基于蜕变测试的自然语言模型歧视性输出检测与缓解
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
本期AI TIME PhD IJCAI专场,我们有幸邀请到了来自香港科技大学计算机科学与工程系的博士生马平川,为我们带来他的精彩分享——基于蜕变测试的自然语言模型歧视性输出检测与缓解Metamorphic Testing and Certified Mitigation of Fairness Violations in NLP Models。

马平川:香港科技大学计算机科学与工程系博士生,导师是王帅教授,主要研究方向为信息安全和软件工程。

一、Motivation

图1 Sentiment analysis by training a CNN model using the Large Movie Review Dataset
我们发现即使在非常简单的CNN模型里,当文本中的单词做了一些改变后,比如在上图的Sentiment analysis例子中,将“actor”换为“actress”或者在“actor”前加“Chinese”,模型的属性会发生比较大的变化,而这种变化大部分情况下是不被期望的,所以我们希望用自动化的方法来检测自然语言模型中的歧视性输出。
当我们将AI模型部署到现实生活中,一个值得关注的问题出现了——模型是否存在对特定群体有歧视性的输出?比如,一些基于AI的招聘工具就被证实存在性别歧视。
二、Preliminaries
1. Metamorphic Testing
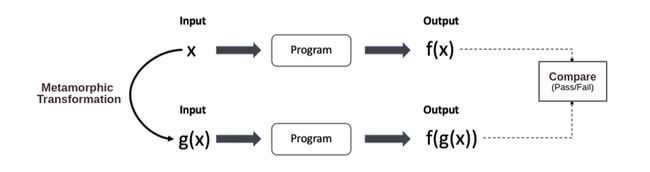
图2 Metamorphic Transformation
这里先阐释几个概念:
Oracle问题:程序的执行结果不能预知的现象在测试理论中称为“Oracle问题”,即预期结果不知道。
蜕变关系Metamorphic relation:是指多次执行目标程序时,输入与输出之间期望遵循的关系。
蜕变测试 Metamorphic Testing:是一种特殊的黑盒测试方法,蜕变测试依据被测软件的领域知识和软件的实现方法建立蜕变关系,利用蜕变关系来生成新的测试用例,通过验证蜕变关系是否被保持来决定测试是否通过。
蜕变测试是由TY Chen在1998年提出的,希望用较少的成本自动化的对较复杂的系统或软件进行测试。我们这篇工作就使用了蜕变测试对AI模型进行了测试。
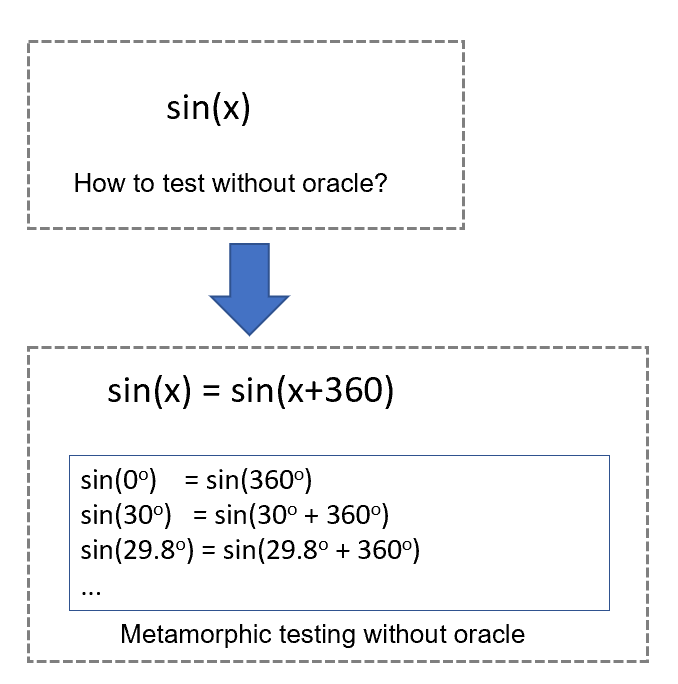
图3 蜕变测试举例
举例来说,假设我们用C语言做了sin(x)的实现并想进行测试,因为我们知道sin(x)=sin(x+360)这个属性保持不变,那么就可以基于此生成很多测试用例,我们不需要知道sin(0)、sin(30)……的Ground truth就可以自动化地进行测试。
在我们这篇工作中,蜕变关系指的就是NLP sentiment analysis的结果不应该因为一些敏感词汇的改变就发生改变。
2. Word Analogy

图4 Word Analogy 1
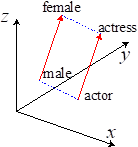
图5 Word Analogy 2
我们还用到了词嵌入模型中的词相似(Word Analogy),属性相关或存在对应关系的词的向量也会存在一些特定的关系。比如上图所示的平行四边形,我们可以通过其中三个词向量的位置推断出第四个词对应的词向量位置,从而找到第四个词。我们通过这个方法可以对文本中的一些词进行变异并形成大量的测试用例。
三、Overview

图6 Workflow
首先对原始输入产生大量变异,这些变异会满足蜕变关系,基于此判定这个模型是否存在有歧视性的输出,从而对模型进行测试。测试完成后,还可以进一步利用蜕变关系得到的测试用例,对模型输出的歧视性进行缓解(Mitigation)。
四、Test Case Generation
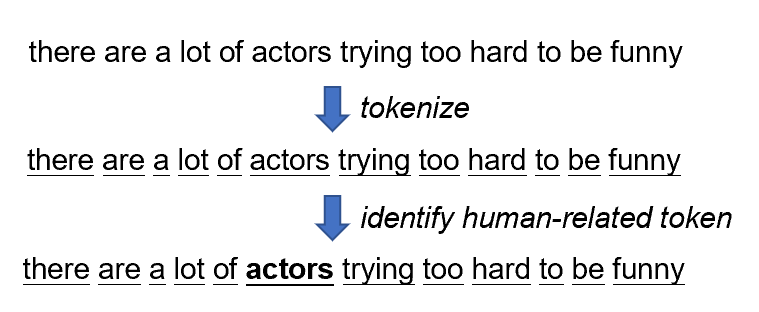
图7 Test Case Generation
在上图所示的例子中,我们首先对文本进行分词,找到human-related token——“actors”并将其称为sensitive token,然后利用知识图谱(Knowledge graph)进行Sensitive Token的识别:

图8 Sensitive Token Identification
比如,现在我们想知道“policewoman”是不是与“human adult”相关的token,我们可以先遍历出k-depth的子图,如果“policewoman”能够在k-hop内达到预先定义好的sensitive token——“human adult”,那么我们就认为“policewoman”是sensitive token。

图9 Check mutable condition
在找到sensitive token后,我们对整个句子做词性分析,为了防止生成不自然的语句,只对前面不存在形容词的token进行变异(Mutation)。
有两种变异方法:
1. Active Mutation
通过manual specification或knowledge graph生成一系列加在sensitive token前的形容词。
图10 Active Mutation
2. Analogy Mutation
利用词相似(Word Analogy),在词向量空间中找到对应的单词,并在符合设定阈值的情况下进行原词的替换。
通过Mutation,一个句子可以生成十多个测试用例,在这次Movie Review的data set中我们一共生成了17万个测试用例并对模型进行了测试。

图11 Analogy Mutation
五、Mitigation
我们借鉴了差分隐私,在NLP的语境下定义了“fairness”:模型不应在只有子群体(subpopulation)不同的两个语义等效的句子上产生“太不同的输出” ,比如原句子与测试用例。即不能通过模型的输出判定对应输入所属的某一特定群体。
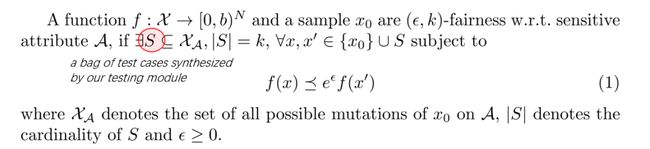
图12 Define “fairness”
我们将模型输出进行平滑化,给原始输入更大的权重,给测试用例更少的权重,使输出既能保持句子原本的语义,也不和subpopulation不同的例子相差过大,从而实现了“fairness”。

图13 Achieve “fairness”
六、Evaluation
Evaluation Ⅰ:
我们对本地模型CNN和LR以及一些商用API如Amazon Comprehend API、Google NLP API、Microsoft NLP API进行了测试,都得到了一些Fairness Violations,如下图所示。
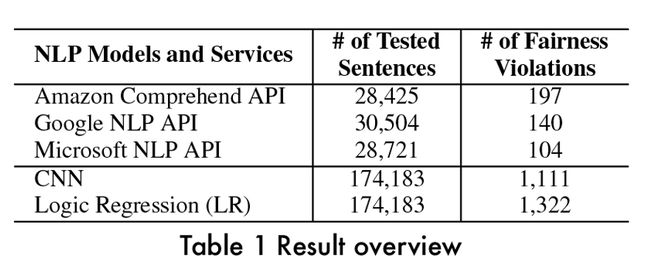
图14 Result overview
我们对比一些原句和测试用例,将“uncle”改为“aunt”,“brothers”改为“sisters”,在“soldiers”前面加“male”等,会让输出结果产生positive或negative的变化,如图所示。

图15 Fairness violations detected by our framework
我们也得到了句子的测试用例生成个数分布:
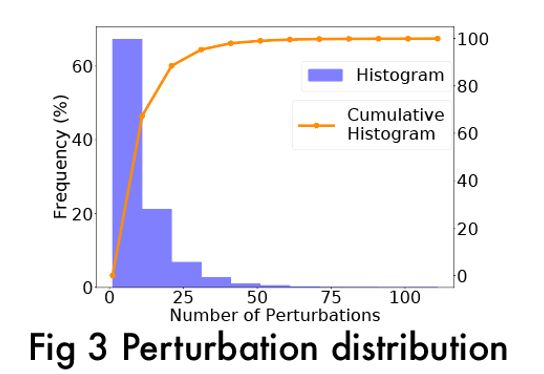
图16 Perturbation distribution
Evaluation Ⅱ:

图17 Fairness violation percentage w.r.t. ε
在Mitigation方面,我们提出了一个Baseline的白盒方法: 用我们在训练集上生成的测试用例去训练增强LR模型, 然后与黑盒方法的性能进行比较,我们发现当ε大于2的时候,黑盒方法的缓解效果超过了白盒方法,当ε足够大的时候,在很多的模型和商用的API上都能产生很好的缓解效果。
REF
Ma, Pingchuan, Shuai Wang, and Jin Liu. "Metamorphic testing and certified mitigation of fairness violations in nlp models." Proceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI). 458–465. 2020.
本文所引用图片均来自讲者PPT.
整理:李嘉琪
审稿:马平川
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/po5Cif)
(点击“阅读原文”下载本次报告ppt)