LeNet试验(一) 搭建pytorch版模型及运行
LeNet非常简单,在MNIST数据集运行速度很快,所以开辟LeNet试验系列文章,以试验各种语句、技巧的效果,分析神经网络的一些特性。
1,Pytorch版本LeNet代码
数据路径为’minst/’,文件夹内放置minst集中的四个gz文件,代码文件放在文件夹外面。
import gzip, struct
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import Dataset, DataLoader
#读取数据的函数
def _read(image, label):
minist_dir = 'mnist/'
with gzip.open(minist_dir + label) as flbl:
magic, num = struct.unpack(">II", flbl.read(8))
label = np.fromstring(flbl.read(), dtype=np.int8)
with gzip.open(minist_dir + image, 'rb') as fimg:
magic, num, rows, cols = struct.unpack(">IIII", fimg.read(16))
image = np.fromstring(fimg.read(), dtype=np.uint8).reshape(len(label), rows, cols)
return image, label
#读取数据
def get_data():
train_img, train_label = _read(
'train-images-idx3-ubyte.gz',
'train-labels-idx1-ubyte.gz')
test_img, test_label = _read(
't10k-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz')
return [train_img, train_label, test_img, test_label]
#定义lenet5
class LeNet5(nn.Module):
def __init__(self):
'''构造函数,定义网络的结构'''
super().__init__()
#定义卷积层
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
#第二个卷积层,6个输入,16个输出,5*5的卷积filter
self.conv2 = nn.Conv2d(6, 16, 5)
#最后是三个全连接层
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
'''前向传播函数'''
#先卷积,然后调用relu激活函数,再最大值池化操作
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
#第二次卷积+池化操作
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
#重新塑形,将多维数据重新塑造为二维数据,256*400
x = x.view(-1, self.num_flat_features(x))
#print('size', x.size())
#第一个全连接
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
#x.size()返回值为(256, 16, 5, 5),size的值为(16, 5, 5),256是batch_size
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
#训练函数
def train(epoch):
#调用前向传播
model.train()
train_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
if use_gpu:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= len(train_loader.dataset)
print('Train Epoch: {} \tTrain Loss: {:.6f}'.format(
epoch, train_loss))
#定义测试函数
def test():
model.eval() #测试模式,主要是保证dropout和BN和训练过程一致。
test_loss = 0
correct = 0
for data, target in test_loader:
if use_gpu:
data, target = data.cuda(), target.cuda()
output = model(data)
#计算总的损失
test_loss += criterion(output, target).item()
pred = output.data.max(1, keepdim=True)[1] #获得得分最高的类别
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
class DealDataset(Dataset):
"""
数据封装成dataset类型
"""
def __init__(self,mode='train'):
X, y, Xt, yt = get_data()
if mode=='train':
self.x_data = X
self.y_data = y
elif mode=='test':
self.x_data = Xt
self.y_data = yt
self.x_data = torch.from_numpy(self.x_data.reshape(-1, 1, 28, 28)).float()
self.y_data = torch.from_numpy(self.y_data).long()
self.len = self.x_data.shape[0]
def __getitem__(self, index):
data = self.x_data[index]
target = self.y_data[index]
return data, target
def __len__(self):
return self.len
#封装数据集
train_dataset = DealDataset(mode='train')
test_dataset = DealDataset(mode='test')
#定义数据加载器
kwargs = {
"num_workers": 0, "pin_memory": True}
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=256, **kwargs)
test_loader = DataLoader(dataset=test_dataset, shuffle=True, batch_size=256, **kwargs)
#实例化网络
model = LeNet5()
#是否使用GPU
use_gpu = torch.cuda.is_available()
if use_gpu:
model = model.cuda()
print('USE GPU')
else:
print('USE CPU')
#使用交叉熵损失函数
criterion = nn.CrossEntropyLoss(size_average=False)
#优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.99))
#执行训练和测试
for epoch in range(1, 101):
train(epoch)
test()
2,运行
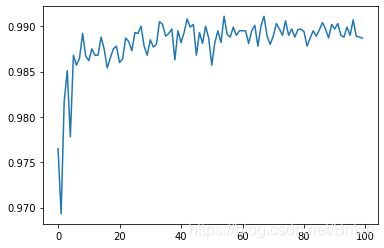
运行结果:

下面几个画图的代码上面没有。
train_loss:

test_loss:

accuarcy: