python爬取淘宝全部『螺蛳粉』数据,看看你真的了解螺蛳粉吗?
01、前言
上一篇文章(爬取淘宝热卖商品并可视化分析,看看大家都喜欢买什么!)爬取分析了淘宝的热卖商品,从分析来看『螺蛳粉』的销量巨高。因此这篇文章将爬取淘宝全部『螺蛳粉』商品数据,通过可视化分析淘宝螺蛳粉的一些秘密!
前言介绍这些废话就不多啰嗦了,直接开始吧!
02、爬取数据
1.数据来源
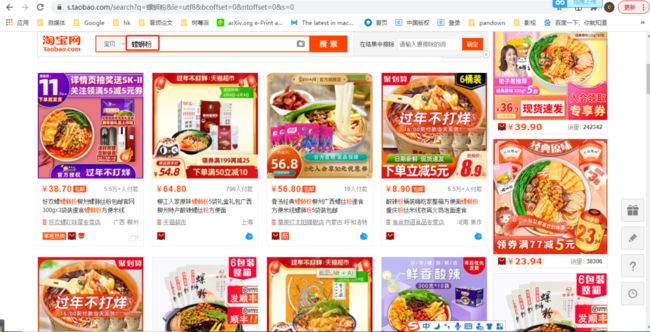
数据来源淘宝,如上图所示,直接在淘宝搜索框搜索“螺蛳粉”,这些就是我们需要爬取的数据。
2.网页分析思路

直接查看网页源代码,可以发现在网页的javascript代码里面包含了商品数据的json数据。
所以可以直接通过requests获取网页源代码,然后借助正则表达式获取这些商品数据。
ok,这样我们的获取数据的思路步骤就很清晰了!
3.编程获取数据
上篇文章我们知道,爬取淘宝数据,有cookie验证(反爬),因此requests中需要添加headers(包含cookie参数)
headers = {
'Host':'s.taobao.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'cookie':'cna=QsEFGOdo0BICARsnWHe+63/1; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; t=effdb32648fc8553a0d1a87926b80343; _m_h5_tk=a94dfbbc27ac02cdbf2cee2a89350b6a_1612614558558; _m_h5_tk_enc=c43b209ec0ed1292bcc622bef5ee6af5; cookie2=1a3fea5ffa0fad17b8c0bbaef21ebb68; _tb_token_=5de15eeea0fbe; xlly_s=1; _samesite_flag_=true; sgcookie=E1007k5qmQ9jBth1shqyTbJtsfmA3xbZNA9skFhamSfqcP7GZBjDZXwyW%2Fnbs39HPqifkG%2FiNiy0TB3VOa4TvxBSyg%3D%3D; unb=913134998; uc3=lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dCuAc6zt7X28yBUrc%3D&id2=WvEIwUQBSki%2F&nk2=rW6iZSg5; csg=4de33d18; lgc=%5Cu897F%5Cu95E8%5Cu5EC9; cookie17=WvEIwUQBSki%2F; dnk=%5Cu897F%5Cu95E8%5Cu5EC9; skt=3fa41897557f2c39; existShop=MTYxMjYwNDU4NA%3D%3D; uc4=nk4=0%40r5%2FGFBQ7A5tJI1TpQam3MZQ%3D&id4=0%40WDb9t1Fxtm4iZCHd0tESONEjEoU%3D; publishItemObj=Ng%3D%3D; tracknick=%5Cu897F%5Cu95E8%5Cu5EC9; _cc_=WqG3DMC9EA%3D%3D; _l_g_=Ug%3D%3D; sg=%E5%BB%898a; _nk_=%5Cu897F%5Cu95E8%5Cu5EC9; cookie1=UUo1TGxcH8cPfpMWT7%2FuMD1anzLFJTzG47%2FnHaFSftY%3D; enc=1xoAdBLlK2BdC0gn79RjfmESRECbfDEgAmzpogjAgEE8dU2FQDF0xFpDq1gxeXD00WiK6XHZ9Wd3C3ltW9vaZw%3D%3D; mt=ci=10_1; uc1=pas=0&cookie15=Vq8l%2BKCLz3%2F65A%3D%3D&cookie21=UtASsssme%2BBq&cookie16=WqG3DMC9UpAPBHGz5QBErFxlCA%3D%3D&existShop=false&cookie14=Uoe1gB38uZ7EFQ%3D%3D; JSESSIONID=7137BBC97E23304D98ADE4E546DB686C; isg=BJ6eJexZctdNAZkZHuCIDdMx7zTgX2LZ0qNVJUgnCuHcaz5FsO-y6cQJZ3fnyFrx; l=eBIj49hqOGMgJqhbBOfanurza77OSIRYYuPzaNbMiOCP9Z5B5f2GW6MUrvY6C3GVh6XXR3yMI8QMBeYBqQAonxv92j-la_kmn; tfstk=c0ifByNUGsffR08N0x9P0RJhfBqOwvI7EgVrhqJE3SL7nW1mfMPBSlefNgULF',
'accept': 'image/avif,image/webp,image/apng,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'upgrade-insecure-requests': '1',
'referer':'https://s.taobao.com/',
}
请求网页内容
url="https://s.taobao.com/search?q=螺蛳粉&ie=utf8&bcoffset=0&ntoffset=0&s=0"
###requests+请求头headers
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
###乱码问题
html = s.decode('utf8')
获取到网页中的javascritp数据中,接着通过正则表达式去提前所需内容(标题、销售地、销售量、评论数、销售价格、商品惟一ID、图片URL)
# 正则模式
p_title = '"raw_title":"(.*?)"' #标题
p_location = '"item_loc":"(.*?)"' #销售地
p_sale = '"view_sales":"(.*?)人付款"' #销售量
p_comment = '"comment_count":"(.*?)"'#评论数
p_price = '"view_price":"(.*?)"' #销售价格
p_nid = '"nid":"(.*?)"' #商品惟一ID
p_img = '"pic_url":"(.*?)"' #图片URL
将正则表达式提取的数据放入到集合data中(方便后面统一保存到csv)
# 数据集合
data = []
# 正则解析
title = re.findall(p_title,html)
location = re.findall(p_location,html)
sale = re.findall(p_sale,html)
comment = re.findall(p_comment,html)
price = re.findall(p_price,html)
nid = re.findall(p_nid,html)
img = re.findall(p_img,html)
for j in range(len(title)):
data.append([title[j],location[j],sale[j],comment[j],price[j],nid[j],img[j]])
![]()
ok,这样我们就完成了从淘宝获取数据的过程,下一步将数据保存到csv中。
4.保存数据到csv
导入python操作csv相关库
import xlrd
import xlwt
from xlutils.copy import copy
追加写入excel
为了方便获取每一页的数据写入excel,这里定义了追加写入excel模板
ef write_excel_xls_append(path, value):
index = len(value) # 获取需要写入数据的行数
workbook = xlrd.open_workbook(path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
new_worksheet.write(i+rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入
new_workbook.save(path) # 保存工作簿
初始化表头
def initexcel():
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('sheet1')
workbook.save('螺蛳粉.xls')
##写入表头
value1 = [["标题", "销售地", "销售量", "评论数", "销售价格", '商品惟一ID', '图片URL']]
book_name_xls = '螺蛳粉.xls'
write_excel_xls_append(book_name_xls, value1)
开始保存
book_name_xls = '螺蛳粉.xls'
write_excel_xls_append(book_name_xls, data)
time.sleep(3)
为了防止禁ip,设置每一页的爬取时间间隔为3秒

通过追加的方式可以将螺蛳粉商品数据保存到excel中!
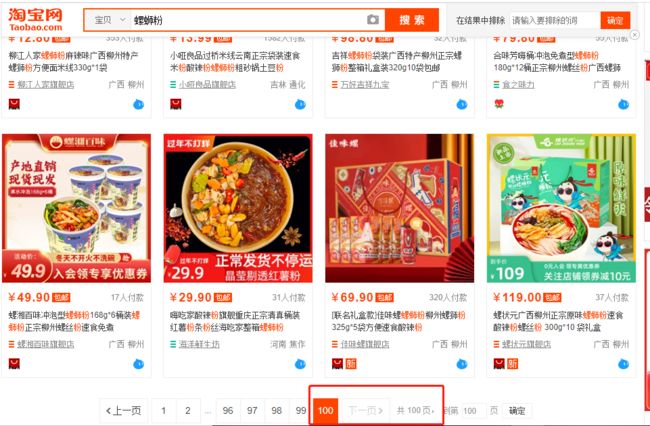
淘宝上的『螺蛳粉』商品一共是100页(每页44条,共100*44条数据)
###请求url
#每页44条 规律:s的跨度为44
# s = 0 44 88 132
for i in range(0,101):
print(i)
url="https://s.taobao.com/search?q=螺蛳粉&ie=utf8&bcoffset=0&ntoffset=0&s="+str(i*44)

ok,这样就爬取了淘宝全部的『螺蛳粉』数据。
03、数据分析
下面分析有一些重复代码(画图的乱码设置、pandas读取csv),为了不多啰嗦,这里先进行声明
# matplotlib中文显示
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 读取数据
# encoding='utf-8',engine='python'
IO = '螺蛳粉.xls'
data = pd.read_excel(io=IO)
分析1:分析价格分布
###分析1:分析价格分布
def analysis1():
# 价格分布
plt.figure(figsize=(16, 9))
plt.hist(data['销售价格'], bins=20, alpha=0.6)
plt.title('价格频率分布直方图')
plt.xlabel('价格')
plt.ylabel('频数')
plt.savefig('价格分布.png')

结论
-
螺蛳粉的价格以50元占大多数,大部分价格在50元范围左右波动。
-
少数螺蛳粉的价格达到250,甚至超过300。(猜测要么是大包销售,要么是明星效应价格)。
-
从整体上来看,螺蛳粉的价格不是很贵,适宜大众消费。
分析2:分析销售地分布
# 销售地分布
group_data = list(data.groupby('销售地'))
loc_num = {}
for i in range(len(group_data)):
loc_num[group_data[i][0]] = len(group_data[i][1])
plt.figure(figsize=(55, 9))
plt.title('销售地')
plt.scatter(list(loc_num.keys())[:20], list(loc_num.values())[:20], color='r')
plt.plot(list(loc_num.keys())[:20], list(loc_num.values())[:20])
plt.savefig('销售地.png')

结论
上图是淘宝售卖『螺蛳粉』店铺的地区分布,取前20个地区进行可视化展示。
sorted_loc_num = sorted(loc_num.items(), key=operator.itemgetter(1), reverse=True) # 排序
loc_num_10 = sorted_loc_num[:10] # 取前10
loc_10 = []
num_10 = []
for i in range(10):
loc_10.append(loc_num_10[i][0])
num_10.append(loc_num_10[i][1])
plt.figure(figsize=(16, 9))
plt.title('销售地TOP10')
plt.bar(loc_10, num_10, facecolor='lightskyblue', edgecolor='white')
plt.savefig('销售地TOP10.png')
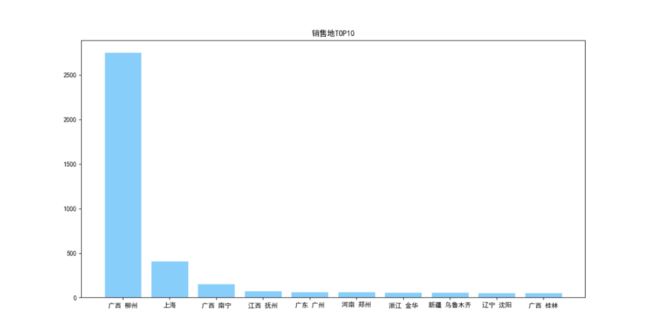
结论
-
在淘宝售卖『螺蛳粉』的店铺中,位于广西-柳州的店铺数量最多,且店铺数量远超于第二名(上海)。(螺蛳粉在广西非常有名,因此第一名是广西无可厚非)。
-
其他的地区的店铺数据都不相伯仲。
分析3:词云分析
###分析3:词云分析
def analysis3():
# 制作词云
content = ''
for i in range(len(data)):
content += data['标题'][i]
wl = jieba.cut(content, cut_all=True)
wl_space_split = ' '.join(wl)
pic = '词云图.png'
gen_stylecloud(text=wl_space_split,
font_path='simsun.ttc',
# icon_name='fas fa-envira',
icon_name='fab fa-qq',
max_words=100,
max_font_size=70,
output_name=pic,
) # 必须加中文字体,否则格式错误

结论
这里将所有商品名称制作词云图,目的是可以看商品标题关键字最多的词是什么。(哪些关键字容易吸引用户)
关键词:螺蛳粉、酸辣粉、广西、包邮,特长,方便面
分析4:商品价格对销量的影响分析
###分析4:线性回归分析
def analysis4():
datas = data
datas = datas.dropna(axis=0, how='any')
x = datas['销售量']
y = datas['销售价格']
x = x.tolist()
y = y.tolist()
for i in range(0, len(x)):
j = x[i]
if "+" in j:
j = j.replace("+", "")
if "万" in j:
j = j.replace("万", "")
j = float(j) * 10000
x[i] = str(j)
flg, ax = plt.subplots()
ax.scatter(x,y, alpha=0.5,edgecolors= 'white')
ax.set_xlabel('销量')
ax.set_ylabel('价格')
ax.set_title('商品价格对销量的影响')
#隐藏刻度线和标签
ax.set_xticks([])
#plt.show()
plt.savefig('商品价格对销量的影响.png')
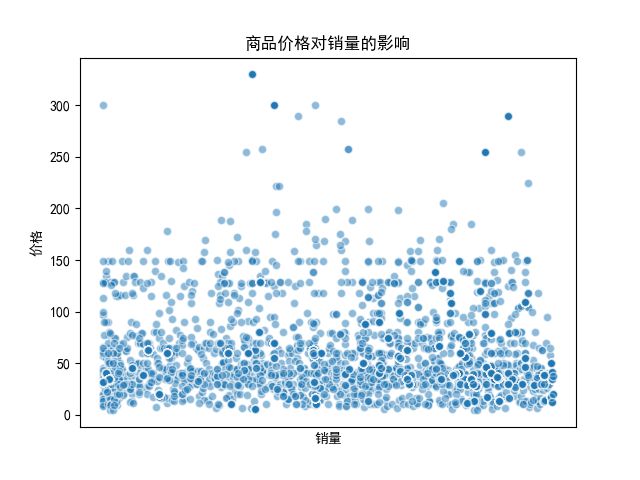
结论
-
总体趋势:随着商品价格增多,其销量有所减少,商品价格对其销量有影响的;
-
价格在30-60之间的商品销量比较集中。
04、总结
以上内容就是淘宝全部『螺蛳粉』商品数据的爬取、分析、可视化过程!
如果大家对本文代码源码感兴趣,扫码关注『Python爬虫数据分析挖掘』后台回复:螺蛳粉 ,获取完整代码。
【各种开源源码获取方式】
识别文末二维码,回复:开源源码
------------- 推荐文章 -------------
1、爬取淘宝热卖商品并可视化分析,看看大家都喜欢买什么!
2、详细实战教程!部署Flask网站+域名访问+免费https证书
3、王者荣耀白晶晶皮肤1小时销量突破千万!分析网友评论我发现了原因
4、基金这么赚钱!!编程实现基金从采集到分析通用模板!(白酒为例)
