Linux文件系统
目录
- 1.认识Linux文件系统
-
- 1.2 文件系统特性
- 1.3 Linux的ext2文件系统
- 1.4 文件系统与目录树的关系
-
- 1.4.0 目录
- 1.4.1 文件
- 1.4.2 目录树读取
- 1.4.3 文件系统大小与磁盘读取性能
- 1.5 ext2/ext3/ext4 文件的存取与日志式文件系统的功能
-
- 1.5.0 ext2/ext3/ext4 文件的存取
- 1.5.1 日志式文件系统(Journaling File System)
- 1.6 Linux文件系统的运行
- 1.7 挂载点(mount point)的意义
- 1.8 其他Linux支持的文件系统与VFS
-
- 1.8.0 Linux VFS(Virtual File System)
- 1.9 XFS文件系统简介(Extended File System)
1.认识Linux文件系统
Linux最传统的磁盘文件系统(file system)使用的是【ext2】
文件系统是建立在磁盘上面的
1.2 文件系统特性
1.磁盘分区完后需要进行格式化(format)后,操作系统(OS)才能使用这个文件系统
为什么需要进行格式化?
因为每种OS所设置的文件属性/权限并不相同,为存放这些文件所需要的数据,需要将分区进行格式化,以成为OS能利用的文件系统格式(file system)
2.每种OS使用的文件系统不同
| OS类型 | 文件系统 |
|---|---|
| Windows 98 | FAT |
| Windows 2000 | NTFS |
| Linux | ext2 |
3.文件系统的数据存放位置
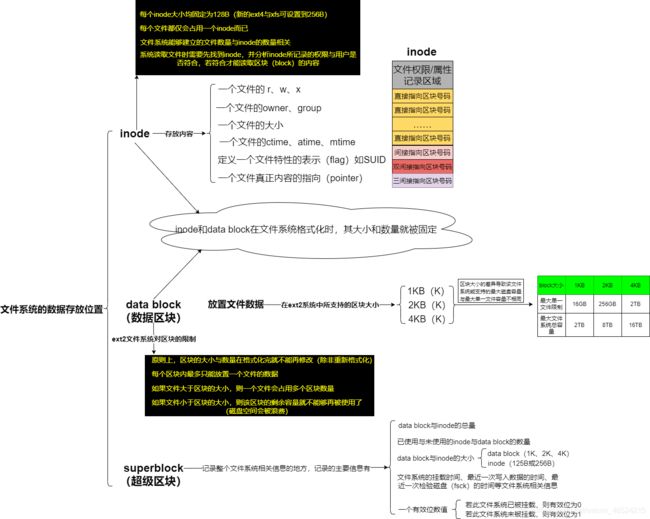
4.inode / data block 数据存取示意图

某个文件的属性与权限数据是放置到 inode4号,这个 inode 记录了文件数据的实际放置点为 2、7、13、15 这4个区块号码,此时OS能按此排列磁盘的读取顺序,一次性将4个区块内容读出来。这种数据存取的方法称为索引式文件系统(indexed allocation)ext2是索引式文件系统
对比:U盘使用的FAT文件系统
FAT文件系统数据存取示意图
1.3 Linux的ext2文件系统
文件系统一开始就将 inode 与 data block 规划好了,除非重新格式化(或利用 resize2fs 等命令修改其大小),否则 inode 与 data block 固定(大小和数量)后就不再变动
1.ext2 文件系统示意图

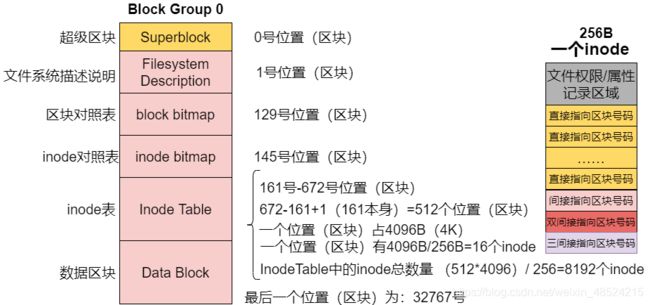
2.inode的结构示意图

间接:再拿一块block来当作记录block号码的记录区,如果文件太大,就会使用间接的block来记录编号,如果文件持续变大,就会利用所谓的双间接,以此类推,三间接就是利用第三层block来记录编号
inode能够指定多少个 block?以较小的 1K block 为例:
| Block大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 一个文件最大容量 | 16GB | 256GB | 2TB |
| 文件系统最大容量 | 2TB | 8TB | 16TB |
- 12个直接指向:12×1K=12K
由于是直接指向:所以总共可记录 12 条记录,因此大小为12K - 1个间接:256×1K=256K
每个block号码的记录会使用 4B,因此 1K 的大小能够记录 256 条记录,因此一个间接可以记录的文件大小为256K - 1个双间接:256×256×1K=2562K
第一层block会指定 256 个第二层,每个第二层可以指定 256 个block号码,因此大小为2562K - 1个三间接:256×256×256×1K=2563K
第一层block会指定 256 个第二层,每个第二层可以指定 256 个第三层,每个第三层可以指定 256 个 block 号码,因此大小为2563K - 一个文件最大容量:将直接、间接、双间接、三间接相加,能够容纳的最大文件为 16GB(1MB=1024KB,1GB=1024MB)
这个方法不能用在 2K 及 4K block大小的计算中,因为大于 2K 的block将会受到 ext2 文件系统本身的限制,所以计算结果不太符合
ext4文件系统的 inode 容量已经可以扩大到 256B,更大的 inode 容量,可以记录更多的文件系统信息,包括新的 ACL 以及 SELinux 类型等
3.利用【dumpe2fs】查询信息
[root@study ~] dumpe2fs [-bh] 设备文件名
选项与参数:
-b : 列出保留为坏道的部分(一般用不到)
-h : 仅列出superblock的数据,不会列出其他的区段内容

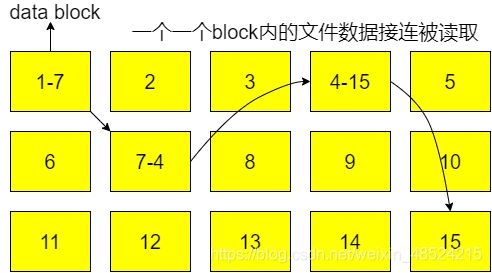
/dev/vda5使用的区块(图中所述为位置)为 4K ,第一个block号码为0号,以Block Group 0为例:
1.4 文件系统与目录树的关系
目录的内容是文件名,一般文件的内容是实际的数据
1.4.0 目录
目录与文件在文件系统当中是如何记录数据的呢?

观察root根目录内的文件所占用的 inode 号码,使用【ls -i】来处理

下图中
- 根目录( / )使用的区块大小为 4K(4096B)
- /boot 使用的区块大小为 4K(4096B)
- /proc 使用的区块大小为 0K,该目录不占磁盘容量
- /usr/sbin 使用的区块大小为 3个4K区块(12288B,12288B/4096B=3)

1.4.1 文件
Linux的ext2文件系统建立一个一般文件时,ext2会分配
- 一个inode
- 相对于该文件大小的区块数量给文件
范例:
假设一个区块为 4KB,想要建立一个 100 KB的文件,那么Linux将分配一个 inode 与25个区块(25×4K=100KB)来存储该文件。要注意:inode 有12个直接指向(12×4KB=48KB)再使用一个间接指向(256×4KB=1024KB)
- 直接指向:48KB
- 间接指向:52KB(100KB-48KB=52KB,剩余1024KB-52KB=972KB)
1.4.2 目录树读取
文件读取流程
以下图中的【/etc/passwd】为例:
(读取者身份为 aeronautics 这个一般身份用户)

-
/ 的inode
通过挂载点(mount point)的信息找到 inode 号码为 2 的根目录 inode,且 inode 规范的权限让我们可以读取该区块的内容(用户组权限为r-x,含r和x权限) -
/ 的区块
经过上个步骤取得的区块的号码,并找到该内容有【etc/】目录的 inode 号码(6029313) -
【etc/】的inode
读取6029313号 inode 得知 aeronautics 具有 r 与 x 权限,因此可以读取 【etc/】的区块内容 -
【etc/】的区块
经过上个步骤取得区块号码,并找到该内容有 passwd 文件的 inode 号码(6029518) -
passwd 的inode
读取 6029518 号inode 得知 aeronautics 具有 r 的权限,因此可以读取 passwd 的区块内容 -
passwd 的区块
最后将该区块内容的数据读出来
1.4.3 文件系统大小与磁盘读取性能
如果文件写入的区块太分散,就会有所谓的文件数据离散的问题。
如果文件系统真的太大,那么当一个文件分别记录在这个文件系统的最前面与最后面的区块号码中,此时会造成磁盘的机械手臂移动幅度过大,也会造成数据读取性能的下降。而且磁头在查找整个文件系统时,也会花费比较多的时间去查找。因此,磁盘分区的规划并不是越大越好,而是要针对主机用途来进行规划。
1.5 ext2/ext3/ext4 文件的存取与日志式文件系统的功能
1.5.0 ext2/ext3/ext4 文件的存取
假设要新增一个文件,文件系统的操作如下:

- 先确定用户对欲新增文件的目录是否具有w与x的权限,若有的话才能新增文件
- 根据 inode bitmap 找到未被使用的 inode 号码,并将新文件的权限/属性写入 inode
- 根据 block bitmap 找到未被使用的 区块号码,并将实际的数据写入区块中,且更新 inode 的指向号码
- 将刚刚写入的 inode 与 区块数据同步更新 inode bitmap 与 block bitmap,并更新superblock 的内容
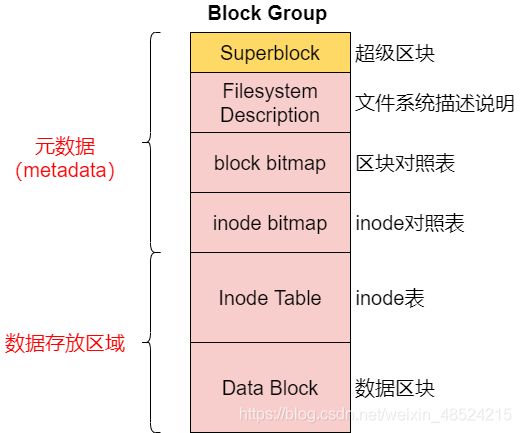
因为 superblock、inode bitmap、block bitmap的数据经常变动,每次新增、删除、编辑时都可能会影响到这三个部分的数据,因此被称为元数据(metadata)
1.5.1 日志式文件系统(Journaling File System)
日志式文件最基础的功能:
当数据的记录过程出现问题时,系统只要去检查日志记录的区块,就可以知道哪个文件发生了问题,针对该问题来做一致性的检查即可,而不必针对整个文件系统进行检查,这样就可达到快速修复文件系统的目的。
一致性检查的步骤:
- 预备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备要写入的信息
- 实际写入:开始写入文件的权限与数据;开始更新元数据(metadata)的数据
- 结束: 完成数据与元数据(metadata)的更新后,在日志记录区块当中完成该文件的记录
1.6 Linux文件系统的运行
所有的数据要加载到内存后,CPU才能处理。
如果编辑大文件,在编辑过程中又频繁地要系统来写入到磁盘中,由于磁盘写入地速度要比内存慢的多,因此你会常常耗在等待磁盘的读写上,导致效率低下。
为解决效率问题,Linux使用异步处理(asynchronously)的方式
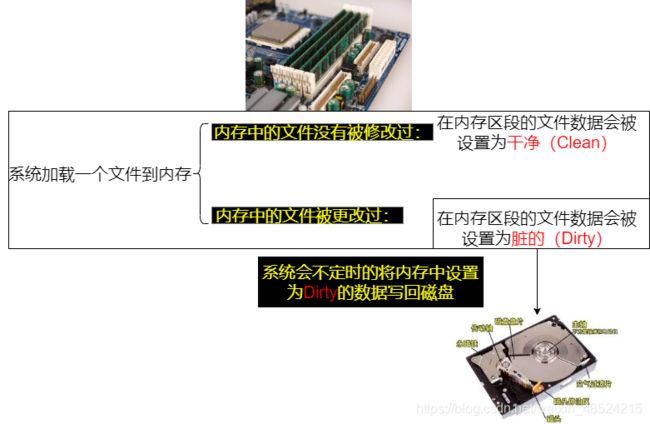
如果能将常用文件放置到内存当中,可提高系统性能
Linux系统上面的文件系统与内存间的关系
- 系统会将常用的文件数据放置到内存的缓冲区,以加快文件系统的读写操作
- 可手动使用【sync】来强制内存中设置为【Dirty】的数据写回到磁盘中
- 若正常关机,关机命令会主动调用【sync】将内存中的数据写入磁盘内
- 若不正常关机(如断电、宕机或其他原因),由于数据尚未回到磁盘内,因此重新启动后可能会花很多时间在进行磁盘校验,甚至可能导致文件系统的损坏(非磁盘损坏)
1.7 挂载点(mount point)的意义
每个文件系统都有独立的 inode、区块、超级区块等信息,这个文件系统要能够链接到目录树才能被使用。将文件系统与目录树结合的操作称为挂载(mount)
重点:挂载点一定是目录,该目录为进入该文件系统的入口

同一个文件系统的某个 inode 只会对应到一个文件内容而已(因为一个文件占用一个 inode)
可以通过判断 inode 号码 来确认不同文件名是否为相同的文件

上面的信息中由于挂载点均在 / ,因此三个文件(/、/. 、/…)均在同一个文件系统内,而这三个文件的 inode 号码均为 2 号,因此这三个文件名都指向同一个 inode 号码,当然这三个文件的内容也完全一样。(根目录的上层【/…】就是它自己)
1.8 其他Linux支持的文件系统与VFS

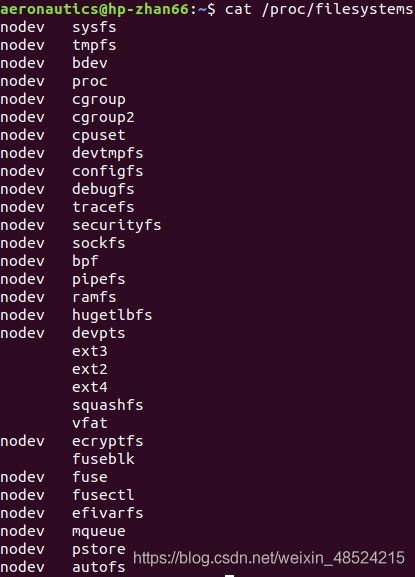
查看系统目前已加载到内存中支持的文件系统:
[root@study ~] cat /proc/filesystems
1.8.0 Linux VFS(Virtual File System)
![]()
通过VFS的功能来管理所有的文件系统,省去自行设置读取文件系统的行为(什么文件系统的模块应该对应读取什么文件的这种行为)
VFS示意图

1.9 XFS文件系统简介(Extended File System)
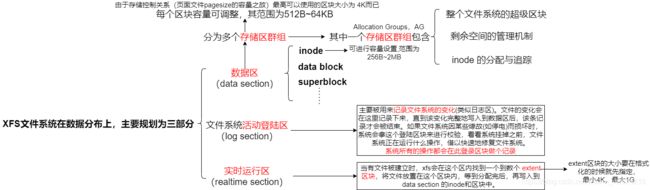
XFS文件系统的描述数据
[root@study ~] xfs_info 挂载点 | 设备文件名
范例:
找出 /boot 这个挂载点下面的文件系统的超级区块记录
