知识图谱:小小的入门级综合应用
文章目录
- 导读
- 背景介绍
- 开始从零搭建知识图谱所需的环境
-
- 大前提
- 想法
- Docker安装
- Neo4j安装
-
- 1、拉取镜像
- 2、准备`docker-compose.yml`文件
- 3、启动
- 4、访问
- 5、Python包
- 问题分析
- 编码实现
-
- 全域变量配置
- 数据读取
- 创建节点
- 创建关系
- 整合
- 最后给个主函数
- 运行
导读
本篇文章转载自Voyager-m的博客:知识图谱-用python操纵neo4j数据库-以高速收费站记录为例。已获得原文作者转载许可。本篇与原篇的区别其实只是在一些循环的代码上进行了简化,让看起来很传统的代码缩减了很多。
背景介绍
让我们来想像这样一个场景:
突然有一天,国家突然要查这段高速公路在这段时间内的收费情况,包括车辆租赁、车辆通行等等的数据,然后经过抽样调查就查到了我们现在需要进行学习的数据:点击这里跳转到GitHub查看数据源。如果你需要,请放心下载,这些都是开源的。
开始从零搭建知识图谱所需的环境
好的,最耗时间的数据集准备已经结束了。我们直接开始吧。
因为并不知道人家查证是怎么查,所以这里就随便构建一下,说明一下构建的过程就够了。我们的目的是学习方法,不是抓犯人
为了能够让所有的人都能够上手,我们就从一台光秃秃的电脑开始。
大前提
先说明一下,我使用的环境是:
Ubuntu20.04 20.04 20.04系统Python3.8.5 3.8.5 3.8.5Microsoft Visual Studio1.52.1 1.52.1 1.52.1+Python拓展包neo4j4.2.1 4.2.1 4.2.1
想法
为了简化部署过程,这里就使用Docker部署neo4j,减少很多本地配置的坑。后来经过实践发现,Docker Hub里面的官方镜像并没有内置Vim或者Vi,而且apt命令执行得究极无敌棒槌慢,所以,尽量不要进入Docker修改配置。
Docker安装
这个就直接参考我之前的安装博客,不再赘述啦。
点我查看Windows版Docker安装
点我查看Ubuntu版Docker安装
Neo4j安装
既然是什么都方便的Docker,那么自然步骤就是:
1、拉取镜像
docker pull neo4j
2、准备docker-compose.yml文件
为了方便,我就在本机部署的,于是放在了/usr/local/docker/neo4j这个目录下
# 以下配置可以兼容2.7到3.5的所有版本
version: '3.3'
# 服务
services:
# neo4j服务
neo4j:
# 镜像来源
image: 'neo4j'
# 随着我的物理机的重启而重启
restart: always
# 使用exec命令进去后显示的主机名称
hostname: 'Neo4j-11xx'
# 在物理机的docker列表中显示名称
container_name: 'neo4j_11xx'
# 开启的端口
ports:
# 管理界面访问端口
- '1174:7474'
# 数据传输端口
- '1187:7687'
# 磁盘映射
volumes:
- /usr/local/docker/neo4j/data:/data
3、启动
docker-compose up -d
4、访问
打开浏览器(虽然知道是废话,但还是叮嘱一句:Windows用户别用IE打开)
然后访问http://localhost:1174这个网址(我们刚刚在docker-compose.yml中开启的是这个端口)。
初始用户名是neo4j,初始密码是neo4j,初始数据库是neo4j。不写是哪个数据库将会默认进入neo4j数据库。对于小白来说,保持空白就好了。
5、Python包
在物理机内,Windows用户可能需要使用Git Bash窗口进行包的安装,而Ubuntu直接使用Ctrl+Alt+T呼出终端安装,命令都是一样的:
pip3 install py2neo
这里就做一回强迫症,直接下最新的,别考虑最早支持的版本。
问题分析
- 如果网址进不去,先考虑是不是端口号输错了,比如明明你从 1174 1174 1174端口能够打开登录界面,却在登录界面使用 7474 7474 7474端口访问数据库。这就像是明明知道你得的是感冒,却拿了一瓶跌打油;
- 接着再考虑一下是不是镜像选错了。虽然
Docker Hub中的镜像很多,但还是尽量使用官方镜像,因为有足够丰富的文档支撑。
编码实现
好了,到这里,环境搭完了,我们就开始吧。
全域变量配置
# 配置类
class CONFIG(enumerate):
# Neo4j访问地址
URL = 'http://localhost:1174'
# 用户名
USERNAME = 'neo4j'
# 密码
PASSWORD = 'ljx62149079'
# xls文件路径
XLS = os.getcwd() + '/knowledge/data.xls'
# csv文件路径
CSV = os.getcwd() + '/knowledge/data.csv'
pass
数据读取
还是老朋友pandas:
# 数据导入类
class DataImporter:
# 类构造器
def __init__(self):
# 直接从Excel里面读取所有的原生数据
# self.raw_data = pd.read_excel(CONFIG.XLS)
self.raw_data = pd.read_csv(CONFIG.CSV)
# 将所有的数据提取到一维数组中(去重)
self.all_data = list(
# 使用集合去掉重复的
set(
[
# 将一维数组所有的数据化为字符串
str(i) for i in list(
# 将二维数组改为一维数组
itertools.chain(
# 根据列属性一一列出表格中所有的行数据
*[item for item in self.raw_data[[
# 列出所有的列属性
column for column in self.raw_data.columns
]].values]
)
)
]
)
)
# 所有的购买方(去重)
self.buyer_list = list(set(self.raw_data['购买方名称']))
# 所有的销售方(去重)
self.seller_list = list(set(self.raw_data['销售方名称']))
# 所有原生数据的映射
self.dict = pd.DataFrame({
# 所有的金额(原生)
'finance': list(self.raw_data['金额']),
# 所有的购买方(原生)
'buyer': list(self.raw_data['购买方名称']),
# 所有的销售方(原生)
'seller': list(self.raw_data['销售方名称'])
})
'''
别忘了加上neo4j数据库访问
'''
# 图数据库对象
self.graph = Graph(
CONFIG.URL,
username=CONFIG.USERNAME,
password=CONFIG.PASSWORD
)
# 清空缓存
self.graph.delete_all()
# 配对器
self.matcher = NodeMatcher(self.graph)
pass
创建节点
既然数据读取可以了,那么我们就可以继续在类里面添加方法:
class DataImporter:
# 传入购买方、销售方数据
def create_tree_node(self, buyers, sellers):
for key in buyers: # 根据购买方创建节点
self.graph.create(
Node('buyer', name=key)
)
pass
for key in sellers: # 根据销售方创建节点
self.graph.create(
Node('seller', name=key)
)
pass
pass
pass
创建关系
class DataImporter:
def create_nodes_relation(self):
# 对于字典中所有的数据
for item in range(0, len(self.dict)):
try:
self.graph.create(
# 关系映射
Relationship(
self.matcher.match('buyer')
.where("_.name='" + self.dict['buyer'][item] + "'")
.first(),
self.dict['finance'][item],
self.matcher.match('seller')
.where("_.name='" + self.dict['seller'][item] + "'")
.first()
)
)
pass
# 如果出错,显示错误。增强程序健壮性
except AttributeError as ae:
print(ae, item)
pass
pass
pass
pass
整合
既然我们把零零碎碎的东西农好了之后,我们就开始整合:
# -*- coding: utf-8 -*-
import pandas as pd
import itertools
import os
from py2neo import Node, Graph, Relationship, NodeMatcher, data
# 配置类
class CONFIG(enumerate):
# Neo4j访问地址
URL = 'http://localhost:1174'
# 用户名
USERNAME = 'neo4j'
# 密码
PASSWORD = 'ljx62149079'
# xls文件路径
XLS = os.getcwd() + '/knowledge/data.xls'
# csv文件路径
CSV = os.getcwd() + '/knowledge/data.csv'
pass
# 数据导入类
class DataImporter:
# 类构造器
def __init__(self):
# 直接从Excel里面读取所有的原生数据
# self.raw_data = pd.read_excel(CONFIG.XLS)
self.raw_data = pd.read_csv(CONFIG.CSV)
# 将所有的数据提取到一维数组中(去重),没用...
# self.all_data = list(set([str(i) for i in list(itertools.chain(*[item for item in self.raw_data[[column for column in self.raw_data.columns]].values]))]))
# 所有的购买方(去重)
self.buyer_list = list(set(self.raw_data['购买方名称']))
# 所有的销售方(去重)
self.seller_list = list(set(self.raw_data['销售方名称']))
# 所有原生数据的映射
self.dict = pd.DataFrame({
# 所有的金额(原生)
'finance': list(self.raw_data['金额']),
# 所有的购买方(原生)
'buyer': list(self.raw_data['购买方名称']),
# 所有的销售方(原生)
'seller': list(self.raw_data['销售方名称'])
})
# 图数据库对象
self.graph = Graph(
CONFIG.URL,
username=CONFIG.USERNAME,
password=CONFIG.PASSWORD
)
# 清空缓存
self.graph.delete_all()
# 配对器
self.matcher = NodeMatcher(self.graph)
pass
# 创建节点方法
def create_tree_node(self, buyers, sellers):
for key in buyers: # 根据购买方创建节点
self.graph.create(
Node('buyer', name=key)
)
pass
for key in sellers: # 根据销售方创建节点
self.graph.create(
Node('seller', name=key)
)
pass
pass
# 创建节点间关系
def create_nodes_relation(self):
# 对于字典中所有的数据
for item in range(0, len(self.dict)):
try:
self.graph.create(
Relationship(self.matcher.match('buyer').where("_.name='" + self.dict['buyer'][item] + "'").first(), self.dict['finance'][item], self.matcher.match('seller').where("_.name='" + self.dict['seller'][item] + "'").first())
)
pass
# 如果出错,显示错误,增强程序健壮性
except AttributeError as ae:
print(ae, item)
pass
pass
pass
pass
这段你可以在我的GitHub中下载
最后给个主函数
if __name__ == '__main__':
# 数据导入类
dataImpoter = DataImporter()
# 创建实体节点
dataImpoter.create_tree_node(dataImpoter.buyer_list, dataImpoter.seller_list)
# 创建实体节点间的关系
dataImpoter.create_nodes_relation()
pass
运行
运行之后,啥都没有,就退出了。
你觉得失败了?当然没有,我们进入浏览器看看:http://localhost:1174,会发现一个界面:

在网址栏下面有个灰色的地方,有个淡淡的neo4j$(得仔细看),我们在这里输入:
MATCH p=()-->() RETURN p LIMIT 25
点击正右端的三角形,也就是运行按钮;如果你想方便也可以按回车。于是能够看到:
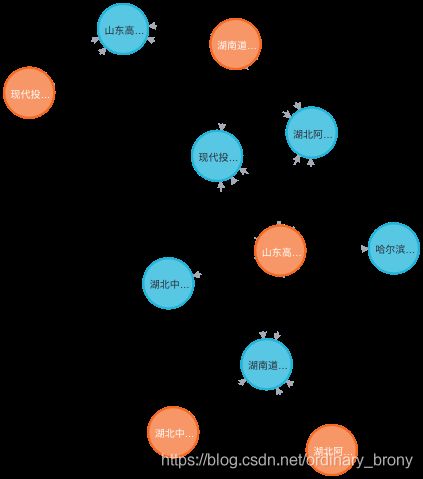
这就是neo4j给出的知识图谱。
看起来还不错!
是不是有点能理解了呢?