搭建伪分布式集群笔记(2)
搭建Hadoop分布式集群一
条件
hadoop-2.6.0.tar.gz
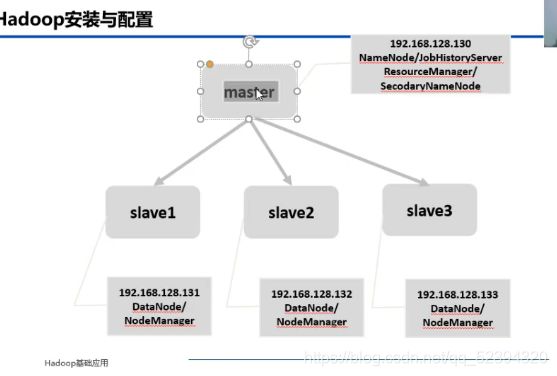
结构图
步骤:
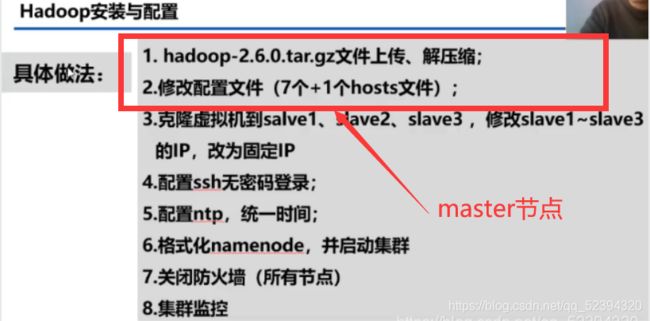
1.Hadoop文件上传,解压缩
上传 hadoop-2.6.0.tar.gz 到/opt目录下

解压到/usr/local目录下
tar -zxf hadoop-2.6.0.tar.gz -C /usr/local

一些常用的目录解读

2.修改配置文件

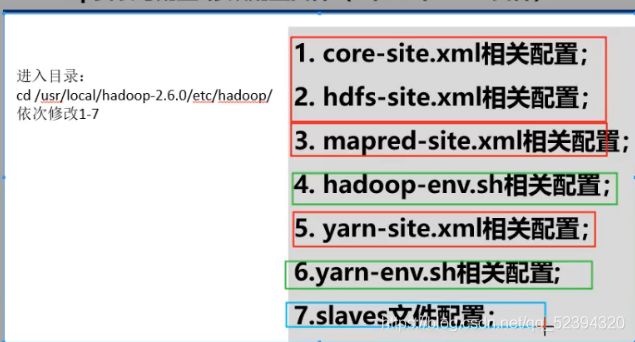
cd /usr/local/hadoop-2.6.0/etc/hadoop
- core-site.xml
fs.defaultFS
hdfs://master:8020
hadoop.tmp.dir
/var/log/hadoop/tmp
- hdfs-site.xml
dfs.namenode.name.dir
file:///data/hadoop/hdfs/name
dfs.datanode.data.dir
file:///data/hadoop/hdfs/data
dfs.namenode.secondary.http-address
master:50090
dfs.replication
3
- mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
- hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
- yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.local-dirs
/data/hadoop/yarn/local
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/data/tmp/logs
yarn.log.server.url
http://master:19888/jobhistory/logs/
URL for job history server
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.resource.memory-mb
2048
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
4096
mapreduce.map.memory.mb
2048
mapreduce.reduce.memory.mb
2048
yarn.nodemanager.resource.cpu-vcores
1
- yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
- slaves
删除localhost,添加:
slave1
slave2
slave3
3.设置IP映射
vim /etc/hosts
添加
192.168.128.130 master master.centos.com
192.168.128.131 slave1 slave1.centos.com
192.168.128.132 slave2 slave2.centos.com
192.168.128.133 slave3 slave3.centos.com
4.克隆slave等三台主机
克隆slave1,slave2,slave3
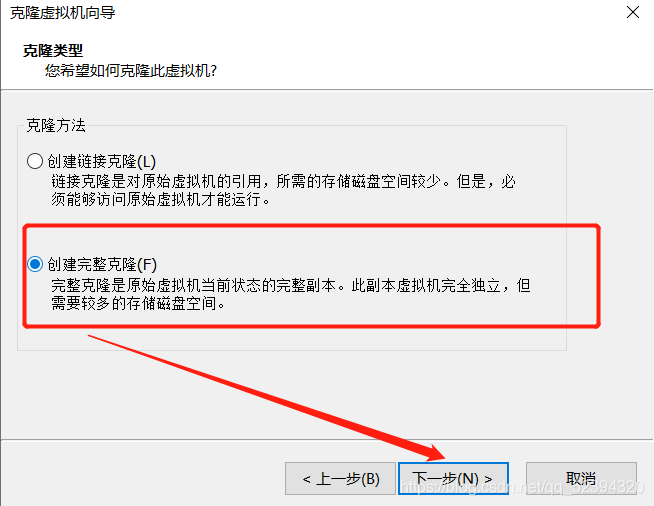

同样克隆出slave2和slave3
更改三台主机的设置
如slave1:
(1)删除文件
rm -rf /etc/udev/rules.d/70-persistent-net.rules
(2)记住值(机器不同,值不同)

(3)更改主机ip
cd /etc/sysconfig/network-scripts/
vim ifcfg-eth0

看是否成功Ping 通
service network restart
ping www.baidu.com
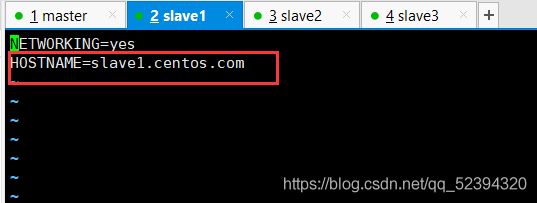
(4)修改机器名
vim /etc/sysconfig/network
(5)重启虚拟机
reboot
(6)在master验证
ping slave1
克隆虚拟机,如果在配置前已提前克隆,则需拷贝hadoop安装文件到集群slave节点
scp -r /usr/local/hadoop-2.6.0 slave1:/usr/local
scp -r /usr/local/hadoop-2.6.0 slave2:/usr/local
scp -r /usr/local/hadoop-2.6.0 slave3:/usr/local
5.配置SSH无密码登录
(1)使用ssh-keygen产生公钥与私钥对。
输入命令“ssh-keygen -t rsa”,接着按三次Enter键
[root@master ~]# ssh-keygen -t rsa
生成私有密钥id_rsa和公有密钥id_rsa.pub两个文件
(2)用ssh-copy-id将公钥复制到远程机器中
ssh-copy-id -i /root/.ssh/id_rsa.pub master//依次输入yes,123456(root用户的密码)
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
ssh-copy-id -i /root/.ssh/id_rsa.pub slave2
ssh-copy-id -i /root/.ssh/id_rsa.pub slave3
(3)验证是否设置无密码登录
依次输入
ssh slave1
ssh slave2
ssh slave3
参考书籍
《教材-Hadoop大数据开发基础》 ----人民邮电出版社