python与机器学习(七)上——PyTorch搭建LeNet模型进行MNIST分类
任务要求:利用PyTorch框架搭建一个LeNet模型,并针对MNIST数据集进行训练和测试。
数据集:MNIST
导入:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.nn import functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# %matplotlib inline
use_gpu = True if torch.cuda.is_available() else False
print('Use GPU:', use_gpu)
运行结果如下:
Use GPU: True
1. 数据集加载:
利用torchvision的datasets加载MNSIT数据集
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])]
)
batch_size = 64
train_dataset = datasets.MNIST(root='./data/', train=True, transform=transform, download=True)
print(train_dataset)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
train_num = len(train_dataset)
print('train image num:', train_num)
运行结果如下:
Dataset MNIST
Number of datapoints: 60000
Root location: ./data/
Split: Train
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=[0.5], std=[0.5])
)
train image num: 60000
test_dataset = datasets.MNIST(root='./data/', train=False, transform=transform, download=True)
print(test_dataset)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
test_num = len(test_dataset)
print('test image num:', test_num)
运行结果如下:
Dataset MNIST
Number of datapoints: 10000
Root location: ./data/
Split: Test
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=[0.5], std=[0.5])
)
test image num: 10000
2. LeNet模型构建:
利用PyTorch构建LeNet模型类
class LeNet(nn.Module):
''' 请在下方编写LeNet模型的代码 '''
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, 1,)
self.conv2 = nn.Conv2d(6, 16, 5, 1)
self.fc1 = nn.Linear(16*4*4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
#x:1*28*28
x = F.max_pool2d(self.conv1(x), 2, 2)
x = F.max_pool2d(self.conv2(x), 2, 2)
x = x.view(-1, 16*4*4)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return F.log_softmax(x,dim=1)
cnn = LeNet()
if use_gpu:
cnn = cnn.cuda()
print(cnn)
运行结果如下:
LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=256, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
3. 优化器和损失函数:
定义优化器(SGD/Adam)和交叉熵损失函数
# 优化器
import torch.optim as optim
# ''' 请在下方编写优化器定义代码 '''
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.001, betas=(0.9, 0.99))
print(optimizer)
# output = cnn(data)
from torch.nn import functional as F
# 损失函数
# ''' 请在下方编写损失函数定义代码 '''
criterion = nn.CrossEntropyLoss(size_average=False)
# loss = F.cross_entropy(output,target) #交叉熵损失函数
print(criterion)
运行结果如下:
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.99)
eps: 1e-08
lr: 0.001
weight_decay: 0
)
CrossEntropyLoss()
4. 模型训练和测试:
模型训练函数(要求间隔记录输出损失函数及正确率)
# 训练CNN模型
def train(epoch):
cnn.train()
train_loss = 0
correct = 0
for batch_idx, (data, label) in enumerate(train_loader):
''' 请在下方编写计算损失函数、预测正确数、误差反向传播、梯度更新相关代码 '''
output = cnn(data)
optimizer.zero_grad()
loss = criterion(output,label)
loss.backward()
optimizer.step() #相当于更新权重值
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(label.view_as(pred)).sum().item()
# 输出训练阶段loss信息
train_loss += loss.item()
train_loss_list.append(loss.item())
if batch_idx % 200 == 0:
print('Train Epoch: {} [{:05d}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), train_num,
100 * batch_idx * len(data) / train_num, loss.item()))
train_loss /= train_num
accuracy = correct / train_num
train_acc_list.append(accuracy)
# 输出训练阶段loss信息
print('Train Epoch: {}\tAverage loss: {:.4f}\tAccuracy: {}/{} ({:.2f}%)'.format(
epoch, train_loss, correct, train_num, 100.0 * accuracy))
模型测试函数(要求间隔记录输出损失函数及正确率)
# 测试CNN模型
def test():
cnn.eval()
test_loss = 0
correct = 0
for data, label in test_loader:
if use_gpu: # 使用GPU
data, label = Variable(data).cuda(), Variable(label).cuda()
''' 请在下方编写计算损失函数、预测正确数相关代码 '''
output = cnn(data)
loss = criterion(output, label) # 将一批的损失相加
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(label.view_as(pred)).sum().item()
test_loss += loss.item()
test_loss_list.append(loss.item())
test_loss /= test_num
accuracy = correct / test_num
test_acc_list.append(accuracy)
# 输出测试阶段loss信息
print('Test Epoch: {}\tAverage loss: {:.4f}\tAccuracy: {}/{} ({:.2f}%)\n'.format(
epoch, test_loss, correct, test_num, 100.0 * accuracy))
train_loss_list = []
test_loss_list = []
train_acc_list = []
test_acc_list = []
epoch_num = 10
for epoch in range(1, epoch_num+1):
# 每轮训练完测试
train(epoch)
test()
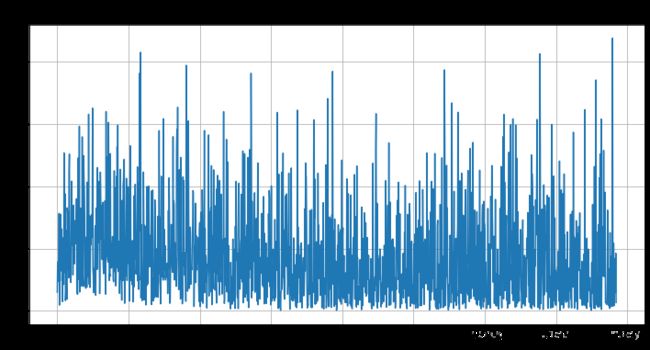
5. 损失函数和正确率曲线:
训练损失函数图 & 测试损失函数图 & 训练/测试正确率图
plt.figure(figsize=(12,6))
plt.plot(train_loss_list)
plt.title('train loss', fontsize=18)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.grid()
plt.show()
plt.figure(figsize=(12,6))
plt.plot(test_loss_list)
plt.title('test loss', fontsize=18)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.grid()
plt.show()
plt.figure(figsize=(12,8))
plt.plot(train_acc_list, 'o-')
plt.plot(test_acc_list, 'o-')
plt.title('Accuracy', fontsize=18)
plt.xlabel('Epoch', fontsize=16)
plt.ylabel('Accuracy', fontsize=16)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.legend(['Train', 'Test'], fontsize=16)
plt.grid()
plt.show()
运行结果如下: