目标检测训练优化Tricks:《Bag of Freebies for Training Object Detection Neural Networks》
目标检测训练Tricks论文笔记
转载请注明出处:https://blog.csdn.net/ouyangfushu/article/details/88686189
作者:SyGoing
QQ: 244679942
一、论文概述及创新点
深度学习中各种SOTA的模型除了网络架构设计的精妙之外,研究者在对模型进行训练的过程中也探索了很多有用的tricks,比如模型优化方法(SGD、Adam和RMSprop等)、数据层面的增强方法、学习率更新策略、损失函数优化(人脸识别的各种loss函数)、正则化、著名的BatchNorm等,这些方法最初的验证几乎都是在分类问题中。论文《Bag of Freebies for Training Object Detection Neural Networks》(下面以文[1]简称)提到对于目标检测模型训练技巧则缺少系统的总结。
我们知道目标检测主要分为以YOLO和SSD为代表的one stage系列和Faster-RCNN为代表的two stage系列,他们各自训练时也有着自己的特点,文[1]似乎在提炼目标检测算法通用训练tricks,论文说是Bag of Freebies,并且更倾向于对One-stage系列优化,one-stage计算量更小,在落地上更为普遍。论文[1]称有四点贡献:
1、第一次系统地评估各种训练Tricks(多借鉴于分类)在不同目标检测算法上的应用效果,为研究者提供了很有价值参考。
2、借鉴分类问题(或对抗生成网络)中mixup数据增强的思路,提出一种适合于目标检测问题的mixup数据增强,并证明能显著提升目标检测模型泛化性能。
3、在不改变模型网络结构及损失函数情况下,应用文中的Tricks取得了5%-30%的AP提升。
4、扩展了目标检测数据增广领域的研究深度,显著增强了模型泛化能力,有助于减少过度拟合问题。实验还揭示了可以在不同网络结构中一致地提高目标检测性能的良好技术。
个人认为文章的杀手锏(创新点)便是借鉴mixup数据增强方法的思路提出适合于目标检测模型的训练的mixup,并且性能(AP)提升效果非常显著(一个打十个),然后配合其他的Tricks进一步增强模型的泛化性能。
二、目标检测训练Tricks
论文[1]总共提到了六种通用的训练Tricks,其中有几种在yolov3原始算法中都有用到,所以说不得不承认yolo系列是非常优秀的目标检测算法。具体为
1、Visually Coherent Image Mixup for Object Detection(mixup数剧增强,借鉴文[2])
与[2]原始的mixup不同点有两点:
1)文[2]提出的mixup数据增强是一种有特色方法,但是实验对象是分类与对抗生成网络,成对图像的mixup是以resize到相同大小的图像为前提完成的。

目标检测问题中如果resize图像到相同大小则会造成图像畸变,检测任务对于这种变化较为敏感,因此作者采用保图像几何形状的方式对图像进行mixup,我的理解是图像直接mixup成对图像,取最大宽高并填充(constant合成的空白区域),最后计算损失时按照mixup的beta分布产生的权重,对损失进行加权求和,再反向传播loss更新模型权重。
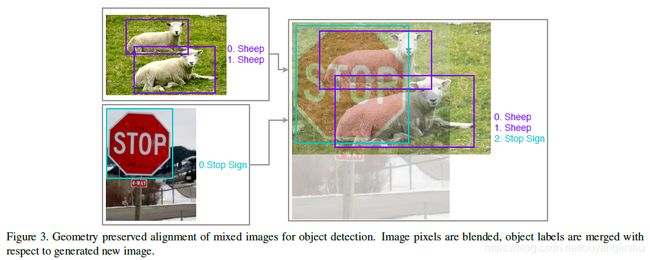
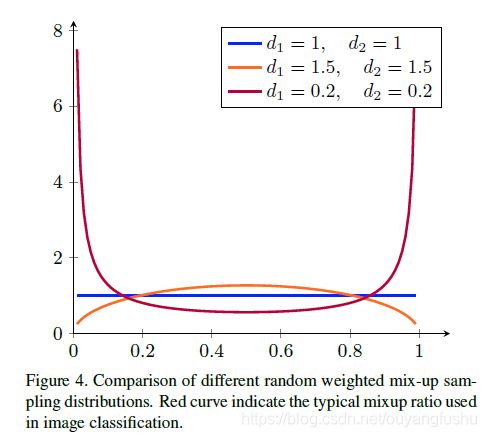
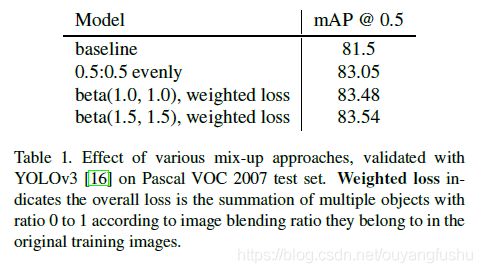
2)文[2]的mixup方法中成对图像求加权和的权重是由Beta分布随机生成(Beta分布如图),Beta的两个参数默认取值1.0(源码),原始mixup论文[2]试验则是从0.2到1.0的几组试验值,论文[1]采用的Beta分布两个参数则是取值大于等于1,在实验中Beta分布的参数值取1.5时效果更好,涨点明显:
 。
。
2、Classification Head Label Smoothing(目标类别标签光滑,参考[3])
在目标检测算法中,除了目标框Bounding Box的定位任务,还有对目标的分类,对于目标分类任务通常采用softmax函数处理类别输出神经元

如果类别标签采用one-hot编码(一个一维向量,维数为类别数目,仅在目标所属类别取1,其余位置取0),则损失函数:
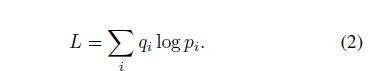
对于任意不同的两个类别,目标类别的分布在完全没有交集的情况下,交叉熵损失才有可能为0,而实际上这种情况不很难达到,即softmax损失函数对于任意两个不同的类别,惩罚两个类别相差很远(在训练中几乎很难达到)。

这样很容易逼上梁山,即使得置信度过高,出现过拟合问题。具体可以参见另一篇博客《熵的概念》。而smooth label 个人感觉则是对标签放松处理(改变类别的分布),使得目标函数不至于太严格,降低不同类别的置信度,一定程度上使得模型更易于收敛且能避免模型过度拟合(over fitting)数据。对目标类别的Ground Truth做如下处理,对原始标签称上一个小于1且接近于1的数,再加上一个类似正则项的东东,其实也就是一种对目标函数做的正则化处理。

其中,K为类别数目,分子为小正数(懒得打公式)。具体的描述可以参看论文[3]。
3、Data Preprocessing(数据预处理,纯粹意义上的数据增强)
数据预处理,这个就是较为纯粹的数据增强了,分类问题中经常用到各种七七八八的数据增强方法,但是文中提到分类问题使用的某些数据增强方式并不适合于目标检测问题,尤其是图像几何形状变换的方法。
文[1]着重研究评估了:1)随机几何变换,如:随机裁剪、随机扩张、随机水平翻转、随机resize;2)随机颜色抖动,如亮度、色调、曝光度、对比度。
目标检测有基于anchors的one stage系列,如经典而优秀的YOLO系列和SSD系列,这类算法的最终检测结果是基于输出Feature Map的每个像素,即基于Anchors的输出特征图像素级预测,如416x416输入的YOLOv2,输出为13x13的特征图,每个像素有5个anchors。
另一种就是基于提名的two stage系列,如基于RPN的Faster-RCNN,RPN阶段产生大量候选框,然后候选框印射到共享特征图中,在ROI Pooling 采样得到候选特征图进行下一步类别预测及位置的Refine,如下图所示为Faster-RCNN。

Two stage系列的算法由于在第二阶段本身具有大量的基于候选框crop的操作配合ROI Pooling或者ROI Align获取统一尺度的ROI,因此这类算法在训练阶段可以不采用随机几何变换。
4、Training Scheduler Revamping(训练策略改进)
1)Cosine schedule
文[1]中提到基于step的学习率策略,达到预设的epoch或iterations就按照一定比例减小学习率,学习率的陡然变化使得模型学习发生震荡而不稳定,而采用cosine schedule[4],cosine 函数自变量为0-pi,值域在0-1之间,这样基础学习率乘上以迭代步为自变量的cosine函数,这样学习率随着迭代进行缓慢减小。具体建模方式参看[4],试验对比效果如图,
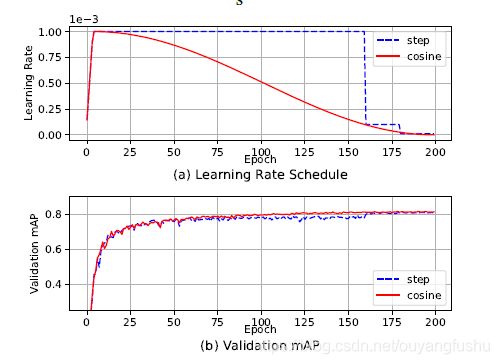
2) Warm up learning rate
如果读过darknet源码就可以看到,YOLOv2-v3训练就是用了这种策略,如cfg中设置burn in参数为1000,warm up学习策略在训练前一千步,从0开始逐渐增大到预设的基础学习率,所以YOLOv2-v3是一种非常优秀的目标检测算法,个人也非常喜欢。

这样做的好处呢? Warm可以避免训练初期的梯度爆炸问题,模型梯度更加稳定。过了1000步,后续迭代步配合cosine 策略,学习率再缓慢降低(模拟退火)。
5、Synchronized Batch Normalization
这个策略是针对土豪提的,对于大规模数据集的多卡训练,Batch会被分割成很多小部分(小 Batch)在不同的显卡,这样实际上虽然加速了训练,但是Batch却变小了,可能会限制Batch Normalization的作用,与大Batch训练的初衷向左。对于分类问题可能影响不到,但是对于对Batch敏感的目标检测任务则影响很大。基于此采用Synchronized Batch Normalization。
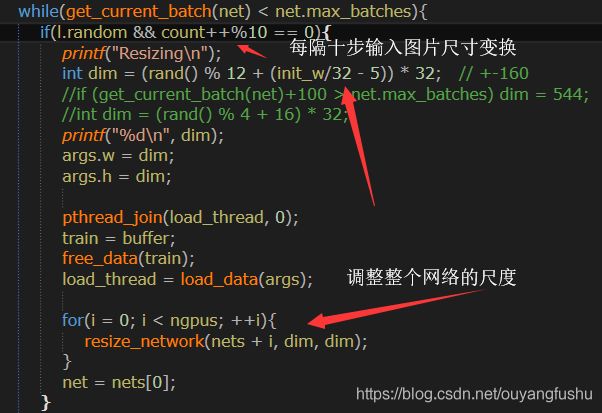
6、Random shapes training for single-stage object detection networks(即输入图像的多尺度训练)
这个Trick其实也是借鉴于YOLOv2/v3,我们知道YOLOv2/v3在训练时,每隔10个iterations就会变化训练图片的尺度,这样做可以实现跨尺度特征融合,也能使得模型在多种输入大小下训练以适应不同的图像大小输入,yolov2论文称之为多尺度训练,文[1]同时也提到这样做也可以使得模型不容易过拟合以增强泛化性能。下面为darknet源码(detector.c 119行):
三、试验与总结
作者首先在Pascal VOC数据集上做了细粒度评估对比实验,然后在MSCOCO数据集上主要测试整体性能和泛化性能,参与实验的有one stage的YOLOv3和two stage的Faster RCNN。
1、YOLOv3 改进实验结果(在VOC数据集上)

2、Faster R-CNN 改进实验结果(在VOC数据集上)

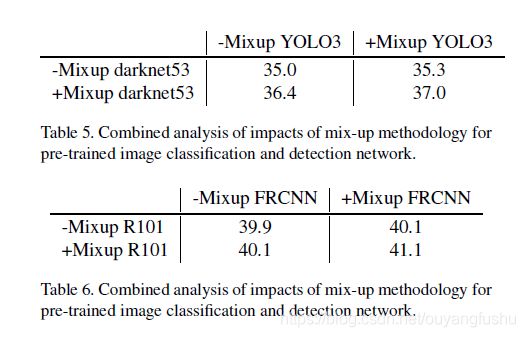
两组对比都是以无任何数据增强方法的训练和基准原始训练作为基准对照,可以看到数据增强对于one stage的yolov3有着显著的影响,不加任何数据增强方法mAP很低,加了之后天壤之别;而two stage的目标检测算法则对于数据增强不太敏感,这可能是因为two stage的目标检测算法(Faster RCNN)是最后预测结果是基于特征图的ROI Pooling映射采样,最后影响回归分类的是一个经过crop的特征图,而不像one stage的目标检测算法依赖于单位像素,文[1]在第三个trick中提到对于几何变换不敏感。
采用文中提到的训练tricks之后,模型的mAP提升较为明显,尤其是mixup的涨点明显,其次是class label smoothing.总体上可以实现5+点涨幅。虽然貌似只有几个点,但是模型的泛化能力提升不容忽视。
3、MSCOCO数据集上的提升

还是one stage的yolov3对于文中的tricks非常受用,毕竟单阶段目标检测算法比较吃数据增强。
值得注意的是mixup在ImageNet预训练Backbone+目标检测算法训练上分别使用时则会有进一步提升,作者特地还做了几组对比。在预训练Backbone上采用mixup训练分类,以及接入检测head的以后的整体训练采用mixup,若都采用涨点最优。
论文中涉及的训练tricks或者(Bags of freebies)已经开源在mxnet中,链接:https://github.com/dmlc/gluon-cv

该论文的缩影在官网也能见到:
https://gluon-cv.mxnet.io/build/examples_detection/index.html
我们来找一下mixup的缩影:
https://github.com/dmlc/gluon-cv/blob/master/gluoncv/data/mixup/detection.py

https://github.com/dmlc/gluon-cv/blob/master/gluoncv/data/transforms/presets/yolo.py

参考文献:
[1] Zhang Z, He T, Zhang H, et al. Bag of Freebies for Training Object Detection Neural Networks[J]. arXiv preprint arXiv:1902.04103, 2019.
[2] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz.mixup: Beyond empirical risk minimization. arXiv preprintarXiv:1710.09412, 2017.
[3] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna.Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and
pattern recognition, pages 2818–2826, 2016.
[4] I. Loshchilov and F. Hutter. Sgdr: Stochastic gradient descentwith warm restarts. arXiv preprint arXiv:1608.03983,2016.
[5] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[6] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.