描述消息,这种统一的格式称之为消息协议。
有效的消息一定具有某种格式,而没有格式的消息是没有意义的。
一般消息层面的协议有AMQP、MQTT、STOMP、XMPP等(消息领域中的JMS更多的是一个规范而不是一个协议),支持的协议越多,其应用范围就会越广,通用性越强,比如RabbitMQ能够支持MQTT协议,就让其在物联网应用中,获得一席之地。
还有的消息中间件,是基于其本身的私有协议运转的,典型的如Kafka。
- 跨语言支持
对很多公司而言,其技术栈体系中会有多种编程语言,如C/C++、JAVA、Go、PHP等,消息中间件本身,具备应用解耦的特性,如果能够进一步的支持多客户端语言,那么就可以将此特性的效能扩大。
跨语言的支持力度也可以从侧面反映出一个消息中间件的流行程度。
- 流量控制
流量控制(flow control)针对的是发送方和接收方速度不匹配的问题,提供一种速度匹配服务,抑制发送速率,使接收方,应用程序的读取速率与之相适应。通常的流控方法有Stop-and-wait、滑动窗口以及令牌桶等。
- 消息顺序性
顾名思义,消息顺序性是指保证消息有序。
这个功能有个很常见的应用场景就是CDC(Change Data Chapture),以MySQL为例,如果其传输的binlog的顺序出错,比如原本是先对一条数据加1,然后再乘以2,发送错序之后就变成了先乘以2后加1了,造成了数据不一致。
- 安全机制
在Kafka 0.9版本之后,就开始增加了身份认证和权限控制两种安全机制。
身份认证是指客户端与服务端连接进行身份认证,包括客户端与Broker之间、Broker与Broker之间、Broker与ZooKeeper之间的连接认证,目前支持SSL、SASL等认证机制。
权限控制是指对客户端的读写操作进行权限控制,包括对消息或Kafka集群操作权限控制。
权限控制是可插拔的,并支持与外部的授权服务进行集成。
对于RabbitMQ而言,其同样提供身份认证(TLS/SSL、SASL)和权限控制(读写操作)的安全机制。
- 消息幂等性
对于确保消息在生产者和消费者之间进行传输而言,一般有三种传输保障(delivery guarantee):
- At most once,至多一次,消息可能丢失,但绝不会重复传输;
- At least once,至少一次,消息绝不会丢,但是可能会重复;
- Exactly once,精确一次,每条消息肯定会被传输一次且仅一次。
对于大多数消息中间件而言,一般只提供At most once和At least once两种传输保障,对于第三种一般很难做到,由此消息幂等性也很难保证。
Kafka自0.11版本,开始引入了幂等性和事务,Kafka的幂等性是指单个生产者对于单分区单会话的幂等,而事务可以保证原子性地写入到多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚,这两个功能加起来,可以让Kafka具备EOS(Exactly Once Semantic)的能力。
不过如果要考虑全局的幂等,还需要与从上下游方面综合考虑,即关联业务层面,幂等处理本身,也是业务层面,所需要考虑的重要议题。
以下游消费者层面为例,有可能消费者消费完一条消息之后,没有来得及确认消息,就发生异常,等到恢复之后,又得重新消费原来消费过的那条消息,那么这种类型的消息幂等,是无法有消息中间件层面来保证的。
如果要保证全局的幂等,需要引入更多的外部资源来保证,比如以订单号作为唯一性标识,并且在下游设置一个去重表。
- 事务性消息
事务本身是一个并不陌生的词汇,事务是由事务开始(Begin Transaction),和事务结束(End Transaction)之间执行的全体操作组成。
支持事务的消息中间件,并不在少数,Kafka和RabbitMQ都支持,不过此两者的事务,是指生产者发生消息的事务,要么发送成功,要么发送失败。
消息中间件,可以作为用来实现分布式事务的一种手段,但其本身,并不提供全局分布式事务的功能。
下表是对Kafka与RabbitMQ功能的总结性对比及补充说明:
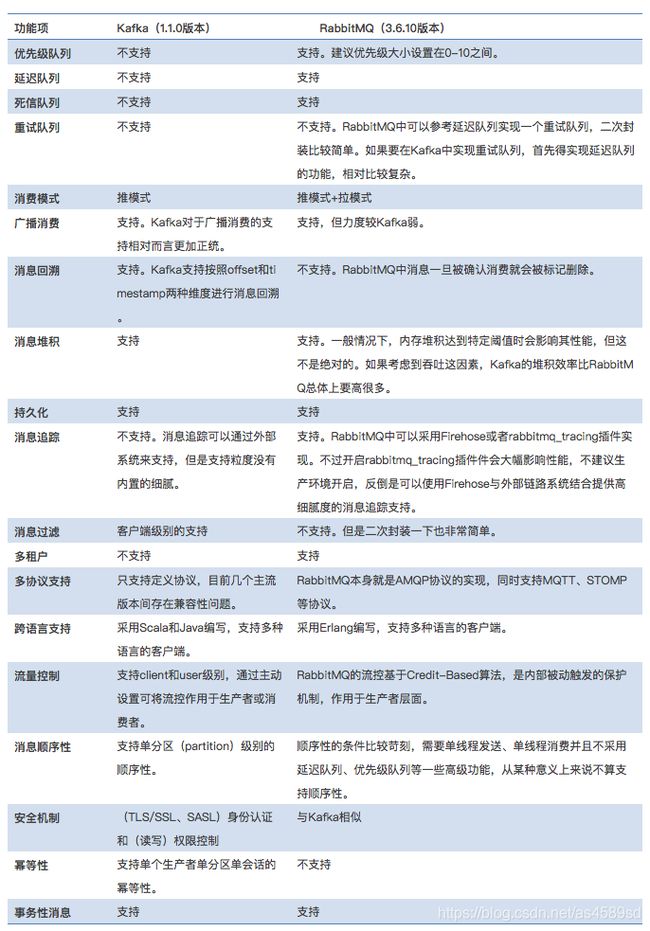
根据性能维度扩展消息中间件
功能维度,是消息中间件选型中的一个重要的参考维度,但这并不是唯一的维度。
有时候性能比功能还要重要,况且性能和功能很多时候是相悖的,鱼和熊掌不可兼得,Kafka在开启幂等、事务功能的时候会使其性能降低,RabbitMQ在开启rabbitmq_tracing插件的时候,也会极大的影响其性能。
消息中间件的性能,一般是指其吞吐量,虽然从功能维度上来说,RabbitMQ的优势要大于Kafka,但是Kafka的吞吐量要比RabbitMQ高出1至2个数量级,一般RabbitMQ的单机QPS在万级别之内,而Kafka的单机QPS可以维持在十万级别,甚至可以达到百万级。
消息中间件的吞吐量,始终会受到硬件层面的限制。
就以网卡带宽为例,如果单机单网卡的带宽为1Gbps,如果要达到百万级的吞吐,那么消息体大小不得超过(1Gb/8)/100W,即约等于134B,换句话说如果消息体大小超过134B,那么就不可能达到百万级别的吞吐。这种计算方式同样可以适用于内存和磁盘。
时延作为性能维度的一个重要指标,却往往在消息中间件领域所被忽视,因为一般使用消息中间件的场景,对时效性的要求并不是很高。
如果要求时效性,完全可以采用RPC的方式实现。
消息中间件具备消息堆积的能力,消息堆积越大,也就意味着端到端的时延也就越长,与此同时,延时队列也是某些消息中间件的一大特色。
那么为什么还要关注消息中间件的时延问题呢?
消息中间件能够解耦系统,对于一个时延较低的消息中间件而言,它可以让上游生产者,发送消息之后,可以迅速的返回,也可以让消费者更加快速的获取到消息。
在没有堆积的情况下,可以让整体上下游的应用之间的级联动作更加高效。
虽然不建议在时效性很高的场景下,使用消息中间件,但是如果所使用的消息中间件的时延方面比较优秀,那么对于整体系统的性能将会是一个不小的提升。
根据“可靠性+可用性”维度扩展消息中间件
消息丢失,是使用消息中间件时,不得不面对的一个点,其背后消息可靠性,也是衡量消息中间件好坏的一个关键因素。
尤其是在金融支付领域,消息可靠性尤为重要。然而说到可靠性必然要说到可用性,注意这两者之间的区别,消息中间件的可靠性,是指对消息不丢失的保障程度;而消息中间件的可用性是指无故障运行的时间百分比,通常用几个9来衡量。
从狭义的角度来说,分布式系统架构是一致性协议理论的应用实现,对于消息可靠性和可用性而言,也可以追溯到消息中间件背后的一致性协议。
对于Kafka而言,其采用的是类似PacificA的一致性协议,通过ISR(In-Sync-Replica)来保证多副本之间的同步,并且支持强一致性语义(通过acks实现)。
对应的RabbitMQ,是通过镜像环形队列,实现多副本及强一致性语义的。
多副本可以保证在master节点宕机异常之后,可以提升slave,作为新的master,而继续提供服务,来保障可用性。
Kafka设计之初是为日志处理而生,给人们留下了数据可靠性要求不要的不良印象,但是随着版本的升级优化,其可靠性得到极大的增强,详细可以参考KIP101。
就目前而言,在金融支付领域使用RabbitMQ居多,而在日志处理、大数据等方面Kafka使用居多,随着RabbitMQ性能的不断提升和Kafka可靠性的进一步增强,相信彼此都能在以前不擅长的领域分得一杯羹。
同步刷盘,是增强一个组件可靠性的有效方式,消息中间件也不例外,Kafka和RabbitMQ都可以支持同步刷盘。
但是对同步刷盘有一定的疑问:绝大多数情景下,一个组件的可靠性,不应该由同步刷盘这种极其损耗性能的操作来保障,而是采用多副本的机制来保证。
这里还要提及的一个方面是扩展能力,这里我狭隘地将此归纳到可用性这一维度,消息中间件的扩展能力,能够增强其用可用能力及范围。
比如前面提到的RabbitMQ支持多种消息协议,这个就是基于其插件化的扩展实现。
还有从集群部署上来讲,归功于Kafka的水平扩展能力,其基本上可以达到线性容量提升的水平,在LinkedIn实践介绍中,就提及了有部署超过千台设备的Kafka集群。
根据“运维管理”维度扩展消息中间件
在消息中间件的使用过程中,难免会出现各式各样的异常情况,有客户端的,也有服务端的,那么怎样及时有效的进行监测及修复。
业务线流量有峰值又低谷,尤其是电商领域,那么怎样才能进行有效的容量评估,尤其是大促期间?脚踢电源、网线被挖等事件层出不穷,如何有效的做好异地多活?这些都离不开消息中间件的衍生产品——运维管理。
运维管理,也可以进行进一步的细分,比如:申请、审核、监控、告警、管理、容灾、部署等。
申请、审核很好理解,在源头对资源进行管控,既可以进行有效校正应用方的使用规范,配和监控也可以做好流量统计与流量评估工作,一般申请、审核与公司内部系统交融性较大,不适合使用开源类的产品。
监控、告警也比较好理解,对消息中间件的使用进行全方位的监控,即可以为系统提供基准数据,也可以在检测到异常的情况配合告警,以便运维、开发人员的迅速介入。
除了一般的监控项(比如硬件、GC等)之外,对于消息中间件,还需要关注端到端时延、消息审计、消息堆积等方面。
对于RabbitMQ而言,最正统的监控管理工具,莫过于rabbitmq_management插件了,但是社区内还有AppDynamics, Collectd, DataDog, Ganglia, Munin, Nagios, New Relic, Prometheus, Zenoss等多种优秀的产品。
Kafka在此方面也毫不逊色,比如:Kafka Manager, Kafka Monitor, Kafka Offset Monitor, Burrow, Chaperone, Confluent Control Center等产品,尤其是Cruise还可以提供自动化运维的功能。
不管是扩容、降级、版本升级、集群节点部署、还是故障处理都离不开管理工具的应用,一个配套完备的管理工具集,可以在遇到变更时做到事半功倍。
故障可大可小,一般是一些应用异常,也可以是机器掉电、网络异常、磁盘损坏等单机故障,这些故障单机房内的多副本足以应付。
如果是机房故障,就要涉及异地容灾了,关键点,在于如何有效的进行数据恢复,对于Kafka而言,可以参考MirrorMarker、uReplicator等产品,而RabbitMQ可以参考Federation和Shovel。
根据“社区力度及生态发展”维度扩展消息中间件
对于目前流行的编程语言而言,如Java、Python,如果你在使用过程中遇到了一些异常,基本上可以通过搜索引擎的帮助来得到解决,因为一个产品用的人越多,踩过的坑也就越多,对应的解决方案也就越多。
对于消息中间件也同样适用,如果你选择了一种“生僻”的消息中间件,可能在某些方面运用的得心应手,但是版本更新缓慢、遇到棘手问题也难以得到社区的支持而越陷越深;相反如果你选择了一种“流行”的消息中间件,其更新力度大,不仅可以迅速的弥补之前的不足,而且也能顺应技术的快速发展来变更一些新的功能,这样可以让你以“站在巨人的肩膀上”。
在运维管理维度我们提及了Kafka和RabbitMQ都有一系列开源的监控管理产品,这些正是得益于其社区及生态的迅猛发展。
消息中间件选型误区探讨
很多人面对消息中间件时,会有一种自研的冲动,你完全可以把消息中间件做为一个基础组件,并没有想象中的那么简单,其背后还需要配套的管理运维整个生态的产品集。
自研还有会交接问题,如果文档不齐全、运作不规范,将会带给新人噩梦般的体验。
是否真的有自研的必要?如果不是KPI的压迫,可以先考虑下这2个问题:
- 目前市面上的消息中间件,是否都真的无法满足目前业务需求?
- 团队是否有足够的能力、人力、财力、精力来支持自研?
很多人在做消息中间件选型时,会参考网络上的很多对比类的文章,但是其专业性、严谨性、以及其政治立场问题都有待考证,需要带着怀疑的态度去审视这些文章。
比如有些文章会在没有任何限定条件及场景的情况下,直接定义某款消息中间件最好,还有些文章没有指明消息中间件版本,及测试环境就来做功能和性能对比分析,诸如此类的文章都可以唾弃之。
消息中间件犹如小马过河,选择合适的才最重要,这需要贴合自身的业务需求,技术服务于业务,大体上可以根据以上,所提及的功能、性能等6个维度来一一进行筛选。
更深层次的抉择,在于你能否掌握其魂:RabbitMQ在于routing,而Kafka在于streaming,了解其根本,对于自己能够对症下药,选择到合适的消息中间件尤为重要。
消息中间件选型,切忌一味的追求性能或者功能,性能可以优化,功能可以二次开发。
如果要在功能和性能方面做一个抉择的话,那么首选性能,因为总体上来说性能优化的空间,没有功能扩展的空间大。
然而对于长期发展而言,生态又比性能以及功能都要重要。
很多时候,对于可靠性方面,也容易存在一个误区:想要找到一个产品,来保证消息的绝对可靠,很不幸的是这世界上没有绝对的东西,只能说尽量趋于完美。
想要尽可能的保障消息的可靠性,也并非单单只靠消息中间件本身,还要依赖于上下游,需要从生产端、服务端和消费端这3个维度去努力保证,《RabbitMQ消息可靠性分析》这篇文章就从这3个维度去分析了RabbitMQ的可靠性。
消息中间件选型,还有一个考量标准就是尽量贴合团队自身的技术栈体系,虽然说,没有蹩脚的消息中间件,只有蹩脚的程序员,但是让一个C栈的团队,去深挖PhxQueue总比去深挖Scala编写的Kafka要容易的多。
真实场景面试
如何写个消息中间件
如何写个消息中间件,首先我们需要明确地提出消息中间件的几个重要角色,分别是生产者、消费者、Broker、注册中心。
可以简述下消息中间件数据流转过程,无非就是生产者生成消息,发送至 Broker,Broker 可以暂缓消息,然后消费者再从 Broker 获取消息,用于消费。
而注册中心用于服务的发现包括:Broker 的发现、生产者的发现、消费者的发现,当然还包括下线,可以说服务的高可用,离不开注册中心。
然后开始简述实现要点,还可以插叙:各模块的通信,可以基于 Netty,然后自定义协议来实现,注册中心,可以利用 zookeeper、consul、eureka、nacos 等等。也可以像 RocketMQ 自己实现,简单的 namesrv (namesrv是类似zk的命名服务端,broker向它发起注册、producer与consumer向他拉取topic的队列。为什么不用现有的比如zk等中间件呢?应该是因为解耦:功能比较简单,不需要引入外界中间件,避免引入新的复杂度,控制权在自己手上,简单即是美。)。
为了考虑扩容和整体的性能,采用分布式的思想,像 Kafka 一样采取分区理念,一个 Topic 分为多个 partition,并且为保证数据可靠性,采取多副本存储,即 Leader 和 follower,根据性能和数据可靠的权衡提供异步和同步的刷盘存储。
并且利用选举算法保证 Leader 挂了之后 ,follower 可以顶上,保证消息队列的高可用。
也同样为了提高消息队列的可靠性利用本地文件系统来存储消息,并且采用顺序写的方式来提高性能。
可根据消息队列的特性,利用内存映射、零拷贝进一步的提升性能,还可利用像 Kafka 这种批处理思想,提高整体的吞吐。
至此就差不多了,该说的要点说的都差不多了,面试官心里已经想,这人好像有点东西……
之后可以深挖的点就很多了,比如面试官可以提到的 Netty,各种注册中心就能问很多,比如各注册中心之间的选型对比等。
面试官还提到了选举算法,所以可能会问 Bully 算法、Raft 算法、ZAB 算法等等。
面试官还提到了分区,可能会问这个分区和 RocketMQ 的队列有什么不同啊?具体分区要怎么实现?
然后面试官提到顺序写,可能会问为什么要顺序写啊?面试官问你说的内存映射和零拷贝又是什么啊?那你以前工作中,RocketMQ 和 Kafka 用了哪个吗?
当然面试官还有可能问各种细节,比如消息的写入如何存储、消息的索引如何生成等等,来深挖看你有没有看过消息中间件的源码。
面试官可以问的还很多,这些知识点还是得靠大家日积月累和平日的多加思考……
做一个面试驱动学习型选手
以上,是对消息中间件的扩展开发的总结,需要面试的小伙伴,可以则其一二,进行深入分析记忆,学习。当然,再好的消息中间件,也需要实际工作中,去实践。消息中间件大道至简:一发一存一消费,没有最好的消息中间件,只有最合适的消息中间件。
面试驱动不仅仅是说为了面试而学习,还要以面试场景来学习,什么意思呢?
学任何一种东西,都模拟一个面试官在你前面,让他从各种角度向你提问,驱动你全方位的理解一个知识点,做一个面试驱动学习型选手。
送给小伙伴几条面试技巧
- 要正确的看待面试官,你和面试官是同等的,不要一来就低声下气的。
- 回答问题需要抓住重点,不要一股脑儿的把你知道的都说了,要留白待面试官提问。
- 要把控面试的节奏,往自己熟知的方向上引。
- 在回答面试官的时候不仅要 get 到他的点,还得为之后的回答铺路,不会说的点不要提,擅长的点多提提。
- 了解面试官的技术栈,及和面试官是否有相同方向的喜好,进而深入技术交流
希望小伙伴,在面试时,能察言观色,对答如流,让你的面试成为一场技术交流,这是面试的最高境界,相信面试完了之后,双方都会有意犹未尽,惺惺相惜的感觉。