《Pytorch - BP全连接神经网络模型》
2020年10月4号,国内已经5号凌晨了,依然在家学习。
今天是我写的第三个 Pytorch程序,从今天起也算是入门了。
这一次我想把之前自己手写的matlab实现的简易的传统的BP神经网络在Pytorch上重新实现一遍,想看看对比和效果差异。
这一次我设计的是一个四个层的全连接网络[784, 400, 200, 100, 10]的网络,输入层是400个节点,输出层是10个节点。其他的都是隐藏层,这里每一层节点的输出我用的是ReLu函数作为激活函数。测试数据依然是MNIST数据集。
核心步骤描述如下:
1:建立的网络模型如下:

结构十分清晰,完全就是按照上述的设计组建的模型,激活函数使用ReLu。
2:MNIST数据集采用运行阶段在网上下载的方式,如果指定目录已经存在该数据集,就会忽略掉download参数,跳过下载。

3:损失函数使用之前学习的交叉熵损失函数,梯度下降算则随机梯度下降。

4:为了我们方便观察整个训练的过程,我们在每一次迭代结束,都会现场使用模型去测试数据集上现场运行一把,看看实际的预测效果如何,分别记录下每次迭代过程中训练损失值,训练准确度,测试损失值,测试准确度,并且也是为了方便画图展示出来。
话不多说,我就直接上代码实例,代码的注释我都是用中文直接写的。
# -*- coding: utf-8 -*
"""
Created on Fri Jul 27 17:47:03 2018
@author: Administrator
"""
import numpy as np
import torch
from torchvision.datasets import mnist # 导入 pytorch 内置的 mnist 数据
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# Step 1:============================准备数据===================
# 定义一个对图像像素数据的标准化处理函数
# 变换到0~255的范围,在变换到0~1的范围
# 对数据进行标准化
# 对图像数据从矩阵形式变成一个 W*H的一维向量
def data_tf(img):
img = np.array(img, dtype='float32') / 255
img = (img - 0.5) / 0.5 # 标准化,
img = img.reshape((-1,)) # 拉平
img = torch.from_numpy(img)
return img
# 先来准备数据
# 使用内置函数下载 mnist 数据集,并且使用自定义的标准化函数对数据进行标准化
# download 参数是表明数据是要从网上下载么?如果该目录下已经存在数据集,就不会再下载了。
train_set = mnist.MNIST('./data', train = True, transform=data_tf, download = True)
test_set = mnist.MNIST('./data', train = False, transform=data_tf, download = True)
firstImg, firstImg_label = train_set[0] # a为训练数据第一个的图像数据,a_label为训练数据第一个的标签
# 训练数据数量是60000
print(train_set)
# 测试数据数量是60000
print(test_set)
# 打印出第一个图像和其标签的值
print(firstImg.shape)
print(firstImg_label)
# DataLoader本质上就是一个iterable(跟python的内置类型list等一样),并利用多进程来加速batch data的处理,使用yield来使用有限的内存
# 使用 pytorch 自带的 DataLoader 定义一个数据迭代器,也就是将数据进行排序标号,shuffle也就是打乱数据
# DataLoader是一个高效,简洁,直观的网络输入数据结构,便于使用和扩展
# 这种方式能加快数据计算速度,减少训练时间。
train_data = DataLoader(train_set, batch_size=64, shuffle=True) # 训练数据
test_data = DataLoader(test_set, batch_size=128, shuffle=False) # 测试数据
# 这里展示的是一个批量处理的数据,想象成之前学习的mini-batch,每次迭代处理一个小批量的数据。
# 训练数据是64个图像为一组数据,维度是[64, 784]
batch, batch_label = next(iter(train_data))
# 打印出一个批次的数图像和其标签,主要为了展示维度。
print(batch.shape)
print(batch_label.shape)
# Step 2:============================定义模型===================
# 定义一个类,继承自 torch.nn.Module,torch.nn.Module是callable的类
# 在整个类里面重新定义一个标准的BP全连接神经网络,网络一共是四层,
# 层数定义:784, 400, 200, 100, 10
# 其中输入层784个节点,输出层是10个节点,分别代表10个数字,其他的层都是隐藏层。
# 我们使用了Relu的激活函数,而不是sigmoid激活函数
# 整个子类需要重写forward函数,
class BPNNModel(torch.nn.Module):
def __init__(self):
# 调用父类的初始化函数,必须要的
super(BPNNModel, self).__init__()
# 创建四个Sequential对象,Sequential是一个时序容器,将里面的小的模型按照序列建立网络
self.layer1 = nn.Sequential(nn.Linear(784, 400), nn.ReLU())
self.layer2 = nn.Sequential(nn.Linear(400, 200), nn.ReLU())
self.layer3 = nn.Sequential(nn.Linear(200, 100), nn.ReLU())
self.layer4 = nn.Sequential(nn.Linear(100, 10))
def forward(self, img):
# 每一个时序容器都是callable的,因此用法也是一样。
img = self.layer1(img)
img = self.layer2(img)
img = self.layer3(img)
img = self.layer4(img)
return img
# 创建和实例化一个整个模型类的对象
model = BPNNModel()
# 打印出整个模型
print(model)
# Step 3:============================定义损失函数和优化器===================
# 定义 loss 函数,这里用的是交叉熵损失函数(Cross Entropy),这种损失函数之前博文也讲过的。
criterion = nn.CrossEntropyLoss()
# 我们优先使用随机梯度下降,lr是学习率: 0.1
optimizer = torch.optim.SGD(model.parameters(), 1e-1)
# Step 4:============================开始训练网络===================
# 为了实时观测效果,我们每一次迭代完数据后都会,用模型在测试数据上跑一次,看看此时迭代中模型的效果。
# 用数组保存每一轮迭代中,训练的损失值和精确度,也是为了通过画图展示出来。
train_losses = []
train_acces = []
# 用数组保存每一轮迭代中,在测试数据上测试的损失值和精确度,也是为了通过画图展示出来。
eval_losses = []
eval_acces = []
for e in range(20):
# 4.1==========================训练模式==========================
train_loss = 0
train_acc = 0
model.train() # 将模型改为训练模式
# 每次迭代都是处理一个小批量的数据,batch_size是64
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 计算前向传播,并且得到损失函数的值
out = model(im)
loss = criterion(out, label)
# 反向传播,记得要把上一次的梯度清0,反向传播,并且step更新相应的参数。
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()
# 计算分类的准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / im.shape[0]
train_acc += acc
train_losses.append(train_loss / len(train_data))
train_acces.append(train_acc / len(train_data))
# 4.2==========================每次进行完一个训练迭代,就去测试一把看看此时的效果==========================
# 在测试集上检验效果
eval_loss = 0
eval_acc = 0
model.eval() # 将模型改为预测模式
# 每次迭代都是处理一个小批量的数据,batch_size是128
for im, label in test_data:
im = Variable(im) # torch中训练需要将其封装即Variable,此处封装像素即784
label = Variable(label) # 此处为标签
out = model(im) # 经网络输出的结果
loss = criterion(out, label) # 得到误差
# 记录误差
eval_loss += loss.item()
# 记录准确率
_, pred = out.max(1) # 得到出现最大值的位置,也就是预测得到的数即0—9
num_correct = (pred == label).sum().item() # 判断是否预测正确
acc = num_correct / im.shape[0] # 计算准确率
eval_acc += acc
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(e, train_loss / len(train_data), train_acc / len(train_data),
eval_loss / len(test_data), eval_acc / len(test_data)))
plt.title('train loss')
plt.plot(np.arange(len(train_losses)), train_losses)
plt.plot(np.arange(len(train_acces)), train_acces)
plt.title('train acc')
plt.plot(np.arange(len(eval_losses)), eval_losses)
plt.title('test loss')
plt.plot(np.arange(len(eval_acces)), eval_acces)
plt.title('test acc')
plt.show()
这里有一些输出,我们解释下:
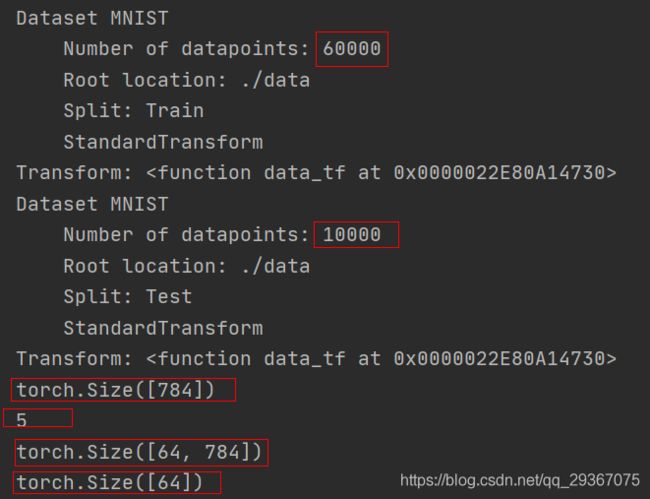
上图展示的是,原始图像数据中,训练数据有60000个,测试数据有10000个,其中第一个训练数据图像是784维度的向量,该图像代表的数字是5。经过DataLoader后,训练数据每一批量的数据是64个图像,是64*784维度的矩阵。
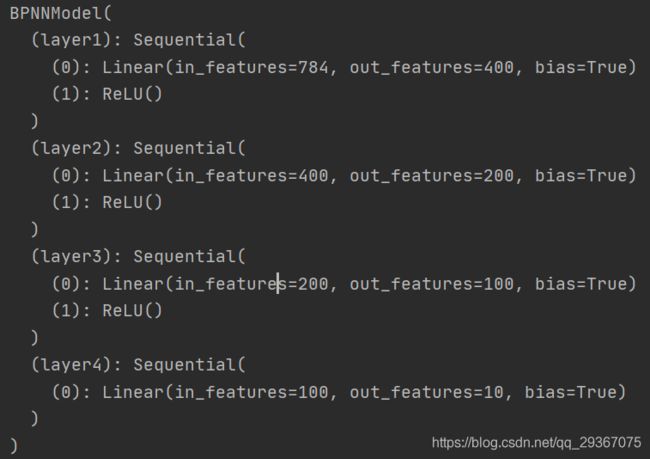
上图展示模型的设计样貌。都是参数模型,四层网络,一共有四层参数。

通过打印,以及结合最后看我们的画出来图像,可见此时模型的准确率已经达到了98%,比我用matlab当初设计的那个模型还要高出6个百分点,框架肯定是做了很多优化的。
