在hadoop调用mapreduce对文件中各个单词出现次数进行统计
目录
- 一、安装环境
- 二、必备工作
-
- 1.创建hadoop账户
- 2.设置Hadoop密码
- 3.为Hadoop用户增加管理员权限
- 4.更新apt
- 5.安装vim
- 6.安装SSH、配置SSH无密码登陆
- 三、安装java环境
-
- 1.安装JDK
- 2.验证JDK安装情况
- 四、安装hadoop
- 五、Hadoop单机配置(非分布式)
- 六、Hadoop伪分布式配置
-
- 1.修改配置文件
- 2.格式化 NameNode
- 3.开启NameNode和DataNode守护进程
- 4.校验安装
- 七、调用MapReduce执行WordCount对单词进行计数
-
- 1.准备
- 2.安装Eclipse
- 3.Hadoop-Eclipse-Plugin的安装与设置
- 4.创建WordCount项目
- 5.WordCount统计
- 八.参考材料
一、安装环境
本教程使用 Ubuntu 14.04 64位 作为系统环境(Ubuntu 12.04,Ubuntu16.04 也行,32位、64位均可),请自行安装系统(可参考使用VirtualBox安装Ubuntu)。
本教程基于原生 Hadoop 2,在 Hadoop 2.6.0 (stable) 版本下验证通过,可适合任何 Hadoop 2.x.y 版本,如 Hadoop 2.7.1、2.6.3、2.4.1等。
二、必备工作
1.创建hadoop账户
如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
2.设置Hadoop密码
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop
3.为Hadoop用户增加管理员权限
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
udo adduser hadoop sudo
最后注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
4.更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
udo apt-get update
若出现如下 “Hash校验和不符” 的提示,可通过更改软件源来解决。若没有该问题,则不需要更改。从软件源下载某些软件的过程中,可能由于网络方面的原因出现没法下载的情况,那么建议更改软件源。在学习Hadoop过程中,即使出现“Hash校验和不符”的提示,也不会影响Hadoop的安装。
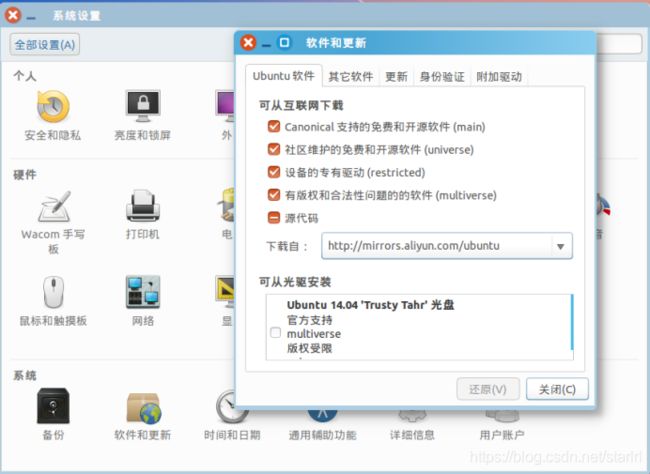
5.安装vim
后续需要更改一些配置文件,我比较喜欢用的是 vim(vi增强版,基本用法相同),建议安装一下(如果你实在还不会用 vi/vim 的,请将后面用到 vim 的地方改为 gedit,这样可以使用文本编辑器进行修改,并且每次文件更改完成后请关闭整个 gedit 程序,否则会占用终端):
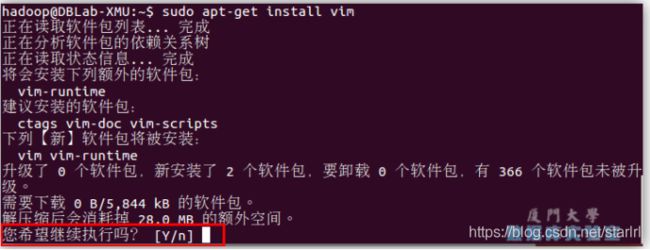
udo apt-get install vim
安装软件时若需要确认,在提示处输入 y 即可。
6.安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
udo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
sh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
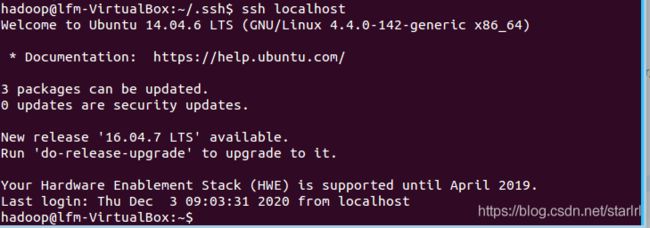
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
三、安装java环境
1.安装JDK
需要按照下面步骤来自己手动安装JDK1.8。
我们已经把JDK1.8的安装包jdk-8u162-linux-x64.tar.gz放在了百度云盘,可以点击这里到百度云盘下载JDK1.8安装包(提取码:99bg)。请把压缩格式的文件jdk-8u162-linux-x64.tar.gz下载到本地电脑,假设保存在“/home/linziyu/Downloads/”目录下。
在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
sh localhost
2.验证JDK安装情况
上面使用了解压缩命令tar,如果对Linux命令不熟悉,可以参考常用的Linux命令用法。
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls
可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_162目录。
下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc
上面命令使用vim编辑器(查看vim编辑器使用方法)打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
java -version
如果能够在屏幕上返回如下信息,则说明安装成功:
hadoop@ubuntu:~$ java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
四、安装hadoop
Hadoop安装文件,可以到Hadoop官网下载。
下载完 Hadoop 文件后一般就可以直接使用。但是如果网络不好,可能会导致下载的文件缺失,可以使用 md5 等检测工具可以校验文件是否完整。
我们选择将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxf ~/下载/hadoop-2.10.0.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.10.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
五、Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词 dfsadmin 出现了1次
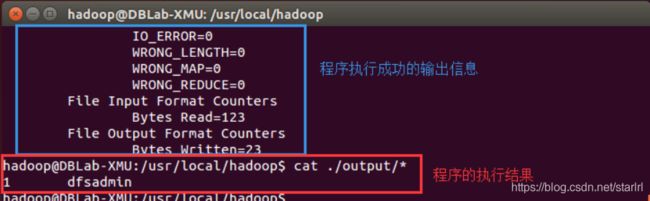
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
rm -r ./output
六、Hadoop伪分布式配置
1.修改配置文件
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将当中的
<configuration>
configuration>
修改为下面配置:
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>
同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/datavalue>
property>
configuration>
2.格式化 NameNode
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
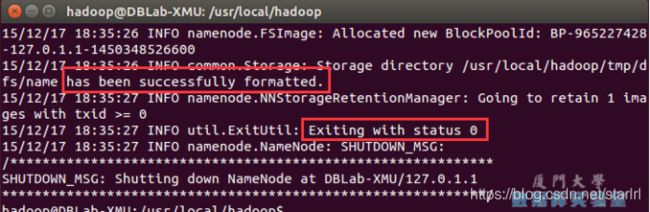
3.开启NameNode和DataNode守护进程
cd /usr/local/hadoop
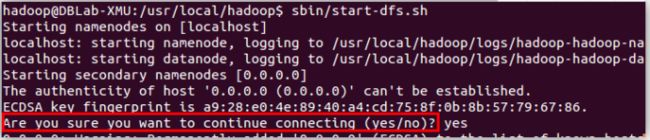
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
若出现如下SSH提示,输入yes即可。
4.校验安装
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
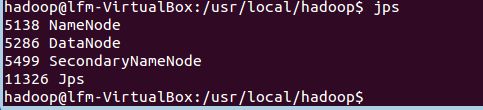
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
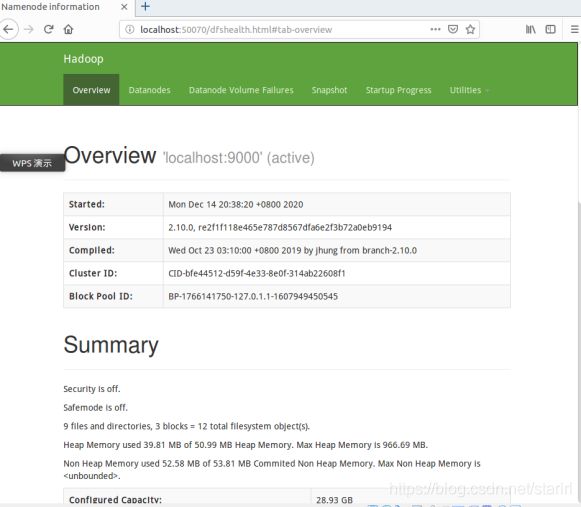
七、调用MapReduce执行WordCount对单词进行计数
1.准备
首先,准备一个不少于10000单词的文本文件,内容不限,可从各大英语文献网下载,将这个文件放置于hadoop文件夹中,以便实验。
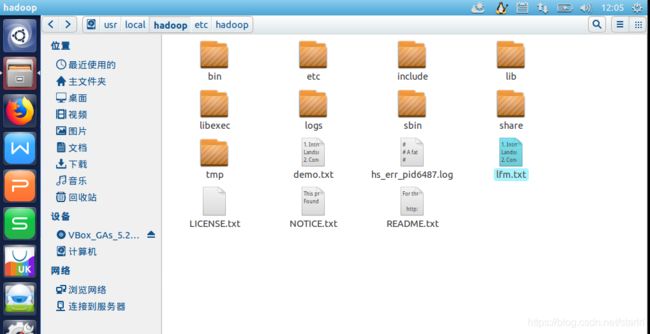
- 图中lfm.txt为实验文件
通过敲命令来创建input文件夹,并将demo.txt上传到input文件夹
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/lfm.txt input
使用ls命令来查看所上传的文件

2.安装Eclipse
在 Ubuntu 和 CentOS 中安装 Eclipse 的方式有所不同,但之后的配置和使用是一样的。
在 Ubuntu 中安装 Eclipse,可从 Ubuntu 的软件中心直接搜索安装,在桌面左侧任务栏,点击“Ubuntu软件中心”。

等待安装完成即可,Eclipse 的默认安装目录为:/usr/lib/eclipse。
3.Hadoop-Eclipse-Plugin的安装与设置
- 安装Hadoop-Eclipse-Plugin
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin,可下载 Github 上的 hadoop2x-eclipse-plugin(备用下载地址:http://pan.baidu.com/s/1i4ikIoP)。
下载后,将 release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar (还提供了 2.2.0 和 2.4.1 版本)复制到 Eclipse 安装目录的 plugins 文件夹中,运行 eclipse -clean 重启 Eclipse 即可(添加插件后只需要运行一次该命令,以后按照正常方式启动就行了)。
unzip -qo ~/下载/hadoop2x-eclipse-plugin-master.zip -d ~/下载 # 解压到 ~/下载 中
sudo cp ~/下载/hadoop2x-eclipse-plugin-master/release/hadoop-eclipse-plugin-2.6.0.jar /usr/lib/eclipse/plugins/ # 复制到 eclipse 安装目录的 plugins 目录下
/usr/lib/eclipse/eclipse -clean # 添加插件后需要用这种方式使插件生效
- 设置Hadoop-Eclipse-Plugin
在继续配置前请确保已经开启了 Hadoop。
hadoop的启动命令为:
cd /usr/local/hadoop
./sbin/start-dfs.sh
启动 Eclipse 后就可以在左侧的Project Explorer中看到 DFS Locations
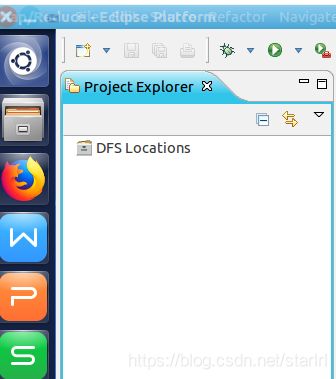
插件需要进一步的配置。
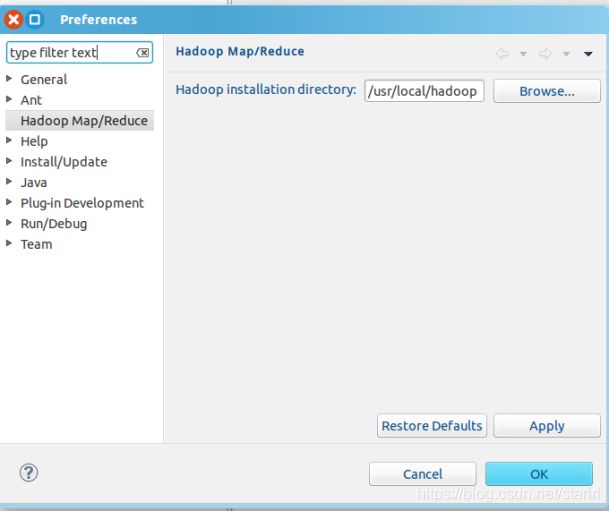
第一步:选择 Window 菜单下的 Preference,创建Hadoop Map/Reduce。
选择/usr/local/hadoop作为 Hadoop 的安装目录。
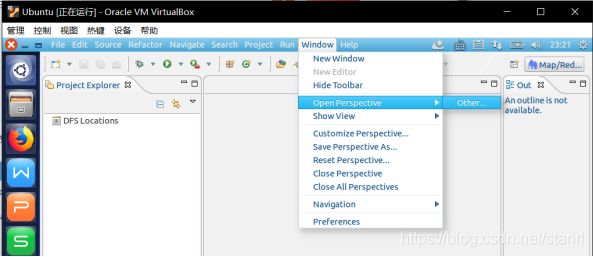
第二步:切换 Map/Reduce 开发视图,选择 Window 菜单下选择 Open Perspective -> Other
第三步:建立与 Hadoop 集群的连接,点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location。
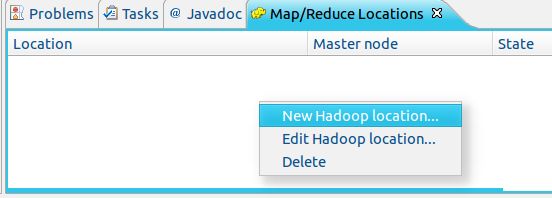
在弹出来的 General 选项面板中,General 的设置要与 Hadoop 的配置一致。一般在Location name里填MapReduce Locations,在port里填9000

当创建成功后,在Project Explorer在有以下显示
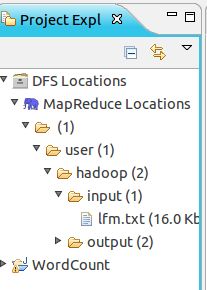
4.创建WordCount项目
- 首先,新建一个项目
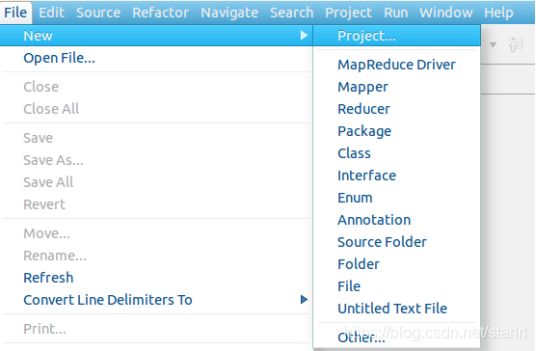
选择项目类型

填写项目名称
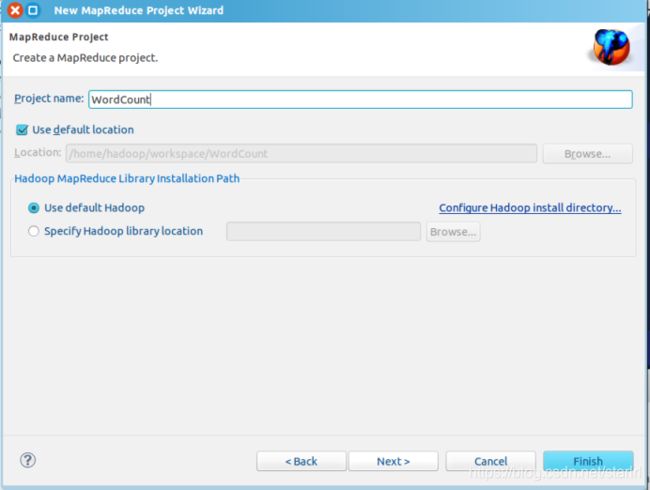
- 其次,接着右键点击刚创建的 WordCount 项目,选择 New -> Class
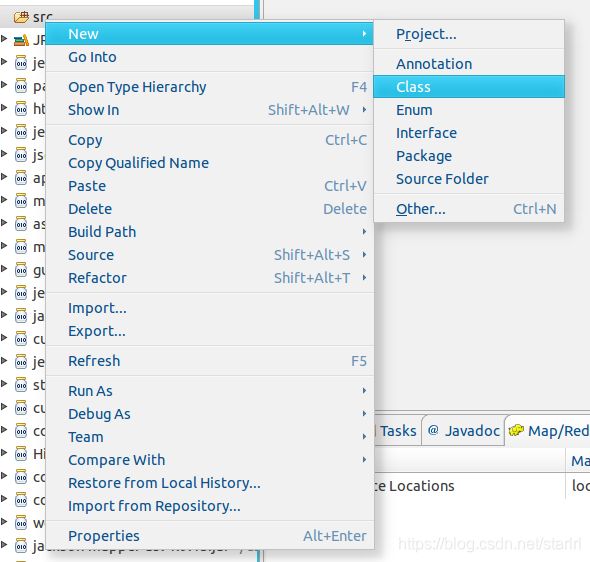
填写相关内容
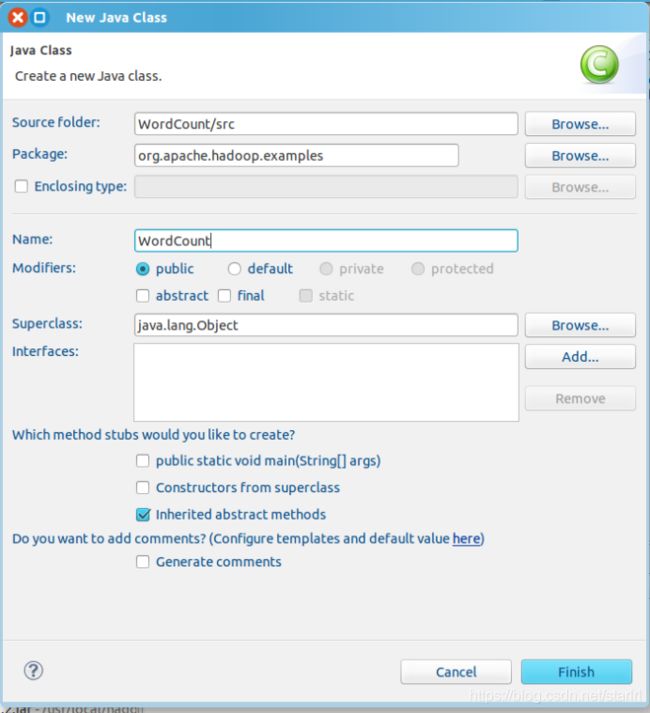
5.WordCount统计
- 当Class创建完成后,将下面代码复制进刚创建好的WordCount.java文件中
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs=new String[]{"input","output"};
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator<IntWritable> i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
- 通过 Eclipse 运行 MapReduce
在运行 MapReduce 程序前,还需要执行一项重要操作(也就是上面提到的通过复制配置文件解决参数设置问题):将 /usr/local/hadoop/etc/hadoop 中将有修改过的配置文件
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src
复制完成后,务必右键点击 WordCount 选择 refresh 进行刷新(不会自动刷新,需要手动刷新),可以看到文件结构如下所示:
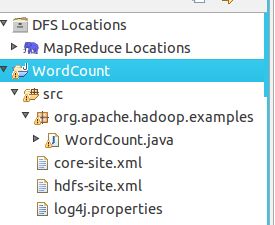
点击工具栏中的 Run 图标,或者右键点击 Project Explorer 中的 WordCount.java,选择 Run As -> Run on Hadoop,就可以运行 MapReduce 程序了。不过由于没有指定参数,运行时会提示 “Usage: wordcount “,需要通过Eclipse设定一下运行参数。
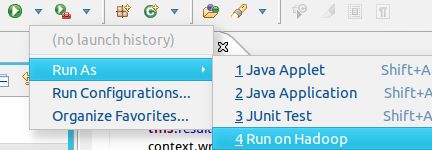
至于如何设定运行参数呢,首先右键点击刚创建的 WordCount.java,选择 Run As -> Run Configurations,在此处可以设置运行时的相关参数(如果 Java Application 下面没有 WordCount,那么需要先双击 Java Application)。切换到 “Arguments” 栏,在 Program arguments 处填写 “input output” 就可以了。
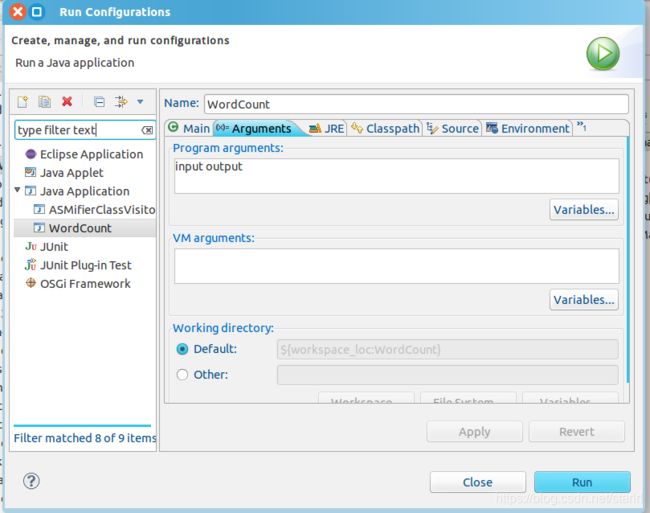
或者也可以直接在代码中设置好输入参数。可将代码 main() 函数的 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 改为:
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
String[] otherArgs=new String[]{
"input","output"}; /* 直接设置输入参数 */
设定参数后,再次运行程序,可以看到运行成功的提示,刷新 DFS Location 后也能看到输出的 output 文件夹。
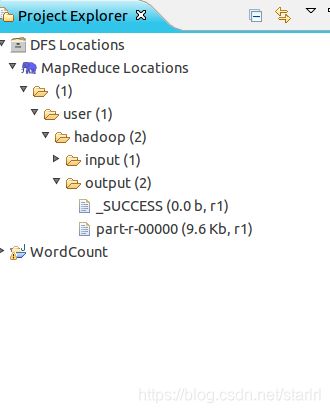
点击output文件夹里的part-r-00000可以查看统计结果

也可以通过命令来查看
cd /usr/local/haddop
./bin/hdfs dfs -cat output/part-r-00000
命令查看效果:
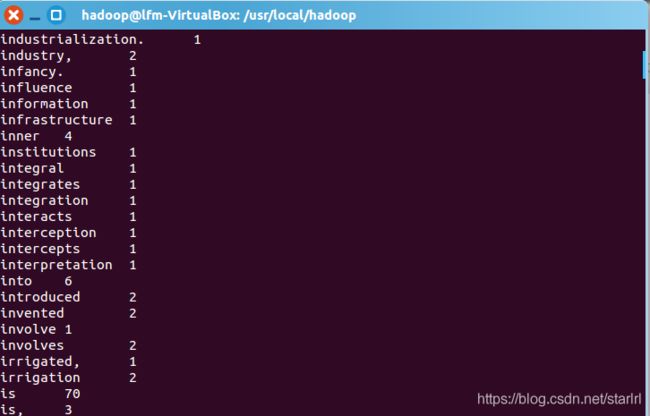
还可以命令将它下载下来
./bin/hdfs dfs -get output/part-r-00000 /home/hadoop/下载
下载效果:
八.参考材料
[1] http://dblab.xmu.edu.cn/blog/285/
[2] http://dblab.xmu.edu.cn/blog/290-2/
[3] http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/