python爬虫-Requests-实战爬取有道翻译与电影资源网所有电影名
1.1 Requests安装
• Windows:pip install requests
• Linux:sudo pip install requests
1.2 导入
import requests
1.3 get与post
(1) 在客户端,Get方式在通过URL提交数据,数据在URL中可以看到;POST方式,数据放置在HTML HEADER内提交。
(2) GET方式提交的数据最多只能有1024 Byte,而POST则没有此限制。
(3) 安全性问题。正如在(1)中提到,使用 Get 的时候,参数会显示在地址栏上,而 Post 不会。所以,如果这些数据是中文数据而且是非敏感数据,那么使用get;如果用户输入的数据不是中文字符而且包含敏感数据,那么还是使用 post为好。
表单提交中get和post方式的区别归纳如下几点:
(1)get是从服务器上获取数据,post是向服务器传送数据。
(2)对于表单的提交方式,在服务器端只能用Request.QueryString来获取Get方式提交来的数据,用Post方式提交的数据只能用Request.Form来获取。
(3)一般来说,尽量避免使用Get方式提交表单,因为有可能会导致安全问题。比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。但是在分页程序中,用Get方式就比用Post好。
具体调用命令时,可以先查看Request Method后面的时GET还是POST。
requests.post(url,data=data,headers=headers)
requests.get(url, headers=headers)
url就是我们需要爬取的资源位置,data是提交数据,headers是为了对程序进行伪装成浏览器,瞒过一些拒绝python访问的网站。
1.3.1 Get获取网页源码:
这里我用百度翻译的网页爬取源码,输出结果就是网页源码。
import requests
WebCode = requests.get('https://fanyi.baidu.com/')
WebCode.encoding='utf-8' #因为汉字会乱码,所以将编码方式改成utf-8 print(WebCode.text)
部分网站如果这种方法行不通,可以采取下列措施:
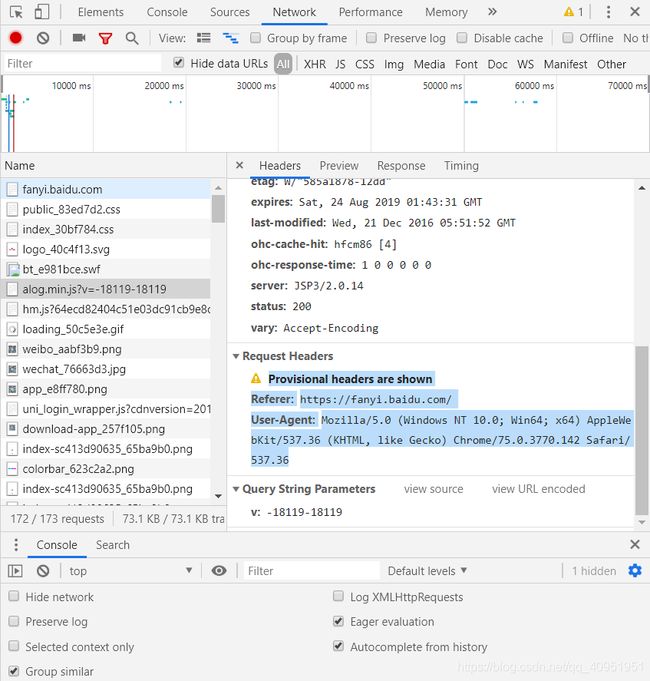
找到User-Agent:,利用这个将自己伪装成浏览器,代码如下:
import requests
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
WebCode = requests.get('https://fanyi.baidu.com/',headers=head)
WebCode.encoding='utf-8' #因为汉字会乱码,所以将编码方式改成utf-8 print(WebCode.text)
1.3.2 Post示例:有道翻译
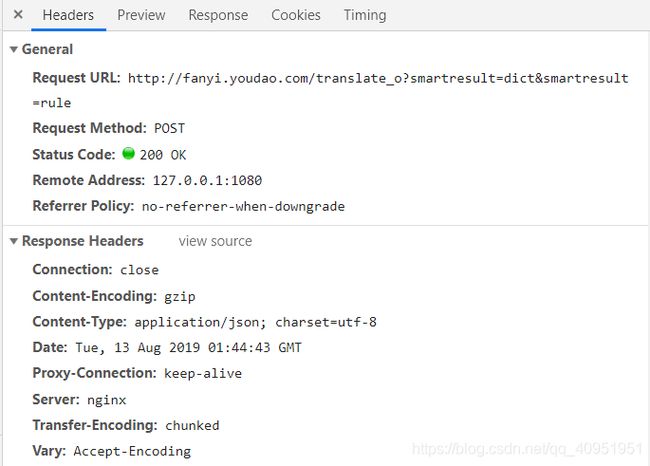
F12打开审核元素,点击到Network,把name栏滑倒最下,与翻译网页各占一半,开始输入需要翻译的文字并注意name最下栏随着输入文字所新添加的元素,然后在这些元素中找到我们需要的东西,可以从preview中查找,这样更加直观。找到以后换到headers,查看请求方式:

我们从General看到这是POST方式和URL,但这里说一下,因为有道翻译有反爬虫机制,所以直接用这个URL是会发生{“errorcode”:50}错误的,所以要把URL中的_o去掉,URL如下:
'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
接下来我们再来找提交的字典数据data,注意data内容的写法,不要直接复制粘贴完就完事了。

完整代码如下:
import requests
import re
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data = {
'i': '我明天去踢球',
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15656606832687',
'sign': '3ed5371910d8a164e3799baada0c2fb5',
'ts': '1565660683268',
'bv': '53539dde41bde18f4a71bb075fcf2e66',
'doctype': 'json',
'version':' 2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME' }
rep = requests.post(url,data=data).text #**只提取文本 print(rep)
result = re.search('src":"(.*?)","tgt":"(.*?)"',rep)
print('中文:'+result[1])
print('英文:'+result[2])
#输出结果:
#{"type":"ZH_CN2EN","errorCode":0,"elapsedTime":1,"translateResult":[[{"src":"我明天去踢球","tgt":"I go to play tomorrow"}]]}
#中文:我明天去踢球
#英文:I go to play tomorrow
1.4 实例——爬取某影视网站所有电影名称
思路:这个程序爬取的是一个影视资源站的所有电影名,首先要用requests.get获取当前网页源码,所以url是当前网址,像这样分页的网页我们不妨先看看第二页的时候网址有什么变化,我们看到了多了?p=2,所以只要把后面的数字改成响应的页数就可以跳转到相应的页面,有了我们需要的所有网页的源码,就可以对网页中的数据进行提取,提取完后先暂存列表,再保存到文件中去。 :
import requests
import re
#换页,并把该页所有电影名称保存到FilmList列表中,参数一是总页数,参数二是当前网页url
def skip(total_page,url):
now_page = int(re.search('p=(\d+)', url, re.S).group(1)) #获取当前页数
FilmList=[]
for i in range(now_page,total_page):
print('正在处理第%d'%i+'页')
upLink = re.sub('p=\d+','p=%d'%i,url,re.S)
#print(upLink)
WebCode = requests.get(upLink) #获取当前网页源码
#WebCode.encoding='utf-8' #因为汉字显示会乱码,所以将编码方式改成utf-8
#print(WebCode.text)
FilmTitle = re.findall('(.*?)',WebCode.text,re.S) #找到当前网页全部电影名
for each in FilmTitle:
#print(each)
FilmList.append(each) #将电影名写入列表
return FilmList
def text_save(filename, data):#filename为写入txt文件的路径,data为要写入数据列表.
file = open(filename,'a')
for i in range(len(data)):
s = str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
file.write(s)
file.close()
print("保存文件成功")
if __name__ == '__main__':
list = skip(10, 'http://www.wuhaozhan.net/movie/list/?p=1')
print(list)
text_save('电影菜单.txt',list)
ose()
print("保存文件成功")
if __name__ == '__main__':
list = skip(10, 'http://www.wuhaozhan.net/movie/list/?p=1')
print(list)
text_save('电影菜单.txt',list)