用python来帮你表白,马赛克拼贴照片制作
养成习惯,先赞后看!!!
目录
- 1.前言
- 2.重点原理
- 3.实现步骤
-
- 3.1修改图片大小
- 3.2计算图片的直方图
- 3.3比较直方图差异,同时替换
- 3.4融合图片
- 4.效果演示
1.前言
主要思想及代码来源于这篇老哥的文章:https://zhuanlan.zhihu.com/p/168667043
有兴趣的小伙伴可以去看看。
其实之前我在b站上就曾经看到过这样一个软件:
顺便贴出软件的下载地址:https://xttx.lanzous.com/id6euad
使用教程:https://www.bilibili.com/video/BV14g4y1i7Ey
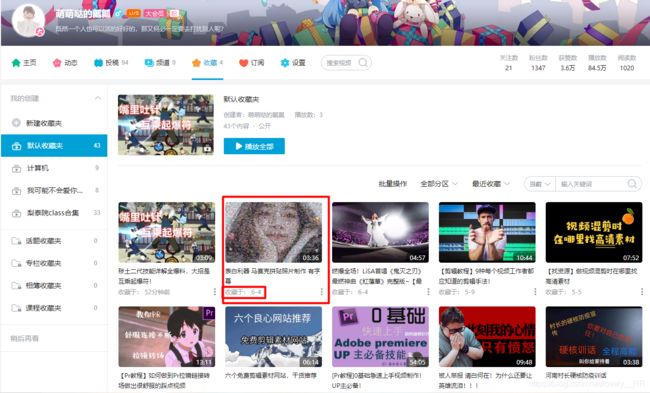
当时我就测试了一下,发现这个软件不是特别的友好,他对于你输入的图片组的 要求是比较高的 ,意思就是你输入的图片组最好本身的尺寸大小最好和你要替换的原图的尺寸大小类似或者是成一定的比例,这样他拼接出来效果的确是可以的,就像下图:
如果尺寸不对或者说提供的图片数量不够,或者说色差太过单一的话,就可能会出现下面的情况:

现在想想我尼玛就是为了图方便才用你的,你这还得让我去找这样那样的图片,那不还是很麻烦吗。所以之后也没怎么用这个软件了。
但是这几天看csdn的时候看到了这位老哥的博客:https://blog.csdn.net/qq_43667130/article/details/107892516
但是他是用C++实现的,我就没看,但是老哥人好,提供一篇用python实现的博客,就是上面那篇博客,于是我就开始尝试读懂并使用它。
2.重点原理
虽然我们不会但是,我们其实也能够说出原理大体上是啥。其实主要步骤就是两步:
1. 将原图与图片组进行适当的分割
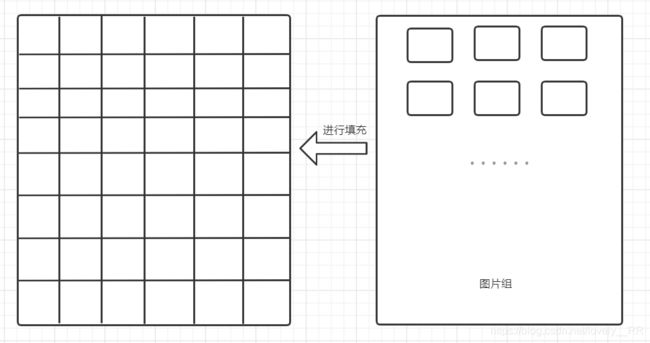
2. 进行色差比较,用色差最相似的图片进行替换
第一步我们通过画图就能看懂了,如下图: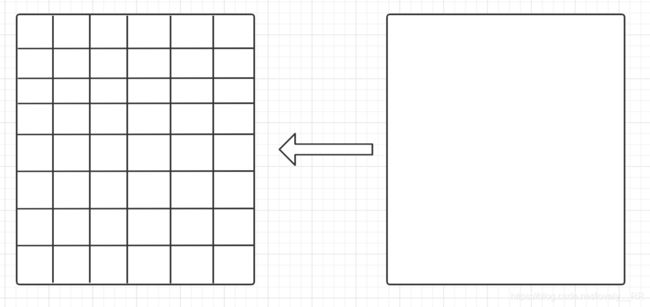
第二步大家也都能理解,我就不扯淡了,如下图:
3.实现步骤
3.1修改图片大小
这里主要包含两方面,一是修改图片组的大小。因为我们提供的图片有的可能是横版的,有的可能是竖版的,并且有的可能是3:4。有的可能是16:9,反正就是图片的大小肯定会出现差异,所以我们需要将图片组的大小固定下来。
这里有个小bug: 如果data1后面的 “/ ”千万不能少,少了他就是单纯读取这个文件,而并非是读取该文件夹目录下的文件,并且所有的路径名当中都不能包含中文,否则也会报错
这里图片组中的图片都是我之前爬虫获得的图片,爬虫源码在我之前的这篇博客中:python爬虫–批量下载cosplay小姐姐图片
# 预处理填充图片
def before_handle_imgs():
print("正在预处理填充图片:")
# 读取图片组的存储路径
readPath = "D:/test/data1/"
# 修改完后图片组的存储路径
savePath = "D:/test/data2/"
files = os.listdir(readPath)
for file in files:
imgPath = readPath + "/" + file
# 读取图片
img = cv.imread(imgPath)
# 重新设置图片的大小,长160px,宽90px
img = cv.resize(img, (160, 90))
# 将修改完后的图片存储到data2目录下
cv.imwrite(savePath + "/" + file, img)
print("预处理填充图片已完成!")
二就是重新修改我们原图的大小,这里的大小就是要和上面的大小对应,长宽一定要是上面图片的倍数,否则就会出现一开始我们遇到的有黑色区域,当然了运行程序他是会 直接报错的
# 预处理待填充图片
def before_handle_img():
print("正在预处理待填充图片:")
# 重新设置原图的大小
width, height = 32000*n, 13500*n
# 读取原图
readPath = "D:/test/img1.jpg"
# 修改完后图片的存储位置
savePath = "D:/test/img2.jpg"
img = cv.imread(readPath)
# 修改图片大小
img = cv.resize(img, (width, height))
# 存储图片
cv.imwrite(savePath, img)
print("预处理待填充图片已完成!")
3.2计算图片的直方图
我们一开始不懂的就以为是计算色差,看了源码之后才知道原来是计算他们的直方图就行了。真的是被自己蠢到了。

这里我们主要讲解一下 cv2.calcHist() 这个函数,大家就懂了。这个函数有5个参数
- image输入图像,传入时应该用中括号[]括起来
- channels::传入图像的通道,如果是灰度图像,那就不用说了,只有一个通道,值为0,如果是彩色图像(有3个通道),那么值为0,1,2,中选择一个,对应着BGR各个通道。这个值也得用[]传入。
- mask:掩膜图像。如果统计整幅图,那么为none。主要是如果要统计部分图的直方图,就得构造相应的炎掩膜来计算。
- histSize:灰度级的个数,需要中括号,比如[256]
- ranges:像素值的范围,通常[0,256],有的图像如果不是0-256,比如说你来回各种变换导致像素值负值、很大,则需要调整后才可以。
这样我们便能计算出图片组中各图片的直方图参数了。
# 用字典存储每一图及其直方图
def build_index():
print("正在计算各图片直方图:")
# 修改完大小后图片的存储路径
readPath = "D:/test/data2/"
files = os.listdir(readPath)
dist = {
}
for file in files:
imgPath = readPath + "/" + file
img = cv.imread(imgPath)
hist = []
# 因为有三个通道即RGB,所以一张图片要计算三次
for i in range(3):
ht = cv.calcHist([img], [i], None, [256], [0, 256])
hist.append(ht)
dist[file] = hist
print("各图片直方图计算已完成!")
return dist
3.3比较直方图差异,同时替换
既然需要比较直方图信息,那么我们就必须也要计算原图各区域的直方图信息,然后循环与图片组的直方图进行比较,并且同时记住当前与其最相似的图片,再循环结束后将其替换。
这其中我们也是重点讲一下这个函数 cv2.compareHist 他主要有三个参数:
- H1为其中一个直方图
- H2为另一个图像的直方图
- method为比较方式
相关性比较 (method= cv.HISTCMP_CORREL ) 值越大,相关度越高,最大值为1,最小值为0
卡方比较(method=cv.HISTCMP_CHISQR 值越小,相关度越高,最大值无上界,最小值0
巴氏距离比较(method=cv.HISTCMP_BHATTACHARYYA) 值越小,相关度越高,最大值为1,最小值为0
# 用最相近的图代替原图
def match_replace(dist):
print("正在替换图片:")
width, height = 32000* n, 13500* n
image = cv.imread("D:/test/img2.jpg")
for i in range(0, height, 90):
for j in range(0, width, 160):
img = image[i:i+90, j:j+160, 0:3]
hist = []
# 计算原图一个马赛克大小的三个通道的直方图
for k in range(3):
ht = cv.calcHist([img], [k], None, [256], [0, 256])
hist.append(ht)
sim = 0.0
# 与整个图片组的直方图进行比较
for key in dist:
# 分别比较三个通道的相似度
match0 = cv.compareHist(hist[0], dist[key][0], cv.HISTCMP_CORREL)
match1 = cv.compareHist(hist[1], dist[key][1], cv.HISTCMP_CORREL)
match2 = cv.compareHist(hist[2], dist[key][2], cv.HISTCMP_CORREL)
match = match0 + match1 + match2
# 没计算过一次,就和之前的相似度进行比较,如果大于说明更加相似就替换,否则就不
if match > sim:
sim = match
rename = key
# 替换图片
image[i:i+90, j:j+160, 0:3] = cv.imread("D:/test/data2/" + rename)
cv.imwrite("D:/test/img3.jpg", image)
print("图片替换已完成!")
效果就是这样的:
这里我们放大看看:
可以发现的确替换了,并且照片的大小也是急剧增加:
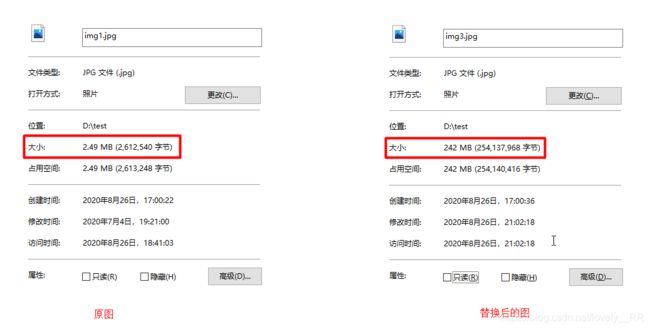
3.4融合图片
其实到上面一步,我们的马赛克图片就做出来了,我自己觉得这样就够了,但是那个老哥还加了这一步就是将原图与我们的马赛克图进行了混合,但是说实话混合之后的确更像了,但是说实话不怎么看的出来是有马赛克合成的。
这里我们还是重点讲一个函数即 cv2.addWeighted() ,这个函数主要有五个参数:
- InputArray src1:表示需要加权的第一个数组,即第一张图像
- alpha:表示第一个图像的权重
- src2:表示第二个数组,和第一个具有相同的尺寸和通道数,即第二张图像
- beta:表示第二个数组的权重值
- gamma:一个加到权重总和上的标量值
上面两者的权重和必须要为1
# 混合图片
def mix_image():
print("正在融合图片:")
# 马赛克图像
image1 = cv.imread("D:/test/img3.jpg")
# 原图修改后的图像
image2 = cv.imread("D:/test/img2.jpg")
# 图像融合
dst = cv.addWeighted(image1, 0.6, image2, 0.4, 3)
# 融合后的图像
cv.imwrite("D:/test/img4.jpg", dst)
print("图片融合已完成!")
image1为马赛克图,image2为修改大小后的原图
image1权重为0.3,image2权重为0.7,如下图:
image1权重为0.7,image2权重为0.3,如下图:
这样对比下来还是能看出融合的效果的
但是我自己还是觉得没必要,感觉就没怎么经过马赛克的过程,感觉基本上就是原图了,所以不太懂这一步。

而且这里大家可能根本看不出来这到底是不是我的图片组构成的啊,这里我们放大之后可以看到:
这里我们看到的确还是由我们的图片组构成的,并且融合之后的图片大小也会增大不少,但是相对于直接替换还是相对小了一点:
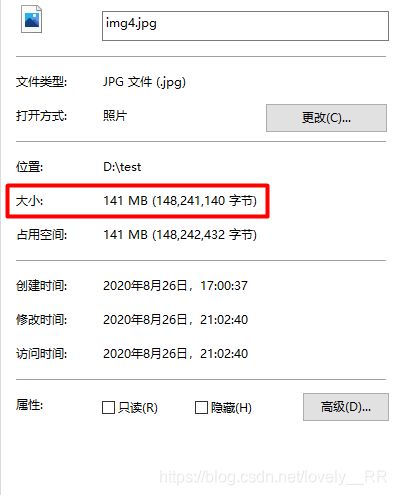
4.效果演示
中间的计算过程与融合过程经过加速了。
一开始我们先看的图片组的原图,之后看的是图片组修改成马赛克大小后的图片:
之后我们看的是先是原图,接着是原图修改大小后的样子
接着就是原图的马赛克图,最后就是融合形成的图。
都看到这里了,如果觉得对你有帮助的话,可以关注博主的公众号,新人up需要你的支持。

如果有什么疑问或者的话,可以私聊博主。
想要源码可以关注公众号回复 蒙太奇 自取哦。