机器学习模型评估指标汇总
在使用机器学习算法中,针对不同的问题需要用不同的模型评估标准,这里统一汇总并结合自己的理解进行阐述。主要以两大类:分类与回归
一、分类问题
混淆矩阵
混淆矩阵是ROC曲线绘制的基础,同时也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。
一句话解释版本:
混淆矩阵就是分别统计分类模型归错类、归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵。
混淆矩阵的定义
混淆矩阵(confusion matrix),它的本质远没有它的名字听上去那么拉风。矩阵,可以理解为就是一张表格,混淆矩阵其实就是一张表格而已。
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。
我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是positive,哪些结果是negative。同时,我们通过用样本数据跑出分类型模型的结果,也可以知道模型认为这些数据哪些是positive,哪些是negative。
因此,我们就能得到这样四个基础指标,我称他们是一级指标(最底层的):
- 真实值是positive,模型认为是positive的数量(True Positive=TP)
- 真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第二类错误(Type II Error)
- 真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第一类错误(Type I Error)
- 真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):

混淆矩阵的指标
预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。所以当我们得到了模型的混淆矩阵后,就需要去看有多少观测值在第二、四象限对应的位置,这里的数值越多越好;反之,在第一、三象限对应位置出现的观测值肯定是越少越好。
二级指标
但是,混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。因此混淆矩阵在基本的统计结果上又延伸了如下4个指标,我称他们是二级指标(通过最底层指标加减乘除得到的):
- 准确率(accuracy)——针对整个模型
- 精确率(precision)
- 灵敏度/召回率(sensitivity/recall)
- 特异度(specificity)
用表格的方式将这四种指标的定义、计算、理解进行了汇总:
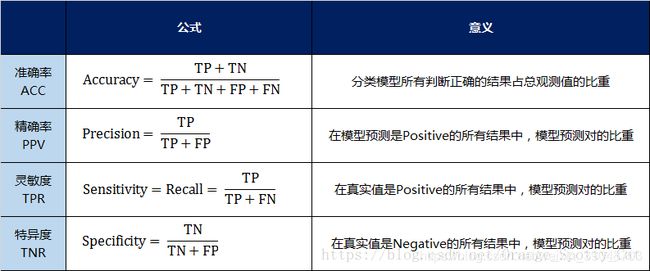
通过上面的四个二级指标,可以将混淆矩阵中数量的结果转化为0-1之间的比率。便于进行标准化的衡量。
在这四个指标的基础上进行拓展,会产生另一个三级指标
实际上非常简单,精确率(precision)是针对我们的预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。
而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。
一般情况下,我们都希望的是这两个指标越高越好,然而不太现实,存在一定的矛盾,故引出了F1 Score。
三级指标
这个指标叫做F1 Score。他的计算公式是:

其中,P代表Precision,R代表Recall。
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
混淆矩阵的实例说明
当分类问题是二分问题是,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同时适用。
一下面的混淆矩阵为例,我们的模型目的是为了预测样本是什么动物,这是我们的结果:

通过混淆矩阵,我们可以得到如下结论:
Accuracy
在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
以猫为例,我们可以将上面的图合并为二分问题:

Precision
所以,以猫为例,模型的结果告诉我们,66只动物里有13只是猫,但是其实这13只猫只有10只预测对了。模型认为是猫的13只动物里,有1条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
Recall
以猫为例,在总共18只真猫中,我们的模型认为里面只有10只是猫,剩下的3只是狗,5只都是猪。这5只八成是橘猫,能理解。所以,Recall(猫)= 10/18 = 55.6%
Specificity
以猫为例,在总共48只不是猫的动物中,模型认为有45只不是猫。所以,Specificity(猫)= 45/48 = 93.8%。
虽然在45只动物里,模型依然认为错判了6只狗与4只猫,但是从猫的角度而言,模型的判断是没有错的。
F1-Score
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
ROC曲线与AUC面积
简介
ROC曲线与AUC面积均是用来衡量分类准确度的工具。可以用来回答这样的问题:
- 分类模型的预测到底准不准确?
- 我们建出模型的错误率有多大?正确率有多高?
- 两个不同的分类模型中,哪个更好用?哪个更准确?
一句话概括:
ROC是一条线,如果我们选择用ROC曲线评判模型的准确性,那么越靠近左上角的ROC曲线,模型的准确度越高,模型越理想;
AUC是线下面积,如果我们选择用AUC面积评判模型的准确性,那么模型的AUC面积值越大,模型的准确度越高,模型越理想;
ROC曲线的定义
ROC曲线全称为受试者工作特征曲线(receiver operating characteristic curve)。说直白点就是通过曲线来判断模型的好坏。
而该曲线的横坐标代表的是“false positive rate”,而纵坐标写着“ture positive rate”。
ROC曲线的计算
ROC曲线的横轴与纵轴,与混淆矩阵(Confusion Matrix)有着密切的关系,具体的理解请详见混淆矩阵篇的讲解。
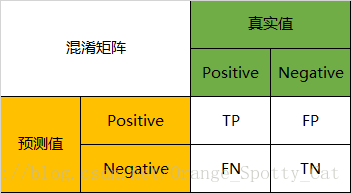
横纵坐标的计算都与混淆矩阵有着密切的关系
横轴(False positive rate)的计算:
横轴FPR可以理解为:在所有真实值为negative的数据中,被模型错误的判断为positive的比例。其计算公式为:

纵轴(ture positive rate)的计算:
纵轴TPR可以被理解为:在所有真实值为positive的数据中,被模型正确的判断为positive的比例。其计算公式为:
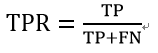
ROC曲线的解读
FPR与TPR分别构成了ROC曲线的横纵轴,因此我们知道在ROC曲线中,每一个点都对应着模型的一次结果。
- 如果ROC曲线完全在纵轴上,代表这一点上,x=0,即FPR=0 。模型没有把任何negative的数据错误的判为positive,预测完全正确。
- 如果ROC曲线完全在横轴上,代表这一点上,y=0,即TPR=0。模型没有把任何positive的数据正确的判断为positive,预测完全不准确。
- 所以如果ROC曲线完全与右上方45度倾角线重合,证明模型的准确率是正好50%,错判的几率是一半一半。
因此,我们绘制出来ROC曲线的形状,是希望TPR大,而FPR小。因此对应在图上就是曲线尽量往左上角贴近。45度的直线一般被常用作Benchmark,即基准模型,我们的预测分类模型的ROC要能优于45度线,否则我们的预测还不如50/50的猜测来的准确。
AUC的定义与解读
AUC的英文叫做Area Under Curve,即曲线下的面积,不能再直白。它就是值ROC曲线下的面积是多大。每一条ROC曲线对应一个AUC值。AUC的取值在0与1之间。
- AUC = 1,代表ROC曲线在纵轴上,预测完全准确。不管Threshold选什么,预测都是100%正确的。
- 0.5 < AUC < 1,代表ROC曲线在45度线上方,预测优于50/50的猜测。需要选择合适的阈值后,产出模型。
- AUC = 0.5,代表ROC曲线在45度线上,预测等于50/50的猜测。
- 0 < AUC < 0.5,代表ROC曲线在45度线下方,预测不如50/50的猜测。
- AUC = 0,代表ROC曲线在横轴上,预测完全不准确。
二、回归问题
1.均方误差
(mean squared error,mse)
观测值与真值偏差的平方和与观测次数的比值:

这就是线性回归中最常用的损失函数,线性回归过程中尽量让该损失函数最小。那么模型之间的对比也可以用它来比较。
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
2.均方根误差(标准误差)
(root mean squard error,RMSE)
标准差是方差的算术平方根。
标准误差是均方误差的算术平方根。
标准差是用来衡量一组数自身的离散程度,而均方根误差是用来衡量观测值同真值之间的偏差,它们的研究对象和研究目的不同,但是计算过程类似。
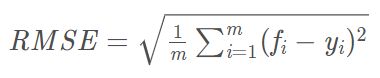
它的意义在于开个根号后,误差的结果就与数据是一个级别的,可以更好地来描述数据。标准误差对一组测量中的特大或特小误差反映非常敏感,所以,标准误差能够很好地反映出测量的精密度。这正是标准误差在工程测量中广泛被采用的原因。
3.平均绝对误差
(mean absolute error,MAE)
平均绝对误差是绝对误差的平均值:
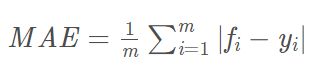
平均绝对误差能够更好地反映预测值误差的实际情况。