使用python通过随机森林实现人脸识别
一、需要了解的知识
1.Bootstrap方法
2.集成学习
3.Bagging
4.Boosting 算法
5.随机森林算法
1.BootStrap方法
我觉得BootStrap是一个有趣的名字,因为他在英语的翻译为鞋带,来自短语:“pull oneself up by one′s bootstrap”,18世纪德国文学家拉斯伯(Rudolf Erich Raspe)的小说《巴龙历险记(或译为终极天将)》(Adventures of Baron Munchausen) 记述道:“巴龙掉到湖里沉到湖底,在他绝望的时候,他用自己靴子上的带子把自己拉了上来。”现意指不借助别人的力量,凭自己的努力,终于获得成功。在这里“bootstrap”法是指用原样本自身的数据抽样得出新的样本及统计量,根据其意现在普遍将其译为“自助法”。
BootStrap的基本思想就是在原始数据的范围内作有放回的再抽样, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本。于是可得到参数θ的一个估计值θ^(b),这样重复若干次,记为B 。
详细请看 https://blog.csdn.net/baimafujinji/article/details/50554664
2.集成学习
假如我们有三个一定差异的分类器,为了得到一个更合理准确的分类器,我们将下面的三个弱分类器通过结合策略Σ来组合成一个强的分类器,从而实现更好的效果。

详细请看 https://www.cnblogs.com/pinard/p/6131423.html
3.Bagging
Bagging是集成学习的一种基本算法,Bagging即从样本集中用BoostStrap采样选出n个训练样本,在所有属性上,用这n个样本训练分类器,重复以上两步m次,就可以得到m个分类器,然后将数据集放在m个分类器上进行分类,最后通过投票机制来决定到底属于哪一类。
详细请看 https://blog.csdn.net/leadai/article/details/79907417
4.Boosting 算法
Boosting 算法更多的是关注被分类错误的样本,首先给每一个训练样例赋予同样的权值,然后构造一个弱分类器,对于那些错误的样例提高权重,然后通过调整过权重的训练集去训练第二个分类器,重复执行以上步骤,最终得到一个效果较好的分类器。
5.决策树
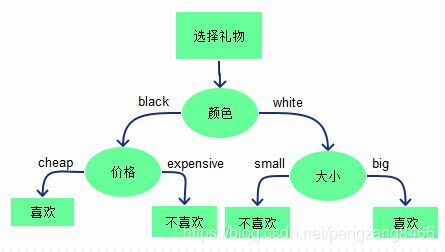
图片来源cococo博客,
决策树又称为判定树,是运用于分类的一种树结构,其中的每个内部节点代表对某一属性的一次测试,每条边代表一个测试结果,叶节点代表某个类或类的分布。
决策树的决策过程需要从决策树的根节点开始,待测数据与决策树中的特征节点进行比较,并按照比较结果选择选择下一比较分支,直到叶子节点作为最终的决策结果。



def get_picture():
label = 1
# 读取所有图片并一维化
while (label <= 20):
for name in glob.glob(PICTURE_PATH + "\\s" + str(label) + "\\*.pgm"):
img = Image.open(name)
# img.getdata()
# np.array(img).reshape(1, 92*112)
all_data_set.append(list(img.getdata()))
all_data_label.append(label)
label += 1
get_picture()

n_components = 16
pca = PCA(n_components=n_components, svd_solver='auto',
whiten=True).fit(all_data_set)
# PCA降维后的总数据集
all_data_pca = pca.transform(all_data_set)
# X为降维后的数据,y是对应类标签
X = np.array(all_data_pca)
y = np.array(all_data_label)
n_estimators = [10,11,12,13,14,15,16,17,18,19,20]
criterion_test_names = ["gini", "entropy"]
![]()
def RandomForest(n_estimators,criterion):
# 十折交叉验证计算出平均准确率
# 交叉验证,随机取
kf = KFold(n_splits=10, shuffle=True)
precision_average = 0.0
# param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5]} # 自动穷举出最优的C参数
# clf = GridSearchCV(SVC(kernel=kernel_name, class_weight='balanced', gamma=param),
# param_grid)
parameter_space = {
"min_samples_leaf": [2, 4, 6],
}
clf = GridSearchCV(RandomForestClassifier(random_state=14,n_estimators = n_estimators,criterion = criterion), parameter_space, cv=5)
for train, test in kf.split(X):
clf = clf.fit(X[train], y[train])
# print(clf.best_estimator_)
test_pred = clf.predict(X[test])
# print classification_report(y[test], test_pred)
# 计算平均准确率
precision = 0
for i in range(0, len(y[test])):
if (y[test][i] == test_pred[i]):
precision = precision + 1
precision_average = precision_average + float(precision) / len(y[test])
precision_average = precision_average / 10
# print (u"准确率为" + str(precision_average))
return precision_average
![]()
for criterion in criterion_test_names:
x_label = []
y_label = []
for i in n_estimators:
y_label.append(RandomForest(i,criterion))
x_label.append(i)
plt.plot(x_label, y_label, label=criterion)
# print("done in %0.3fs" % (time() - t0))
plt.xlabel("criterion")
plt.ylabel("Precision")
plt.title('Different Contrust')
plt.legend()
plt.show()
全部代码如下
# -*- coding: utf-8 -*-
from time import time
from PIL import Image
import glob
import numpy as np
import sys
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
# 设置解释器为utf8编码,不知为何文件开头的注释没用。
# 尽管这样设置,在IPython下仍然会出错,只能用原装Python解释器执行本程序
# reload(sys)
# sys.setdefaultencoding("utf8")
# print sys.getdefaultencoding()
PICTURE_PATH = u"C:\\Users\\zhangliang\\Desktop\\att_faces"
all_data_set = [] # 原始总数据集,二维矩阵n*m,n个样例,m个属性
all_data_label = [] # 总数据对应的类标签
def get_picture():
label = 1
# 读取所有图片并一维化
while (label <= 20):
for name in glob.glob(PICTURE_PATH + "\\s" + str(label) + "\\*.pgm"):
img = Image.open(name)
# img.getdata()
# np.array(img).reshape(1, 92*112)
all_data_set.append(list(img.getdata()))
all_data_label.append(label)
label += 1
get_picture()
n_components = 16
pca = PCA(n_components=n_components, svd_solver='auto',
whiten=True).fit(all_data_set)
# PCA降维后的总数据集
all_data_pca = pca.transform(all_data_set)
# X为降维后的数据,y是对应类标签
X = np.array(all_data_pca)
y = np.array(all_data_label)
n_estimators = [10,11,12,13,14,15,16,17,18,19,20]
criterion_test_names = ["gini", "entropy"]
# 输入核函数名称和参数gamma值,返回SVM训练十折交叉验证的准确率
def RandomForest(n_estimators,criterion):
# 十折交叉验证计算出平均准确率
# 交叉验证,随机取
kf = KFold(n_splits=10, shuffle=True)
precision_average = 0.0
# param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5]} # 自动穷举出最优的C参数
# clf = GridSearchCV(SVC(kernel=kernel_name, class_weight='balanced', gamma=param),
# param_grid)
parameter_space = {
"min_samples_leaf": [2, 4, 6],
}
clf = GridSearchCV(RandomForestClassifier(random_state=14,n_estimators = n_estimators,criterion = criterion), parameter_space, cv=5)
for train, test in kf.split(X):
clf = clf.fit(X[train], y[train])
# print(clf.best_estimator_)
test_pred = clf.predict(X[test])
# print classification_report(y[test], test_pred)
# 计算平均准确率
precision = 0
for i in range(0, len(y[test])):
if (y[test][i] == test_pred[i]):
precision = precision + 1
precision_average = precision_average + float(precision) / len(y[test])
precision_average = precision_average / 10
# print (u"准确率为" + str(precision_average))
return precision_average
#print("precision_average : ",RandomForest())
# t0 = time()
#kernel_to_test = ['rbf', 'poly', 'sigmoid']
# # rint SVM(kernel_to_test[0], 0.1)
# plt.figure(1)
#
for criterion in criterion_test_names:
x_label = []
y_label = []
for i in n_estimators:
y_label.append(RandomForest(i,criterion))
x_label.append(i)
plt.plot(x_label, y_label, label=criterion)
# print("done in %0.3fs" % (time() - t0))
plt.xlabel("criterion")
plt.ylabel("Precision")
plt.title('Different Contrust')
plt.legend()
plt.show()