webpack性能优化策略
前言
前端技术的发展真的可以用百(gui)花(quan)齐(zhen)放(luan)来形容,无论是技术栈的演进,技术框架的推新,还是各种模式,反模式的最佳实践都在不断的涌现。如今前端工程化的概念早已深入人心,那种直接在js中写脚本,通过src嵌入到页面,然后按F5刷新页面查看结果的开发方式已经渐行渐远。基本上选择一款合适的编译和资源管理工具已经成为了所有前端工程中的标配,而在诸多构建工具中,webpack以其丰富的功能和灵活的配置在诸多构建工具中大方光彩,React、Vue、Angular2等诸多知名项目也都选用其作为官方构建工具,深受业内追捧,但随着工程开发但复杂度和代码规模不断地增加,webpack暴露出来的性能问题也愈发明显,极大的影响着开发过程中的体验。

问题归纳
经历了多个web项目的实战经验,对webpack在构建中逐步暴露出来的性能问题归纳主要有如下几个方面:
- 代码全量构建速度过慢,即使是很小的改动,也要等待长时间才能查看到更新与编译后的结果(引入HMR热更新后有明显改进);
- 随着项目业务的复杂度增加,工程模块体积也会急剧增大,构建后的模块通常要以M为单位计算;
- 多个项目之间共用基础资源存在重复打包,基础库代码复用率不高;
- node的单进程实现在耗cpu计算型loader中表现不佳;
针对以上问题,我们来看看怎样利用webpack现有的一些机制和第三方扩展插件来逐个击破。
慢在何处
作为工程师,我们需要用数据和事实说话,“我觉得很慢”,“太卡了”,“太大了”,之类的表述难免显得太笼统和抽象,那么我们不妨从以下几个方面来着手进行分析:
- 从项目结果着手,代码组织是否合理,依赖使用是否合理;
- 从webpack自身提供的优化手段着手,看看哪些api未做优化配置;
- 从webpack自身不足着手,做有针对性的扩展,进一步提升效率;
这里我们借助webpack的可视化资源分析工具:webpack-visualizer,在webpack构建的时候会自动帮助你计算各个模块在你的项目工程中的依赖与分布情况,方便做更精确的资源依赖和引用的分析。
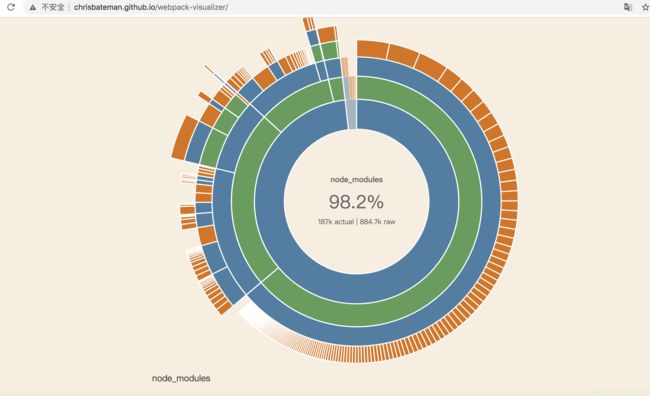
从上图中,我们发现,在大多数的工程项目中,依赖库的体积永远是大头,体积占整个项目的9成,而且在每次开发过程中也会重新读取和编译对应的依赖资源,这其实是很大的资源开销浪费,而且对编译结果影响微乎其微,毕竟在实际业务开发中,我们很少会去修改第三方库中的源码,改进方案如下:
方案一 使用DullPlugin提高打包速度
思想:把项目中用到的第三方模块单独打包到一个dll文件中进行管理,之后打包的时候直接去dll里面引用,不用每次都打包第三方模块,节省了webpack对第三方模块打包分析的时间,提升打包速度。
要实现这些功能点呢需要对webpack做如下配置:
1. 配置dllPlugin对应资源表并编译文件 (新建配置文件webpack.dll.js,并做如下配置):
const path = require('path')
const webpack = require('webpack')
module.exports = {
mode: 'production',
entry: {
// 资源依赖包,提前编译
vendors: ['react', 'react-dom', 'lodash']
},
output: {
filename: '[name].dll.js',
path: path.resolve(__dirname, '../dll'),
// 对应entry里的name
library: '[name]'
},
// 使用插件来分析库文件,把库文件中第三方模块的映射关系放到manifest文件中
plugins: [
new webpack.DllPlugin({
name: '[name]',
path: path.resolve(__dirname, '../dll/[name].manifest.json')
})
]
}
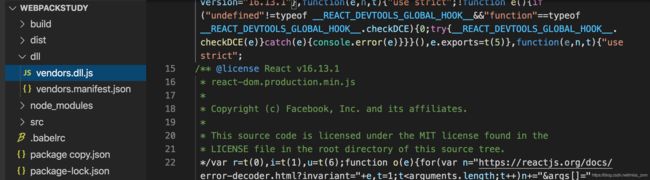
如上图,可以看到react、react-dom等第三方库都被打包到了单独到dll文件中了,同时生成了用来保存映射关系的manifest文件。
文件说明:
- vendors.dll.js可以作为编译好的静态资源文件直接在页面中通过src链接引入;
- vendors.manifest.json中保存了webpack中的预编译信息,这样等于提前拿到了依赖库中的chunk信息,在实际开发过程中就无需要进行重复编译;
2. 配置DllReferencePlugin,将manifest.json文件添加到webpack构建中
在webpack.config.js 配置文件中添加如下代码:
new webpack.DllReferencePlugin({
manifest: path.resolve(__dirname, '../dll/vendors.manifest.json')
})
配置好了之后,打包项目的时候webpack就会对文件进行分析,当遇到第三方模块时,DllReferencePlugin会到manifest文件中找映射关系(dll.js文件和manifest.json存在一一对应关系),如果找到,就会直接使用刚才已打包好的,不会再动态的去node_modules里面引入,减少了打包时间的消耗。
方案二 合理配置resolve参数,降低文件查找性能损耗
- extersions中只配置js、jsx等逻辑性文件,不配置css、jpg等资源类型文件,尽可能减小列表,减少文件查找时的性能损耗;
- 频率出现高的文件后缀优先放在前面;
- 在组件中引入文件时,尽量写上后缀名;
配置如下:
resolve: {
extensions: ['.js', '.jsx'] ,
}
当在组件中引入文件时,比如: import child from ‘./component/child’ ,webpack就会自动带上extersions中配置的后缀去询问文件是否存在,先查找child.js,没有当话再查找child.jsx。因此可以看出,如果列表越长或者正确的后缀越往后,尝试的次数就会越多,损耗的性能越多。
方案三 使用Happypack加速你的代码构建
在webpack中为了方便各种资源和类型的加载,设计了以loader加载器的形式读取资源,但是受限于node的变成模型影响,所有loader虽然以async的形式来并发调用,但是还是运行在单个进程以及在同一个事件循环中,这就直接导致了我们需要同时读取多个loader文件资源时,比如babel-loader需要转换各种jsx、es6文件,那么,在这种同步计算时需要耗费大量cpu运算的过程中,node的单进程就无优势了,那么happypack就是来解决此类问题的。
1. 开启Happypack的线程池
思想:将原油的webpack对loader的执行过程从单一进程形式扩展到多进程模式,原本的流程保持不变,这样就可以在不修改原有配置的基础上来完成对编译过程的优化
具体配置如下:
const HappyPack = require('happypack')
module: {
rules: [{
test: /\.js$/,
exclude: /node_modules/,
loader: 'happypack/loader?id=happybabel',
}]
plugins: [
new HappyPack({
id: 'happybabel',
loaders: ['babel-loader'],
// threadPool: happyThreadPool,
cache: true,
verbose: true
})]
}
我们可以看到通过在loader中配置直接指向happypack提供的loader,对于文件实际匹配的处理 loader,则是通过配置在plugin属性来传递说明,这里happypack提供的loader与plugin的衔接匹配,则是通过id=happybabel来完成。最终的构建提升速度如下:
优化前:

优化后:

小结
性能优化无止境,在前端工程日益庞大的今天,在实际开发中,针对实际项目,持续改进构建工具的性能,对项目开发效率对提升是极其有益的。