电影评论分类(python深度学习——二分类问题)
记:二分类问题应该是应用最广泛的机器学习问题,电影评论分类是指根据电影评论的文字内容,将其划分为正面评论或者是负面评论,是一个二分类问题,我从头到尾学习了代码,并且进行了整理,有的内容是个人理解,如有错误还请指正。(本代码实在jupyter notebook上完成的)
1、典型的keras工作流程
(1)定义训练数据:输入张量和目标张量
(2)定义层组成的网络(模型),将输入映射到目标
(3)配置学习过程:选择合适的损失函数,优化器和需要监控的指标
(4)调用模型的fit方法在训练数据上进行迭代
2、IMDB数据集:包含来自互联网电影数据库的50000条严重两极分化的评论,数据集被分成两部分,分别是训练集25000条,测试集25000条。在实验的时候需要将每一条评论里的单词转化为对应的整数索引,再将正序序列转换为张量才能输入到神经网络中,转换成张量时一般会把列表进行one-hot编码,将其转换成0和1组成的向量。
3、常见问题损失函数的选择:
对于二分类问题,可以选择二元交叉熵(binary crossentropy)损失函数;对于多分类问题,可以选择分类交叉熵(categorical crossentropy)损失函数;对于回归问题,可以选择均方误差(mean-squared error)损失函数;对于序列学习问题,可以用联结主义时序分类(CTC,connectionist temporal classification)损失函数。
4、完整代码以及代码部分注释如下:
#引入所需要的包
from keras.datasets import imdb
import numpy as np
from keras import models
from keras import layers
from keras import optimizers
from keras import losses
from keras import metrics
import matplotlib.pyplot as plt
#加载IMDB数据集
#train_data,test_data都是由评论组成的列表,每条评论又是单词索引组成的列表
#train_labels,test_labels都是0和1组成的列表,0代表负面,1代表正面
(train_data,train_labels),(test_data,test_labels)=imdb.load_data(num_words=10000)
#num_words=10000意思时只保留训练数据中前10000个最常出现的单词,低频单词将被舍弃
#数据集的一些信息,train_data.shape为(25000,)
print(train_data.shape)
print(train_labels[0])
word_index=imdb.get_word_index()#将单词映射为整数索引的字典
reverse_word_index=dict([(value,key) for (key,value) in word_index.items()])#键值颠倒
decoded_review=' '.join([reverse_word_index.get(i-3,'?') for i in train_data[0]])#解码,i-3是因为0,1,2是“填充”,“序列开始”,“未知词”
#查看解码后的数据
print(decoded_review)
#将整数序列编码为二进制矩阵,之后才能够将数据输入到神经网络中
def vectorize_sequences(sequences,dimension=10000):
results=np.zeros((len(sequences),dimension))#创建一个该形状的零矩阵
for i,sequence in enumerate(sequences):
results[i,sequence]=1.
return results
x_train=vectorize_sequences(train_data)#进行向量化
x_test=vectorize_sequences(test_data)
#将标签向量化
y_train=np.asarray(train_labels).astype('float32')
y_test=np.asarray(test_labels).astype('float32')
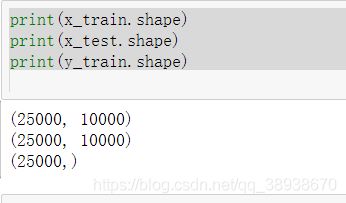
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
解码后的数据如下:

向量化之后的数据形状如下:
#模型定义
#个人理解,哪个compile写在最后的话,最后history返回的字典中就与哪个compile相关,下面
#的训练模型之前又写了个#model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])
#在画图的时候就要注意字典中的关键字key
model=models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
#编译模型
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
#配置自定义优化器的参数
model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss='binary_crossentropy',metrics=['accuracy'])
#使用自定义的损失和指标
model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss=losses.binary_crossentropy,metrics=[metrics.binary_accuracy])
#留出验证集10000个样本,x_val,y_val对应于验证集
#partial_x_train,partial_y_train对应与训练集
x_val=x_train[:10000]
partial_x_train=x_train[10000:]
y_val=y_train[:10000]
partial_y_train=y_train[10000:]
#训练模型,
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
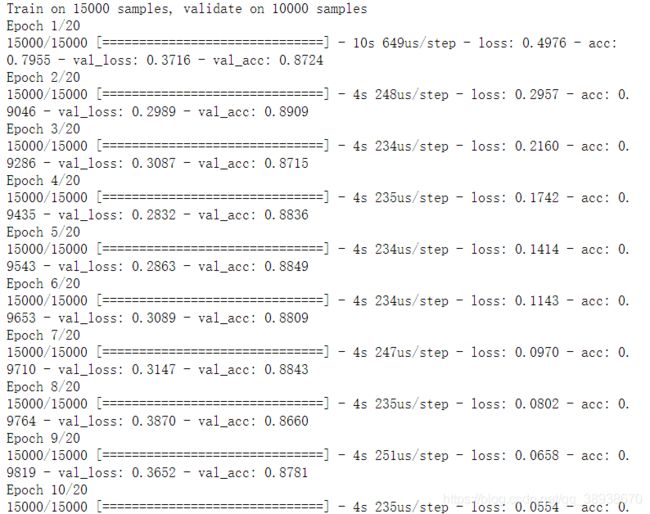
history=model.fit(partial_x_train,partial_y_train,
epochs=20,batch_size=512,
validation_data=(x_val,y_val))
执行fit函数之后的结果如下:(一共迭代20次,图没有截完整,后面会作图显示出来)
#字典中返回4个指标,分别是:验证集损失函数值,验证集精度,训练集损失函数值,训练集精度
history_dict=history.history
print(history_dict.keys())
#输出结果为:dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
#如果去掉最后一个compile,则输出结果为:dict_keys(['val_acc', 'acc', 'val_loss', 'loss'])#绘制字典中的训练和验证损失值图像
history_dict=history.history
loss_values=history_dict['loss']
val_loss_values=history_dict['val_loss']
epochs=range(1,len(loss_values)+1)
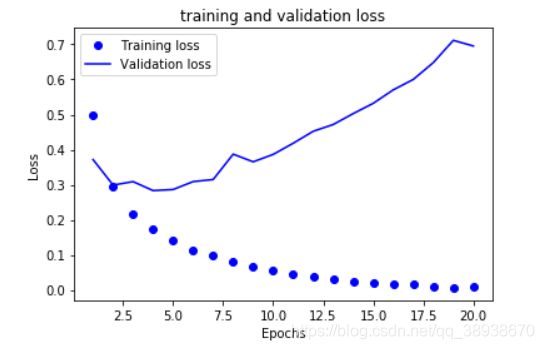
plt.plot(epochs,loss_values,'bo',label='Training loss')#bo表示蓝色原点
plt.plot(epochs,val_loss_values,'b',label='Validation loss')#b表示蓝色实线
plt.title('training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()结果如下图所示:
#绘制训练和验证精度
plt.clf() # clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc_values, 'bo', label='Training acc')
plt.plot(epochs, val_acc_values, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()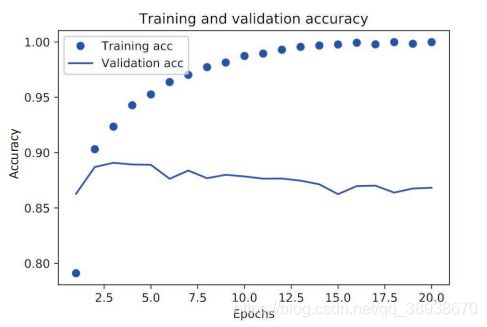
结论:训练损失每轮都在降低,训练精度每轮都在提升,这也符合我们想要的结果;但是验证损失和验证精度确非如此,他们在一定次数的迭代之后结果开始慢慢变差。即模型在训练集上的表现越来越好,但在没有训练过的数据上不一定会越来越好,也就是“过拟合”的情况,所以为了防止过拟合我们可以在第三轮左右就停止训练,通常情况下需要用很多方法来降低过拟合。
#鉴于上面验证数据的表现,下面我们重新训练一个模型,指迭代4次,然后在测试集上评估该模型
model=models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
model.fit(x_train,y_train,epochs=4,batch_size=512)
results=model.evaluate(x_test,y_test)
#results的结果为:[0.29865485565185546, 0.88252]#使用训练好的网络在测试集上生成预测结果
predict_result=model.predict(x_test)
print(predict_result)
print(predict_result.shape)
输出结果如下:
对于某些样本来说该网络非常确认,达到了99%的精度,而对某些样本并不确认,只有10%的精度