计算机视觉(三)——人脸识别
文章目录
- 一、人脸检测
-
- 1.OpenCV+深度学习人脸检测
- 2.Haar cascades人脸检测
- 3.HOG + Linear SVM人脸检测
- 4.人脸面部特征检测
-
- (1)基于dlib的面部特征检测
- (2)基于dlib的面部特征检测进阶
- (3)基于dlib的快速面部特征检测
- 5.人脸检测的应用
-
- (1)眨眼检测
- (2)困意检测
- 二、人脸识别
-
- 1.人脸识别基础
-
- (1)编码网络
- (2)训练网络
- 2.人脸识别进阶
-
- (1)特征抽取
- (2)模型训练
- (3)预测新图片
- 3.人脸校准
- 4.活体检测
计算机视觉在人脸方向的应用主要为人脸识别,对于人脸识别问题,首先需要进行人脸检测定位到人脸的位置,之后再进行识别。
人脸识别需要用到的重要库包括OpenCV、dlib和face_recognition。dlib库主要是用于构建人脸向量,而face_recognition库是在dlib基础之上的第三方库,使程序变得更简单。安装方法很简单
pip install dlib
pip install face_recognition
一、人脸检测
在进行人脸识别之前,我们首先需要找到一张图片中人脸的位置,人脸检测算法不需要知道这个人脸是谁,只需要定位到人脸即可。人脸检测的方法有很多种,例如基于OpenCV和深度学习的人脸检测,基于HOG和Linear SVM的人脸检测等等,一个小建议是:
- 追求准确率,使用OpenCV+深度学习算法
- 追求速度,使用Haar cascades
- 同时考虑两者,使用HOG + Linear SVM
1.OpenCV+深度学习人脸检测
原文链接
OpenCV+深度学习框架是基于SSD模型(基于ResNet),在OpenCV中有一个dnn模块,里面包含了很多和神经网络相关的库。本模型是基于caffe,需要提前定义网络结构的文件和每层网络权重的文件
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
加载必要的库,命令行参数设置可能输入的参数,confidence表示筛掉可能性低的检测的阈值
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# load the input image and construct an input blob for the image
# by resizing to a fixed 300x300 pixels and then normalizing it
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
首先加载所需的caffe模型以及参数,之后读入文件并利用dnn.blobFromImage进行一定预处理。
# pass the blob through the network and obtain the detections and
# predictions
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for the
# object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the bounding box of the face along with the associated
# probability
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
将输入送入网络,得到可能的输出,之后不断循环输出的检测结果,当概率大于阈值时输出框的位置
2.Haar cascades人脸检测
原文链接
OpenCV的 haarcascades 目录中存储了很多预训练Haar分类器来检测多种多样的物体。,其中有两个文件可以检测猫的脸:
- haarcascade_frontalcatface.xml
- haarcascade_frontalcatface_extended.xml
# import the necessary packages
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-c", "--cascade",
default="haarcascade_frontalcatface.xml",
help="path to cat detector haar cascade")
args = vars(ap.parse_args())
导入库及设定参数,cascade参数即上述两个文件
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# load the cat detector Haar cascade, then detect cat faces
# in the input image
detector = cv2.CascadeClassifier(args["cascade"])
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
minNeighbors=10, minSize=(75, 75))
导入文件及 Haar 分类器及其设定参数并输出结果,四个参数分别是图像文件;图像金字塔缩放比例;给定区域边界框的最小数目;框的最小长宽
# loop over the cat faces and draw a rectangle surrounding each
for (i, (x, y, w, h)) in enumerate(rects):
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
# show the detected cat faces
cv2.imshow("Cat Faces", image)
cv2.waitKey(0)
输出结果
这种方法最大的问题是如何设置 detectMultiScale 里的参数,尤其是第二个和第三个,scaleFactor 参数设置的过大会导致检测的信息过少,而该参数过小会导致耗时很长。
3.HOG + Linear SVM人脸检测
原文链接
使用HOG + Linear SVM进行人脸检测的步骤如下:
- 从训练集中采样P个正样本。寻找并抽取这些样本的Hog描述
- 从训练集中采样N个负样本(不包含任何想要检测的物体)。寻找并抽取这些样本的Hog描述。通常N远大于P
- 对于正样本和负样本训练一个线性SVM
- 应用hard-negative mining:对负样本中每张图片及每张图片可能的范围,使用滑动窗口技术在整张图片上滑动,对于得到的每个窗口抽取Hog特征送入训练好的分类器,如果分类器误分类为包含想要的物体,记录该样本的特征向量。
- 将所有误分类的样本的特征向量按照概率分类并用这些样本重新训练分类器
- 将训练好的分类器应用到测试集,在得到所有的可能框之后应用非极大值抑制得到最终的结果。
4.人脸面部特征检测
检测人脸面部特征是形状预测问题的一个分支,检测面部特征主要包括两个步骤:
- 定位图片中的人脸
- 在脸部区域检测关键面部特征
定位人脸的方法上节介绍过,面部特征检测器有很多,但它们主要都用于检测嘴、左右眉毛、左右眼睛、鼻子和下巴。
(1)基于dlib的面部特征检测
原文链接
dlib的预训练面部特征检测器的原理是估计匹配面部特征的68个坐标点的位置

这68个坐标点是基于 iBUG 300-W dataset训练的,使用其他的数据会有不同的坐标点数量。代码如下:
def rect_to_bb(rect):
# take a bounding predicted by dlib and convert it
# to the format (x, y, w, h) as we would normally do
# with OpenCV
x = rect.left()
y = rect.top()
w = rect.right() - x
h = rect.bottom() - y
# return a tuple of (x, y, w, h)
return (x, y, w, h)
工具函数,给定输入为dlib检测器产生的矩形框,输出为边界框的左上角x,y以及宽和高
def shape_to_np(shape, dtype="int"):
# initialize the list of (x, y)-coordinates
coords = np.zeros((68, 2), dtype=dtype)
# loop over the 68 facial landmarks and convert them
# to a 2-tuple of (x, y)-coordinates
for i in range(0, 68):
coords[i] = (shape.part(i).x, shape.part(i).y)
# return the list of (x, y)-coordinates
return coords
工具函数,输入为dlib检测器产生的shape对象,输出为68个点坐标
import numpy as np
import argparse
import imutils
import dlib
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
# load the input image, resize it, and convert it to grayscale
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale image
rects = detector(gray, 1)
# loop over the face detections
for (i, rect) in enumerate(rects):
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# convert dlib's rectangle to a OpenCV-style bounding box
# [i.e., (x, y, w, h)], then draw the face bounding box
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the face number
cv2.putText(image, "Face #{}".format(i + 1), (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw them on the image
for (x, y) in shape:
cv2.circle(image, (x, y), 1, (0, 0, 255), -1)
# show the output image with the face detections + facial landmarks
cv2.imshow("Output", image)
cv2.waitKey(0)
首先导入库和设定命令行参数,需要有一个预训练的面部特征检测器。
之后初始化一个人脸定位器和面部特征检测器
然后定位人脸位置,得到边界框
最后循环遍历得到的边界框并检测脸部特征并输出,输出68个坐标点位置

(2)基于dlib的面部特征检测进阶
原文链接
本节在上一小节的基础上进一步标定并抽取特征
根据上一小节得到的68个特征点,我们可以得到脸部特征的区域,具体对应为
嘴——[48,68];右眉毛——[17,22];左眉毛——[22,27],右眼——[34,42];左眼——[42,48];鼻子——[27,35];下巴——[0,17]。基于这些可以画出不同器官的区域。
# define a dictionary that maps the indexes of the facial
# landmarks to specific face regions
FACIAL_LANDMARKS_IDXS = OrderedDict([
("mouth", (48, 68)),
("right_eyebrow", (17, 22)),
("left_eyebrow", (22, 27)),
("right_eye", (36, 42)),
("left_eye", (42, 48)),
("nose", (27, 35)),
("jaw", (0, 17))
])
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):
# create two copies of the input image -- one for the
# overlay and one for the final output image
overlay = image.copy()
output = image.copy()
# if the colors list is None, initialize it with a unique
# color for each facial landmark region
if colors is None:
colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),
(168, 100, 168), (158, 163, 32),
(163, 38, 32), (180, 42, 220)]
# loop over the facial landmark regions individually
for (i, name) in enumerate(FACIAL_LANDMARKS_IDXS.keys()):
# grab the (x, y)-coordinates associated with the
# face landmark
(j, k) = FACIAL_LANDMARKS_IDXS[name]
pts = shape[j:k]
# check if are supposed to draw the jawline
if name == "jaw":
# since the jawline is a non-enclosed facial region,
# just draw lines between the (x, y)-coordinates
for l in range(1, len(pts)):
ptA = tuple(pts[l - 1])
ptB = tuple(pts[l])
cv2.line(overlay, ptA, ptB, colors[i], 2)
# otherwise, compute the convex hull of the facial
# landmark coordinates points and display it
else:
hull = cv2.convexHull(pts)
cv2.drawContours(overlay, [hull], -1, colors[i], -1)
# apply the transparent overlay
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
# return the output image
return output
需要注意的是,由于下巴不是一个区域,所以要单独拿出来画线,得到的结果如图:

(3)基于dlib的快速面部特征检测
原文链接
dlib中有包含仅5个点的面部特征检测器,这五个点对应的位置分别是:两个点对应左眼,两个点对应右眼,一个点对应鼻子。
相比于之前的68个点检测器,5点检测器在速度上略有提升,但在模型大小上有显著的提升。在代码上的区别主要是预训练的文件不同,其余都类似。
5.人脸检测的应用
(1)眨眼检测
原文链接
通过上文介绍的面部特征检测,我们可以对视频中的人是否眨眼进行检测。由上文可知,眼部位置有6个特征点组成,如下图

因此,我们定义一个公式 eye aspect ratio (EAR)

公式的分子计算的垂直方向距离,分母计算的水平方向距离,通过这个公式,我们可以知道当眼睛睁开的时候,EAR趋向于一个常数,而当眼睛闭上时候,这个值会变成0。下面是关于视频识别眨眼的实战:
from scipy.spatial import distance as dist
from imutils.video import FileVideoStream
from imutils.video import VideoStream
from imutils import face_utils
import numpy as np
import argparse
import imutils
import time
import dlib
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-v", "--video", type=str, default="",
help="path to input video file")
args = vars(ap.parse_args())
def eye_aspect_ratio(eye):
# compute the euclidean distances between the two sets of
# vertical eye landmarks (x, y)-coordinates
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
# compute the euclidean distance between the horizontal
# eye landmark (x, y)-coordinates
C = dist.euclidean(eye[0], eye[3])
# compute the eye aspect ratio
ear = (A + B) / (2.0 * C)
# return the eye aspect ratio
return ear
定义EAR函数
# define two constants, one for the eye aspect ratio to indicate
# blink and then a second constant for the number of consecutive
# frames the eye must be below the threshold
EYE_AR_THRESH = 0.3
EYE_AR_CONSEC_FRAMES = 3
# initialize the frame counters and the total number of blinks
COUNTER = 0
TOTAL = 0
第一个参数定义EAR函数闭眼的阈值,第二个参数是确保阈值小于0.3要在连续三个帧以内,第三个参数记录了连续小于0.3帧的个数,第四个记录眨眼的次数
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
# grab the indexes of the facial landmarks for the left and
# right eye, respectively
FACIAL_LANDMARKS_IDXS = OrderedDict([
("mouth", (48, 68)),
("right_eyebrow", (17, 22)),
("left_eyebrow", (22, 27)),
("right_eye", (36, 42)),
("left_eye", (42, 48)),
("nose", (27, 35)),
("jaw", (0, 17))
])
(lStart, lEnd) = FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = FACIAL_LANDMARKS_IDXS["right_eye"
获取眼睛的关键点
# start the video stream thread
print("[INFO] starting video stream thread...")
vs = FileVideoStream(args["video"]).start()
fileStream = True
# vs = VideoStream(src=0).start()
# vs = VideoStream(usePiCamera=True).start()
# fileStream = False
time.sleep(1.0)
# loop over frames from the video stream
while True:
# if this is a file video stream, then we need to check if
# there any more frames left in the buffer to process
if fileStream and not vs.more():
break
# grab the frame from the threaded video file stream, resize
# it, and convert it to grayscale
# channels)
frame = vs.read()
frame = imutils.resize(frame, width=450)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
rects = detector(gray, 0)
# loop over the face detections
for rect in rects:
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# extract the left and right eye coordinates, then use the
# coordinates to compute the eye aspect ratio for both eyes
leftEye = shape[lStart:lEnd]
rightEye = shape[rStart:rEnd]
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
# average the eye aspect ratio together for both eyes
ear = (leftEAR + rightEAR) / 2.0
# compute the convex hull for the left and right eye, then
# visualize each of the eyes
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
# check to see if the eye aspect ratio is below the blink
# threshold, and if so, increment the blink frame counter
if ear < EYE_AR_THRESH:
COUNTER += 1
# otherwise, the eye aspect ratio is not below the blink
# threshold
else:
# if the eyes were closed for a sufficient number of
# then increment the total number of blinks
if COUNTER >= EYE_AR_CONSEC_FRAMES:
TOTAL += 1
# reset the eye frame counter
COUNTER = 0
# draw the total number of blinks on the frame along with
# the computed eye aspect ratio for the frame
cv2.putText(frame, "Blinks: {}".format(TOTAL), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "EAR: {:.2f}".format(ear), (300, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
这段代码首先读入视频文件获取每一个关键帧,在每一帧上计算左眼和右眼的EAR,之后有一个可供选择的可视化过程,之后用之前定义的两个变量记录阈值小于0.3的次数,小于3则算一次眨眼直到视频播放完成。
(2)困意检测
原文链接
困意检测的原理和眨眼检测类似,两者的区别是眨眼检测判断EAR的值在很短时间内从常数变为0再变成常数,而困意检测则是判断EAR是否在某一段时间内均低于阈值,其余相同。
二、人脸识别
1.人脸识别基础
原文链接
人脸识别中,首先有一个概念叫做深度度量学习(deep metric learning)。在深度度量学习中,输入是一张图片,输出是一个实数特征向量。对于dlib人脸识别网络,输出的是一个128维向量。
我们使用三元组(triplets)来训练网络,具体原理是我们输入三张图片进入网络,其中两张图片代表着同一个人脸,第三张图片是数据集中一张随机的另一个人的人脸。之后网络会对每张图片构建一个128维向量,我们要做的是尽可能调整神经网络的参数使得两张同样人脸的129维特征向量尽可能相近,和不同的人脸向量尽可能远。
这一小节使用简单的knn算法对人脸进行识别
(1)编码网络
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
加载必要的库以及命令行参数
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the list of known encodings and known names
knownEncodings = []
knownNames = []
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the input image and convert it from BGR (OpenCV ordering)
# to dlib ordering (RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# detect the (x, y)-coordinates of the bounding boxes
# corresponding to each face in the input image
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
# compute the facial embedding for the face
encodings = face_recognition.face_encodings(rgb, boxes)
# loop over the encodings
for encoding in encodings:
# add each encoding + name to our set of known names and
# encodings
knownEncodings.append(encoding)
knownNames.append(name)
# dump the facial encodings + names to disk
print("[INFO] serializing encodings...")
data = {
"encodings": knownEncodings, "names": knownNames}
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
上述代码中,face_recognition.face_locations用于定位人脸,face_recognition.face_encodings用于生成人脸的128维向量
(2)训练网络
# import the necessary packages
import face_recognition
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
加载必要库和命令行参数
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
# load the input image and convert it from BGR to RGB
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# detect the (x, y)-coordinates of the bounding boxes corresponding
# to each face in the input image, then compute the facial embeddings
# for each face
print("[INFO] recognizing faces...")
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
encodings = face_recognition.face_encodings(rgb, boxes)
# initialize the list of names for each face detected
names = []
读入测试用的图片,定位人脸并转换成128维向量
# loop over the facial embeddings
for encoding in encodings:
# attempt to match each face in the input image to our known
# encodings
matches = face_recognition.compare_faces(data["encodings"],
encoding)
name = "Unknown"
# check to see if we have found a match
if True in matches:
# find the indexes of all matched faces then initialize a
# dictionary to count the total number of times each face
# was matched
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {
}
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# determine the recognized face with the largest number of
# votes (note: in the event of an unlikely tie Python will
# select first entry in the dictionary)
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
# loop over the recognized faces
for ((top, right, bottom, left), name) in zip(boxes, names):
# draw the predicted face name on the image
cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(image, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
对于图片中的每个人脸,我们都使用face_recognition.compare_faces函数将其与之前得到的已知人脸向量集进行比较,将满足条件的已知人脸进行比较最后输出匹配次数最多的人脸作为结果。
2.人脸识别进阶
原文地址
上一小节中的人脸识别算法存在的一个问题是它利用了KNN的思想来寻找最匹配的人脸,KNN算法虽然简单,但是容易犯错,因此可以采用一些机器学习方法来进行人脸识别,本小节通过 dlib+OpenCV来进行算法设计
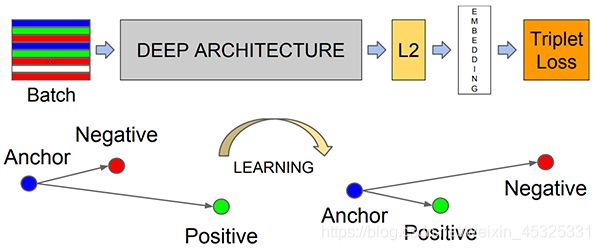
(1)特征抽取
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--embeddings", required=True,
help="path to output serialized db of facial embeddings")
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load our serialized face embedding model from disk
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
detector ,embedder 分别定义了人脸检测器和特征抽取器
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize our lists of extracted facial embeddings and
# corresponding people names
knownEmbeddings = []
knownNames = []
# initialize the total number of faces processed
total = 0
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the image, resize it to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image
# dimensions
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(image, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# apply OpenCV's deep learning-based face detector to localize
# faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
# ensure at least one face was found
if len(detections) > 0:
# we're making the assumption that each image has only ONE
# face, so find the bounding box with the largest probability
i = np.argmax(detections[0, 0, :, 2])
confidence = detections[0, 0, i, 2]
# ensure that the detection with the largest probability also
# means our minimum probability test (thus helping filter out
# weak detections)
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI and grab the ROI dimensions
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# add the name of the person + corresponding face
# embedding to their respective lists
knownNames.append(name)
knownEmbeddings.append(vec.flatten())
total += 1
# dump the facial embeddings + names to disk
print("[INFO] serializing {} encodings...".format(total))
data = {
"embeddings": knownEmbeddings, "names": knownNames}
f = open(args["embeddings"], "wb")
f.write(pickle.dumps(data))
f.close()
一些注意的点是在定位人脸时,大小小于20*20的会被过滤掉
(2)模型训练
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--embeddings", required=True,
help="path to serialized db of facial embeddings")
ap.add_argument("-r", "--recognizer", required=True,
help="path to output model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to output label encoder")
args = vars(ap.parse_args())
# load the face embeddings
print("[INFO] loading face embeddings...")
data = pickle.loads(open(args["embeddings"], "rb").read())
# encode the labels
print("[INFO] encoding labels...")
le = LabelEncoder()
labels = le.fit_transform(data["names"])
# train the model used to accept the 128-d embeddings of the face and
# then produce the actual face recognition
print("[INFO] training model...")
recognizer = SVC(C=1.0, kernel="linear", probability=True)
recognizer.fit(data["embeddings"], labels)
# write the actual face recognition model to disk
f = open(args["recognizer"], "wb")
f.write(pickle.dumps(recognizer))
f.close()
# write the label encoder to disk
f = open(args["le"], "wb")
f.write(pickle.dumps(le))
f.close()
首先将标签进行编码,之后使用SVM对 128 维向量进行训练
(3)预测新图片
# import the necessary packages
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-r", "--recognizer", required=True,
help="path to model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to label encoder")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load our serialized face embedding model from disk
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
# load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args["recognizer"], "rb").read())
le = pickle.loads(open(args["le"], "rb").read())
# load the image, resize it to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image dimensions
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(image, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# apply OpenCV's deep learning-based face detector to localize
# faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for the
# face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255, (96, 96),
(0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# perform classification to recognize the face
preds = recognizer.predict_proba(vec)[0]
j = np.argmax(preds)
proba = preds[j]
name = le.classes_[j]
# draw the bounding box of the face along with the associated
# probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
人脸检测盒特征抽取的步骤和之前相同,得到新图片的特征向量后送入训练好的SVM中得到预测结果。
3.人脸校准
原文链接
有些时候图片中的人脸可能并不是正面,也可能旋转了一些角度,因此通过旋转、放缩等操作进行人脸校准可以提升最终的识别准确率。代码如下:
# import the necessary packages
from .helpers import FACIAL_LANDMARKS_IDXS
from .helpers import shape_to_np
import numpy as np
import cv2
class FaceAligner:
def __init__(self, predictor, desiredLeftEye=(0.35, 0.35),
desiredFaceWidth=256, desiredFaceHeight=None):
# store the facial landmark predictor, desired output left
# eye position, and desired output face width + height
self.predictor = predictor
self.desiredLeftEye = desiredLeftEye
self.desiredFaceWidth = desiredFaceWidth
self.desiredFaceHeight = desiredFaceHeight
# if the desired face height is None, set it to be the
# desired face width (normal behavior)
if self.desiredFaceHeight is None:
self.desiredFaceHeight = self.desiredFaceWidth
def align(self, image, gray, rect):
# convert the landmark (x, y)-coordinates to a NumPy array
shape = self.predictor(gray, rect)
shape = shape_to_np(shape)
# extract the left and right eye (x, y)-coordinates
(lStart, lEnd) = FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = FACIAL_LANDMARKS_IDXS["right_eye"]
leftEyePts = shape[lStart:lEnd]
rightEyePts = shape[rStart:rEnd]
# compute the center of mass for each eye
leftEyeCenter = leftEyePts.mean(axis=0).astype("int")
rightEyeCenter = rightEyePts.mean(axis=0).astype("int")
# compute the angle between the eye centroids
dY = rightEyeCenter[1] - leftEyeCenter[1]
dX = rightEyeCenter[0] - leftEyeCenter[0]
angle = np.degrees(np.arctan2(dY, dX)) - 180
# compute the desired right eye x-coordinate based on the
# desired x-coordinate of the left eye
desiredRightEyeX = 1.0 - self.desiredLeftEye[0]
# determine the scale of the new resulting image by taking
# the ratio of the distance between eyes in the *current*
# image to the ratio of distance between eyes in the
# *desired* image
dist = np.sqrt((dX ** 2) + (dY ** 2))
desiredDist = (desiredRightEyeX - self.desiredLeftEye[0])
desiredDist *= self.desiredFaceWidth
scale = desiredDist / dist
# compute center (x, y)-coordinates (i.e., the median point)
# between the two eyes in the input image
eyesCenter = ((leftEyeCenter[0] + rightEyeCenter[0]) // 2,
(leftEyeCenter[1] + rightEyeCenter[1]) // 2)
# grab the rotation matrix for rotating and scaling the face
M = cv2.getRotationMatrix2D(eyesCenter, angle, scale)
# update the translation component of the matrix
tX = self.desiredFaceWidth * 0.5
tY = self.desiredFaceHeight * self.desiredLeftEye[1]
M[0, 2] += (tX - eyesCenter[0])
M[1, 2] += (tY - eyesCenter[1])
# apply the affine transformation
(w, h) = (self.desiredFaceWidth, self.desiredFaceHeight)
output = cv2.warpAffine(image, M, (w, h),
flags=cv2.INTER_CUBIC)
# return the aligned face
return output
人脸校准器包含四个参数,predictor是面部特征预测模型,desiredLeftEye是期望输出左眼位置占全图的比例,desiredFaceWidth是期望人脸宽度,desiredFaceHeight是期望人脸高度
Align函数有三个参数,分别是输入的RGB图像,灰度图像和dlib的HOG人脸检测的边界框。
Align函数的过程包括:
- 通过HOG人脸检测得到左右眼的位置,计算左右眼中心点的连线和水平线的角度,之后以中心位置进行旋转;
- 图片的放缩程度通过计算当前左右眼中心点的距离和期望左右眼中心点距离的比例来决定
- 最后进行裁剪得到最终的脸部修正图片
4.活体检测
原文链接
在人脸识别中,为了防止他人利用照片或者视频的方式使人脸识别系统产生错误判断,进行活体检测是有必要的。进行活体检测的方式有很多种,参考论文 An Overview of Face liveness Detection,比如:
- 纹理分析:计算脸部区域的LBP,然后使用SVM进行判断
- 频率分析:检验脸部的傅里叶域
- 可变聚焦分析(Variable focusing Analysis):连拍两张照片,聚焦在不同位置,查看像素值 (Pixel Value) 的变化
- 启发式算法(Heuristic-Based Algorithms):眼动、唇动、眨眼这些动作,照片是不会有的。
- 光流算法(Optical Flow Algorithms):在相邻两帧之间,检测物体运动的方向和幅度,查出2D和3D物体之间的差别。