命名实体识别一个小例子的学习过程
一.首先是有关机器学习一些概念
1.机器学习可以被分类为:
①.监督学习:其中数据带有一个附加属性,即我们想要预测的结果值。
②.分类:样本属于两个或者更多的类,想从已经标记的数据中学习如何预测未标记数据的类别。从有限的类别中,给每个样本贴上正确的标签。
③.回归:如果期望的输出由一个或者多个连续变量组成,则称为回归。eg:预测鲑鱼的长度是其年龄和体重的函数。
④.无监督学习:其中训练数据由没有任何相应目标值的一组输入向量x组成,这种问题的目标可能是在数据中发现彼此类似的示例所聚成的组,称为聚类。
或者,确定输入空间内的数据分布,称为密度估计。
又或者,从高维数据投影数据空间缩小到二维或者三维进行可视化。
2.数据集和测试集
机器学习是从数据的属性中学习,并应用到新数据的过程中去。
所以需要将数据集分为:训练集和测试集。
其中我们从训练集中学习数据的属性,并使用测试集去测试模型的正确性。
3.数据交换格式
在计算机的不同程序之间,或者不同的编程语言之间进行交换数据,也需要一种大家都听得懂的语言,这就是数据交换格式,通过文本以特定的形式进行描绘数据。主要有xml,json,yaml
①. xml(Extensible Markup Language)可扩展标记语言
设计宗旨在于传输数据而非显示数据,xml标签没有被预先定义,需要自行定义标签。
②. json(JavaScript Object Notation)
是一种轻量级的数据交换格式,采用完全独立于语言的文本格式。
%%%%%%用一个例子直观认识两种数据交换格式:
有一个用户数据包括:用户名、密码、所在部门、性别、年龄
————————使用XML进行表示————————————
< user>
< name>张三< /name>
< password>123456< /password>
< department>技术部< /department>
< sex>男< /sex>
< old>30< /old>
< /user>
————————使用JSON进行表示————————————
{
“name”:“张三”,
“password”:“123456”,
“department”:“技术部”,
“sex”:“男”,
“old”:“30”
}
二. 实体识别过程概述
1.数据预处理
包括对配文件进行检查、对用户上传正负语料打上标签、并完成切词和词性标注。
2.数据切分
先从训练语料中按模取十分之一的数据作为测试集。测试集用于评估定制化前后的效果。接着对剩下的数据进行打乱,按照比例切分为训练集和验证集,其中训练集用于模型的训练,验证集用于已经训练好的模型中筛选效果最好的模型。
3.特征提取和格式转换
生成训练词典,将训练集、测试集、验证集转换为相应的格式,供训练使用。
4.训练、验证及测试
使用训练工具进行训练,从训练的模型中挑选效果最好的模型,并在测试集上评估制定前后的准确率。
三. 代码片段
from bs4 import BeautifulSoup as bs
from bs4.element import Tag
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import codecs
import nltk
import pycrfsuite
import numpy as np
# Read data file and parse the XML
with codecs.open("D://mydata_git//n3-collection//reuters.xml", "r", "utf-8") as infile: #utf-8编码格式打开文件
soup = bs(infile, "html5lib")
#print(soup.simpletextpart) #输出xml中第一个simpletxtpart,全部小写,如果是SimpleTextPart无法通过
docs = [] #列表
for elem in soup.find_all("document"): #对于每一个document创建texts
texts = []
# Loop through each child of the element under "textwithnamedentities"
for c in elem.find("textwithnamedentities").children:
if type(c) == Tag:
if c.name == "namedentityintext":
label = "N" # part of a named entity
else:
label = "I" # irrelevant word
for w in c.text.split(" "): #将句子切割为单词
if len(w) > 0:
texts.append((w, label))
#for w in c:
# texts.append((w,label))
docs.append(texts)
#print(docs)
data = []
#for i,doc in enumerate(docs):
for doc in docs:
#Obtain the list of tokens in the document
tokens = [t for t,label in doc]
#Perform POS tagging
tagged = nltk.pos_tag(tokens)
#Take the word,POS tag,and its label
data.append([(w,pos,label) for (w,label),(word,pos) in zip(doc,tagged)])
#print(data)
def word2features(doc, i): #获取的是data
word = doc[i][0]
postag = doc[i][1]
#Common features for all words
features = [ #不懂这些特征??????
'bias',
'word.lower=' + word.lower(), #就是将单词转换为小写形式
'word.upper=' + word.upper(),
'word[-3:]=' + word[-3:], #取单词的后三个字母
'word[-2:]=' + word[-2:], #取单词的后两个字母
'word.isupper=%s' % word.isupper(), #判断单词是否大写
'word.istitle=%s' % word.istitle(), #判断是否首字母大写其余小写
'word.isdigit=%s' % word.isdigit(), #判断是否数字
'postag=' + postag #词性标签
]
#Features for words that are not at the beginning of a document
#对于不在文档开头的单词
#提取前文特征
if i > 0:
word1 = doc[i-1][0]
postag1 = doc[i-1][1]
features.extend([
'-1:word.lower=' + word1.lower(),
'-1:word.istitle=%s' % word1.istitle(),
'-1:word.isupper=%s'% word1.isupper(),
'-1:word.isdigit=%s'% word1.isdigit(),
'-1:postag=' + postag1
])
else:
#Indicate that it is the 'beginning of a document'
features.append('BOS')
#Features for words that are not at the end of a document
#对于不是文档最后一个的单词
#提取下文特征
if i < len(doc)-1:
word1 = doc[i+1][0]
postag1 = doc[i+1][1]
features.extend([
'+1:word.lower=' + word1.lower(),
'+1:word.istitle=%s' % word1.istitle(),
'+1:word.isupper=%s' % word1.isupper(),
'+1:word.isdigit=%s' % word1.isdigit(),
'+1:postag=' + postag1
])
else:
#Indicate that it is the 'end of a document'
features.append('EOS')
return features
#A function for extracting features in documents
#文档特征提取函数
def extract_features(doc):
return [word2features(doc,i) for i in range(len(doc))]
#A function for generating the list of labels for each document
#为每个文档生成标签列表
def get_labels(doc):
return [label for (token,postag,label) in doc]
#print("这是doc")
#for doc in data:
# print(extract_features(doc))
x = [extract_features(doc) for doc in data] #x拿到的是每个单词的特征
y = [get_labels(doc) for doc in data] #y拿到的是每个单词的标签,例如N/I
#print("这是x")
#print(x)
#print("这是y")
#print(y)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)#按照8:2将数据集进行训练集:测试集进行划分
#print("这是x_train")
#print(x_train)
trainer = pycrfsuite.Trainer(verbose=False) #创建一个训练器,verbose=True将打印出训练过程
#Submit training data to the trainer #将训练数据装载进trainer训练器
for xseq,yseq in zip(x_train,y_train): #装载进去的是一个zip
trainer.append(xseq,yseq)
#Set the parameters of the model #默认使用lbfgs算法,下面对算法的参数进行了设置
trainer.set_params({
#cofficient for L1 penalty
'c1':0.1,
#coefficient for L2 penalty
'c2':0.01,
#maximum number of iterations
'max_iterations':200,
#whether to include transitions that are possible,but not observed
'feature.possible_transitions':True
})
#Provide a file name as a parameter to the train function, such that the model will be saved to the file when training is finished
trainer.train('crf.model') #将训练器的模型命名为crf.model,此后可用这个模型去训练测试数据
tagger = pycrfsuite.Tagger() #创建一个标记器
tagger.open('crf.model')
y_pred = [tagger.tag(xseq) for xseq in x_test] #利用model对测试集的数据进行预测
#let's take a look at a random sample in the testing set
i=12
print("a random simple")
print(x_test)
print(x_test[0])
print([x[1].split("=")[1]for x in x_test[0]])
for x,y in zip(y_pred[i],[x[1].split("=")[1]for x in x_test[i]]):
print("%s (%s)" % (y,x))
#Create a mapping of labels to indices
labels = {
"N":1, "I":0}
#Convert the sequences of tags into a 1-dimensional array
#将预测出来的标签序列转换为一维数组
predictions = np.array([labels[tag] for row in y_pred for tag in row])
truths = np.array([labels[tag] for row in y_test for tag in row])
# print out the classification report
print(classification_report(
truths,predictions,target_names=["I","N"]
))
#总结流程如下
# 首先对文章内容打标签,包括是否实体,以及词性标签
# 构建特征函数
# 将数据集进行划分
# 构建训练器,使用算法以及特征函数进行训练
# 构建标注器,对测试集进行预测
# 将标签序列转化为一维数组
# 输出预测结果
四. 关于代码中一些知识点的解释
1.利用codecs模块实现字符的编码转换工作
编码转化时,通常以unicode作为中间编码,即
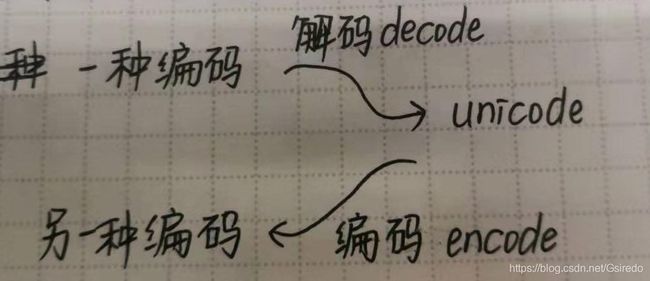
用codecs的open方法来指定打开的文件的语言编码,它会在读取的时候自动转化为unicode。如果直接用语言内建的open方法打开之后会是乱码。
———————————利用codecs——————————————
import codecs
with codecs.open(write_fileroute,‘a’,encoding=‘utf-8’)as f:
f.write(‘要写入文件的内容’)
———————————直接打开————————————————
with open(file,‘a’)as f:
f.write(‘要写入文件的内容’)
2.beautiful soup解析文档
①. 主要功能
从网页中抓取数据,通过解析文档为用户提供需要抓取的数据。
②. beautiful soup解析出来的节点对象
beautiful soup将复杂的文档解析为一个树形结构,每个节点都是Python的对象:Tag/Beautiful Soup/NavigableString/Comment
<1>Tag
html的一个个标签
eg: < h1>welcome< /h1> 其中的加粗部分为tag
<2>Beautiful Soup
文档的全部内容
<3>NavigableString
标签内部的文字,比如上面的welcome
<4>Comment
文档的注释部分
3.利用nltk库替单词加上词性标签
①. nltk库介绍
nltk是一个高效的python构建的平台,用来处理人类自然语言数据。它提供了易于使用的接口,通过这些接口可以访问超过50个语料库和词汇资源。还有一套用于分类、标记化、词干标记、解析和语义推理的文本处理库。
②. 使用nltk实现简单的例子
<1>给一些文本分词+打标签
import nltk
sentence = """At eight o'clock on Thursday morning Arthur didn't feel very good."""
tokens = nltk.word_tokenize(sentence)
print(tokens)
tagged = nltk.pos_tag(tokens)
print(tagged[0:12])<2>识别已经命名的实体
#nltk.download('maxent_ne_chunker')
#nltk.download('words')
entities = nltk.chunk.ne_chunk(tagged)
print(entities)<3>显示解析树
#nltk.download('treebank')
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0] #wsj是华尔街日报语料
t.draw()③. nltk词性标注POS中的词性
CC 连词 and, or,but, if, while,although
CD 数词 twenty-four, fourth, 1991,14:24
DT 限定词 the, a, some, most,every, no
EX 存在量词 there, there’s
FW 外来词 dolce, ersatz, esprit, quo,maitre
IN 介词连词 on, of,at, with,by,into, under
JJ 形容词 new,good, high, special, big, local
JJR 比较级词语 bleaker braver breezier briefer brighter brisker
JJS 最高级词语 calmest cheapest choicest classiest cleanest clearest
LS 标记 A A. B B. C C. D E F First G H I J K
MD 情态动词 can cannot could couldn’t
NN 名词 year,home, costs, time, education
NNS 名词复数 undergraduates scotches
NNP 专有名词 Alison,Africa,April,Washington
NNPS 专有名词复数 Americans Americas Amharas Amityvilles
PDT 前限定词 all both half many
POS 所有格标记 ’ ‘s
PRP 人称代词 hers herself him himself hisself
PRP$ 所有格 her his mine my our ours
RB 副词 occasionally unabatingly maddeningly
RBR 副词比较级 further gloomier grander
RBS 副词最高级 best biggest bluntest earliest
RP 虚词 aboard about across along apart
SYM 符号 % & ’ ” ”. ) )
TO 词to to
UH 感叹词 Goodbye Goody Gosh Wow
VB 动词 ask assemble assess
VBD 动词过去式 dipped pleaded swiped
VBG 动词现在分词 telegraphing stirring focusing
VBN 动词过去分词 multihulled dilapidated aerosolized
VBP 动词现在式非第三人称时态 predominate wrap resort sue
VBZ 动词现在式第三人称时态 bases reconstructs marks
WDT Wh限定词 who,which,when,what,where,how
WP WH代词 that what whatever
WP$ WH代词所有格 whose
WRB WH副词
4 .使用sklearn进行数据划分
通常使用train_test_split进行数据划分
①. def train_test_split(*arrays, **options):
其中options包括test_size, train_size, random_state, shuffle, stratify
test_size有三种类型:
float:0.0-1.0之间,代表测试集占数据总集的一个比例。
int:代表测试数据集具体的样本数量。
None:设置为训练数据集的补。
shuffle:默认为None,在划分数据前先打乱数据。
stratify:array-like或者None(默认),如果不是None,将会利用数据的标签分层划分。
————————————————————————————————————
当数据太大而无法存入单个计算机内,使用外存算法。
②. 感知机
per = PerPerceptron(verbose=10, n_jobs=-1, max_iter=5)
per.partial_fit(X_train, y_train, classes)③. 具有SGD训练的线性分类器
sgd = SGDClassifier()
sgd.partial_fit(X_train,y_train,classes)④. 用于多项模型的朴素贝叶斯分类器
nb =MultinomialNB(alpha = 0.01)
nb.partial_fit(X_train,y_train,classes)⑤. Passive Aggressive分类器
pa = PassiveAggressiveClassifier()
pa.partial_fit(X_train,y_train,classes)5.利用pycrfsuite创建训练器和标记器
trainer = pycrfsuite.Trainer(verbose=False) 创建一个训练器,将训练数据装载进行,通过trainer.set_params对算法的参数进行设置,trainer.train(‘crf.model’) 将训练器的模型命名为crf.model用于后续的测试。
tagger = pycrfsuite.Tagger()创建一个标记器,将crf.model模型用于标记器中,y_pred = [tagger.tag(xseq) for xseq in x_test]将训练数据通过模型进行训练从而得到预测数据y_pred
6.利用numpy将标签序列转化为一维数据
numpy(Numerical Python)是Python语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
7.利用sklearn打印预测精度
对于二分类的混淆矩阵
Actual Positive Negative
Positive True Positive False Positive
Negative False Negavite True Negative
①. 召回率 recall
召回率=真正例/(真正例+假反例)
召回率可以被理解为模型找到数据集中所有感兴趣的数据点的能力。
②. 精度 precision
精度=真正例/(真正例+假正例)
精度表达模型找到的数据点中实际相关的实例。
随着精度的增加,召回率会下降,反之亦然。
③. 精度-召回率权衡f1-score
f1=2*(precision*recall)/(precision+recall)
当f1较高时说明实验方法较有效。
④. 正确率accuracy
正确率=真正例/所有例
正确率越高分类器越好。
⑤. marco avg简单的算术平均 weighted avg对每一类的加权平均,权重为所占比例。
参考链接:https://sklearn.apachecn.org/docs/0.21.3/51.html
https://wenku.baidu.com/view/ea5479be85254b35eefdc8d37
6eeaeaad1f31698.html
http://ai.baidu.com/forum/topic/show/942823
https://www.cnblogs.com/hester/p/5465338.html
https://www.jianshu.com/p/d12015530dd6
https://blog.csdn.net/qq_35203425/article/details/81591568