爬虫-Scrapy (十) 搭建ip代理池
每一个爬虫程序员都应该有一个ip池,就像每个战士都应该有一把风剑。
一、找到一个ip代理提供商
提供ip代理的服务商很多,基本都会先提供些不稳定的免费ip,然后引导你消费,我们本次的目标就是把免费的ip抓取下来,验证是否可用,如果可用存入数据库中,作为代理使用。
百度下ip代理,然后随便打开一个,找到免费ip列表
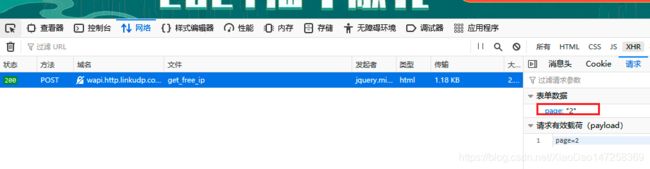
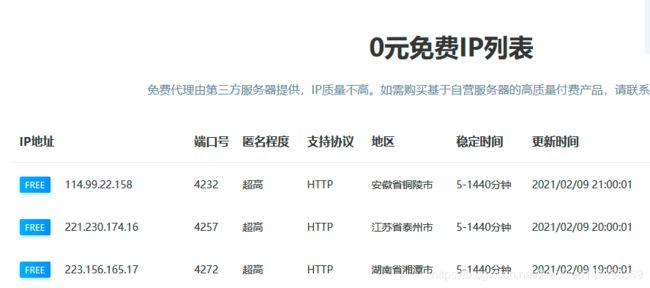 点下翻页,抓下请求方法,可以放下,每次切换页都发送了一个post请求,表达数据page:页码
点下翻页,抓下请求方法,可以放下,每次切换页都发送了一个post请求,表达数据page:页码
 OK,下面我们爬取前5页的ip地址和端口存入库中。
OK,下面我们爬取前5页的ip地址和端口存入库中。
二、抓取ip
创建项目ipPool,创建爬虫pro,然后分析下页面源码结构,很简单,这里就省略了,直接贴代码
proxySpider.py
import scrapy
from scrapy import FormRequest
from ipPool.items import IpPoolItem
class ProxySpider(scrapy.Spider):
name = 'proxySpider'
allowed_domains = ['linkudp.com']
base_url = "http://wapi.http.linkudp.com/index/index/get_free_ip"
def start_requests(self):
for i in range(1,6): #取前5页
yield FormRequest(url=self.base_url, formdata={
'page': str(i)}, callback=self.parse)
def parse(self, response):
tr_list = response.xpath('//table/tr')[1:7] #第一行是标题,第2-7行是数据
for tr in tr_list:
ip = tr.xpath('./td[1]/span/text()').extract_first()
port = tr.xpath('./td[2]/text()').extract_first()
item = IpPoolItem()
item['ip'] = ip
item['port'] = port
print(item)
yield item
运行看下结果
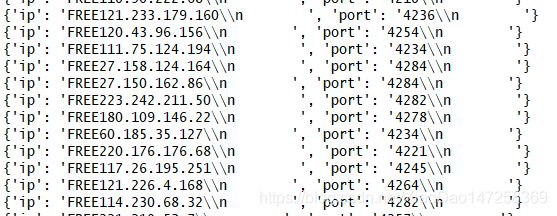
ip 和 port中包含 FREE ,\n 这样非预期的字符,需要用正则表达式处理下
def parse(self, response):
tr_list = response.xpath('//table/tr')[1:7] #第一行是标题,第2-7行是数据
ip_pattern = re.compile(r'\d+\.\d+\.\d+\.\d+') # 简易版IP正则
port_pattern = re.compile(r'\d+') # 简易版port正则
for tr in tr_list:
ip_ori = tr.xpath('./td[1]/span/text()').extract_first()
port_ori = tr.xpath('./td[2]/text()').extract_first()
# 清洗ip 和 port
ip = ip_pattern.findall(str(ip_ori))[0]
port = port_pattern.findall(str(port_ori))[0]
# 存入item
item = IpPoolItem()
item['ip'] = ip
item['port'] = port
print(item)
yield item
再次运行看下效果
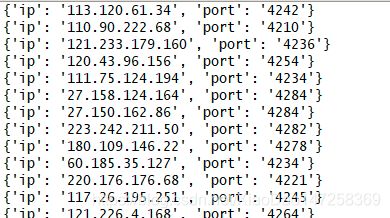
OK,没问题了
三、过滤有效ip
免费代理不能保证有效性和稳定的,所以我们抓取完写个方法验证下,原来就是引用requests 库,用request.get方法将代理传入,超时时间设置为2秒,如果2秒内可以返回预期结果则认为ip有效,否则认为无效。
check_ip 代码
'''
校验ip是否有效
'''
def check_ip(self, ip, port):
url = 'http://icanhazip.com/'
proxy = {
'http':'http://{}:{}'.format(ip, port)}
try:
r = requests.get(url, proxies=proxy, timeout=5)
return r.text==ip
except requests.exceptions.RequestException as e:
return False
修改下parse , 打印下校验结果
def parse(self, response):
tr_list = response.xpath('//table/tr')[1:7] #第一行是标题,第2-7行是数据
ip_pattern = re.compile(r'\d+\.\d+\.\d+\.\d+') # 简易版IP正则
port_pattern = re.compile(r'\d+') # 简易版port正则
for tr in tr_list:
ip_ori = tr.xpath('./td[1]/span/text()').extract_first()
port_ori = tr.xpath('./td[2]/text()').extract_first()
# 清洗ip 和 port
ip = ip_pattern.findall(str(ip_ori))[0]
port = port_pattern.findall(str(port_ori))[0]
# 存入item
item = IpPoolItem()
item['ip'] = ip
item['port'] = port
if self.check_ip(ip, port):
print(ip + ' is valid')
else:
print(ip + ' is not valid')
# print(item)
yield item
看下运行结果,共5页,30个ip
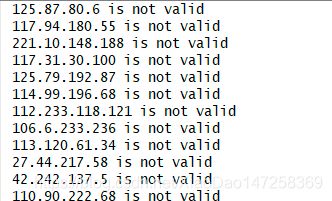
OK,全部都是无效的。
四、入库
因为抓取的免费ip全部都是无效的,就不用写入库了,本篇结束。