Spark学习-2.4.0-源码分析-3-Spark 核心篇-Spark Submit任务提交
文章目录
- 1. 概述
- 2. Spark应用程序执行流程简介
- 3. Spark Submit任务提交流程详解
-
-
- 3.1 第一步,编写用户脚本并用Spark-Submit提交
-
-
- 3.1.1 用户脚本内容
- 3.1.2 命令行日志
-
- 3.1.3 Spark-Submit脚本分析
-
-
- 4. SparkSubmit源码详解
- 5. 提交网关 :“RestSubmissionClient” && “Client”
-
-
- 5.1 RestSubmissionClientApp申请注册Driver详解
- 5.2 ClientApp申请注册Driver详解
- 5.3 Master接收消息并注册
-
- 致谢
1. 概述
本文介绍Spark应用程序提交的第一步: 使用Spark Submit提交应用。本文将从spark提交的脚本开始,逐步分析脚本内容,脚本执行后的命令行输出,然后开始分析源码(SparkSubmit、RestSubmissionClientApp、ClientApp),从而较为完整的描述Spark-Submit任务提交的流程,提交过程中会向Master去注册Driver,然后便是等待Master返回Driver的注册结果。Driver的启动、注册请移驾:Driver的注册与启动。
2. Spark应用程序执行流程简介
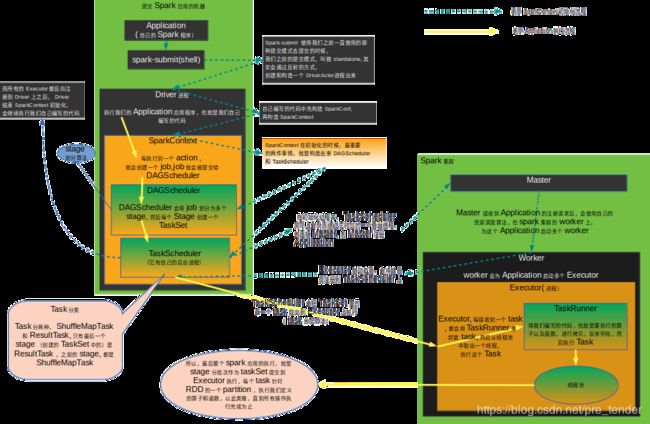
Spark引用程序在集群上以独立的进程集运行,其运行时候涉及的组件及关系如下:

-
用户提交编写的程序(作为Driver程序)初始化SparkContext对象,SparkContext负责协调应用程序在集群上运行
-
想要在集群上运行, SparkContext需要连接到集群管理器Cluster Manager,申请资源,注册Application
- 集群管理器有多种:Spark独立集群管理器,即Standalone,除此之外还有Mesos、YARN - 集群管理器负责在应用程序之间分配资源 -
连接到集群管理器后,根据申请的资源,在集群中的Worker节点上创建Executor
-
创建好Executor后,Executor将信息发送给Driver
-
SparkContext初始化过程中创建并启动DAGScheduler将用户编写的程序转化为Task任务,将Task任务发送给指定Executor,进行任务计算
-
将Task计算结果返回Driver,Spark任务计算完毕,一系列处理关闭Spark任务。
注册和任务执行 架构流程图 如下所示:
3. Spark Submit任务提交流程详解
3.1 第一步,编写用户脚本并用Spark-Submit提交
官方介绍如何提交应用程序
3.1.1 用户脚本内容
在可执行脚本中,内容大致如下:
|
|
|
|
|---|---|---|
./bin/spark-submit \ |
使用$SPARK_HOME/bin目录下的 spark-submit 脚本去提交用户的程序 |
./bin/spark-submit \ |
--class |
应用程序的入口 | –class org.apache.spark.examples.SparkPi \ |
--master |
master地址,这是集群中master的URL地址 | –master spark://192.168.1.20:7077 \ |
--deploy-mode |
部署模式,是否将用户的Driver程序 部署到集群的Worker节点(cluster集群模式) ,或将本地作为外部client客户端 模式(默认为client客户端模式) |
–deploy-mode cluster \ |
--conf |
spark 配置,键-值对形式 | –supervise \ --executor-memory 2G \ --total-executor-cores 5 \ |
... # other options |
其他配置项 | |
|
用户程序Jar包路径 | /path/to/examples.jar \ |
[application-arguments] |
用户应用程序所需参数 | 1000 |
3.1.2 命令行日志
日志来源:http://www.louisvv.com/archives/1340.html
[root@louisvv bin]# ./spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.1.20:7077 --deploy-mode cluster --executor-memory 2G --total-executor-cores 5 ../examples/jars/spark-examples_2.11-2.1.0.2.6.0.3-8.jar 1000
Running Spark using the REST application submission protocol.
18/04/19 17:03:29 INFO RestSubmissionClient: Submitting a request to launch an application in spark://192.168.1.20:7077.
18/04/19 17:03:40 WARN RestSubmissionClient: Unable to connect to server spark://192.168.1.20:7077.
Warning: Master endpoint spark://192.168.1.20:7077 was not a REST server. Falling back to legacy submission gateway instead.
这里面有一个WARN,说spark://192.168.1.20:7077不是一个REST服务,使用传统的提交网关
3.1.3 Spark-Submit脚本分析
从Spark-submit这个脚本作为入口,脚本最后调用exec执行 “ S P A R K H O M E ” / b i n / s p a r k − c l a s s 调 用 c l a s s 为 : o r g . a p a c h e . s p a r k . d e p l o y . S p a r k S u b m i t “ {SPARK_HOME}”/bin/spark-class 调用class为:org.apache.spark.deploy.SparkSubmit “ SPARKHOME”/bin/spark−class调用class为:org.apache.spark.deploy.SparkSubmit“@”为脚本执行的上面的所有参数
`Spark-submit部分内容:`
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi # disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
spark-class脚本执行步骤:
- 首先校验
$SPARK_HOME/conf,spark相关依赖目录$SPARK_HOME/jars,hadoop相关依赖目录$HADOOP_HOEM/lib - 将校验所得所有目录地址拼接为
LAUNCH_CLASSPATH变量 - 将
$JAVA_HOME/bin/java定义为RUNNER变量 - 调用
build_command()方法,创建执行命令 - 把
build_command()方法创建的命令,循环加到数组CMD中,最后执行exec执行CMD命令
#-z 判断SPARK_HOME变量的长度是否为0,等于0为真
if [ -z "${SPARK_HOME}" ]; then
#加载当前目录的find...的变量
source "$(dirname "$0")"/find-spark-home
fi
#加载这个文件的变量
. "${SPARK_HOME}"/bin/load-spark-env.sh
# Find the java binary
#-n 判断变量长度是否不为0,不为0为真
if [ -n "${JAVA_HOME}" ]; then
#JAVAHOME存在就赋值RUNNER为这个
RUNNER="${JAVA_HOME}/bin/java"
else
#监测java命令是否存在
if [ "$(command -v java)" ]; then
RUNNER="java"
else
#不存在退出
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find Spark jars.
#判断${SPARK_HOME}/jars目录是否存在,存在为真
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
#判断下边俩,不都存在就报错退出
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
#存在就变量赋值
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
HADOOP_LZO_JAR=
HADOOP_LZO_DIR="/usr/hdp/${HDP_VERSION}/hadoop/lib"
#获取那个目录下匹配hadoop-lzo.*${HDP_VERSION}\.jar的jar包数量
num_jars="$(ls -1 "$HADOOP_LZO_DIR" | grep "^hadoop-lzo.*${HDP_VERSION}\.jar$" | wc -l)"
#如果数量为0,把那个变量弄为空
if [ "$num_jars" -eq "0" -a -z "$HADOOP_LZO_JAR" ]; then
HADOOP_LZO_JAR=
#大于1报错退出
elif [ "$num_jars" -gt "1" ]; then
echo "Found multiple Hadoop lzo jars in $HADOOP_LZO_DIR:" 1>&2
echo "Please remove all but one jar." 1>&2
exit 1
#等于1赋值
elif [ "$num_jars" -eq "1" ]; then
LZO_JARS="$(ls -1 "$HADOOP_LZO_DIR" | grep "^hadoop-lzo-.*${HDP_VERSION}\.jar$" || true)"
HADOOP_LZO_JAR="${HADOOP_LZO_DIR}/${LZO_JARS}"
fi
export _HADOOP_LZO_JAR="${HADOOP_LZO_JAR}"
# Add the launcher build dir to the classpath if requested.
#这变量长度大于1赋值
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
# For tests
#这变量长度大于1 unset目录权限
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi
build_command() {
#执行命令获取
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
#输出返回值
printf "%d\0" $?
}
#创建数组
CMD=()
#把build_commands输出结果,循环加到数组CMD中
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
#数组长度
COUNT=${#CMD[@]}
#数组长度-1
LAST=$((COUNT - 1))
#数组的最后一个值,也就是上边$?的值
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
#如果返回值不是数字,退出
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fi
#如果返回值不为0,退出,返回返回值
if [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fi
#CMD还是原来那些参数,$@
CMD=("${CMD[@]:0:$LAST}")
#执行这些
exec "${CMD[@]}"
最终执行的CMD命令如下:
/opt/jdk1.8/bin/java -Dhdp.version=2.6.0.3-8 -cp /usr/hdp/current/spark2-
historyserver/conf/:/usr/hdp/2.6.0.3-8/spark2/jars/*:/usr/hdp/cur
rent/hadoop-client/conf/org.apache.spark.deploy.SparkSubmit \
--master spark://192.168.1.20:7077 \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--executor-memory 2G \
--total-executor-cores 5 \
../examples/jars/spark-examples_2.11-2.1.0.2.6.0.3-8.jar \
1000
4. SparkSubmit源码详解
因为在最终执行的命令(exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@")之中,指定了程序的入口为org.apache.spark.deploy.SparkSubmit,
因此在Spark-Submit提交应用程序之后,接下来便是分析SparkSubmit源码中的执行逻辑和流程。
在Object SparkSubmit中,main(args)函数执行流程为:
- 创建一个
匿名的SparkSubmit的匿名子类:在子类中重写了parseArguments() 和doSubmit()等 - 创建submit对象:用这个匿名子类,创建一个名为
submit的对象。 - 用
submit.doSubmit(args)进行提交。(这里的args就是用户脚本中的所有参数,详情见3.1.3 Spark-Submit脚本分析) - doSubmit()先会调用
val appArgs = parseArguments(args)去new一个SparkSubmitArguments对象并返回。(这个对象会先解析用户脚本中的参数并存储之后再返回) - 用
appArgs.action进行模式匹配(SUBMIT、KILL、REQUEST_STATUS、PRINT_VERSION) - 对于模式
SUBMIT,如果匹配成功,调用submit(appArgs)方法(这里的argsArgs是doSubmit()中创建的,而不是main(args)中的),submit执行逻辑如下:
- 6.1 首先调用prepareSubmitEnvironment()方法,准备submit环境。
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
– 6.1.1.根据参数中master和delpoy-mode,设置对应的clusterManager和部署模式
– 6.1.2.再根据args中的其他参数,设置相关childArgs, childClasspath, sysProps, childMainClass,并返回结果
- 6.2 prepareSubmitEnvironment()完成后,需要判断是否为Standalone Cluster模式和是否设置了useRest
– 6.2.1.如果args.isStandaloneCluster && args.useRest 为true,调用doRunMain()方法,并提供一个故障转移以使用传统网关的处理。(关于网关,参见本文第五节 提交网关 :“RestSubmissionClient” && “Client”)
– 6.2.2.如果为false,直接调用doRunMain方法。它其实调用了runMain()方法
— 1st 使用URLClassLoader加载jar包。
— 2nd 加载Jar包后,从中获取mainClass的main方法。
— 3rd 利用mainClass创建一个app 。 (app的类型SparkApplication,但实际上是RestSubmissionClientApp 或者 ClientApp
— 4th 调用app.start()开始切换到应用程序的注册和执行。
(在RestSubmissionClient的start()->run()->createSubmission()->postJson()或者Client的onStart()方法中,均实现了向Master注册Driver) - 至此,SparkSubmit类中的操作已经完结,接下来是Driver向Master注册,而这部分是在
RestSubmissionClient或者Client中完成的
在独立群集模式下,有两个提交网关:
(1)使用o.a.s.deploy.Client作为包装器的传统RPC网关。
(2)Spark 1.3中引入的基于REST的新网关
后者是Spark 1.3的默认行为,但如果`主端点不是REST服务器,Spark提交将故障转移以使用旧网关。
在上面执行spark-submit 提交SparkPi任务时,报出的WARN,就是在提交网关这里
部分源码如下:
Object SparkSubmit的 main()函数:
override def main(args: Array[String]): Unit = {
val submit = new SparkSubmit() {
//这是SparkSubmit的一个匿名子类
self =>
override protected def parseArguments(args: Array[String]): SparkSubmitArguments = {
// SparkSubmitArguments继承自SparkSubmitArgumentsParser,会对提交参数进行解析
new SparkSubmitArguments(args) {
override protected def logInfo(msg: => String): Unit = self.logInfo(msg)
override protected def logWarning(msg: => String): Unit = self.logWarning(msg)
}
}
override protected def logInfo(msg: => String): Unit = printMessage(msg)
override protected def logWarning(msg: => String): Unit = printMessage(s"Warning: $msg")
override def doSubmit(args: Array[String]): Unit = {
try {
super.doSubmit(args)
} catch {
case e: SparkUserAppException =>
exitFn(e.exitCode)
}
}
}
submit.doSubmit(args)
}
-----------------------------------------------------------------------------------
Class SparkSubmit中的函数
# 第一步 submit.doSubmit(args)
def doSubmit(args: Array[String]): Unit = {
// Initialize logging if it hasn't been done yet. Keep track of whether logging needs to
// be reset before the application starts.
val uninitLog = initializeLogIfNecessary(true, silent = true)
//doSubmit()先会调用`val appArgs = parseArguments(args)`去new一个SparkSubmitArguments对象并返回。
//这里的args就是用户脚本中的所有参数
val appArgs = parseArguments(args) //这里会
if (appArgs.verbose) {
logInfo(appArgs.toString)
}
//用`appArgs.action`进行模式匹配`(SUBMIT、KILL、REQUEST_STATUS、PRINT_VERSION)
//对于模式`SUBMIT`,如果匹配成功,调用`submit(appArgs)`方法
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
# 第二步 submit(appArgs, uninitLog)
**这分两步进行。
* 首先,我们通过设置适当的类路径,系统属性和应用程序参数来准备启动环境,以便根据集群管理器和部署模式运行子主类。
* 其次,我们使用此启动环境来调用子主类的main方法,doRunMain()-> runMain()-> app.start() 。
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
//准备启动环境
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
// Let the main class re-initialize the logging system once it starts.
if (uninitLog) {
Logging.uninitialize()
}
//doRunMain()启动环境来调用子主类的main方法
//在独立群集模式下,有两个提交网关:
//(1)使用o.a.s.deploy.Client作为包装器的传统RPC网关。
//(2)Spark 1.3中引入的基于REST的新网关
//后者是Spark 1.3的默认行为,但如果主端点不是REST服务器,Spark提交将故障转移以使用旧网关。
if (args.isStandaloneCluster && args.useRest) {
try {
logInfo("Running Spark using the REST application submission protocol.")
doRunMain()
} catch {
// 故障转移以使用旧版提交网关
case e: SubmitRestConnectionException =>
logWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args, false)
}
// In all other modes, just run the main class as prepared
} else {
doRunMain()
}
}
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
error(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
}
接着看看doRunMain()方法中调用的runMain()方法:
/**
*使用提供的启动环境运行子类的main方法。
*
*请注意,如果我们正在运行集群部署模式或python应用程序,则此主类将不是用户提供的类。
*/
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sparkConf: SparkConf,
childMainClass: String,
verbose: Boolean): Unit = {
if (verbose) {
logInfo(s"Main class:\n$childMainClass")
logInfo(s"Arguments:\n${childArgs.mkString("\n")}")
// sysProps may contain sensitive information, so redact before printing
logInfo(s"Spark config:\n${Utils.redact(sparkConf.getAll.toMap).mkString("\n")}")
logInfo(s"Classpath elements:\n${childClasspath.mkString("\n")}")
logInfo("\n")
}
// 1.创建loader用于加载Jar包
val loader =
if (sparkConf.get(DRIVER_USER_CLASS_PATH_FIRST)) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
// 使用URLClassLoader加载jar包
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
// 2. 获取mainClass的main方法
var mainClass: Class[_] = null
try {
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
logWarning(s"Failed to load $childMainClass.", e)
if (childMainClass.contains("thriftserver")) {
logInfo(s"Failed to load main class $childMainClass.")
logInfo("You need to build Spark with -Phive and -Phive-thriftserver.")
}
throw new SparkUserAppException(CLASS_NOT_FOUND_EXIT_STATUS)
case e: NoClassDefFoundError =>
logWarning(s"Failed to load $childMainClass: ${e.getMessage()}")
if (e.getMessage.contains("org/apache/hadoop/hive")) {
logInfo(s"Failed to load hive class.")
logInfo("You need to build Spark with -Phive and -Phive-thriftserver.")
}
throw new SparkUserAppException(CLASS_NOT_FOUND_EXIT_STATUS)
}
//3. 创建一个App并调用start()方法
//这里没大看懂,但好像是根据mainClass来创建一个SparkApplication
// RestSubmissionClientApp 和 ClientApp均是SparkApplication 的子类
// 所以创建出来的app对象应该是 RestSubmissionClientApp 或者 ClientApp
//这样,后面调用的start()方法才能够 调用子类中重写的start()方法 进行driver的注册
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
logWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
new JavaMainApplication(mainClass)
}
try {
app.start(childArgs.toArray, sparkConf)
} catch {
case t: Throwable =>
throw findCause(t)
}
@tailrec
def findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
}
5. 提交网关 :“RestSubmissionClient” && “Client”
在讨论ClientApp的start()方法向Master注册Driver之前,我们先来讨论下在Standalone下的两种提交网关
在独立群集模式下,有两个提交网关:
(1)使用o.a.s.deploy.Client作为包装器的传统RPC网关。
(2)Spark 1.3中引入的基于REST的新网关
后者是Spark 1.3的默认行为,但如果`主端点不是REST服务器,Spark提交将故障转移以使用旧网关。
在上面执行spark-submit 提交SparkPi任务时,报出的WARN,就是在提交网关这里
这两种提交网关的取舍,取决于:
-
提交模式:client mode 、cluster mode -
用户脚本中的参数deploy-mode
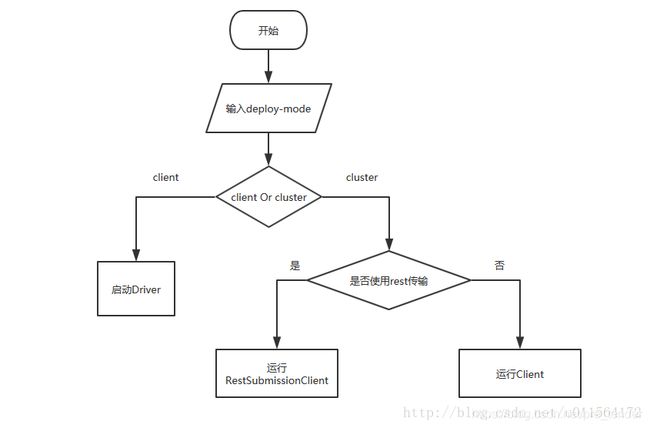
“RestSubmissionClient” or “Client”模式确定流程
图片来源: Spark 任务调度之Submit Driver
首先声明:“RestSubmissionClientApp” && “ClientApp”是在内部创建了一个“RestSubmissionClient” && “ClientEndpoint”,从而调用Client的方法,来实现向Master发送注册消息。查看二者的关系:

所以下面我们重点讨论下这两个App的内部实现细节。
5.1 RestSubmissionClientApp申请注册Driver详解
由于都是调用的app.start(),因此我们先对RestSubmissionClientApp的解析便从start()方法开始。
在此之前,Master端要先启动一个StandaloneRestServer:
# 首先我们发现在Master.scala中的main()方法中,有这样一行代码:
main(...){
...
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
...
}
# 而在startRpcEnvAndEndpoint()方法中创建了一个 StandaloneRestServer :
startRpcEnvAndEndpoint(){
...
//构造Master时候,会初始化StandaloneRestServer(RestSubmissionServer的子类)这个Server,并执行它的start方法。
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
...
}
* new Master()完成会执行Master的onStart()方法中,
* 它初始化了一个StandaloneRestServer(继承自RestSubmissionServer)
onStart(){
...
if (restServerEnabled) {
val port = conf.getInt("spark.master.rest.port", 6066)
restServer = Some(new StandaloneRestServer(address.host, port, conf, self, masterUrl))
}
restServerBoundPort = restServer.map(_.start())
//start()会启动这个server开始监听消息,并返回port
//而StandaloneRestServer并没有重写父类的start()方法,
//也就是说,这里的start()方法其实就是父类RestSubmissionServer的start()方法
...
}
-------------------RestSubmissionServer.scala---------------
def start(): Int = {
val (server, boundPort) = Utils.startServiceOnPort[Server](requestedPort, doStart, masterConf)
_server = Some(server)
logInfo(s"Started REST server for submitting applications on port $boundPort")
boundPort
}
---------------------------------------------------------
StandaloneRestServer端:
StandaloneRestServer继承自RestSubmissionServer,首先我们看看官方对RestSubmissionServer的说明:
响应[[RestSubmissionClient]]提交的请求的服务器。
此服务器根据情况响应不同的HTTP代码:
- 200 OK - 请求已成功处理
- 400 BAD REQUEST - 请求格式错误,未成功验证或意外类型
- 468 UNKNOWN PROTOCOL VERSION - 请求指定此服务器不理解的协议
- 500 INTERNAL SERVER ERROR - 服务器在处理请求时在内部抛出异常
服务器始终包含HTTP正文中相关[[SubmitRestProtocolResponse]]的JSON表示。
但是,如果发生错误,服务器将包含[[ErrorResponse]]而不是客户端预期的[[ErrorResponse]]。
如果此错误响应的构造本身失败,则响应将包含一个空体,其中包含指示内部服务器错误的响应代码。
二者的继承关系:
|
|
|
子类内容 |
|---|---|---|
RestSubmissionServer.scala |
StandaloneRestServer.scala | |
RestSubmissionServer |
StandaloneRestServer | |
RestServlet |
||
KillRequestServlet |
StandaloneKillRequestServlet | |
StatusRequestServlet |
StandaloneStatusRequestServlet | |
SubmitRequestServlet |
StandaloneSubmitRequestServlet | 创建了buildDriverDescription() 重写了handleSubmit() |
ErrorServlet,继承自RestServlet |
结合源代码(略)以及注释可知:
- StandaloneRestServer其实是作为一个代理,RestSubmissionClient是通过RestSubmissionServer的消息转发来实现和Master的通信。
- StandaloneRestServer中创建了一系列的Servlet(服务连接器)来处理各种消息,例如SubmitRequestServlet、KillRequestServlet、StatusRequestServlet。而这些Servlet在继承父类时也重写了父类的一些方法。
既然master创建并启动了这个StandaloneRestServer,而观察RestSubmissionServer可以发现如下路由 (理所当然会被继承):
//从URL前缀到为其提供服务的servlet的映射。 暴露于测试。
protected val baseContext = s"/${RestSubmissionServer.PROTOCOL_VERSION}/submissions"
protected lazy val contextToServlet = Map[String, RestServlet](
//这里是用正则匹配URL前缀
s"$baseContext/create/*" -> submitRequestServlet,
s"$baseContext/kill/*" -> killRequestServlet,
s"$baseContext/status/*" -> statusRequestServlet,
"/*" -> new ErrorServlet // default handler
)
可见create类型的消息由submitRequestServlet处理,查看submitRequestServlet的说明以及它的doPost方法:
private[rest] abstract class SubmitRequestServlet extends RestServlet {
/**
*使用请求中指定的参数向Master提交申请。
*
*请求被假定为JSON形式的[[SubmitRestProtocolRequest]]。
*如果请求成功处理,请向客户端返回适当的响应,指示如此。 否则,返回错误。
*/
protected override def doPost(
requestServlet: HttpServletRequest,
responseServlet: HttpServletResponse): Unit = {
val responseMessage = try {
//解析出jar包,主类等参数
val requestMessageJson = Source.fromInputStream(requestServlet.getInputStream).mkString
val requestMessage = SubmitRestProtocolMessage.fromJson(requestMessageJson)
//响应应该已在客户端上验证。
//如果不是这样,请自行验证以避免潜在的NPE。
requestMessage.validate()
handleSubmit(requestMessageJson, requestMessage, responseServlet)
} catch {
//客户端无法提供有效的JSON,因此这不是我们的错
case e @ (_: JsonProcessingException | _: SubmitRestProtocolException) =>
responseServlet.setStatus(HttpServletResponse.SC_BAD_REQUEST)
handleError("Malformed request: " + formatException(e))
}
sendResponse(responseMessage, responseServlet)
}
//未实现,在子类StandaloneSubmitRequestServlet中实现
protected def handleSubmit(
requestMessageJson: String,
requestMessage: SubmitRestProtocolMessage,
responseServlet: HttpServletResponse): SubmitRestProtocolResponse
}
我们看StandaloneSubmitRequestServlet中的handleSubmit的具体实现:
- 在
SubmitRequestServlet中并未实现handleSubmit() - 但是
StandaloneSubmitRequestServlet继承它时,是重写了handleSubmit()这个方法的 - 并且它还
构造了buildDriverDescription()方法来创建一个DriverDescription
------------------------------StandaloneRestServer.scala-------------------
private[rest] class StandaloneSubmitRequestServlet(
masterEndpoint: RpcEndpointRef,
masterUrl: String,
conf: SparkConf)
extends SubmitRequestServlet {
/**
*处理提交请求并构建适当的响应以返回给客户端。
*
*这假定请求消息已成功验证。
*如果请求消息不是预期类型,则将错误返回给客户端。
*/
protected override def handleSubmit(
requestMessageJson: String,
requestMessage: SubmitRestProtocolMessage,
responseServlet: HttpServletResponse): SubmitRestProtocolResponse = {
requestMessage match {
case submitRequest: CreateSubmissionRequest =>
//通过Master的ref发送RequestSubmitDriver(driverDescription)消息给Master这个Endpoint。
val driverDescription = buildDriverDescription(submitRequest)
val response = masterEndpoint.askSync[DeployMessages.SubmitDriverResponse](
DeployMessages.RequestSubmitDriver(driverDescription))
val submitResponse = new CreateSubmissionResponse
submitResponse.serverSparkVersion = sparkVersion
submitResponse.message = response.message
submitResponse.success = response.success
submitResponse.submissionId = response.driverId.orNull
val unknownFields = findUnknownFields(requestMessageJson, requestMessage)
if (unknownFields.nonEmpty) {
// If there are fields that the server does not know about, warn the client
submitResponse.unknownFields = unknownFields
}
submitResponse
case unexpected =>
responseServlet.setStatus(HttpServletResponse.SC_BAD_REQUEST)
handleError(s"Received message of unexpected type ${unexpected.messageType}.")
}
}
/**
*上一个方法中用到的
*从提交请求中指定的字段构建驱动程序描述。
*
* 这涉及构建一个命令,该命令考虑了内存,java选项,类路径和其他设置以启动驱动程序。
* 这当前不考虑python应用程序使用的字段,因为在独立集群模式下不支持python。
*/
private def buildDriverDescription(request: CreateSubmissionRequest): DriverDescription = {
// Required fields, including the main class because python is not yet supported
val appResource = Option(request.appResource).getOrElse {
throw new SubmitRestMissingFieldException("Application jar is missing.")
}
val mainClass = Option(request.mainClass).getOrElse {
throw new SubmitRestMissingFieldException("Main class is missing.")
}
// Optional fields
val sparkProperties = request.sparkProperties
val driverMemory = sparkProperties.get("spark.driver.memory")
val driverCores = sparkProperties.get("spark.driver.cores")
val driverExtraJavaOptions = sparkProperties.get("spark.driver.extraJavaOptions")
val driverExtraClassPath = sparkProperties.get("spark.driver.extraClassPath")
val driverExtraLibraryPath = sparkProperties.get("spark.driver.extraLibraryPath")
val superviseDriver = sparkProperties.get("spark.driver.supervise")
val appArgs = request.appArgs
// Filter SPARK_LOCAL_(IP|HOSTNAME) environment variables from being set on the remote system.
val environmentVariables =
request.environmentVariables.filterNot(x => x._1.matches("SPARK_LOCAL_(IP|HOSTNAME)"))
// Construct driver description
val conf = new SparkConf(false)
.setAll(sparkProperties)
.set("spark.master", masterUrl)
val extraClassPath = driverExtraClassPath.toSeq.flatMap(_.split(File.pathSeparator))
val extraLibraryPath = driverExtraLibraryPath.toSeq.flatMap(_.split(File.pathSeparator))
val extraJavaOpts = driverExtraJavaOptions.map(Utils.splitCommandString).getOrElse(Seq.empty)
val sparkJavaOpts = Utils.sparkJavaOpts(conf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = new Command(
"org.apache.spark.deploy.worker.DriverWrapper",
Seq("{
{WORKER_URL}}", "{
{USER_JAR}}", mainClass) ++ appArgs, // args to the DriverWrapper
environmentVariables, extraClassPath, extraLibraryPath, javaOpts)
val actualDriverMemory = driverMemory.map(Utils.memoryStringToMb).getOrElse(DEFAULT_MEMORY)
val actualDriverCores = driverCores.map(_.toInt).getOrElse(DEFAULT_CORES)
val actualSuperviseDriver = superviseDriver.map(_.toBoolean).getOrElse(DEFAULT_SUPERVISE)
new DriverDescription(
appResource, actualDriverMemory, actualDriverCores, actualSuperviseDriver, command)
}
}
---------------------------DriverDescription.scala---------------
# DriverDescription格式:
private[deploy] case class DriverDescription(
jarUrl: String,
mem: Int,
cores: Int,
supervise: Boolean,
command: Command) {
override def toString: String = s"DriverDescription (${command.mainClass})"
}
RestSubmissionClientApp端:
到现在,server已经启动好了,能够接收来自ClientApp的消息,那么我们看看RestSubmissionClientApp是怎么发送消息的。
还记得前面的app.start(childArgs.toArray, sparkConf)吗?我们先看看这个Start()方法:
---------------------class RestSubmissionClientApp-----------------------------------
override def start(args: Array[String], conf: SparkConf): Unit = {
if (args.length < 2) {
sys.error("Usage: RestSubmissionClient [app resource] [main class] [app args*]")
sys.exit(1)
}
val appResource = args(0)
val mainClass = args(1)
val appArgs = args.slice(2, args.length)
val env = RestSubmissionClient.filterSystemEnvironment(sys.env)
run(appResource, mainClass, appArgs, conf, env)
}
/** run()提交运行应用程序的请求并返回响应。 可见测试。 */
def run(
appResource: String,
mainClass: String,
appArgs: Array[String],
conf: SparkConf,
env: Map[String, String] = Map()): SubmitRestProtocolResponse = {
val master = conf.getOption("spark.master").getOrElse {
throw new IllegalArgumentException("'spark.master' must be set.")
}
val sparkProperties = conf.getAll.toMap
val client = new RestSubmissionClient(master)
val submitRequest = client.constructSubmitRequest(
appResource, mainClass, appArgs, sparkProperties, env)
//这个的createSubmission方法就会去发送请求启动Driver
client.createSubmission(submitRequest)
}
--------------------------class RestSubmissionClient--------------------------
/**
*提交由提供的请求中的参数指定的应用程序。
* Driver可以看成是一个应用程序
*
*如果提交成功,请轮询提交的状态并将其报告给用户。 否则,报告服务器提供的错误消息。
*/
def createSubmission(request: CreateSubmissionRequest): SubmitRestProtocolResponse = {
logInfo(s"Submitting a request to launch an application in $master.")
var handled: Boolean = false
var response: SubmitRestProtocolResponse = null
for (m <- masters if !handled) {
validateMaster(m)
val url = getSubmitUrl(m)
response = postJson(url, request.toJson)
response match {
case s: CreateSubmissionResponse =>
if (s.success) {
reportSubmissionStatus(s)
handleRestResponse(s)
handled = true
}
case unexpected =>
handleUnexpectedRestResponse(unexpected)
}
response
}
/** Send a POST request with the given JSON as the body to the specified URL. */
private def postJson(url: URL, json: String): SubmitRestProtocolResponse = {
logDebug(s"Sending POST request to server at $url:\n$json")
val conn = url.openConnection().asInstanceOf[HttpURLConnection]
conn.setRequestMethod("POST")
conn.setRequestProperty("Content-Type", "application/json")
conn.setRequestProperty("charset", "utf-8")
conn.setDoOutput(true)
try {
val out = new DataOutputStream(conn.getOutputStream)
Utils.tryWithSafeFinally {
out.write(json.getBytes(StandardCharsets.UTF_8))
} {
out.close()
}
} catch {
case e: ConnectException =>
throw new SubmitRestConnectionException("Connect Exception when connect to server", e)
}
/**
*readResponse()函数:
* 从服务器读取响应并将其作为经过验证的[[SubmitRestProtocolResponse]]返回。
* 如果响应表示错误,请将嵌入的消息报告给用户。
*/
readResponse(conn)
}
总结一下:
- 声明: 下面的
submitRequest = request = json,都是应用程序提交请求,只是不同函数中命名不同罢了 client.createSubmission(submitRequest)createSubmission()内部:response = postJson(url, request.toJson)postJson()内部:out.write(json.getBytes(StandardCharsets.UTF_8));
readResponse(conn)conn是和server的连接- 回到server中,还记得吗?有一个
handleSubmit()方法,里面有case submitRequest =>
val response = masterEndpoint.askSync[DeployMessages.SubmitDriverResponse]( DeployMessages.RequestSubmitDriver(driverDescription)) masterEndpoint.askSync()就是向Master发送了一个[[RpcEndpoint.receiveAndReply]]类型的消息.RequestSubmitDriver(driverDescription)),并获取起返回的消息- 接下来就是
Master端接收RequestSubmitDriver这个消息,然后注册并回复消息了。这部分参见本文章Spark学习-2.4.0-源码分析-3-Spark 核心篇-Spark Submit任务提交中的5.3 Driver接收消息并注册
5.2 ClientApp申请注册Driver详解
同样回到前面的提交部分,还是从app.start()方法着手看。Driver就是一个Client
首先需要明确的是,如果是ClientApp,那么就不需要在Maste端启动一个StandaloneRestServer,因为ClientApp是直接向Master发送RequestSubmitDriver(driverDescription)消息,而Master则接收消息注册Driver,并返回注册结果,以SubmitDriverResponse()的形式。
app.start()以及ClientEndpoint.onStart()代码如下:
- start()执行:
- 创建一个
RpcEnv保存当前Driver的信息 - 获取
Master的Endpoint用于发送注册信息 - onstart()执行:
- 模式匹配
driverArgs.cmd,如果是lunch,那么就进行driver启动以及注册准备工作 - 获取用户程序的
main,以及一些依赖项、参数等等,封装为一个Command - 创建一个
DriverDescription(它包含了command),并向Master发送注册消息RequestSubmitDriver(driverDescription)。 - 接下来就是
Master端接收RequestSubmitDriver这个消息,然后注册并回复消息了。这部分参见本文章Spark学习-2.4.0-源码分析-3-Spark 核心篇-Spark Submit任务提交中的5.3 Driver接收消息并注册
---------------org.apache.spark.deploy.Client.scala-----------------
private[spark] class ClientApp extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
val driverArgs = new ClientArguments(args)
if (!conf.contains("spark.rpc.askTimeout")) {
conf.set("spark.rpc.askTimeout", "10s")
}
Logger.getRootLogger.setLevel(driverArgs.logLevel)
val rpcEnv =
RpcEnv.create("driverClient", Utils.localHostName(), 0, conf, new SecurityManager(conf))
val masterEndpoints = driverArgs.masters.map(RpcAddress.fromSparkURL).
map(rpcEnv.setupEndpointRef(_, Master.ENDPOINT_NAME))
rpcEnv.setupEndpoint("client", new ClientEndpoint(rpcEnv, driverArgs, masterEndpoints, conf))
rpcEnv.awaitTermination()
}
}
onStart():
-----------------------------------------Class ClientEndpoint--------------------------------
override def onStart(): Unit = {
driverArgs.cmd match {
case "launch" =>
// TODO: We could add an env variable here and intercept it in `sc.addJar` that would
// truncate filesystem paths similar to what YARN does. For now, we just require
// people call `addJar` assuming the jar is in the same directory.
// TODO:我们可以在这里添加一个env变量,并在"sc.addJar"中拦截它,这将截短文件系统路径,类似于YARN所做的。
// 现在,我们只需要人们调用"addJar"假设这个jar在同一个目录中。
val mainClass = "org.apache.spark.deploy.worker.DriverWrapper"
val classPathConf = "spark.driver.extraClassPath"
val classPathEntries = getProperty(classPathConf, conf).toSeq.flatMap {
cp =>
cp.split(java.io.File.pathSeparator)
}
val libraryPathConf = "spark.driver.extraLibraryPath"
val libraryPathEntries = getProperty(libraryPathConf, conf).toSeq.flatMap {
cp =>
cp.split(java.io.File.pathSeparator)
}
val extraJavaOptsConf = "spark.driver.extraJavaOptions"
val extraJavaOpts = getProperty(extraJavaOptsConf, conf)
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val sparkJavaOpts = Utils.sparkJavaOpts(conf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = new Command(mainClass,
Seq("{
{WORKER_URL}}", "{
{USER_JAR}}", driverArgs.mainClass) ++ driverArgs.driverOptions,
sys.env, classPathEntries, libraryPathEntries, javaOpts)
val driverDescription = new DriverDescription(
driverArgs.jarUrl,
driverArgs.memory,
driverArgs.cores,
driverArgs.supervise,
command)
asyncSendToMasterAndForwardReply[SubmitDriverResponse](
RequestSubmitDriver(driverDescription))
case "kill" =>
val driverId = driverArgs.driverId
asyncSendToMasterAndForwardReply[KillDriverResponse](RequestKillDriver(driverId))
}
}
5.3 Master接收消息并注册
由于两种提交方式给Master发送的注册消息都是RequestSubmitDriver(driverDescription),所以Master端的注册也就都是相同的。
Master端接收消息并注册:
- 创建一个
DriverInfo - 使用持久化引擎将
Driver持久化 - 加入等待调度的队列
- 调用
schedule()进行调度 - 注意这里的是receiveAndReply()而不是receive(),而Worker与Application都是receive()
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RequestSubmitDriver(description) =>
if (state != RecoveryState.ALIVE) {
val msg = s"${Utils.BACKUP_STANDALONE_MASTER_PREFIX}: $state. " +
"Can only accept driver submissions in ALIVE state."
context.reply(SubmitDriverResponse(self, false, None, msg))
} else {
logInfo("Driver submitted " + description.command.mainClass)
val driver = createDriver(description)
persistenceEngine.addDriver(driver)
waitingDrivers += driver
drivers.add(driver)
schedule()
// TODO: It might be good to instead have the submission client poll the master to determine
// the current status of the driver. For now it's simply "fire and forget".
context.reply(SubmitDriverResponse(self, true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}"))
}
.....
}
------------------------------------------------------------------------
private def createDriver(desc: DriverDescription): DriverInfo = {
val now = System.currentTimeMillis()
val date = new Date(now)
new DriverInfo(now, newDriverId(date), desc, date)
}
--------------------------------------------------------------
/**
* • 在正在等待的应用之间安排当前可用的资源。每次新应用加入或资源可用性更改时,都会调用此方法。
*/
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) {
return
}
// Drivers take strict precedence over executors
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
for (driver <- waitingDrivers.toList) {
// iterate over a copy of waitingDrivers
// We assign workers to each waiting driver in a round-robin fashion. For each driver, we
// start from the last worker that was assigned a driver, and continue onwards until we have
// explored all alive workers.
var launched = false
var numWorkersVisited = 0
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver)
waitingDrivers -= driver
launched = true
}
curPos = (curPos + 1) % numWorkersAlive
}
}
startExecutorsOnWorkers()
}
致谢
Spark 任务调度之Submit Driver
Spark源码阅读: Spark Submit任务提交
Spark执行过程【源码分析+图示】——启动脚本(standalone模式)