【文献阅读】VQA的一篇综述(D. Teney等人,IEEE Signal Processing Magazine,2017)
一、文章背景
文章题目:《Visual Question Answering : A tutorial》
这篇文章和《Visual question answering: A survey of methods and datasets》这篇文章有同一作者Q. Wu和D. Teney,所以感觉两篇文章实际上差不多。
文章下载地址:https://ieeexplore.ieee.org/document/8103161
文章引用格式:D. Teney, Q. Wu, and A. Hengel. "Visual Question Answering : A tutorial." IEEE Signal Processing Magazine, vol, 163, no. 6, pp: 63-75, 2017. DOI: 10.1109/MSP.2017.2739826
项目地址:无
二、文章导读
先放上文章的摘要部分:
The task of visual question answering (VQA) is receiving increasing interest from researchers in both the computer vision and natural language processing fields. Tremendous advances have been seen in the field of computer vision due to the success of deep learning, in particular on low- and midlevel tasks, such as image segmentation or object recognition. These advances have fueled researchers’ confidence for tackling more complex tasks that combine vision with language and high-level reasoning. VQA is a prime example of this trend. This article presents the ongoing work in the field and the current approaches to VQA based on deep learning. VQA constitutes a test for deep visual understanding and a benchmark for general artificial intelligence (AI). While the field of VQA has seen recent successes, it remains a largely unsolved task.
摘要部分作者主要说了目前的深度学习在低层次或者中层次的任务中表现较好,比如图像分割,目标识别,但是对于高层次的推理,比如VQA,仍然是未解决的问题。
三、文章详细介绍
introduction部分主要介绍了VQA的动机和一些困难,比如一个问题不一定有唯一的答案,另外根据统计,几乎top 1000个答案就可以回答约90%的问题。
下面介绍下数据集的情况。VQA的早期数据集,大部分是半自动化的方式制作的,比用用看图说话,VQA目前的数据集,大部分都是通过众包(crowdsourcing)的方式人工制作。目前的数据集大致围绕以下三个方面发生变化:(1)数据集的大小(size),比如涉及到的名词概念;(2)需要推理的数量,比如是否需要多个概念之间的交互;(3)外部知识需要多少;VQA的数据集作者主要分了以下几类:
VQA-real:这个是现实图像的数据集,更新后的名字为VQA 2.0.比如:

Visual genome and visual7W:它是目前最大的数据集。
Zero-shot VQA:所谓zero-shot,就是指测试数据中出现了训练数据中没有的单词,来检验模型的学习整合能力(比如模型学到了马,老虎,熊猫,但是却让模型识别斑马,这样就是zero-shot)。比如,

Clipart images:大部分都是一些抽象图像,比如:
Video-based QA:目前只有很少的相关工作。
1. VQA中的深度学习(Deep neural networks for VQA)
处理流程可以如下图所示:
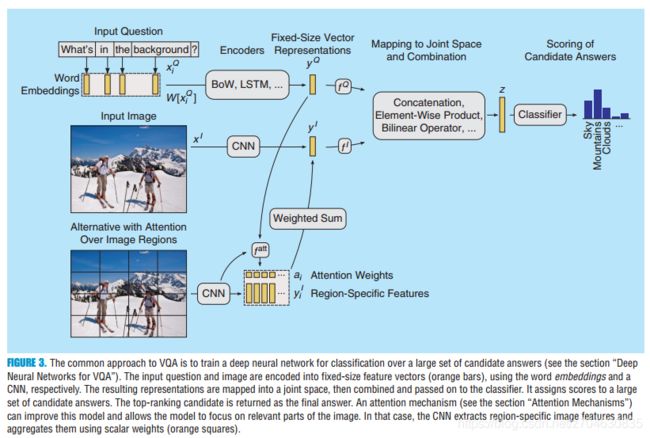
首先分别处理图像和问题,获得向量表示,然后将两个特征向量映射到同一空间中,最后将其联合输送到结果。
(1)图像编码Image encoding
输入图像x,用CNN来提取特征,然后用向量y来表示。CNN一般是预训练好的标准网络,向量y的尺寸一般设置为1024或者2048。
(2)问题编码Question encoding
和图像编码同理,第i个单词可以用词汇表中的索引来表示,每一个单词都可以表示为一个向量,即通过查找表的方式对问题进行表示。一种替代法是将索引向量表示为one-hot形式。所有单词的向量之后会表示成一个向量,常用的方法比如BoW,LSTM。
(3)特征联合Combination of image and question features.
这一步是为了将两个特征映射到同一个空间中,一种简单的策略就是连接(concatenate),另外就是点乘(multiplicative)。
(4)输出Output
一般是将这部分看做一个分类问题,一般是从2000个常出现的候选答案中选择一个。尽管一些不常见的答案会被过滤掉,但是留下的候选答案仍能够应付90%的问题,最终分类器输出排名最高的即为最终答案。
(5)变种Variations
这里作者给出了一些变种:
Encoding the question and the image with a single recurrent neural network (an LSTM) by passing the image features together with each word embedding or only once prior to the question words.
Encoding the question with a bidirectional RNN, i.e., two LSTMs that process the words in forward and backward order, respectively. This aims at capturing the language structure with more uniform importance on the beginning and the end of the question.
Adding additional multiplicative interactions within the network and between the features of the image and of the question. Such interpretations are typical of deep-learning models, but have little concrete support. Performance benefits usually stem simply from the additional capacity of the network.
Alternative schemes for combining image and question representations, such as element-wise sums and products, bilinear operations such as multimodal compact bilinear pooling (MCB) etc.
Gradual increases in performance of the state of the art is also explained by increasingly better pretrained CNNs to provide image features, and by the application of general enhancements for neural network architectures, such highway networks and residual networks, dropout, batch normalization, etc.
2. 高级技术Advanced techniques
(1)注意力机制Attention mechanisms
CNN提取的是全局特征,而局部特征,是从预训练CNN的早期层(先于池化)中获得的。网络会对每一个局部区域计算他注意力权重,因此一张图最终就可以表示为各个区域的加权和。比如:

注意力机制目前也提出了许多变种,比如HieCoAtt。
(2)预训练的语言表示Pretraining language representations
前面提到的将问题中的单词表示为向量,这个过程叫做词嵌入(word embeddings)。输入的词汇表中的每一个单词都有它自己的嵌入,这些嵌入可以通过后向传播的参数学得。这样的问题有两个:一是数据集中的出现单词都将是一个冗长(long-tail)的分布,也就是说有的单词并不会频繁出现,对于这类单词并不能学习到稳定且有意义的嵌入;二是拖尾(long-tail)属性,极端条件下,某些单词会在测试集频繁出现,但是在训练集中则很少出现,这类词的嵌入则很难通过样本学习到,实际上处理中,这类单词会被丢弃。
解决这类问题的一个办法就是在一个很大的数据集上预训练词嵌入,常见的词嵌入比如在维基百科上预训练的GloVe;另一个是word2vec的skip-gram模型。使用预训练的嵌入能够提高VQA的泛化性,
(3)记忆增广的神经网络Memory-augmented neural networks
记忆增广的神经网络在文本问答,VQA中表现出了较好的效果,该网络能够维持输入数据的内在表示。该模型用于VQA的一个变种是dynamic memory networks (DMNs),网络结构如下所示:

它由4个模块组成,输入模块将输入数据转换为离散向量,称为facts;问题模块使用GRU计算问题的向量表示;情景记忆模块(episodic memory module)检索需要回答问题的facts;回答模块使用分类器对候选答案进行排序。
(4)外部信息检索Run time retrieval of additional information
用外部先验知识的VQA能够学习推理能力,目前已有相关研究,这里不多介绍。
3. 目前和将来Directions of current and future research
目前基于标准VQA数据集,精度已经能够从58%提高到70%,作者认为这已经到达了一个瓶颈(seemed to plateau),调查结果如下表所示:

(1)数据集的偏见问题(Issues of data set biases)
语言偏见就是指问题带有明显的答案指向性,偏见是一种很微妙的现象,但它是现实世界中真是存在的。然而现有的VQA模型则过度的依赖于偏见,对训练数据死记硬背,实则并没有真正理解视觉场景。不看图像的VQA(blinded)和看图像的VQA(nonblinede)之间竟然没有很大差异,正确率分别为56%和65%。而正常情况下的blinded VQA的正确率应该接近0%,这也是未来需要考虑的一个问题。
(2)生词的问题(Issues with unknown and novel words)
目前的VQA都是监督的,例如训练数据中的名词和概念只能覆盖有限的现实世界。一个问题就是现有的模型都是在标准数据集上表现很好,但是并没有关注到数据集中的稀有单词,(可以认为是一种过拟合)。近期的一些工作提出zero-shot VQA,即测试问题中会出现一些相关生词,来检测模型是否真正的学习到了较好的泛化性。
(3)外部知识(External knowledge)
前面提到的zero-shot VQA,一定程度上需要检索外部知识(retrieving additional information),也就是learn to learn。
(4)模块化的方法(Modular approaches)
目前的大部分 方法都是端到端的整体网络。后面有人讲VQA分解成一些小任务(subtasks),从而提出了模块化的方法,每一个模块就负责解耦(decouple)一个小任务,与端对端方式不同的是,它是使用的中间的媒介信息。
(5)组合方法(Compositional models)
这类方法的目标就是为了解决泛化性,目前一个经典的方法是neural module networks。最近为了评估VQA的泛化性提出了一个新的数据集CLEVR。
四、小结
1. 这里附加上两位作者的个人简介:
Damien Teney ([email protected]) obtained his B. Sc. degree in 2007, his M.Sc. degree in 2009, and his Ph.D. degree in 2013, all in computer science from the University of Liege, Belgium. He is a postdoctoral researcher at the Australian Centre for Visual Technologies of the University of Adelaide, where he works on computer vision and machine learning. He was previously affiliated with Carnegie Mellon University, Pittsburgh, Pennsylvania; the University of Bath, United Kingdom; and the University of Innsbruck, Austria.
Qi Wu ([email protected]) received a bachelor’s degree in mathematical sciences from China Jiliang University, Hangzhou, and a master’s degree in computer science and a Ph.D. degree in computer vision from the University of Bath, United Kingdom, in 2012 and 2015, respectively. He is a postdoctoral researcher at the Australian Centre for Robotic Vision of the University of Adelaide. His research interests include cross-depiction object detection and classification, attributes learning, neural networks, and image captioning.