Chapter 3 (General Random Variables): Conditioning (条件)
本文为 I n t r o d u c t i o n Introduction Introduction t o to to P r o b a b i l i t y Probability Probability 的读书笔记
目录
- Conditioning a Random Variable on an Event
- Conditioning one Random Variable on Another
- Conditional Expectation
- Independence
Conditioning a Random Variable on an Event
- The conditional PDF of a continuous random variable X X X, given an event A A A with P ( A ) > 0 P(A) > 0 P(A)>0, is defined as a nonnegative function f X ∣ A f_{X |A} fX∣A that satisfies
P ( X ∈ B ∣ A ) = ∫ B f X ∣ A ( x ) d x P(X\in B|A)=\int_Bf_{X|A}(x)dx P(X∈B∣A)=∫BfX∣A(x)dxfor any subset B B B of the real line. In particular, by letting B B B be the entire real line, we obtain the normalization property
∫ − ∞ ∞ f X ∣ A ( x ) d x = 1 \int_{-\infty}^\infty f_{X|A}(x)dx=1 ∫−∞∞fX∣A(x)dx=1 - In the important special case where we condition on an event of the form { X ∈ A } \{X\in A\} { X∈A}, with P ( X ∈ A ) > 0 P( X \in A)>0 P(X∈A)>0, the definition of conditional probabilities yields
P ( X ∈ B ∣ X ∈ A ) = P ( X ∈ B , X ∈ A ) P ( X ∈ A ) = ∫ A ∩ B f X ( x ) d x P ( X ∈ A ) P(X\in B|X\in A)=\frac{P(X\in B,X\in A)}{P(X\in A)}=\frac{\int_{A\cap B}f_X(x)dx}{P(X\in A)} P(X∈B∣X∈A)=P(X∈A)P(X∈B,X∈A)=P(X∈A)∫A∩BfX(x)dxBy comparing with the earlier formula, we conclude that
 As in the discrete case, the conditional PDF is zero outside the conditioning set. Within the conditioning set, the conditional PDF has exactly the same shape as the unconditional one, except that it is scaled by the constant factor 1 / P ( X ∈ A ) 1/P(X\in A) 1/P(X∈A), so that f X ∣ { X ∈ A } f_{X|\{X\in A\}} fX∣{ X∈A} integrates to 1; see Fig. 3.14. Thus, the conditional PDF is similar to an ordinary PDF, except that it refers to a new universe in which the event { X ∈ A } \{X\in A\} { X∈A} is known to have occurred.
As in the discrete case, the conditional PDF is zero outside the conditioning set. Within the conditioning set, the conditional PDF has exactly the same shape as the unconditional one, except that it is scaled by the constant factor 1 / P ( X ∈ A ) 1/P(X\in A) 1/P(X∈A), so that f X ∣ { X ∈ A } f_{X|\{X\in A\}} fX∣{ X∈A} integrates to 1; see Fig. 3.14. Thus, the conditional PDF is similar to an ordinary PDF, except that it refers to a new universe in which the event { X ∈ A } \{X\in A\} { X∈A} is known to have occurred.

Example 3.13. The Exponential Random Variable is Memoryless.
The time T T T until a new light bulb burns out is an exponential random variable with parameter λ \lambda λ. Ariadne turns the light on, leaves the room, and when she returns, t t t time units later, finds that the light bulb is still on, which corresponds to the event A = { T > t } A = \{T > t\} A={ T>t}. Let X X X be the additional time until the light bulb burns out. What is the conditional CDF of X X X, given the event A A A?
SOLUTION
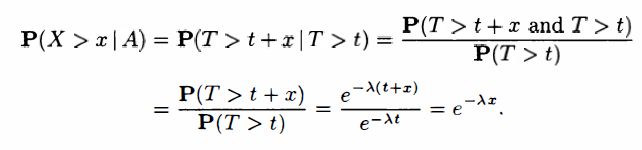
joint conditional PDF
- Suppose, for example, that X X X and Y Y Y are jointly continuous random variables, with joint PDF f X , Y f_{X,Y} fX,Y. If we condition on a positive probability event of the form C = { ( X , Y ) ∈ A } C=\{(X,Y)\in A\} C={ (X,Y)∈A}, we have

- In this case, the conditional PDF of X X X, given this event, can be obtained from the formula
f X ∣ C ( x ) = ∫ − ∞ ∞ f X , Y ∣ C ( x , y ) d y f_{X|C}(x)=\int_{-\infty}^\infty f_{X,Y|C}(x,y)dy fX∣C(x)=∫−∞∞fX,Y∣C(x,y)dyThese two formulas provide one possible method for obtaining the conditional PDF of a random variable X X X when the conditioning event is not of the form { X ∈ A } \{X\in A\} { X∈A}, but is instead defined in terms of multiple random variables.
- We finally note that there is a version of the total probability theorem which involves conditional PDFs: if the events A 1 , . . . , A n A_1, ... , A_n A1,...,An form a partition of the sample space, then
f X ( x ) = ∑ i = 1 n P ( A i ) f X ∣ A i ( x ) f_X(x)=\sum_{i=1}^nP(A_i)f_{X|A_i}(x) fX(x)=i=1∑nP(Ai)fX∣Ai(x) - To justify this statement, we use the total probability theorem and obtain
P ( X ≤ x ) = ∑ i = 1 n P ( A i ) P ( X ≤ x ∣ A i ) P(X\leq x)=\sum_{i=1}^nP(A_i)P(X\leq x|A_i) P(X≤x)=i=1∑nP(Ai)P(X≤x∣Ai)This formula can be rewritten as
∫ − ∞ x f X ( t ) d t = ∑ i = 1 n P ( A i ) ∫ − ∞ x f X ∣ A i ( t ) d t \int_{-\infty}^xf_X(t)dt=\sum_{i=1}^nP(A_i)\int_{-\infty}^xf_{X|A_i}(t)dt ∫−∞xfX(t)dt=i=1∑nP(Ai)∫−∞xfX∣Ai(t)dtWe then take the derivative of both sides, with respect to x x x, and obtain the desired result.
Example 3.14.
The metro train arrives at the station near your home every quarter hour starting at 6:00 a.m. You walk into the station every morning between 7:10 and 7:30 a.m., and your arrival time is a uniform random variable over this interval. What is the PDF of the time you have to wait for the first train to arrive?
SOLUTION
- Let X X X be the time of your arrival and Y Y Y be the waiting time. We calculate the PDF f Y f_Y fY using a divide-and-conquer strategy. Let A A A and B B B be the events

f Y ( y ) = P ( A ) f Y ∣ A ( y ) + P ( B ) f Y ∣ B ( y ) \begin{aligned}f_Y(y)&=P(A)f_{Y|A}(y)+P(B)f_{Y|B}(y) \end{aligned} fY(y)=P(A)fY∣A(y)+P(B)fY∣B(y)

- We have

Conditioning one Random Variable on Another
- Let X X X and Y Y Y be continuous random variables with joint PDF f X , Y f_{X,Y} fX,Y. For any y y y with f Y ( y ) > 0 f_Y(y) > 0 fY(y)>0 . the conditional PDF of X X X given that Y = y Y= y Y=y, is defined by
f X ∣ Y ( x ∣ y ) = f X , Y ( x , y ) f Y ( y ) f_{X|Y}(x|y)=\frac{f_{X,Y}(x,y)}{f_Y(y)} fX∣Y(x∣y)=fY(y)fX,Y(x,y)

- For the case of more than two random variables, there are natural extensions to the above. For example, we can define conditional PDFs by formulas such as

- To interpret the conditional PDF, let us fix some small positive numbers δ 1 \delta_1 δ1 and δ 2 \delta_2 δ2, and condition on the event B = { y ≤ Y ≤ y + δ 2 } B=\{y\leq Y\leq y+\delta_2\} B={ y≤Y≤y+δ2}. We have

- In words, f X ∣ Y ( x ∣ y ) δ 1 f_{X|Y}(x|y)\delta_1 fX∣Y(x∣y)δ1 provides us with the probability that X X X belongs to a small interval [ x , x + δ 1 ] [x,x+\delta_1] [x,x+δ1], given that Y Y Y belongs to a small interval [ y , y + δ 2 ] [y,y+\delta_2] [y,y+δ2]. Since f X ∣ Y ( x ∣ y ) δ 1 f_{X|Y}(x|y)\delta_1 fX∣Y(x∣y)δ1 does not depend on δ 2 \delta_2 δ2, we can think of the limiting case where δ 2 \delta_2 δ2 decreases to zero and write
P ( x ≤ X ≤ x + δ 1 ∣ Y = y ) ≈ f X ∣ Y ( x ∣ y ) δ 1 P(x\leq X\leq x+\delta_1|Y=y)\approx f_{X|Y}(x|y)\delta_1 P(x≤X≤x+δ1∣Y=y)≈fX∣Y(x∣y)δ1and, more generally,
P ( X ∈ A ∣ Y = y ) = ∫ A f X ∣ Y ( x ∣ y ) d x P(X\in A|Y=y)=\int_Af_{X|Y}(x|y)dx P(X∈A∣Y=y)=∫AfX∣Y(x∣y)dx - Conditional probabilities are given the zero probability event { Y = y } \{Y=y\} { Y=y}. But the above formula provides a natural way of defining such conditional probabilities. In addition, it allows us to view the conditional PDF f X ∣ Y ( x ∣ y ) f_{X|Y}(x|y) fX∣Y(x∣y) (as a function of x x x) as a description of the probability law of X X X, given that the event { Y = y } \{Y=y\} { Y=y} has occurred.
Example 3.16.
The speed of a typical vehicle that drives past a police radar is modeled as an exponentially distributed random variable X X X with mean 50 miles per hour. The police radar’s measurement Y Y Y of the vehicle’s speed has an error which is modeled as a normal random variable with zero mean and standard deviation equal to one tenth of the vehicle’s speed. What is the joint PDF of X X X and Y Y Y?
SOLUTION
- We have f X ( x ) = ( 1 / 50 ) e − x / 50 f_X(x) = (1/50)e^{-x/50} fX(x)=(1/50)e−x/50, for x ≥ 0 x\geq0 x≥0. Also, conditioned on X = x X = x X=x, the measurement Y Y Y has a normal PDF with mean x x x and variance x 2 / 100 x^2 /100 x2/100. Therefore,
f Y ∣ X ( y ∣ x ) = 1 2 π ( x / 10 ) e − ( y − x ) 2 / ( 2 x 2 / 100 ) f_{Y|X}(y|x) =\frac{1}{\sqrt{2\pi}(x/10)}e^{-(y-x)^2/(2x^2/100)} fY∣X(y∣x)=2π(x/10)1e−(y−x)2/(2x2/100)Thus, for all x ≥ 0 x\geq0 x≥0 and all y y y,
f X , Y ( x , y ) = f X ( x ) f Y ∣ X ( y ∣ x ) f_{X,Y}(x,y)=f_X(x)f_{Y|X}(y|x) fX,Y(x,y)=fX(x)fY∣X(y∣x)
Problem 34.
A defective coin minting machine produces coins whose probability of heads is a random variable P P P with PDF
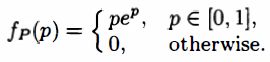 A coin produced by this machine is selected and tossed repeatedly, with successive tosses assumed independent. Find the probability that a coin toss results in heads.
A coin produced by this machine is selected and tossed repeatedly, with successive tosses assumed independent. Find the probability that a coin toss results in heads.
SOLUTION
- Let A A A be the event that the first coin toss resulted in heads. To calculate the probability P ( A ) P(A) P(A), we use the continuous version of the total probability theorem:
P ( A ) = ∫ 0 1 P ( A ∣ P = p ) f P ( p ) d p = ∫ 0 1 p 2 e p d p = e − 2 P(A) =\int_0^1P(A| P = p)f_P (p) dp =\int_0^1p^2e^p dp=e-2 P(A)=∫01P(A∣P=p)fP(p)dp=∫01p2epdp=e−2
Conditional Expectation
Let X X X snd Y Y Y be jointly continuous random variables, and let A A A be an event with P ( A ) > 0 P(A)>0 P(A)>0.
- Definitions: The conditional expectation of X X X given the event A A A is defined by
E [ X ∣ A ] = ∫ − ∞ ∞ x f X ∣ A ( x ) d x E[X|A]=\int_{-\infty}^\infty xf_{X|A}(x)dx E[X∣A]=∫−∞∞xfX∣A(x)dxThe conditional expectation of X X X given that Y = y Y = y Y=y is defined by
E [ X ∣ Y = y ] = ∫ − ∞ ∞ x f X ∣ Y ( x ∣ y ) d x E[X|Y=y]=\int_{-\infty}^\infty xf_{X|Y}(x|y)dx E[X∣Y=y]=∫−∞∞xfX∣Y(x∣y)dx - The expected value rule: For a function g ( X ) g(X) g(X), we have
E [ g ( X ) ∣ A ] = ∫ − ∞ ∞ g ( x ) f X ∣ A ( x ) d x E[g(X)|A]=\int_{-\infty}^\infty g(x)f_{X|A}(x)dx E[g(X)∣A]=∫−∞∞g(x)fX∣A(x)dxand
E [ g ( X ) ∣ Y = y ] = ∫ − ∞ ∞ g ( x ) f X ∣ Y ( x ∣ y ) d x E[g(X)|Y=y]=\int_{-\infty}^\infty g(x)f_{X|Y}(x|y)dx E[g(X)∣Y=y]=∫−∞∞g(x)fX∣Y(x∣y)dx - Total expectation theorem: Let A 1 , A 2 , . . . , A n A_1, A_2, ... , A_n A1,A2,...,An be disjoint events that form a partition of the sample space, and assume that P ( A i ) > 0 P(A_i) > 0 P(Ai)>0 for all i i i. Then,
E [ X ] = ∑ i = 1 n P ( A i ) E [ X ∣ A i ] E[X]=\sum_{i=1}^nP(A_i)E[X|A_i] E[X]=i=1∑nP(Ai)E[X∣Ai]Similarly,
E [ X ] = ∫ − ∞ ∞ E [ X ∣ Y = y ] f Y ( y ) d y E[X]=\int_{-\infty}^\infty E[X|Y=y]f_Y(y)dy E[X]=∫−∞∞E[X∣Y=y]fY(y)dy- To justify the first version of the total expectation theorem, we start with the total probability theorem
f X ( x ) = ∑ i = 1 n P ( A i ) f X ∣ A i ( x ) f_X(x)=\sum_{i=1}^nP(A_i)f_{X|A_i}(x) fX(x)=i=1∑nP(Ai)fX∣Ai(x)multiply both sides by x x x, and then integrate from − ∞ -\infty −∞ to ∞ \infty ∞. - To justify the second version of the total expectation theorem, we observe that

- To justify the first version of the total expectation theorem, we start with the total probability theorem
- There are natural analogs for the case of functions of several random variables. For example,
E [ g ( X , Y ) ∣ Y = y ] = ∫ g ( x , y ) f X ∣ Y ( x ∣ y ) d x E[g(X,Y)|Y=y]=\int g(x,y)f_{X|Y}(x|y)dx E[g(X,Y)∣Y=y]=∫g(x,y)fX∣Y(x∣y)dxand
E [ g ( X , Y ) ] = ∫ E [ g ( x , y ) ∣ Y = y ] f Y ( y ) d y E[g(X,Y)]=\int E[g(x,y)|Y=y]f_Y(y)dy E[g(X,Y)]=∫E[g(x,y)∣Y=y]fY(y)dy
- The total expectation theorem can often facilitate the calculation of the mean, variance, and other moments of a random variable, using a divide-and-conquer approach.
Example 3.17. Mean and Variance of a Piecewise Constant PDF.
- Suppose that the random variable X X X has the piecewise constant PDF

- Consider the events
 P ( A 1 ) = ∫ 0 1 f X ( x ) d x = 1 3 , P ( A 2 ) = ∫ 1 2 f X ( x ) d x = 2 3 E [ X ∣ A 1 ] = ∫ − ∞ ∞ x f X ∣ A 1 ( x ) d x = ∫ 0 1 x f X ( x ) P ( A 1 ) d x = ∫ 0 1 x d x = 1 2 E [ X 2 ∣ A 1 ] = ∫ − ∞ ∞ x 2 f X ∣ A 1 ( x ) d x = ∫ 0 1 x 2 f X ( x ) P ( A 1 ) d x = ∫ 0 1 x 2 d x = 1 3 E [ X ∣ A 2 ] = ∫ − ∞ ∞ x f X ∣ A 2 ( x ) d x = ∫ 1 2 x f X ( x ) P ( A 2 ) d x = ∫ 1 2 x d x = 3 2 E [ X 2 ∣ A 1 ] = ∫ − ∞ ∞ x 2 f X ∣ A 1 ( x ) d x = ∫ 1 2 x 2 f X ( x ) P ( A 1 ) d x = ∫ 1 2 x 2 d x = 7 3 P(A_1)=\int_0^1f_X(x)dx=\frac{1}{3},\ \ \ \ \ P(A_2)=\int_1^2f_X(x)dx=\frac{2}{3} \\E[X|A_1]=\int_{-\infty}^\infty xf_{X|A_1}(x)dx=\int_0^1x\frac{f_{X}(x)}{P(A_1)}dx=\int_0^1xdx=\frac{1}{2}\\ E[X^2|A_1]=\int_{-\infty}^\infty x^2f_{X|A_1}(x)dx=\int_0^1x^2\frac{f_{X}(x)}{P(A_1)}dx=\int_0^1x^2dx=\frac{1}{3} \\E[X|A_2]=\int_{-\infty}^\infty xf_{X|A_2}(x)dx=\int_1^2x\frac{f_{X}(x)}{P(A_2)}dx=\int_1^2xdx=\frac{3}{2}\\ E[X^2|A_1]=\int_{-\infty}^\infty x^2f_{X|A_1}(x)dx=\int_1^2x^2\frac{f_{X}(x)}{P(A_1)}dx=\int_1^2x^2dx=\frac{7}{3} P(A1)=∫01fX(x)dx=31, P(A2)=∫12fX(x)dx=32E[X∣A1]=∫−∞∞xfX∣A1(x)dx=∫01xP(A1)fX(x)dx=∫01xdx=21E[X2∣A1]=∫−∞∞x2fX∣A1(x)dx=∫01x2P(A1)fX(x)dx=∫01x2dx=31E[X∣A2]=∫−∞∞xfX∣A2(x)dx=∫12xP(A2)fX(x)dx=∫12xdx=23E[X2∣A1]=∫−∞∞x2fX∣A1(x)dx=∫12x2P(A1)fX(x)dx=∫12x2dx=37
P ( A 1 ) = ∫ 0 1 f X ( x ) d x = 1 3 , P ( A 2 ) = ∫ 1 2 f X ( x ) d x = 2 3 E [ X ∣ A 1 ] = ∫ − ∞ ∞ x f X ∣ A 1 ( x ) d x = ∫ 0 1 x f X ( x ) P ( A 1 ) d x = ∫ 0 1 x d x = 1 2 E [ X 2 ∣ A 1 ] = ∫ − ∞ ∞ x 2 f X ∣ A 1 ( x ) d x = ∫ 0 1 x 2 f X ( x ) P ( A 1 ) d x = ∫ 0 1 x 2 d x = 1 3 E [ X ∣ A 2 ] = ∫ − ∞ ∞ x f X ∣ A 2 ( x ) d x = ∫ 1 2 x f X ( x ) P ( A 2 ) d x = ∫ 1 2 x d x = 3 2 E [ X 2 ∣ A 1 ] = ∫ − ∞ ∞ x 2 f X ∣ A 1 ( x ) d x = ∫ 1 2 x 2 f X ( x ) P ( A 1 ) d x = ∫ 1 2 x 2 d x = 7 3 P(A_1)=\int_0^1f_X(x)dx=\frac{1}{3},\ \ \ \ \ P(A_2)=\int_1^2f_X(x)dx=\frac{2}{3} \\E[X|A_1]=\int_{-\infty}^\infty xf_{X|A_1}(x)dx=\int_0^1x\frac{f_{X}(x)}{P(A_1)}dx=\int_0^1xdx=\frac{1}{2}\\ E[X^2|A_1]=\int_{-\infty}^\infty x^2f_{X|A_1}(x)dx=\int_0^1x^2\frac{f_{X}(x)}{P(A_1)}dx=\int_0^1x^2dx=\frac{1}{3} \\E[X|A_2]=\int_{-\infty}^\infty xf_{X|A_2}(x)dx=\int_1^2x\frac{f_{X}(x)}{P(A_2)}dx=\int_1^2xdx=\frac{3}{2}\\ E[X^2|A_1]=\int_{-\infty}^\infty x^2f_{X|A_1}(x)dx=\int_1^2x^2\frac{f_{X}(x)}{P(A_1)}dx=\int_1^2x^2dx=\frac{7}{3} P(A1)=∫01fX(x)dx=31, P(A2)=∫12fX(x)dx=32E[X∣A1]=∫−∞∞xfX∣A1(x)dx=∫01xP(A1)fX(x)dx=∫01xdx=21E[X2∣A1]=∫−∞∞x2fX∣A1(x)dx=∫01x2P(A1)fX(x)dx=∫01x2dx=31E[X∣A2]=∫−∞∞xfX∣A2(x)dx=∫12xP(A2)fX(x)dx=∫12xdx=23E[X2∣A1]=∫−∞∞x2fX∣A1(x)dx=∫12x2P(A1)fX(x)dx=∫12x2dx=37 - We now use the total expectation theorem to obtain
E [ X ] = P ( A 1 ) E [ X ∣ A 1 ] + P ( A 2 ) E [ X ∣ A 2 ] = 7 6 E [ X 2 ] = P ( A 1 ) E [ X 2 ∣ A 1 ] + P ( A 2 ) E [ X 2 ∣ A 2 ] = 15 9 E[X]=P(A_1)E[X|A_1]+P(A_2)E[X|A_2]=\frac{7}{6} \\E[X^2]=P(A_1)E[X^2|A_1]+P(A_2)E[X^2|A_2]=\frac{15}{9} E[X]=P(A1)E[X∣A1]+P(A2)E[X∣A2]=67E[X2]=P(A1)E[X2∣A1]+P(A2)E[X2∣A2]=915The variance is given by
v a r ( X ) = E [ X 2 ] − ( E [ X ] ) 2 = 11 36 var(X)=E[X^2]-(E[X])^2=\frac{11}{36} var(X)=E[X2]−(E[X])2=3611
Independence
- Two continuous random variables X X X and Y Y Y are independent if their joint PDF is the product of the marginal PDFs
f X , Y ( x , y ) = f X ( x ) f Y ( y ) , f o r a l l x , y f_{X,Y}(x,y)=f_X(x)f_Y(y),\ \ \ \ \ for\ all\ x,y fX,Y(x,y)=fX(x)fY(y), for all x,y - There is a natural generalization to the case of more than two random variables. For example, we say that the three random variables X , Y X, Y X,Y, and Z Z Z are independent if
f X , Y , Z ( x , y , z ) = f X ( x ) f Y ( y ) f Z ( z ) , f o r a l l x , y , z f_{X,Y,Z}(x,y,z)=f_X(x)f_Y(y)f_Z(z),\ \ \ \ \ for\ all\ x,y,z fX,Y,Z(x,y,z)=fX(x)fY(y)fZ(z), for all x,y,z - If X X X and Y Y Y are independent, then any two events of the form { X ∈ A } \{X\in A\} { X∈A} and { Y ∈ B } \{Y\in B\} { Y∈B} are independent

- If any two events of the form { X ∈ A } \{X\in A\} { X∈A} and { Y ∈ B } \{Y\in B\} { Y∈B} are independent, then X X X and Y Y Y are independent
F X , Y ( x , y ) = P ( X ≤ x , Y ≤ y ) = P ( X ≤ x ) P ( Y ≤ y ) = F X ( x ) F Y ( y ) ∴ f X , Y ( x , y ) = ∂ 2 F X , Y ( x , y ) ∂ x ∂ y = f X ( x ) f Y ( y ) F_{X,Y}(x,y)=P(X\leq x, Y\leq y) = P(X\leq x) P(Y\leq y) = F_X(x)F_Y(y) \\\therefore f_{X,Y}(x,y)=\frac{\partial^2F_{X,Y}(x,y)}{\partial x\partial y}=f_X(x)f_Y(y) FX,Y(x,y)=P(X≤x,Y≤y)=P(X≤x)P(Y≤y)=FX(x)FY(y)∴fX,Y(x,y)=∂x∂y∂2FX,Y(x,y)=fX(x)fY(y) - In particular, independence implies that
F X , Y ( x , y ) = P ( X ≤ x , Y ≤ y ) = P ( X ≤ x ) P ( Y ≤ y ) = F X ( x ) F Y ( y ) F_{X,Y}(x,y) = P(X\leq x, Y\leq y) = P(X\leq x) P(Y\leq y) = F_X(x)F_Y(y) FX,Y(x,y)=P(X≤x,Y≤y)=P(X≤x)P(Y≤y)=FX(x)FY(y)This property can be used to provide a general definition of independence between two random variables. e.g., if X X X is discrete and Y Y Y is continuous. - An argument similar to the discrete case shows that if X X X and Y Y Y are independent, then
E [ g ( X ) h ( Y ) ] = E [ g ( X ) ] E [ h ( Y ) ] v a r ( X + Y ) = v a r ( X ) + v a r ( Y ) E[g(X)h(Y)]=E[g(X)]E[h(Y)] \\var(X+Y)=var(X)+var(Y) E[g(X)h(Y)]=E[g(X)]E[h(Y)]var(X+Y)=var(X)+var(Y)
Problem 22.
We have a stick of unit length, and we consider breaking it in three pieces using one of the following three methods. For each of the methods (i), (ii), and (iii), what is the probability that the three pieces we are left with can form a triangle?
- (i) We choose randomly and independently two points on the stick using a uniform PDF, and we break the stick at these two points.
- (ii) We break the stick at a random point chosen by using a uniform PDF, and then we break the piece that contains the right end of the stick, at a random point chosen by using a uniform PDF.
- (iii) We break the stick at a random point chosen by using a uniform PDF, and then we break the larger of the two pieces at a random point chosen by using a uniform PDF.
SOLUTION
- Define coordinates such that the stick extends from position 0 (the left end) to position 1 (the right end). Denote the position of the first break by X X X and the position of the second break by Y Y Y. With method (ii), we have X < Y X < Y X<Y. With methods (i) and (iii), we assume that X < Y X < Y X<Y and we later account for the case Y < X Y < X Y<X by using symmetry.
- Under the assumption X < Y X < Y X<Y, the three pieces form a triangle if
X < ( Y − X ) + ( 1 − Y ) ( Y − X ) < X + ( 1 − Y ) ( 1 − Y ) < X + ( Y − X ) X < (Y - X) + (1 - Y ) \\(Y-X) < X + (1 - Y ) \\(1 - Y ) < X + (Y - X) X<(Y−X)+(1−Y)(Y−X)<X+(1−Y)(1−Y)<X+(Y−X)These conditions simplify to
X < 0.5 ; Y > 0.5 ; Y − X < 0.5 X < 0.5;\ \ \ Y > 0.5;\ \ \ Y- X < 0.5 X<0.5; Y>0.5; Y−X<0.5 - Consider first method (i). For X X X and Y Y Y to satisfy these conditions, the pair ( X , Y ) (X, Y) (X,Y) must lie within the triangle with vertices ( 0 , 0.5 ) , ( 0.5 , 0.5 ) (0,0.5), (0.5, 0.5) (0,0.5),(0.5,0.5), and ( 0.5 , 1 ) (0.5, 1) (0.5,1). This triangle has area 1 / 8 1/8 1/8. Thus the probability of the event that the three pieces form a triangle a n d and and X < Y X < Y X<Y is 1 / 8 1/8 1/8. By symmetry, the probability of the event that the three pieces form a triangle and X > Y X > Y X>Y is 1 / 8 1/8 1/8. Since there two events are disjoint and form a partition of the event that the three pieces form a triangle, the desired probability is 1 / 4 1/4 1/4.
- Consider next method (ii). Since X X X is uniformly distributed on [ 0 , 1 ] [0, 1] [0,1] and Y Y Y is uniformly distributed on [ X , 1 ] [X, 1] [X,1], we have for 0 ≤ x ≤ y ≤ 1 0\leq x \leq y \leq 1 0≤x≤y≤1,
f X , Y ( x , y ) = f X ( x ) f Y ∣ X ( y ∣ x ) = 1 ⋅ 1 1 − x f_{X,Y}(x,y)=f_X(x)f_{Y|X}(y|x)=1\cdot\frac{1}{1-x} fX,Y(x,y)=fX(x)fY∣X(y∣x)=1⋅1−x1The desired probability is the probability of the triangle with vertices ( 0 , 0.5 ) , ( 0.5 , 0.5 ) (0, 0.5), (0.5, 0.5) (0,0.5),(0.5,0.5), and ( 0.5 , 1 ) (0.5, 1) (0.5,1):
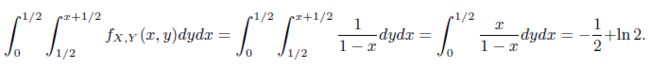
- Consider finally method (iii). Consider first the case X < 0.5 X < 0.5 X<0.5. Then the larger piece after the first break is the piece on the right. Thus, as in method (ii), Y Y Y is uniformly distributed on [ X , 1 ] [X, 1] [X,1] and the integral above gives the probability of a triangle being formed a n d and and X < 0.5 X < 0.5 X<0.5. Considering also the case X > 0.5 X > 0.5 X>0.5 doubles the probability, giving a final answer of − 1 + 2 l n 2 -1 + 2 ln 2 −1+2ln2
Problem 30. The Beta PDF.
- The beta PDF with parameters α > 0 \alpha > 0 α>0 and β > 0 \beta > 0 β>0 has the form

- The normalizing constant is
B ( α , β ) = ∫ 0 1 x α − 1 ( 1 − x ) β − 1 d x , B(\alpha,\beta)=\int_0^1x^{\alpha-1}(1-x)^{\beta-1}dx, B(α,β)=∫01xα−1(1−x)β−1dx,and is known as the Beta function. - (a) Show that for any m > 0 m > 0 m>0, the m m mth moment of X X X is given by
E [ X m ] = B ( α + m , β ) B ( α , β ) E[X^m]=\frac{B(\alpha+m,\beta)}{B(\alpha,\beta)} E[Xm]=B(α,β)B(α+m,β) - (b) Assume that α \alpha α and β \beta β are integer. Show that
B ( α , β ) = ( α − 1 ) ! ( β − 1 ) ! ( α + β − 1 ) ! B(\alpha,\beta)=\frac{(\alpha-1)!(\beta-1)!}{(\alpha+\beta-1)!} B(α,β)=(α+β−1)!(α−1)!(β−1)!so that
E [ X m ] = α ( α + 1 ) . . . ( α + m − 1 ) ( α + β ) ( α + β + 1 ) . . . ( α + β + m − 1 ) E[X^m]=\frac{\alpha(\alpha+1)...(\alpha+m-1)}{(\alpha+\beta)(\alpha+\beta+1)...(\alpha+\beta+m-1)} E[Xm]=(α+β)(α+β+1)...(α+β+m−1)α(α+1)...(α+m−1)
SOLUTION
(b)
- In the special case where α = 1 \alpha = 1 α=1 or β = 1 \beta=1 β=1, we can carry out the straightforward integration in the definition of B ( α , β ) B(\alpha , \beta) B(α,β), and verify the result.
- We will now deal with the general case. Let Y , Y 1 , . . . , Y α + β Y, Y_1, ... , Y_{\alpha+\beta} Y,Y1,...,Yα+β be independent random variables, uniformly distributed over the interval [ 0 , 1 ] [0, 1] [0,1], and let A A A be the event
A = { Y 1 ≤ . . . ≤ Y α ≤ Y ≤ Y α + 1 ≤ . . . ≤ Y α + β } A=\{Y_1\leq...\leq Y_\alpha\leq Y\leq Y_{\alpha+1}\leq...\leq Y_{\alpha+\beta}\} A={ Y1≤...≤Yα≤Y≤Yα+1≤...≤Yα+β}Then
P ( A ) = 1 ( α + β + 1 ) ! P(A)=\frac{1}{(\alpha+\beta+1)!} P(A)=(α+β+1)!1because all ways of ordering these α + β + 1 \alpha+\beta+1 α+β+1 random variables are equally likely. - Consider the following two events:
B = { m a x { Y 1 , . . . , Y α } ≤ Y } C = { Y ≤ m i n { Y α + 1 , . . . , Y α + β } } B=\{max\{Y_1,...,Y_\alpha\}\leq Y\}\\ C=\{Y\leq min\{Y_{\alpha+1},...,Y_{\alpha+\beta}\}\} B={ max{ Y1,...,Yα}≤Y}C={ Y≤min{ Yα+1,...,Yα+β}}We have, using the total probability theorem,
P ( B ∩ C ) = ∫ 0 1 P ( B ∩ C ∣ Y = y ) f Y ( y ) d y = ∫ 0 1 P ( m a x { Y 1 , . . . , Y α } ≤ y ≤ m i n { Y α + 1 , . . . , Y α + β } ) d y = ∫ 0 1 P ( m a x { Y 1 , . . . , Y α } ≤ y ) P ( y ≤ m i n { Y α + 1 , . . . , Y α + β } ) d y = ∫ 0 1 y α ( 1 − y ) β d y \begin{aligned}P(B\cap C)&=\int_0^1P(B\cap C|Y=y)f_Y(y)dy \\&=\int_0^1P(max\{Y_1,...,Y_\alpha\}\leq y\leq min\{Y_{\alpha+1},...,Y_{\alpha+\beta}\})dy \\&=\int_0^1 P(max\{Y_1,...,Y_\alpha\}\leq y)P(y\leq min\{Y_{\alpha+1},...,Y_{\alpha+\beta}\})dy \\&=\int_0^1y^\alpha(1-y)^\beta dy \end{aligned} P(B∩C)=∫01P(B∩C∣Y=y)fY(y)dy=∫01P(max{ Y1,...,Yα}≤y≤min{ Yα+1,...,Yα+β})dy=∫01P(max{ Y1,...,Yα}≤y)P(y≤min{ Yα+1,...,Yα+β})dy=∫01yα(1−y)βdy - We also have
P ( A ∣ B ∩ C ) = 1 α ! β ! P(A|B\cap C)=\frac{1}{\alpha!\beta!} P(A∣B∩C)=α!β!1because given the events B B B and C C C, all α ! \alpha! α! possible orderings of Y 1 , . . . , Y α Y_1, ... , Y_\alpha Y1,...,Yα are equally likely, and all β ! \beta! β! possible orderings of Y α + 1 , . . . , Y α + β Y_{\alpha+1},...,Y_{\alpha+\beta} Yα+1,...,Yα+β are equally likely. - By writing the equation
P ( A ) = P ( B ∩ C ) P ( A ∣ B ∩ C ) P(A)=P(B\cap C)P(A|B\cap C) P(A)=P(B∩C)P(A∣B∩C)in terms of the preceding relations, we finally obtain
B ( α , β ) = ∫ 0 1 x α − 1 ( 1 − x ) β − 1 d x = ( α − 1 ) ! ( β − 1 ) ! ( α + β − 1 ) ! B(\alpha,\beta)=\int_0^1x^{\alpha-1}(1-x)^{\beta-1}dx=\frac{(\alpha-1)!(\beta-1)!}{(\alpha+\beta-1)!} B(α,β)=∫01xα−1(1−x)β−1dx=(α+β−1)!(α−1)!(β−1)!