中文预训练模型泛化能力挑战赛
目录
- 赛题描述及数据说明
-
- 数据说明
- 数据格式
- 评测方案
-
- 计算公式:
- macro f1
-
- sklearn 计算方式 (python):
- 赛题分析
-
- 多任务学习
-
- 多任务学习动机
- 模型结构
-
- 硬共享模式
- 软共享模式
- 共享-私有模式
- loss优化
- 代码实践
-
- Step 1:环境准备
- Step 2:数据读取
-
- 1) 数据集合并
- 2)标签编码
- 3) 数据信息查看
- Step 3: 数据分析(EDA)
-
- 1) 子句长度统计分析
- 2)统计标签的基本分布信息
- Step 4: 预训练模型选择
-
- 1) 模型选择
- 2) 调优参数配置
- Step 5: 模型构建
-
- 1) 切分数据集(Train,Val)进行模型训练、评价
-
- keras.backend.clip(x, min_value, max_value)
- keras.backend.round()
- keras.backend.epsilon()
- 2) 构造输入bert的数据格式
-
- to_categorical
- 3) 模型搭建
- 4) 模型训练
- 5) 输出结果
赛题描述及数据说明
大赛地址:https://tianchi.aliyun.com/s/3bd272d942f97725286a8e44f40f3f74
本赛题精选了以下3个具有代表性的任务,要求选手提交的模型能够同时预测每个任务对应的标签:
数据说明
OCNLI:是第一个非翻译的、使用原生汉语的大型中文自然语言推理数据集;
OCEMOTION:是包含7个分类的细粒度情感性分析数据集;
TNEWS:来源于今日头条的新闻版块,共包含15个类别的新闻;
数据格式
- 任务1:OCNLI–中文原版自然语言推理
0 一月份跟二月份肯定有一个月份有. 肯定有一个月份有 0
1 一月份跟二月份肯定有一个月份有. 一月份有 1
2 一月份跟二月份肯定有一个月份有. 一月二月都没有 2
3 一点来钟时,张永红却来了 一点多钟,张永红来了 0
4 不讲社会效果,信口开河,对任何事情都随意发议论,甚至信谣传谣,以讹传讹,那是会涣散队伍、贻误事业的 以讹传讹是有害的 0
(注:id 句子1 句子2 标签)
(注:标签集合:[蕴含,中性,不相关])
- 任务2:OCEMOTION–中文情感分类
0 你知道多伦多附近有什么吗?哈哈有破布耶...真的书上写的你听哦...你家那块破布是世界上最大的破布,哈哈,骗你的啦它是说尼加拉瓜瀑布是世界上最大的瀑布啦...哈哈哈''爸爸,她的头发耶!我们大扫除椅子都要翻上来我看到木头缝里有头发...一定是xx以前夹到的,你说是不是?[生病] sadness
1 平安夜,圣诞节,都过了,我很难过,和妈妈吵了两天,以死相逼才终止战争,现在还处于冷战中。sadness
2 我只是自私了一点,做自己想做的事情! sadness
3 让感动的不仅仅是雨过天晴,还有泪水流下来的迷人眼神。happiness
4 好日子 happiness
(注:id 句子 标签)
- 任务3:TNEWS–今日头条新闻标题分类
0 上课时学生手机响个不停,老师一怒之下把手机摔了,家长拿发票让老师赔,大家怎么看待这种事? 108
1 商赢环球股份有限公司关于延期回复上海证券交易所对公司2017年年度报告的事后审核问询函的公告 104
2 通过中介公司买了二手房,首付都付了,现在卖家不想卖了。怎么处理? 106
3 2018年去俄罗斯看世界杯得花多少钱? 112
4 剃须刀的个性革新,雷明登天猫定制版新品首发 109
(注:id 句子 标签)
评测方案
参赛选手仅可使用单模型,推荐选手使用单模型完成本赛题(单模型的定义:一个任务只能有一个预测函数,所有任务只能使用同一个bert,在计算图中只能有一个bert),先求出每个任务的macro f1,然后在三个任务上取平均值,具体计算公式如下:
计算公式:
| 名称 | 说明 |
|---|---|
| TP(True Positive) | 真阳性:预测为正,实际也为正 |
| FP(False Positive) | 假阳性:预测为正,实际为负 |
| FN(False Negative) | 假阴性:预测与负、实际为正 |
| TN(True Negative) | 真阴性:预测为负、实际也为负 |
| P(Precision) | 精确率 P = TP/(TP+FP) |
| R(Recall) | 召回率 R = TP/(TP+FN) |
| F(f1-score) | F-值 F = 2PR/(P+R) |
macro f1
需要先计算出每一个类别的准召及其f1 score,然后通过求均值得到在整个样本上的f1 score。
sklearn 计算方式 (python):
from sklearn.metrics import confusion_matrix, precision_recall_fscore_support, classification_report, f1_score
l_t, l_p = [1, 2, 3, 2, 3], [2, 2, 3, 2, 1]
marco_f1_score = f1_score(l_t, l_p, average='macro')
print(marco_f1_score)
print(f"{'confusion_matrix':*^80}")
print(confusion_matrix(l_t, l_p, ))
print(f"{'classification_report':*^80}")
print(classification_report(l_t, l_p, ))
示例输出:
0.48888888888888893
********************************confusion_matrix********************************
[[0 1 0]
[0 2 0]
[1 0 1]]
*****************************classification_report******************************
precision recall f1-score support
1 0.00 0.00 0.00 1
2 0.67 1.00 0.80 2
3 1.00 0.50 0.67 2
accuracy 0.60 5
macro avg 0.56 0.50 0.49 5
weighted avg 0.67 0.60 0.59 5
最终得分:
取每个任务的macro f1,最后取平均值,作为 最终得分。
计:
- macro_f1_ocnli 为ocnli任务的 macro_f1
- macro_f1_ocemotion 为ocemotion任务的 macro_f1
- macro_f1_tnews 为tnews任务的 macro_f1
最终得分为:
score = (macro_f1_ocnli + macro_f1_ocemotion + macro_f1_tnews) / 3
赛题分析
-
本次赛题为数据挖掘类型,通过预训练模型调优进行分类。
-
是一个典型的多任务多分类问题。
-
主要应用keras_bert,以及pandas、numpy、matplotlib、seabon、sklearn、keras等数据挖掘常用库或者框架来进行数据挖掘任务。
-
赛题禁止人工标注;微调阶段不得使用外部数据;三个任务只能共用一个bert;只能单折训练。
多任务学习
多任务学习(Multi-Task Learning/MTL),有时候也称为:联合学习( joint learning)、自主学习(learning to learn)、辅助任务学习(learning with auxiliary tasks )。大多数机器学习模型都是独立对一个任务进行学习的,而多任务学习则是将多个相关任务放在一起进行学习。从损失函数角度来说,只要优化的是多个损失函数,则就是在进行多任务学习。多任务学习的目标是,通过利用相关任务的训练信号中包含的特定领域信息来提高泛化能力。当前多任务学习的研究,主要集中在两个方面:模型结构和loss优化。对比于单任务学习,多任务学习有不少优点,下面从多任务学习的动机和有效性来进行阐述。
多任务学习动机
- 从生物学上讲,可以把MTL看作是受到人类学习的启发,在学习新任务时,人类通常会使用在其他相关任务上学来的知识。
- MTL避免重复计算共享层中的特征,既减少了内存的占用,也大大提高了推断速度。
- 单任务学习每个特定任务都需要大量带标签数据,MTL提供了一种有效的方法,来利用相关任务的监督数据。
- 多任务学习通过缓解对某一任务的多度拟合而获得正则化效果,从而使所学的表征在任务间具有通用性。
为什么有效? - 每一个任务数据都有噪音,模型只学习一个任务容易在该任务上过拟合,而学习多个任务可以使模型通过平均噪声的方式获得更好的表示。
- 如果一个任务非常嘈杂,或者数据有限且高维,那么模型将很难区分相关和不相关的特征。MTL可以帮助模型将注意力集中在那些真正重要的特性上,因为其他任务将为这些特性的相关性或不相关性提供额外的证据。
- 对某个任务B来说,特征G比较容易学到,但对另外的任务A则比较难学到。可能因为任务A与特征G的交互比较复杂,或者其他特征阻碍了模型学习特征G的能力。这个时候,使用MTL,可以通过任务B来学习到特征G。
- MTL使模型偏向于所有任务都偏向的特征,这有助于推广到新的任务,因为特征在足够多的训练任务中表现良好,也会在新任务上表现良好,只要它们来自相同的环境。
- MTL通过引入归纳偏差来当做正则化,降低过拟合风险。
模型结构
如下图所示,深度学习中的多任务学习模型结构主要分为三种:硬共享模式、软共享模式和共享-私有模式。
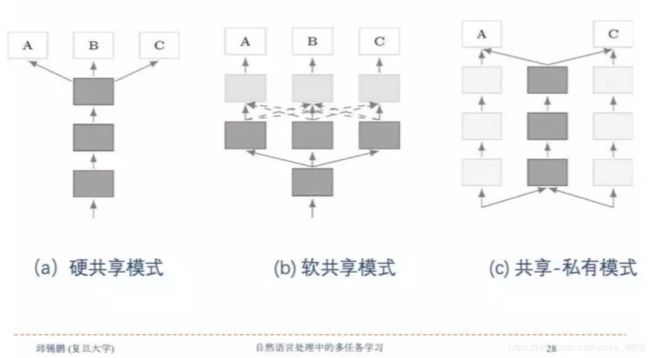
硬共享模式
从1993年开始,硬参数共享就是神经网络MTL中最常用的方法。如上图a所示,它通常在所有任务之间共享隐藏层,同时保留几个特定任务的输出层。硬参数共享可以大大降低了过拟合的风险。
软共享模式
如上图b所示,在软共享模式中,每个任务都有自己的模型和参数,对模型参数之间的距离进行正则化,从而使参数趋于相似。
共享-私有模式
如上图c所示,共享-私有模式,通过设置外部记忆共享机制来实现在所有任务上的信息共享。该模式有个优点,可以避免在共享路径上传递负迁移的信息,这些信息对另外的任务有损害。
loss优化
以最经典的硬共享模式为例,来分析下多任务学习的loss,最简单的方式就是多个任务的loss直接相加,就得到整体的loss,那么loss函数为:
L o s s = ∑ i l o s s i Loss =\sum_i loss_i Loss=i∑lossi
其中 l o s s i loss_i lossi 表示第i个任务的loss。
这种方式非常简单,但不合理之处也比较明显,不同的任务loss的量级不同,这可能导致多任务的学习被某个任务所主导或学偏。所以我们对loss函数进行简单的调整,为每一个任务的loss添加一个权重参数,则整体loss函数变为:
L o s s = ∑ i w i ∗ l o s s i \\ Loss = \sum_i w_i*loss_i Loss=i∑wi∗lossi
其中 w i w_i wi 表示第i个任务的权重。
相对于loss直接相加的方法,这种方式可以让我们调整每个任务的重要性程度,但仍然存在一些问题,因为不同的任务学习的难易程度不同,且不同的任务处于的学习阶段不同,比如某个任务接近收敛,而某个任务还没训练好,这样固定的权重就会限制任务的学习。所以在多任务学习中,还可以使用动态的加权方式,loss的权重会根据任务的学习阶段、学习的难易程度甚至是学习的效果来进行调整,这时,整体loss函数变为:
L o s s = ∑ i w i ( t ) ∗ l o s s i \\ Loss = \sum_iw_i(t)*loss_i Loss=i∑wi(t)∗lossi
w i ( t ) w_i(t) wi(t) 表示第t步时,任务i的权重值,关于动态权重的选择方式,可以参考以下方式:
- Gradient Normalization——梯度标准化【Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks】
- Dynamic Weight Averaging ——动态加权平均【End-to-End Multi-Task Learning with Attention】
- Dynamic Task Prioritization ——动态任务优先级【Dynamic task prioritization for multitask learning】
- Uncertainty Weighting——不确定性加权【Multi-task learning using uncertainty to weigh losses for scene geometry and semantics】
当然除此之外,还有研究人员将MTL视为多目标优化问题,总体目标是在所有任务中找到一个帕累托最优解,具体可参考论文【Multiple-gradient descent algorithm (mgda) for multiobjective optimization】。
代码实践
Step 1:环境准备
导入相关包
import pandas as pd
import codecs, gc
import numpy as np
from sklearn.model_selection import KFold
from keras_bert import load_trained_model_from_checkpoint, Tokenizer
from keras.metrics import top_k_categorical_accuracy
from keras.layers import *
from keras.callbacks import *
from keras.models import Model
import keras.backend as K
from keras.optimizers import Adam
from keras.utils import to_categorical
from sklearn.preprocessing import LabelEncoder
如果在google colab上运行代码,需要先将数据上传至driver上。执行以下代码挂在driver并配置相关环境。
from google.colab import drive
drive.mount('/content/drive')
'''
路径说明:
../code #保存代码
../data #保存数据
../subs #保存数据
../chinese_roberta_wwm_large_ext_L-24_H-1024_A-16 #bert路径
'''
pip install keras-bert
Step 2:数据读取
# 将ocnli中content1[0:maxlentext1]+content2作为ocnli任务的content
times_train = pd.read_csv('/data/TNEWS_train1128.csv', sep='\t', header=None, names=('id', 'content', 'label')).astype(str)
ocemo_train = pd.read_csv('/data/OCEMOTION_train1128.csv',sep='\t', header=None, names=('id', 'content', 'label')).astype(str)
ocnli_train = pd.read_csv('/data/OCNLI_train1128.csv', sep='\t', header=None, names=('id', 'content1', 'content2', 'label')).astype(str)
ocnli_train['content'] = ocnli_train['content1'] + ocnli_train['content2'] # .apply( lambda x: x[:maxlentext1] )
times_testa = pd.read_csv('/data/TNEWS_a.csv', sep='\t', header=None, names=('id', 'content')).astype(str)
ocemo_testa = pd.read_csv('/data/OCEMOTION_a.csv',sep='\t', header=None, names=('id', 'content')).astype(str)
ocnli_testa = pd.read_csv('/data/OCNLI_a.csv', sep='\t', header=None, names=('id', 'content1', 'content2')).astype(str)
ocnli_testa['content'] = ocnli_testa['content1'] + ocnli_testa['content2'] # .apply( lambda x: x[:maxlentext1] )
1) 数据集合并
分别将三个任务的content、label列按行concat在一起作为训练集和标签、测试集,以此简单地将三任务转化为单任务。
# 合并三个任务的训练、测试数据
train_df = pd.concat([times_train, ocemo_train, ocnli_train[['id','content', 'label']]], axis=0).copy()
testa_df = pd.concat([times_testa, ocemo_testa, ocnli_testa[['id', 'content']]], axis=0).copy()
2)标签编码
# LabelEncoder处理标签,因为bert输入的label需要从0开始
# LabelEncoder(): Encode labels with value between 0 and n_classes-1.
encode_label = LabelEncoder()
train_df['label'] = encode_label.fit_transform(train_df['label'].apply(str))
3) 数据信息查看
train_df.info()
'''
Int64Index: 147453 entries, 0 to 48777
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 147453 non-null object
1 content 147453 non-null object
2 label 147453 non-null int64
dtypes: int64(1), object(2)
memory usage: 4.5+ MB
'''
数据为id、content、label三列,无子句为空的行。
Step 3: 数据分析(EDA)
1) 子句长度统计分析
统计子句长度主要用于设置输入bert的序列长度。
times_train['content'].str.len().describe(percentiles=[.95, .98, .99])\
,ocemo_train['content'].str.len().describe(percentiles=[.95, .98, .99])\
,ocnli_train['content1'].str.len().describe(percentiles=[.95, .98, .99])\
,ocnli_train['content2'].str.len().describe(percentiles=[.95, .98, .99])
'''
(count 63360.000000
mean 22.171086
std 7.334206
min 2.000000
50% 22.000000
95% 33.000000
98% 37.000000
99% 39.000000
max 145.000000
Name: content, dtype: float64, count 35315.000000
mean 48.214328
std 84.391942
min 3.000000
50% 34.000000
95% 134.000000
98% 138.000000
99% 142.000000
max 12326.000000
Name: content, dtype: float64, count 48778.000000
mean 24.174607
std 11.515428
min 8.000000
50% 22.000000
95% 46.000000
98% 49.000000
99% 50.000000
max 50.000000
Name: content1, dtype: float64, count 48778.000000
mean 15.828529
std 977.396848
min 2.000000
50% 10.000000
95% 21.000000
98% 24.000000
99% 27.000000
max 215874.000000
Name: content2, dtype: float64)
'''
从上可以看出,当设置bert序列长度为142时即可覆盖约99%子句的全部内容。
2)统计标签的基本分布信息
train_df['label'].value_counts() / train_df.shape[0]
'''
1 0.113467
0 0.109940
17 0.107397
23 0.084603
21 0.060318
10 0.047771
6 0.041749
4 0.039918
13 0.039036
8 0.033292
3 0.032668
5 0.032268
11 0.029487
19 0.029481
9 0.027690
18 0.027588
12 0.027541
16 0.027460
22 0.027412
15 0.022923
7 0.016853
2 0.008993
24 0.006097
20 0.004001
14 0.002048
Name: label, dtype: float64
'''
由上可以看出,标签占比差距非常大。在拆分训练集与验证集时如果简单地采用随机拆分,可能会导致验证集不存在部分标签的情况。
Step 4: 预训练模型选择
1) 模型选择
在众多nlp预训练模型中,本文baseline选择了哈工大与讯飞联合发布的基于全词遮罩(Whole Word Masking)技术的中文预训练模型:RoBERTa-wwm-ext-large。点击以下链接了解更多详细信息:
-
论文地址:https://arxiv.org/abs/1906.08101
-
开源模型地址:https://github.com/ymcui/Chinese-BERT-wwm
-
哈工大讯飞联合实验室的项目介绍:https://mp.weixin.qq.com/s/EE6dEhvpKxqnVW_bBAKrnA
2) 调优参数配置
为方便调优,在同一代码块中配置调优的参数。
#一些调优参数
er_patience = 2 # early_stopping patience
lr_patience = 5 # ReduceLROnPlateau patience
max_epochs = 2 # epochs
lr_rate = 2e-6 # learning rate
batch_sz = 4 # batch_size
maxlen = 256 # 设置序列长度为,base模型要保证序列长度不超过512
lr_factor = 0.85 # ReduceLROnPlateau factor
maxlentext1 = 200 # 选择ocnli子句一的长度
n_folds = 10 # 设置验证集的占比:1/n_folds
Step 5: 模型构建
1) 切分数据集(Train,Val)进行模型训练、评价
采用StratifiedKFold分层抽样抽取10%的训练数据作为验证集。
### 采用分层抽样的方式,从训练集中抽取10%作为验证机
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=222)
X_trn = pd.DataFrame()
X_val = pd.DataFrame()
for train_index, test_index in skf.split(train_df.copy(), train_df['label']):
X_trn, X_val = train_df.iloc[train_index], train_df.iloc[test_index]
break#不能多折训练
采用f1值做为评价指标,当评价指标不在提升时,降低学习率。
from keras import backend as K
def f1(y_true, y_pred):
def recall(y_true, y_pred):
"""Recall metric.
Only computes a batch-wise average of recall.
Computes the recall, a metric for multi-label classification of
how many relevant items are selected.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
"""Precision metric.
Only computes a batch-wise average of precision.
Computes the precision, a metric for multi-label classification of
how many selected items are relevant.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return2*((precision*recall)/(precision+recall+K.epsilon()))
keras.backend.clip(x, min_value, max_value)
逐元素clip(将超出指定范围的数强制变为边界值)
参数
- x: 张量或变量。
- min_value: Python 浮点或整数。
- max_value: Python 浮点或整数。
返回 - 一个张量。
keras.backend.round()
- 将小数取整:四舍六入五取偶
keras.backend.epsilon()
进行除法运算时,通常将其添加到分母中以防止被零除误差。Epsilon是一个很小的值(在TensorFlow Core v2.2.0中为1e-07),与分母的值几乎没有区别,但可确保它不等于零。
2) 构造输入bert的数据格式
# 标签类别个数
n_cls = len( train_df['label'].unique() )
# 训练数据、测试数据和标签转化为模型输入格式
# 训练集每行的content、label转为tuple存入list,再转为numpy array
TRN_LIST = []
for data_row in X_trn.iloc[:].itertuples():
TRN_LIST.append((data_row.content, to_categorical(data_row.label, n_cls)))
TRN_LIST = np.array(TRN_LIST)
# 验证集每行的content、label转为tuple存入list,再转为numpy array
VAL_LIST = []
for data_row in X_val.iloc[:].itertuples():
VAL_LIST.append((data_row.content, to_categorical(data_row.label, n_cls)))
VAL_LIST = np.array(VAL_LIST)
#测试集每行的content、label转为tuple存入list,再转为numpy array,其中label全为0
DATA_LIST_TEST = []
for data_row in testa_df.iloc[:].itertuples():
DATA_LIST_TEST.append((data_row.content, to_categorical(0, n_cls)))
DATA_LIST_TEST = np.array(DATA_LIST_TEST)
to_categorical
to_categorical就是将类别向量转换为二进制(只有0和1)的矩阵类型表示。其表现为将原有的类别向量转换为独热编码的形式。
3) 模型搭建
在bert后接一层Lambda层取出[CLS]对应的向量,再接一层Dense层用于分类输出。
#bert模型设置
def build_bert(nclass):
global lr_rate
bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path, seq_len=None) # 加载预训练模型
for l in bert_model.layers:
l.trainable = True
x1_in = Input(shape=(None,))
x2_in = Input(shape=(None,))
x = bert_model([x1_in, x2_in])
x = Lambda(lambda x: x[:, 0])(x) # 取出[CLS]对应的向量用来做分类
p = Dense(nclass, activation='softmax')(x) # 直接dense层softmax输出
model = Model([x1_in, x2_in], p)
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr_rate), #选择优化器并设置学习率
metrics=['accuracy', f1])
print(model.summary())
return model
4) 模型训练
使用google colab 上的V100卡训练一个epoch需要约1.5小时,跑两个epoch即可。
#模型训练函数
def run_nocv(nfold, trn_data, val_data, data_labels, data_test, n_cls):
global er_patience
global lr_patience
global max_epochs
global f1metrics
global lr_factor
test_model_pred = np.zeros((len(data_test), n_cls))
model = build_bert(n_cls)
# 下行代码用于加载保存的权重继续训练
# model.load_weights(path + '/subs/model.epoch01_val_loss0.9911_val_acc0.6445_val_f10.6276.hdf5')
early_stopping = EarlyStopping(monitor="val_f1", patience=er_patience) # 早停法,防止过拟合 #'val_accuracy'
plateau = ReduceLROnPlateau(monitor="val_f1", verbose=1, mode='max', factor=lr_factor, patience=lr_patience) # 当评价指标不在提升时,降低学习率
checkpoint = ModelCheckpoint(path + "/subs/model.epoch{epoch:02d}_val_loss{val_loss:.4f}_val_acc{val_accuracy:.4f}_val_f1{val_f1:.4f}.hdf5", monitor="val_f1", verbose=2, save_best_only=True, mode='max', save_weights_only=True) #保存val_f1最好的模型权重
#训练跟验证集可shuffle打乱,测试集不可打乱(否则在生成结果文件的时候没法跟ID对应上)
train_D = data_generator(trn_data, shuffle=True)
valid_D = data_generator(val_data, shuffle=True)
test_D = data_generator(data_test, shuffle=False)
#模型训练
model.fit_generator(
train_D.__iter__(),
steps_per_epoch=len(train_D),
epochs=max_epochs,
validation_data=valid_D.__iter__(),
validation_steps=len(valid_D),
callbacks=[early_stopping, plateau, checkpoint],
)
#模型预测
test_model_pred = model.predict_generator(test_D.__iter__(), steps=len(test_D), verbose=1)
train_model_pred = test_model_pred # model.predict(train_D.__iter__(), steps=len(train_D), verbose=1)
del model
gc.collect() #清理内存
K.clear_session() #clear_session就是清除一个session
return test_model_pred, train_model_pred
调用上述函数进行训练与预测。
cvs = 1
#输出为numpy array格式的25列概率
test_model_pred, train_model_pred = run_nocv(cvs, TRN_LIST, VAL_LIST, None, DATA_LIST_TEST, n_cls)
5) 输出结果
#将结果转为DataFrame格式
preds_tst_df = pd.DataFrame(test_model_pred)
#再将range(0,25)做encode_label逆变换作为该DataFrame的列名
preds_col_names = encode_label.inverse_transform( range(0,n_cls) )
preds_tst_df.columns = preds_col_names
#从每个任务对应的概率标签列中找出最大的概率对应的列名作为预测结果
'''
如ocnli任务的预测结果只能为0、1、2,那么从preds_tst_df中选择0-1-2三列中每行概率最大的列名作为ocnli任务的测试集预测结果,其它两个任务依此类推。
'''
times_preds = preds_tst_df.head(times_testa.shape[0])[times_train['label'].unique().tolist()]
times_preds = times_preds.eq(times_preds.max(1), axis=0).dot(times_preds.columns)
ocemo_preds = preds_tst_df.head(times_testa.shape[0] + ocemo_testa.shape[0]).tail(ocemo_testa.shape[0])[ocemo_train['label'].unique().tolist()]
ocemo_preds = ocemo_preds.eq(ocemo_preds.max(1), axis=0).dot(ocemo_preds.columns)
ocnli_preds = preds_tst_df.tail(ocnli_testa.shape[0])[ocnli_train['label'].unique().tolist()]
ocnli_preds = ocnli_preds.eq(ocnli_preds.max(1), axis=0).dot(ocnli_preds.columns)
#输出任务tnews的预测结果
times_sub = times_testa[['id']].copy()
times_sub['label'] = times_preds.values
times_sub.to_json(path + "/subs/tnews_predict.json", orient='records', lines=True)
#输出任务ocemo的预测结果
ocemo_sub = ocemo_testa[['id']].copy()
ocemo_sub['label'] = ocemo_preds.values
ocemo_sub.to_json(path + "/subs/ocemotion_predict.json", orient='records', lines=True)
#输出任务ocnli的预测结果
ocnli_sub = ocnli_testa[['id']].copy()
ocnli_sub['label'] = ocnli_preds.values
ocnli_sub.to_json(path + "/subs/ocnli_predict.json", orient='records', lines=True)
参考链接:https://mp.weixin.qq.com/s/IxwCTAGJ6gzqBOJGOBdJvQ