Mysql事务和锁(三) 事务中的锁
- Mysql事务和锁(一) 事务的ACID特性和原理
- Mysql事务和锁(二) 事务的隔离级别和MVCC
- Mysql事务和锁(三) 事务中的锁
- Mysql事务和锁(四) 死锁
Mysql中的锁
锁是计算机协调多个进程或者线程并发访问某一个资源的机制,用于维护数据一致性。
锁的分类
从对数据操作的类型分为:读锁和写锁
读锁(共享锁,S锁,share的缩写):
对同一份数据,多个读操作可以同时进行。
写锁(排他锁,X锁):
当某个用户对数据进行修改的时候,不允许其他用户读或者写。
读锁和读锁之间不会冲突(意思是一行数据被一个客户端A加了读锁,其他客户端B也可以对这条数据加读锁)
读锁和写锁之间会冲突:这里分为两种情况,一种是先加读锁,后加了写锁,此时加写锁会产生冲突进入等待状态;另一种是先加写锁,后加读锁,此时加读锁产生冲突进入等待状态。
写锁和写锁之间也会冲突,要等待前一个写锁被释放另一个客户端才能加写锁。
小结就是:读锁-读锁不阻塞,读锁-写锁会阻塞,写锁-读锁会阻塞,写锁-写锁会阻塞。
有时候,执行语句时mysql会自动给这条语句上锁,有时候又不会,具体看存储引擎。不过我们也可以手动上锁。
如何手动上锁:
- 上排他锁:
Select/update/insert/delete ...... for update; # 如果是innodb,这里上的是行锁,如果在myisam这里上的是表锁。
- 上共享锁:
Select/update/insert/delete ...... lock in share mode;
从粒度来分:表锁和行锁
表锁:偏向于myisam,开销小,加锁快,而且不会发生死锁;锁定粒度大,发生锁冲突的概率高,并发度低。
行锁:偏向于innodb,容易发生死锁;锁粒度小,并发度较高。
表锁和行锁中也分读锁和写锁。
手动上表锁:
Lock table t write; # 给表t上一个表级的写锁
Lock table t read; # 给表t上一个表级的读锁
批量给表锁解锁:
Unlock tables
Myisam只支持表锁。
Innodb支持表锁和行锁。
下面针对myisam和innodb两种引擎发生并发读写来理解读锁、写锁、表锁和行锁。
Myisam下的并发加锁:
情景1:
客户端A先执行
Select * from t where id between 1 and 200000;
同时客户端B:
Select * from t where id = 200001;
结果: A和B同时执行select。
原因:A执行select时,myisam会自动为t表加一个表级的读锁;B执行select的时候也会为t上一个表级的读锁。但是读锁之间不排斥,所以B也上锁成功。AB可以同时读。
情景2:
客户端A先执行
Select * from t where id between 1 and 200000;
同时客户端B:
Update t set name=’111’ where id = 200001;
结果: B等A执行select完毕后才开始执行update。
原因:A执行select时,myisam会自动为t表加一个表级的读锁;B执行update的时候也会为t上一个表级的写锁。但是读锁和写锁之间排斥,此时阻塞,所以B要等A释放了读锁之后才能上写锁。
情景3:
客户端B先执行
Update t set name=’111’ where id = 200001;
同时客户端A:
Select * from t where id between 1 and 200000;
结果: A等B执行完update之后才开始select
原因:B先上表级别的写锁,此时A想上读锁被失败,要等B解锁后A才能上锁。
情景4:
客户端A先执行
Select * from t where id between 1 and 200000 for update;
同时客户端B:
Select * from t where id = 200001;
结果: B等A执行完后才执行。
原因:使用了 for update,表示A执行这条select时不是上一个读锁,而是上一个写锁(排他锁)。所以B要上锁的时候被写锁排斥阻塞。
Innodb下的并发:
先说明几点:
首先,innodb中除了select之外,每一句sql单句都是一个事务。
比如:
# 执行
insert into t values (null, “zbp”)
# 它其实真正执行的是
Begin;
insert into t values (null, “zbp”)
Commit;
还有在自动提交事务和非自动提交事务的情况下,begin的执行顺序
比如:
# 我要执行两个sql单句
Insert xxx1; # 隔10秒后,我才去执行下面这句insert
Insert xxx2;
# 在自动提交事务(set autocommit=1)的情况下,它的真实执行情况如下:
Begin;
Insert xxx1;
Commit;
# 过了10秒之后
Begin;
Insert xxx2;
Commit;
# 在手动提交事务(set autocommit=0)的情况下,它的真实执行情况如下:
Begin;
Insert xxx1;
Commit;
Begin;
# 过了10秒时候
Insert xxx2;
Commit;
Begin;
这里只是提一提非自动提交事务的这个特点,但大多数情况我们的单sql事务都是使用自动提交事务的。
第二点是:在事务中,执行sql的时候可能自动或手动加了锁,但是执行完这条sql后锁不会释放,要等到commit后才会释放。
比如
Begin;
Update xxx # 上了锁1
Update xxx2 # 上了锁2
Delete from xxx where id=3 # 上了锁3
Commit; # 释放锁1,锁2,锁3
下面开始情景分析:
客户端A和B同时begin,之后
情景1:
客户端A先:
Update t set name=’zbp’ where id = 3;
还没commit
客户端B同时:
Select * from t where id=3;
结果:A和B同时执行,B没有阻塞。
原因:在innodb事务中,读数据的时候默认不加锁,而是采用mvcc的机制读取undo日志中的历史数据。所以,A执行update的时候,会上一个行级的排他锁,但是B执行select的时候,由于无需上写锁,所以B不会阻塞。
假设没有mvcc机制,那么B读数据的时候就需要加一个读锁,此时B会阻塞。所以MVCC机制在一定程度上解决了读-写之间的并发问题。MVCC在之后会再介绍
情景2:
客户端A先:
Select * from t where id=3 lock in share mode;
还没commit
客户端B同时:
Update t set name=’111’ where id =3;
结果:A先执行完,B被阻塞没有执行。
原因:A手动给id为3的数据加了一个行级的读锁。读锁和B的写锁相排斥所以阻塞。B要等到A执行了commit的时候才会释放锁,B才开始执行。
情景3:
客户端A先:
Select * from t where id=3 lock in share mode;
还没commit
客户端B同时:
Update t set name=’111’ where id =4;
结果:AB同时执行没有阻塞。
原因:A和B加锁的对象分别是不同的行。这个例子说明innodb默认使用行锁而非表锁。
情景4:
客户端A先:
Select * from t where id=3 lock in share mode;
还没commit
客户端B同时:
Select * from t where id=3 lock in share mode;
结果:AB同时进行没有阻塞
原因:A和B都是上的读锁。读锁之间是兼容的,所以即使A还没释放读锁,B可以执行。
不仅是update的时候会上锁,insert和delete的时候也会对这行数据上排它锁。
情景5:行锁退化为表锁
客户端A和B同时begin,表t只有id和name字段,id是主键,name没有设置索引。之后
客户端A:
Select * from t where name=’zhangsan’ lock in share mode;
还没commit
客户端B:
Update t set name=’lisi111’ where name=’lisi’ ;
结果:A执行成功,B阻塞没有执行
原因:我们看到A和B操作的是两条不同的行,但是在innodb中,如果对一条没有用到索引的sql进行上锁,就会从行锁退化成表锁。所以客户端A这里就把整个表都锁住了。
客户端B想上一个写锁,不过由于A把整个表锁住了,所以必须让等A commit了,把锁释放了B才能执行,而且B执行的时候也没用到索引也是上的一个表锁。
有时候我们的sql看上去明明where用了索引,然后加锁发现还是变成了表锁,这是因为你的索引失效。你可以用explain看看他的key字段是否真的用到了索引。
在这里我们顺便再谈谈加锁和索引之间的关系:
我们说加行锁,其实本质上是给索引加锁。假如一个表里面有3个字段:id, name, extra
其中id是主键,name是普通索引。
如果我们执行一条以主键索引为条件语句:
Update x set extra=”xxx” where id > 100 and id <90;
上面使用到了主键索引,此时跑到主键的聚集索引的b+树中把id为90到100的行都锁了起来。然后再改extra字段的值。
如果我们执行一条以普通索引为条件的语句:
Update x set extra = “xxx” where name = “zbp” or name = “zhangsan”;
这里也用到普通索引,而且普通索引没有失效。所以,mysql会先到name这个二级索引的B+树的叶子节点中将name为zbp和zhangsan的元素给锁住。
然后找到叶子节点中zbp和zhangsan对应的id,再跑到聚集索引的B+树中把id对应的行给锁住。
然后再在聚类索引中修改extra字段的值。
也就是说二级索引的记录和主键索引的记录的这2行都被锁住了。
如果我们以非索引的字段为条件,那么行锁变为表锁。
现在我们思考一个问题,假如一个事务A执行 select * from x where id = 1 for update; 因为这里用到了主键作为条件,所以它会锁住主键索引的B+树的id为1的数据。请问,另一个事务B此时执行 select id from x where name=”zbp1”; (假设id为1的数据name就是zbp1),这个事务会阻塞吗。
要注意:select id from x where name=”zbp1”; 用到了覆盖索引,意味着这条sql不会再去查主键索引的B+树了。我的猜测是,A只锁住了主键索引,没有锁住二级索引,所以B应该不会阻塞。
我试了一下,还是阻塞了,看来只用到主键索引作为条件不仅把主键索引给锁住了,还把二级索引也锁住了。
上锁导致快照读变为当前读:
情景6:上锁导致快照读变为当前读
AB同时开启事务 begin; 表t中只有一条记录 (1, ‘zbp’)
客户端A:
Update t set name=’zbp2’ where id=1;
执行了commit
客户端B:
Select * from t;
Select * from t lock in share mode;
结果:B的第一个查询结果是zbp,第二个结果是zbp2
原因:A由于commit了,所以A释放了锁,所以B执行第二个select的时候不会阻塞。为什么两次查询结果不同:因为第一个select 没上锁,是一个快照读,读的是B这个事务内的可见版本而B事务的可见版本中name是zbp,第二个select上了锁,是一个当前读,读的是最新版本的数据,所以是zbp2;
意向锁
什么是意向锁?
意向锁本身是一种表锁,而且是一种不会和行级锁冲突的表锁。Innodb中,(意向)表锁和行锁可以共存。
在innodb中,当mysql要对数据加行锁的时候会先对整个表加一个意向锁,之后才往对应的行加行锁。此时这个表既加了行锁又加了表锁,所以行锁和表锁共存。
意向锁是mysql自动加的,无需我们手动加。
意向锁分为
意向写锁(IX):当需要对数据加行级写锁时,mysql 会先向整个表加意向写锁
意向读锁(IS):当需要对数据加行级读锁时,mysql 会先向整个表加意向读锁
为什么会出现意向锁,它的出现是为了要解决什么问题?
情景7:
有一张users表:MySql,InnoDB,Repeatable-Read:users(id PK,name)
假设有100W条数据
客户端A:
Begin;
Update users set name=’zbp’ where id=10w;
A未提交
客户端B要直接给users表加一个表级的读锁:
Lock tables users read;
假如没有意向锁的存在。那么B想要给表加一个表级别的读锁,B就要判断users表是否已经被其他客户端的事务加了写锁(包括表级写锁和行级写锁)。所以,mysql就会对100W条数据进行一一遍历,直到遍历到第10w条记录的时候mysql发现:哦~,第10W条记录被上了一个写锁,于是B开始阻塞,等待A把写锁释放才上锁。
但是这个一条条遍历的过程很费cpu而且耗时。
为了解决这个情况,mysql可以在客户端A上行级写锁之前先上一个意向写锁(IX)。B要加表级读锁的时候直接发现user表已经被上了一个表级的意向写锁,这个时候B也不用去一个个遍历数据看users是否被锁了,因为意向锁已经明确告诉你users表已经被锁。
所以,意向锁的一个功能就是有种通知的功能,直接告诉其他想上表锁的事务说:这个表已经被行锁给锁定了某些行了,你不能再在上面加一个表锁了哦。
意向锁之间互相兼容

这个很好理解:
例如事务A update 了users表中id为1的数据未提交,事务B update 了id为100的数据。此时users表被上了4把锁:A添加的意向写锁和id=1上的行级写锁、B添加的意向写锁和id=100上的行级写锁
这个过程不会阻塞,就已经说明了事务A加了IX锁之后事务B也能成功上IX锁,否则B就改不了id为100的数据了。
一个事务的意向锁和另外一个事务的行锁兼容
用上面的例子一样可以理解。事务A上的IX锁之后,事务B依旧能够成功的给id为100的行上行锁。
一个事务的意向锁和另一个事务的表锁互斥(但意向读锁和表级读锁不互斥)
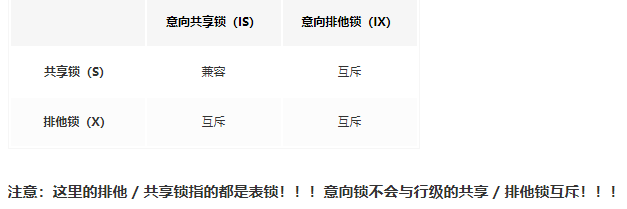
意向锁是innodb支持多粒度锁的体现(支持表锁和行锁共存的体现)
行锁按照算法来分,又可以分为:记录锁(record lock),间隙锁(gap lock)和临键锁(next-key lock)。
间隙锁和临键锁(解决幻读)
首先什么是间隙?
举个例子:有一个innodb表,3个字段,id, name, extra, id是主键,name是普通索引。
+----+-------+-------+
| id | name | extra |
+----+-------+-------+
| 1 | zbp | xxx |
| 3 | zbp3 | xxx |
| 4 | zbp4 | xxx |
| 5 | zbp5 | xxx |
| 6 | zbp6 | xxx |
| 9 | zbp6 | xxx |
| 10 | zbp6 | xxx |
| 12 | zbp12 | xxx |
| 13 | zbp13 | xxx |
| 14 | zbp14 | xxx |
+----+-------+-------+
对于id而言,id不是连续的,这个表的id的间隙有5个,分别是:1之前,1/3之间(缺了个2),6/9之间(缺了个7和8),10/12之间(缺了11)以及14之后。
对于name索引而言,不重复的值之间都是间隙,所以name字段的间隙有9个。
对于extra字段来说,由于extra不是索引字段,所以不存在间隙一说。而且对extra上锁就是一个表锁,表锁把整个表(包括所有行和所有间隙)都锁住了。
什么是间隙锁?
间隙锁其实本质上也是一个行锁。它可以锁住行与行之间的间隙,使得insert无法插入数据到这些间隙中。
什么是临键锁?
临键锁就是记录锁+间隙锁。他不仅能锁住行,还能锁住行之间的间隙,使得insert无法插入数据到这些间隙中。最常见的表现形式就是where使用范围条件的行锁。
情景分析如下:
A、B都执行begin
情景1:
客户端A:
Select * from x where id>1 and id < 4 for update;
A未commit
客户端B:
Insert into x values (2, ‘zbp2’); # 发生阻塞。
# 或者执行 update x set id=2 where name='zbp14'; 也会阻塞
原因:A的where条件不仅把行1,3,4给锁住了,还把1和3之间的间隙给锁住了,此时B就无法插入id为2的数据。
该例子A用到了临键锁
情景2:
客户端A:
Select * from x where id=1 for update;
A未commit
客户端B:
Insert into x values (2, ‘zbp2’); # 正常插入。
# 或者执行 update x set id=2 where name='zbp14'; 修改成功
原因:A只是把行1锁住了,但是没有锁住1和3之间的间隙。如果id不是主键或者唯一键,而只是一个普通索引,此时A的select就会同时把行1本身和(-∞,1)与(1,3)这两个空隙都锁住。这个例子说明当使用主键或者唯一索引使用精确条件(=,in等)命中了一条记录时,临键锁会降级为记录锁。
该例子A用到了记录锁,没能用到临键锁
情景2-2:
客户端A:
Select * from x where id>2 and id<=6;
客户端B:
insert into x values (7,'zbp7','xxx'); # 阻塞
# insert into x values (2, ’zbp2’, ‘xxx’); 也阻塞
原因:A锁住了:(1,3)间隙 和[3,6]之间的4行 和 (6,9) 的间隙。
情景3:
客户端A:
Select * from x where id=7 for update;
A未commit
客户端B:
Insert into x values (7, ‘zbp7’); # 发生阻塞。
# 或者执行 update x set id=7 where name='zbp14'; 也会阻塞
原因:A没有锁住任何的行,但是锁住了行6和行9之间的间隙(没锁住行,只锁住了间隙),此时B就无法插入id为7或者id为8的数据。这里上的是一个间隙锁而不是记录锁,因为where id=7没有命中任何行。
同样的 如果是 Select * from x where id=16 for update; 就会把(14,+无穷大)间隙给锁住,此时B执行 insert into x values (null,”zbp15”,”xxx”) 或者 执行insert into x values (17,”zbp17”,”xxx”)都会被阻塞。
该例子A用到了间隙锁
情景4:
客户端A:
Select * from x where name=’zbp5’ for update;
A未commit
客户端B:
Insert into x values (null, ‘zbp5’); # 发生阻塞。
# 如果是执行:Insert into x values (null, ‘zbp55’); 还是会发生阻塞,因为zbp55也在(zbp5, zbp6)这个间隙之间。
原因:A不仅把zbp5的行给锁住了,也把(zbp4, zbp5) 和 (zbp5, zbp6)这两个间隙给锁住了(和情景2对比,name是个普通索引,所以这里用到的是一个临键锁而没有退化为一个记录锁)。所以B无法插入zbp5和zbp55
该例子用到了临键锁
情景5:
客户端A:
Select * from x where id=5 for update; # id为5的行,它的name字段是zbp5
A未commit
客户端B:
Insert into x values (null, ‘zbp5’); # 插入成功。
# 但是update x set name='zbp55' where name='zbp5'; 会阻塞
原因:这道题我们只要想想底层的B+树就很容易理解。A查的是id为5的行,并且给这个行加锁,也就是给主键索引的B+树中的叶节点的id=5的行元素加行锁,但是B新增数据是往B+树的最后一个叶节点之后((14, +∞)这个间隙)插入一个行元素,而(14, +∞)这个间隙并没有被锁住。再看二级索引的B+树,其实二级索引中name为zbp5的元素已经被锁住,但是zbp5的间隙没有锁,所以插入的数据的name为zbp5也不会阻塞,但是更改name为zbp5的sql阻塞了。
该例子用到了记录锁
情景6:
客户端A:
Select * from x where id>=5 for update; A未commit
客户端B:
Insert into x values (null, ‘zbp5’); # 阻塞。
原因:A把(14, +∞)这个间隙给锁住了,而B新增数据的id肯定是15,在这个区间之中,所以被阻塞了。
该例子用到了临键锁
情景7:不只是select会产生临键锁,update和delete也会
客户端A:
Update x set name=’zbpxxx’ where id>=13 and id<=14;
# 或者 delete from x where id>=13 and id<=14
A未commit
客户端B:
Insert into x values (null, ‘zbp5’); # 阻塞。
原因:A的update或delete把(14, +∞)这个间隙给锁住了,而B新增数据的id肯定是15,所以被阻塞了。
该例子用到了临键锁
情景8:正常情况下,insert不会产生临键锁
客户端A:
insert into x values (7,'zbp7','xxx');
A未commit
客户端B:
insert into x values (8,'zbp8','xxx'); # 未阻塞。
# insert into x values (7,'zbp7','xxx'); 阻塞。
原因:这个例子中A没有锁住(6,9)这个间隙,所以B往这个间隙插入也没有阻塞。不过锁住了id=7的行。
当然,insert虽然没有锁住间隙,但是insert也是会上锁的,当表中有唯一索引的时候,insert插入会上一个共享锁检查我要insert的值是否在表中已经有重复值,检查完后会插入一条数据,并对这条插入的数据上一个行级的X锁。
临键锁在以下两个条件时会降级成为间隙锁或者记录锁:
当查询未命中任务记录时,会降级为间隙锁
当使用主键或者唯一索引的精确条件(in/=)命中了一条记录时,会降级为记录锁。但是如果用普通索引命中一条记录,不会降级为记录锁
情景9: 临键锁降级的场景
客户端A:
update x set name="zbp7" where id=7; # A尝试修改一条不存在的记录,此时where没有命中,因为id=7的记录根本不存在
# 或者执行 delete from x where id=7 删除一条不存在的行
A未提交
客户端B:
insert into x values (8, "zbp8", "xxx"); # 插入数据8,阻塞
原因:id为7的行不存在,所以没有命中这一行就会把(6,9)这个间隙都锁住,所以id=8的数据无法插入
假设现在id=7的记录时存在的,A执行update x set name=“zbp777” where id=7;就会降级为记录锁(因为id是主键,而且这里是一个精确条件而不是范围条件),此时可以插入id为8的记录不会阻塞。
情景10:delete删除一条数据
客户端A:
Delete from x where id=3; # 删除了id=3的行
客户端B:
insert into x values (2, "zbp2", "xxx"); # 不会阻塞
# insert into x values (3, "zbp3", "xxx"); # 阻塞了
原因: 删的是一条存在的记录,而且是用主键精确删除。所以他是一个记录锁,不会锁住(1,4)这个间隙。所以id=2的记录可以插入,而id=3的记录不能插入。
我们可以在一个事务查询的时候加上临键锁来解决幻读问题,它就是通过能够锁住行与行的间隙,使得一个事务在读的时候其他事务无法插入来做到的。
张柏沛IT技术博客 > Mysql事务和锁(三) 事务中的锁