
这个周末断断续续的阅读完了《Effective Python之编写高质量Python代码的59个有效方法》,感觉还不错,具有很大的指导价值。下面将以最简单的方式记录这59条建议,并在大部分建议后面加上了说明和示例,文章篇幅大,请您提前备好瓜子和啤酒!
1. 用Pythonic方式思考
第一条:确认自己使用的Python版本
(1)有两个版本的python处于活跃状态,python2和python3
(2)有很多流行的Python运行时环境,CPython、Jython、IronPython以及PyPy等
(3)在开发项目时,应该优先考虑Python3
第二条:遵循PEP风格指南
PEP8是针对Python代码格式而编订的风格指南,参考:http://www.python.org/dev/peps/pep-0008
(1)当编写Python代码时,总是应该遵循PEP8风格指南
(2)当广大Python开发者采用同一套代码风格,可以使项目更利于多人协作
(3)采用一致的风格来编写代码,可以令后续的修改工作变得更为容易
第三条:了解bytes、str、与unicode的区别
(1)python2提供str和unicode,python3中修改为bytes和str,bytes为原始的8位值,str包含unicode字符,在进行编码转换时使用decode和encode方法
(2)从文件中读取二进制数据,或向其中写入二进制数据时,总应该以‘rb’或‘wb’等二进制模式来开启文件
第四条:用辅助函数来取代复杂的表达式
(1)开发者很容易过度运用Python的语法特性,从而写出那种特别复杂并且难以理解的单行表达式
(2)请把复杂的表达式移入辅助函数中,如果要反复使用相同的逻辑,那更应该这么做
第五条:了解切割序列的方法
(1)不要写多余的代码:当start索引为0,或end索引为序列长度时,应将其省略a[:]
(2)切片操作不会计较start与end索引是否越界,者使得我们很容易就能从序列的前端或后端开始,对其进行范围固定的切片操作,a[:20]或a[-20:]
(3)对list赋值的时候,如果使用切片操作,就会把原列表中处在相关范围内的值替换成新值,即便它们的长度不同也依然可以替换
第六条:在单词切片操作内,不要同时指定start、end和step
(1)这条的目的主要是怕代码难以阅读,作者建议将其拆解为两条赋值语句,一条做范围切割,另一条做步进切割
(2)注意:使用[::-1]时会出现不符合预期的错误,看下面的例子
msg = '谢谢' print('msg:',msg) x = msg.encode('utf-8') y = x.decode('utf-8') print('y:',y) z=x[::-1].decode('utf-8') print('z:', z)
输出:

第七条:用列表推导式来取代map和filter
(1)列表推导要比内置的map和filter函数清晰,因为它无需额外编写lambda表达式
(2)字典与集合也支持推导表达式
第八条:不要使用含有两个以上表达式的列表推导式
第九条:用生成器表达式来改写数据量较大的列表推导式
(1)列表推导式的缺点
在推导过程中,对于输入序列中的每个值来说,可能都要创建仅含一项元素的全新列表,当输入的数据比较少时,不会出现问题,但如果输入数据非常多,那么可能会消耗大量内存,并导致程序崩溃,面对这种情况,python提供了生成器表达式,它是列表推导和生成器的一种泛化,生成器表达式在运行的时候,并不会把整个输出序列呈现出来,而是会估值为迭代器。
把实现列表推导式所用的那种写法放在一对园括号中,就构成了生成器表达式
numbers = [1,2,3,4,5,6,7,8] li = (i for i in numbers) print(li)
>>>>
(2)串在一起的生成器表达式执行速度很快
第十条:尽量用enumerate取代range
(1)尽量使用enumerate来改写那种将range与下表访问结合的序列遍历代码
(2)可以给enumerate提供第二个参数,以指定开始计数器时所用的值,默认为0
color = ['red','black','write','green'] #range方法 for i in range(len(color)): print(i,color[i]) #enumrate方法 for i,value in enumerate(color): print(i,value)
第11条:用zip函数同时遍历两个迭代器
(1)内置的zip函数可以平行地遍历多个迭代器
(2)Python3中的zip相当于生成器,会在遍历过程中逐次产生元组,而python2中的zip则是直接把这些元组完全生成好,并一次性地返回整份列表、
(3)如果提供的迭代器长度不等,那么zip就会自动提前终止
attr = ['name','age','sex'] values = ['zhangsan',18,'man'] people = zip(attr,values) for p in people: print(p)
第12条:不要在for和while循环后面写else块
(1)python提供了一种很多编程语言都不支持的功能,那就是在循环内部的语句块后面直接编写else块
for i in range(3): print('loop %d' %(i)) else: print('else block!')
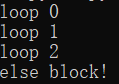
上面的写法很容易让人产生误解:如果循环没有正常执行完,那就执行else,实际上刚好相反
(2)不要再循环后面使用else,因为这种写法既不直观,又容易让人误解
第13条:合理利用try/except/else/finally结构中的每个代码块
try: #执行代码 except: #出现异常 else: #可以缩减try中代码,再没有发生异常时执行 finally: #处理释放操作
2. 函数
第14条:尽量用异常来表示特殊情况,而不要返回None
(1)用None这个返回值来表示特殊意义的函数,很容易使调用者犯错,因为None和0及空字符串之类的值,在表达式里都会贝评估为False
(2)函数在遇到特殊情况时应该抛出异常,而不是返回None,调用者看到该函数的文档中所描述的异常之后,应该会编写相应的代码来处理它们
第15条:了解如何在闭包里使用外围作用域中的变量
(1)理解什么是闭包
闭包是一种定义在某个作用域中的函数,这种函数引用了那个作用域中的变量
(2)表达式在引用变量时,python解释器遍历各作用域的顺序:
a. 当前函数的作用域
b. 任何外围作用域(例如:包含当前函数的其他函数)
c. 包含当前代码的那个模块的作用域(也叫全局作用域)
d. 内置作用域(也即是包含len及str等函数的那个作用域)
e. 如果上卖弄这些地方都没有定义过名称相符的变量,那么就抛出NameError异常
(3)赋值操作时,python解释器规则
给变量赋值时,如果当前作用域内已经定义了这个变量,那么该变量就会具备新值,若当前作用域内没有这个变量,python则会把这次赋值视为对该变量的定义
(4)nonlocal
nonlocal的意思:给相关变量赋值的时候,应该在上层作用域中查找该变量,nomlocal的唯一限制在于,它不能延申到模块级别,这是为了防止它污染全局作用域
(5)global
global用来表示对该变量的赋值操作,将会直接修改模块作用域的那个变量
第16条:考虑用生成器来改写直接返回列表的函数
参考第九条
第17条:在参数上面迭代时,要多加小心
(1)函数在输入的参数上面多次迭代时要当心,如果参数是迭代对象,那么可能会导致奇怪的行为并错失某些值
看下面两个例子:
例1:
def normalize(numbers): total = sum(numbers) print('total:',total) print('numbers:',numbers) result = [] for value in numbers: percent = 100 * value / total result.append(percent) return result numbers = [15,35,80] print(normalize(numbers))
输出:
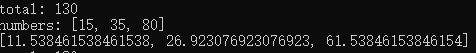
例2:将numbers换成生成器
def fun(): li = [15,35,80] for i in li: yield i print(normalize(fun()))
输出:

原因:迭代器只产生一轮结果,在抛出过StopIteration异常的迭代器或生成器上面继续迭代第二轮,是不会有结果的。
(2)python的迭代器协议,描述了容器和迭代器应该如何于iter和next内置函数、for循环及相关表达式互相配合
(3)想判断某个值是迭代器还是容器,可以拿该值为参数,两次调用iter函数,若结果相同,则是迭代器,调用内置的next函数,即可令该迭代器前进一步
if iter(numbers) is iter(numbers): raise TypeError('Must supply a container')
第18条:用数量可变的位置参数减少视觉杂讯
(1)在def语句中使用*args,即可令函数接收数量可变的位置参数
(2)调用函数时,可以采用*操作符,把序列中的元素当成位置参数,传给该函数
(3)对生成器使用*操作符,可能导致程序耗尽内存并崩溃,所以只有当我们能够确定输入的参数个数比较少时,才应该令函数接受*arg式的变长参数
(4)在已经接收*args参数的函数上面继续添加位置参数,可能会产生难以排查的错误
第19条:用关键字参数来表达可选的行为
(1)函数参数可以按位置或关键字来指定
(2)只使用位置参数来调用函数,可能会导致这些参数值的含义不够明确,而关键字参数则能够阐明每个参数的意图
(3)该函数添加新的行为时,可以使用带默认值的关键字参数,以便与原有的函数调用代码保持兼容
(4)可选的关键字参数总是应该以关键字形式来指定,而不应该以位置参数来指定
第20条:用None和文档字符串来描述具有动态默认值的参数
import datetime import time def log(msg,when=datetime.datetime.now()): print('%s:%s' %(when,msg)) log('hi,first') time.sleep(1) log('hi,second')
输出:![]()
两次显示的时间一样,这是因为datetime.now()只执行了一次,也就是它只在函数定义的时候执行了一次,参数的默认值,会在每个模块加载进来的时候求出,而很多模块都在程序启动时加载。我们可以将上面的函数改成:
import datetime import time def log(msg,when=None): """ arg when:datetime of when the message occurred """ if when is None: when=datetime.datetime.now() print('%s:%s' %(when,msg)) log('hi,first') time.sleep(1) log('hi,second')
输出:
![]()
(1)参数的默认值,只会在程序加载模块并读到本函数定义时评估一次,对于{}或[]等动态的值,这可能导致奇怪的行为
(2)对于以动态值作为实际默认值的关键字参数来说,应该把形式上的默认值写为None,并在函数的文档字符串里面描述该默认值所对应的实际行为
第21条:用只能以关键字形式指定的参数来确保代码明确
(1)关键字参数能够使函数调用的意图更加明确
(2)对于各参数之间很容易混淆的函数,可以声明只能以关键字形式指定的参数,以确保调用者必须通过关键字来指定它们。对于接收多个Boolean标志的函数更应该这样做
3. 类与继承
第22条:尽量用辅助类来维护程序的状态,而不要用字典或元组
作者的意思是:如果我们使用字典或元组保存程序的某部分信息,但随着需求的不断变化,需要逐渐的修改之前定义好的字典或元组结构,会出现多次的嵌套,过分膨胀会导致代码出现问题,而且难以理解。遇到这样的情况,我们可以把嵌套结构重构为类。
(1)不要使用包含其他字典的字典,也不要使用过长的元组
(2)如果容器中包含简单而又不可变的数据,那么可以先使用namedtupe来表述,待稍后有需要时,再修改为完整的类
注意:namedtuple类无法指定各参数的默认值,对于可选属性比较多的数据来说,namedtuple用起来不方便
(3)保存内部状态的字典如果变得比较复杂,那就应该把这些代码拆分为多个辅组类
第23条:简单的接口应该接收函数,而不是类的实例
(1)对于连接各种python组件的简单接口来说,通常应该给其直接传入函数,而不是先定义某个类,然后再传入该类的实例
(2)Python种的函数和方法可以像类那么引用,因此,它们与其他类型的对象一样,也能够放在表达式里面
(3)通过名为__call__的特殊方法,可以使类的实例能够像普通的Python函数那样得到调用
第24条:以@classmethod形式的多态去通用的构建对象
在python种,不仅对象支持多态,类也支持多态
(1)在Python程序种,每个类只能有一个构造器,也就是__init__方法
(2)通过@classmethod机制,可以用一种与构造器相仿的方式来构造类的对象
(3)通过类方法机制,我们能够以更加通用的方式来构建并拼接具体的子类
下面以实现一套MapReduce流程计算文件行数为例来说明:
(1)思路
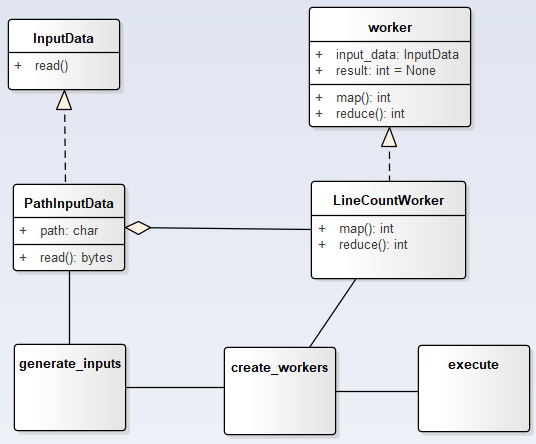
(2)上代码


import threading import os class InputData: def read(self): raise NotImplementedError class PathInputData(InputData): def __init__(self,path): super().__init__() self.path = path def read(self): return open(self.path).read() class worker: def __init__(self,input_data): self.input_data = input_data self.result = None def map(self): raise NotImplementedError def reduce(self): raise NotImplementedError class LineCountWorker(worker): def map(self): data = self.input_data.read() self.result = data.count('\n') def reduce(self,other): self.result += other.result def generate_inputs(data_dir): for name in os.listdir(data_dir): yield PathInputData(os.path.join(data_dir,name)) def create_workers(input_list): workers = [] for input_data in input_list: workers.append(LineCountWorker(input_data)) return workers def execute(workers): threads = [threading.Thread(target=w.map) for w in workers] for thread in threads: thread.start() for thread in threads: thread.join() first,rest = workers[0],workers[1:] for worker in rest: first.reduce(worker) return first.result def mapreduce(data_dir): inputs = generate_inputs(data_dir) workers = create_workers(inputs) return execute(workers) if __name__ == "__main__": print(mapreduce('D:\mapreduce_test'))
上面的代码在拼接各种组件时显得非常费力,下面重新使用@classmethod来改进下
import threading import os class InputData: def read(self): raise NotImplementedError @classmethod def generate_inputs(cls,data_dir): raise NotImplementedError class PathInputData(InputData): def __init__(self,path): super().__init__() self.path = path def read(self): return open(self.path).read() @classmethod def generate_inputs(cls,data_dir): for name in os.listdir(data_dir): yield cls(os.path.join(data_dir,name)) class worker: def __init__(self,input_data): self.input_data = input_data self.result = None def map(self): raise NotImplementedError def reduce(self): raise NotImplementedError @classmethod def create_workers(cls,input_list): workers = [] for input_data in input_list: workers.append(cls(input_data)) return workers class LineCountWorker(worker): def map(self): data = self.input_data.read() self.result = data.count('\n') def reduce(self,other): self.result += other.result def execute(workers): threads = [threading.Thread(target=w.map) for w in workers] for thread in threads: thread.start() for thread in threads: thread.join() first,rest = workers[0],workers[1:] for worker in rest: first.reduce(worker) return first.result def mapreduce(data_dir): inputs = PathInputData.generate_inputs(data_dir) workers = LineCountWorker.create_workers(inputs) return execute(workers) if __name__ == "__main__": print(mapreduce('D:\mapreduce_test'))
通过类方法实现多态机制,我们可以用更加通用的方式来构建并拼接具体的类
第25条:用super初始化父类
如果从python2开始详细的介绍super使用方法需要很大的篇幅,这里只介绍python3中的使用方法和MRO
(1)MRO即为方法解析顺序,以标准的流程来安排超类之间的初始化顺序,深度优先,从左至右,它也保证钻石顶部那个公共基类的__init__方法只会运行一次
(2)python3中super的使用方法
python3提供了一种不带参数的super调用方法,该方式的效果与用__class__和self来调用super相同
class A(Base): def __init__(self,value): super(__class__,self).__init__(value) class A(Base): def __init__(self,value): super().__init__(value)
推荐使用上面两种方法,python3可以在方法中通过__class__变量精确的引用当前类,而Python2中则没有定义__class__方法
(3)总是应该使用内置的super函数来初始化父类
第26条:只在使用Mix-in组件制作工具类时进行多重继承
python是面向对象的编程语言,它提供了一些内置的编程机制,使得开发者可以适当地实现多重继承,但是,我们应该尽量避免多重继承,若一定要使用,那就考虑编写mix-in类,mix-in是一种小型的类,它只定义了其他类可能需要提供的一套附加方法,而不定义自己的 实例属性,此外,它也不要求使用者调用自己的__init__函数
(1)能用mix-in组件实现的效果,就不要使用多重继承来做
(2)将各功能实现为可插拔的mix-in组件,然后令相关的类继承自己需要的那些组件,即可定制该类实例所具备的行为
(3)把简单的行为封装到mix-in组件里,然后就可以用多个mix-in组合出复杂的行为了
第27条:多用public属性,少用private属性
python没有从语法上严格保证private字段的私密性,用简单的话来说,我们都是成年人。
个人习惯:_XXX 单下划代表protected;__XXX 双下划线开始的且不以_结尾表示private;__XXX__系统定义的属性和方法
class People: __name="zhanglin" def __init__(self): self.__age = 16 print(People.__dict__) p = People() print(p.__dict__)

会发现__name和__age属性名都发生了变化,都变成了(_类名+属性名),只有在__XXX这种命名方式下才会发生变化,所以以这种方式作为伪私有说明
(1)python编译器无法严格保证private字段的私密性
(2)不要盲目地将属性设为private,而是应该从一开始就做好规划,并允许子类更多地访问超类内部的api
(3)应该更多的使用protected属性,并在文档中把这些字段的合理用法告诉子类的开发者,而不是试图用private属性来限制子类访问这些字段
(4)只有当子类不受自己控制时,才可以考虑用private属性来避免名称冲突
第28条:继承collections.abc以实现自定义的容器类型
collections.abc模块定义了一系列抽象基类,它们提供了每一种容器类型所应具备的常用方法,大家可以自己参考源码
__all__ = ["Awaitable", "Coroutine", "AsyncIterable", "AsyncIterator", "AsyncGenerator", "Hashable", "Iterable", "Iterator", "Generator", "Reversible", "Sized", "Container", "Callable", "Collection", "Set", "MutableSet", "Mapping", "MutableMapping", "MappingView", "KeysView", "ItemsView", "ValuesView", "Sequence", "MutableSequence", "ByteString", ]
(1)如果定制的子类比较简单,那就可以直接从Python的容器类型(如list、dict)中继承
(2)想正确实现自定义的容器类型,可能需要编写大量的特殊方法
(3)编写自制的容器类型时,可以从collections.abc模块的抽象基类中继承,那些基类能够确保我们的子类具备适当的接口及行为
4. 元类及属性
第29条:用纯属性取代get和set方法
(1)编写新类时,应该用简单的public属性来定义其接口,而不要手工实现set和get方法
(2)如果访问对象的某个属性,需要表现出特殊的行为,那就用@property来定义这种行为
比如下面的示例:成绩必须在0-100范围内
class Homework: def __init__(self): self.__grade = 0 @property def grade(self): return self.__grade @grade.setter def grade(self,value): if not (0<=value<=100): raise ValueError('Grade must be between 0 and 100') self.__grade = value
(3)@property方法应该遵循最小惊讶原则,而不应该产生奇怪的副作用
(4)@property方法需要执行得迅速一些,缓慢或复杂的工作,应该放在普通的方法里面
(5)@property的最大缺点在于和属性相关的方法,只能在子类里面共享,而与之无关的其他类都无法复用同一份实现代码
第30条:考虑用@property来代替属性重构
作者的意思是:当我们需要迁移属性时(也就是对属性的需求发生变化的时候),我们只需要给本类添加新的功能,原来的那些调用代码都不需要改变,它在持续完善接口的过程中是一种重要的缓冲方案
(1)@property可以为现有的实例属性添加新的功能
(2)可以用@properpy来逐步完善数据模型
(3)如果@property用的太过频繁,那就应该考虑彻底重构该类并修改相关的调用代码
第31条:用描述符来改写需要复用的@property方法
首先对描述符进行说明,先看下面的例子:
class Grade: def __init(self): self.__value = 0 def __get__(self, instance, instance_type): return self.__value def __set__(self, instance, value): if not (0 <= value <= 100): raise ValueError('Grade must be between 0 and 100') self.__value = value class Exam: math_grade = Grade() chinese_grade = Grade() science_grade = Grade() if __name__ == "__main__": exam = Exam() exam.math_grade = 99 exam1 = Exam() exam1.math_grade = 75 print('exam.math_grade:',exam.math_grade, 'is wrong') print('exam1.math_grade:',exam1.math_grade, 'is right')
输出:
![]()
会发现在两个Exam实例上面分别操作math_grade时,导致了错误的结果,出现这种情况的原因是因为该math_grade属性为Exam类的实例,为了解决这个问题,看下面的代码
class Grade: def __init__(self): self.__value = {} def __get__(self, instance, instance_type): if instance is None: return self return self.__value.get(instance,0) def __set__(self, instance, value): if not (0 <= value <= 100): raise ValueError('Grade must be between 0 and 100') self.__value[instance] = value class Exam: math_grade = Grade() chinese_grade = Grade() science_grade = Grade() if __name__ == "__main__": exam = Exam() exam.math_grade = 99 exam1 = Exam() exam1.math_grade = 75 print('exam.math_grade:',exam.math_grade, 'is wrong') print('exam1.math_grade:',exam1.math_grade, 'is right')
输出:
![]()
上面这种实现方式很简单,而且能够正常运作,但它仍然有个问题,那就是会泄露内存,在程序的生命期内,对于传给__set__方法的每个Exam实例来说,__values字典都会保存指向该实例的一份引用,者就导致实例的引用计数无法降为0,从而使垃圾收集器无法将其收回。使用python的内置weakref模块,可解决上述问题。
class Grade: def __init(self): self.__value = weakref.WeakKeyDictionary()
(1)如果想复用@property方法及其验证机制,那么可以自己定义描述符
(2)WeakKeyDictionary可以保证描述符类不会泄露内存
(3)通过描述符协议来实现属性的获取和设置操作时,不要纠结于__getattribute__的方法具体运作细节
第32条:用__getattr__、__getattribute__和__setattr__实现按需生成的属性
如果某个类定义了__getattr__,同时系统在该类对象的实例字典中又找不到待查询的属性,那么就会调用这个方法
惰性访问的概念:初次执行__getattr__的时候进行一些操作,把相关的属性加载进来,以后再访问该属性时,只需从现有的结果中获取即可
程序每次访问对象的属性时,Python系统都会调用__getattribute__,即使属性字典里面已经有了该属性,也以让会触发__getattribute__方法
(1)通过__getattr__和__setattr__,我们可以用惰性的方式来加载并保存对象的属性
(2)要理解__getattr__和__getattribute__的区别:前者只会在待访问的属性缺失时触发,,而后者则会在每次访问属性时触发
(3)如果要在__getattribute__和__setattr__方法中访问实例属性,那么应该直接通过super()来做,以避免无限递归
第33条:用元类来验证子类
元类最简单的一种用途,就是验证某个类定义的是否正确,构建复杂的类体系时,我们可能需要确保类的风格协调一致,确保某些方法得到了覆写,或是确保类属性之间具备某些严格的关系。
下例判断类属性中是否含有name属性:
#验证某个类的定义是否正确 class Meta(type): def __new__(meta,name,bases,class_dict): print('class_dict:',class_dict) if not class_dict.get('name',None): #判断类属性中是否含有name属性 raise AttributeError('must has name attribute') return type.__new__(meta,name,bases,class_dict) class A(metaclass=Meta): def __init__(self): self.chinese_grade = 90 self.math_grade = 99 if __name__ == '__main__': a = A()
输出:

(1)通过元类,我们可以在生成子类对象之前,先验证子类的定义是否合乎规范
(2)python系统把子类的整个class语句体处理完毕之后,就会调用其元类的__new__方法
第34条:用元类来注册子类
元类还有一个用途就是在程序中自动注册类型,对于需要反向查找(reverse lookup)的场合,这种注册操作很有用
看下面的例子:对对象进行序列化和反序列化
import json register = {} class Meta(type): def __new__(meta,name,bases,attr_dic): cls = type.__new__(meta,name,bases,attr_dic) print('create class in Meta:', cls) register[cls.__name__] = cls return cls class Serializable(metaclass=Meta): def __init__(self,*args): self.args = args def serialize(self): return json.dumps({ 'class':self.__class__.__name__, 'args':self.args}) def deserilize(self,json_data): json_dict = json.loads(json_data) classname = json_dict['class'] args = json_dict['args'] return register[classname](*args) class Point2D(Serializable): def __init__(self,x,y): super().__init__(x,y) self.x = x self.y = y def add(self): return self.x + self.y if __name__ == "__main__": p = Point2D(2,5) data = p.serialize() print('serialize_data:',data) new_point2d = p.deserilize(data) print('new_point2d:',new_point2d) print(new_point2d.add())
输出:

(1)通过元类来实现类的注册,可以确保所有子类就都不会泄露,从而避免后续的错误
第35条:用元类来注解类的属性
(1)借助元类,我们可以在某个类完全定义好之前,率先修改该类的属性
(2)描述符与元类能够有效的组合起来,以便对某种行为做出修饰,或在程序运行时探查相关信息
(3)如果把元类与描述符相结合,那就可以在不使用weakref模块的前提下避免内存泄漏
5. 并发与并行
并发和并行的关键区别在于能不能提速,若是并行,则总任务的执行时间会减半,若是并发,那么即使可以看似平行的方式分别执行多条路径,依然不会使总任务的执行速度得到提升,用Python语言编写并发程序,是比较容易的,通过系统调用、子进程和C语言扩展等机制,也可以用Python平行地处理一些事务,但是,要想使并发式的python代码以真正平行的方式来运行,却相当困难。
可以先阅读我之前的博客,相信会有帮组:python究竟要不要使用多线程
第36条:用subprocess模块来管理子进程
在多年的发展过程中,Python演化出了多种运行子进程的方式,其中包括popen、popen2和os.exec*等,然而,对于至今的Python来说,最好且最简单的子进程管理模块,应该是内置的subprocess模块
第37条:可以用线程来执行阻塞式I/O,但不要用它做平行计算
(1)因为受全局解释锁(GIL)的限制,所以多条Python线程不能在多个CPU核心上面平行地执行字节码
(2)尽管受制于GIL,但是python的多线程功能依然很有用,它可以轻松地模拟出同一时刻执行多项任务的效果
(3)通过python线程,我们可以平行地执行多个系统调用,这使得程序能够在执行阻塞式I/O操作的同时,执行一些运算操作
第38条:在线程中使用Lock来防止数据竞争
class LockingCounter: def __init__(self): self.lock = threading.Lock() self.count = 0 def increment(self, offset): with self.lock: self.count += offset
第39条:用Queue来协调各线程之间的工作
作者举了一个照片处理系统的例子:
需求:该系统从数码相机里面持续获取照片、调整其尺寸,并将其添加到网络相册中。
实现:使用三阶段的管线实现,需要4个自定义的deque消息队列,第一阶段获取新照片,第二阶段把下载好的照片传给缩放函数,第三阶段把缩放后的照片交给上传函数
问题:该程序虽然可以正常运行,但是每个阶段的工作函数都会有差别,这使得前一阶段可能会拖慢后一阶段的进度,从而令整条管线迟滞,后一阶段会在其循环语句中,反复查询输入队列,以求获取新的任务,而任务却迟迟未到达,这将令后一阶段陷入饥饿,会白白浪费CPU时间,效率特低
内置的queue模块的Queue类可以解决上述问题,因为其get方法会持续阻塞,直到有新的数据加入
import threading from queue import Queue class ClosableQueue(Queue): SENTINEL = object() def close(self): self.put(SENTINEL) def __iter__(self): while True: item = self.get() try: if item is self.SENTINEL: return yield item finally: self.task_done() class StoppabelWoker(threading.Thread): def __init__(self,func,in_queue,out_queue): self.func = func self.in_queue = in_queue self.out_queue = out_queue def run(self): for item in self.in_queue: result = self.func(item) self.out_queue.put(result)
(1)管线是一种优秀的任务处理方式,它可以把处理流程划分未若干个阶段,并使用多条python线程来同时执行这些任务
(2)构建并发式的管线时,要注意许多问题,其中包括:如何防止某个阶段陷入持续等待的状态之中,如何停止工作线程,以及如何防止内存膨胀等
(3)Queue类所提供的机制,可以cedilla解决上述问题,它具备阻塞式的队列操作,能够指定缓冲区的尺寸,而且还支持join方法,这使得开发者可以构建出健壮的管线
第40条:考虑用协程来并发地运行多个函数
(1)协程提供了一种有效的方式,令程序看上去好像能够同时运行大量函数
(2)对于生成器内的yield表达式来说,外部代码通过send方法传给生成器的那个值就是该表达式所要具备的值
(3)协程是一种强大的工具,它可以把程序的核心逻辑,与程序同外部环境交互时所使用的代码相隔离
第41条:考虑用concurrent.futures来实现真正的平行计算
参考之前的博客:网络爬虫必备知识之concurrent.futures库
6. 内置模块
第42条:用functools.wrap定义函数修饰器
为了维护函数的接口,修饰之后的函数,必须保留原函数的某些标准Python属性,例如__name__和__module__,这个时候我们需要使用functools.wraps来确保修饰后函数具备正确的行为
第43条:考虑以contextlib和with语句来改写可复用的try/finally代码
(1)可以用with语句来改写try/finally块中的逻辑,以提升复用程度,并使代码更加整洁
import threading lock = threading.Lock() lock.acquier() try: print("lock is held") finally: lock.release()
可以直接使用下面的语法:
import threading lock = threading.Lock() with lock: print("lock is held")
(2)内置的contextlib模块提供了名叫为contextmanager的修饰器,开发者只需要用它来修饰自己的函数,即可令该函数支持with语句
from contextlib import contextmanager @contextmanager def file_open(path): ''' file open test''' try: fp = open(path,"wb") yield fp except OSError: print("We had an error!") finally: print("Closing file") fp.close() if __name__ == "__main__": with file_open("contextlibtest.txt") as fp: fp.write("Testing context managers".encode("utf-8"))
(3)情景管理器可以通过yield语句向with语句返回一个值,此值会赋给由as关键字所指定的变量
第44条:用copyreg实现可靠pickle操作
(1)内置的pickle模块,只适合用来彼此信任的程序之间,对相关对象执行序列化和反序列化操作
(2)如果用法比较复杂,那么pickle模块的功能可能就会出现问题,我们可以用内置的copyreg模块和pickle结合起来使用,以便为旧数据添加缺失的属性值、进行类的版本管理、并给序列化之后的数据提供固定的引入路径
第45条:应该用datetime模块来处理本地时间,而不是time模块
(1)不要用time模块在不同时区之间进行转换
(2)如果要在不同时区之间,可靠地执行转换操作,那就应该把内置的datetime模块与开发者社区提供的pytz模块打起来使用
(3)开发者总是应该先把时间表示为UTC格式,然后对其执行各种转换操作,最后再把它转回本地时间
第46条:使用内置算法和数据结构
(1)双向队列 collections.deque
(2)有序字典 dollections.OrderDict
(3)带有默认值的有序字典 collections.defaultdict
(4)堆队列(优先级队列)heapq.heap
(5)二分查找 bisect模块中的bisect_left函数等提供了高效的二分折半搜索算法
(6)与迭代器有关的工具 itertools模块
第47条:在重视精度的场合,应该使用decimal
(1)decimal模块中的Decimal类默认提供28个小数位,以进行定点数字运算,还可以按照开发射所要求的精度及四舍五入
第48条:学会安装由Python开发者社区所构建的模块
7. 协作开发
第49条:为每个函数、类和模块编写文档字符串
第50条:用包来安排模块,并提供稳固的API
(1)只要把__init__.py文件放入含有其他源文件的目录里,就可以将该目录定义为包,目录中的文件,都将成为包的子模块,该包的目录下面,也可以含有其他的包
(2)把外界可见的名称,列在名为__all__的特殊属性里,即可为包提供一套明确的API
第51条:为自编的模块定义根异常,以便调用者与API相隔离
意思就是单独用个模块提供各种异常API
第52条:用适当的方式打破循环依赖关系
(1)调整引入顺序
(2)先引入、再配置、最后运行
只在模块中给出函数、类和常量的定义,而不要在引入的时候真正去运行那些函数
(3)动态引入:在函数或方法内部使用import语句
第53条:用虚拟环境隔离项目,并重建其依赖关系
参考之前的博客:Python之用虚拟环境隔离项目,并重建依赖关系
8. 部署
第54条:考虑用模块级别的代码来配置不同的部署环境
(1)可以根据外部条件来决定模块的内容,例如,通过sys和os模块来查询宿主操作系统的特性,并以此来定义本模块中的相关结构
第55条:通过repr字符串来输出调试信息
第56条:通过unittest来测试全部代码
这个在后面会单独写篇博客对unittest单元测试模块进行详细说明
第57条:考虑用pdb实现交互调试
第58条:先分析性能,然后再优化
(1)优化python程序之前,一定要先分析其性能,因为python程序的性能瓶颈通常很难直接观察出来
(2)做性能分析时,应该使用cProfile模块,而不要使用profile模块,因为前者能够给出更为精确的性能分析数据
第59条:用tracemalloc来掌握内存的使用及泄露情况
在Python的默认实现中,也就是Cpython中,内存管理是通过引用计数来处理的,另外,Cpython还内置了循环检测器,使得垃圾回收机制能够把那些自我引用的对象清除掉
(1)使用内置的gc模块进行查询,列出垃圾收集器当前所知道的每个对象,该方法相当笨拙
(2)python3.4提供了内置模块tracemalloc可以打印出Python系统在执行每一个分配内存操作时所具备的完整堆栈信息
文章到这里就全部结束了,感谢您这么有耐心的阅读!