实战|Hadoop大数据集群搭建
一个执着于技术的公众号
前言
今天来为粉丝圆梦啦

话不多说,咱直接进入实战环节
实验环境:

主机名 IP地址 角色
qll251 192.168.1.251 NameNode
qll252 192.168.1.252 DataNode1
qll253 192.168.1.253 DataNode2
所需软件包:
hadoop-2.9.2.tar.gz
jdk-8u241-linux-x64.tar.gz
软件包下载地址:
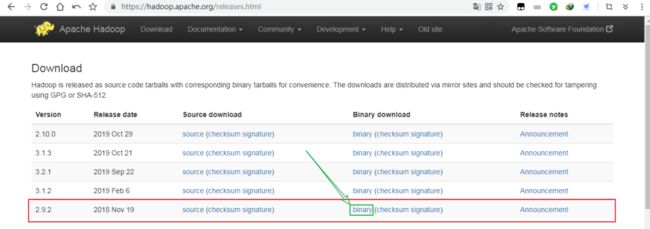
Hadoop软件包官方下载地址:
https://hadoop.apache.org/releases.html
【今天我们以2.9.2版本为例,搭建出一套Hadoop大数据集群】
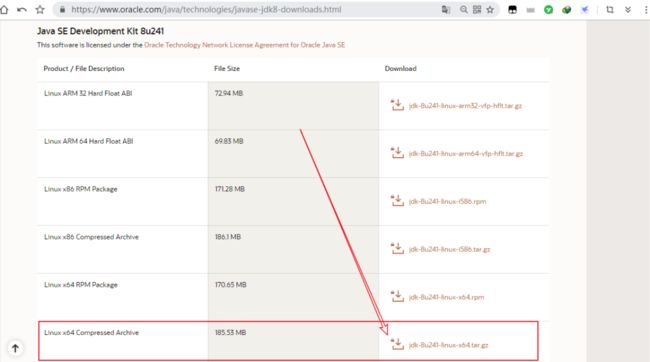
jdk软件包官方下载地址:
https://www.oracle.com/java/technologies/javase-jdk8-downloads.html
开始搭建
[本次实验,三台机器操作系统均采用CentOS7.5,同时关闭防火墙、关闭selinux]
1、在qll251上配置免密登录
配置在qll251上,可以ssh无密码登录qll251,qll252,qll253
[root@qll251 ~]# ssh-keygen //一路回车即可
[root@qll251 ~]#ssh-copy-id [email protected]
[root@qll251 ~]#ssh-copy-id [email protected]
[root@qll251 ~]#ssh-copy-id [email protected]
2、三台机器上配置hosts文件,如下:
1)首先在192.168.1.251主机配置hosts

2)复制hosts到其它两机器:
[root@qll251 ~]# scp /etc/hosts [email protected]:/etc
[root@qll251 ~]# scp /etc/hosts [email protected]:/etc
注意:
在/etc/hosts中,不要把机器名字同时对应到127.0.0.1这个地址,否则会导致数据节点连接不上namenode,报错如下:
org.apache.hadoop.ipc.Client:Retrying connect to server: master/192.168.1.251:9000
3、在三台节点上创建运行Hadoop用户
useradd -u 8000 hadoop
echo 123123 | passwd --stdin hadoop
注意:三台节点都需要创建hadoop用户,保持UID一致。
4、在三台节点上安装Java环境 JDK
1)我们先在qll251主机上配置jdk环境
【把 jdk-8u241-linux-x64.tar.gz 上传至/home下】
[root@qll251 home]# tar -zxvf jdk-8u241-linux-x64.tar.gz -C /usr/local
# 将jdk解压至/usr/local/下
2)配置jdk环境变量
# 编辑 /etc/profile,在文件最后添加以下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_241
export JAVA_BIN=/usr/local/jdk1.8.0_241/bin
export PATH=${JAVA_HOME}/bin:$PATH
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
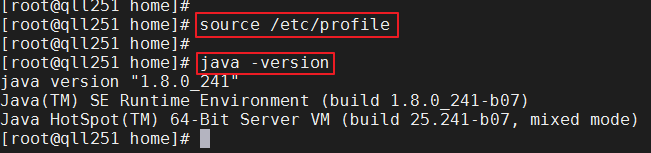
3)执行:
source /etc/profile #使配置文件生效
java -version #验证java运行环境是否安装成功
4)将jdk部署到另外两台机器上
[root@qll251 ~]# scp -r /usr/local/jdk1.8.0_241/ qll252:/usr/local
[root@qll251 ~]# scp -r /usr/local/jdk1.8.0_241/ qll253:/usr/local
[root@qll251 ~]# scp /etc/profile qll252:/etc/
[root@qll251 ~]# scp /etc/profile qll253:/etc/
使新建立的环境变量立刻生效
[root@qll252 ~]# source /etc/profile
[root@qll253 ~]# source /etc/profile
4、在qll251安装Hadoop 并创建相应的工作目录
1)解压Hadoop安装文件
【把 jdk-8u241-linux-x64.tar.gz 上传至/home下】
[root@qll251 home]# tar -zxf hadoop-2.9.2.tar.gz -C /home/hadoop/
#我们把Hadoop的安装目录解压在:/home/hadoop/hadoop-2.9.2

2)创建hadoop相关的工作目录
[root@qll251 ~]# mkdir -p /home/hadoop/tmp /home/hadoop/dfs/{name,data}

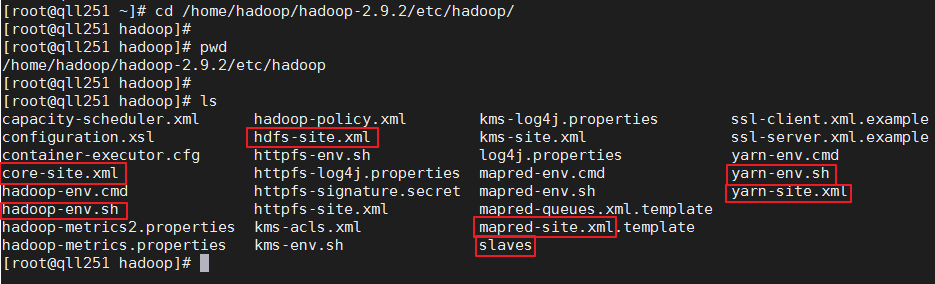
5、在qll251节点配置Hadoop
配置文件位置:/home/hadoop/hadoop-2.9.2/etc/hadoop
一共需要修改7个配置文件:
1)hadoop-env.sh,指定hadoop的java运行环境
该文件是hadoop运行基本环境的配置,需要修改的为java虚拟机的位置。
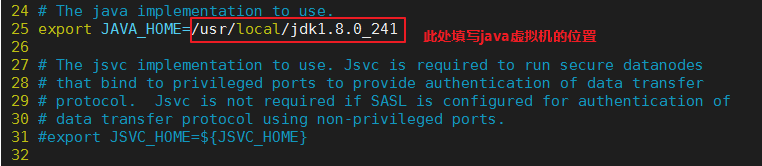
2)yarn-env.sh,指定yarn框架的java运行环境
该文件是yarn框架运行环境的配置,同样需要修改java虚拟机的位置。

3)配置文件slaves ,指定datanode 数据存储服务器
将所有DataNode的名字写入此文件中,每个主机名一行,配置如下:

4)配置文件core-site.xml,指定访问hadoop web界面访问路径
hadoop的核心配置文件,这里需要配置两个属性,fs.default.FS配置了hadoop的HDFS系统的命名,位置为主机的9000端口;
hadoop.tmp.dir配置了hadoop的tmp目录的根位置。
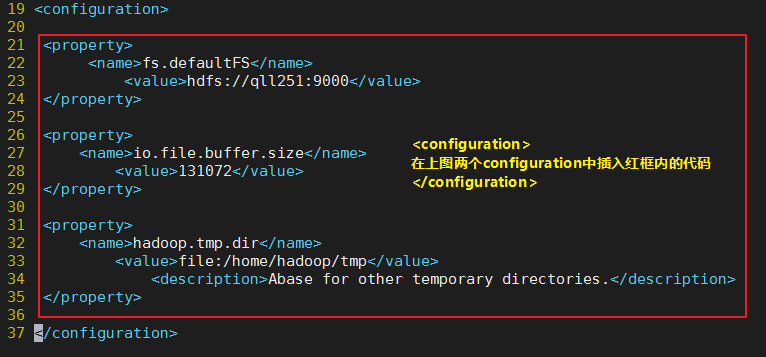
提供下源代码:
fs.defaultFS
hdfs://qll251:9000
io.file.buffer.size
131072
hadoop.tmp.dir
file:/home/hadoop/tmp
Abase for other temporary directories.
5)配置文件hdfs-site.xml
hdfs的配置文件,dfs.http.address配置了hdfs的http的访问位置;
dfs.replication配置了文件块的副本数,一般不大于从机的个数。

提供下源代码:
dfs.namenode.secondary.http-address
qll251:9001
dfs.namenode.name.dir
file:/home/hadoop/dfs/name
dfs.datanode.data.dir
file:/home/hadoop/dfs/data
dfs.replication
2
dfs.webhdfs.enabled
true
6)配置文件mapred-site.xml
mapreduce任务的配置,由于hadoop2.x使用了yarn框架,所以要实现分布式部署,必须在mapreduce.framework.name属性下配置为yarn。mapred.map.tasks和mapred.reduce.tasks分别为map和reduce的任务数。
# 生成mapred-site.xml
[root@qll251 hadoop]# cp mapred-site.xml.template mapred-site.xml
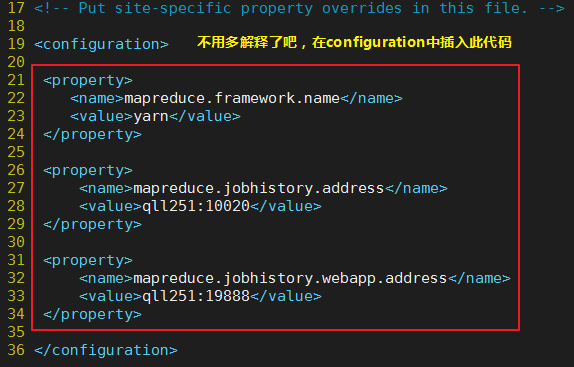
提供下源代码:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
qll251:10020
mapreduce.jobhistory.webapp.address
qll251:19888
7)配置节点yarn-site.xml
该文件为yarn框架的配置,主要是一些任务的启动位置

提供下源代码:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
qll251:8032
yarn.resourcemanager.scheduler.address
qll251:8030
yarn.resourcemanager.resource-tracker.address
qll251:8031
yarn.resourcemanager.admin.address
qll251:8033
yarn.resourcemanager.webapp.address
qll251:8088
6、修改hadoop安装文件的所属者及所属组
[root@qll251]# chown -R hadoop.hadoop /home/hadoop

7、设置qll251主机上的hadoop普通用户免密登录
生成基于hadoop用户的不输入密码登录:因为后期使用hadoop用户启动datenode节点需要直接登录到对应的服务器上启动datenode相关服务
# step 1:切换hadoop用户
[root@qll251 ~]# su - hadoop
[hadoop@qll251 ~]$
# step 2:创建密钥文件
[hadoop@qll251 ~]$ ssh-keygen
# step 3:将公钥分别copy至qll251,qll252,qll253
[hadoop@qll251 ~]$ ssh-copy-id hadoop@qll251
[hadoop@qll251 ~]$ ssh-copy-id hadoop@qll252
[hadoop@qll251 ~]$ ssh-copy-id hadoop@qll253
8、将hadoop安装文件复制到其他DateNode节点
[root@qll251 ~]# su - hadoop
[hadoop@qll251 ~]$
[hadoop@qll251 ~]$ scp -r /home/hadoop/hadoop-2.9.2/ hadoop@qll252:~/
[hadoop@qll251 ~]$ scp -r /home/hadoop/hadoop-2.9.2/ hadoop@qll253:~/
9、qll251上启动Hadoop
1)格式化namenode
首先切换到hadoop用户,执行hadoop namenode的初始化,只需要第一次的时候初始化,之后就不需要了。

如果所示,format成功
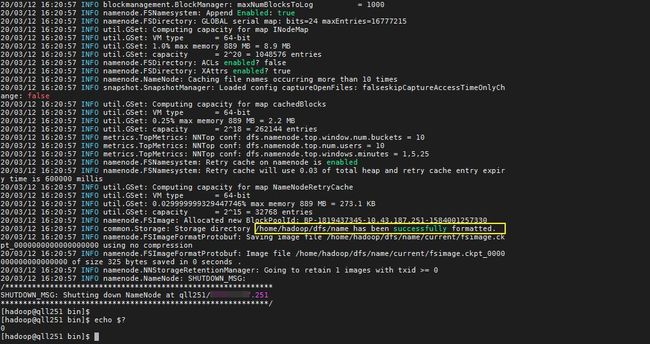
我们查看下格式化后生成的文件吧;

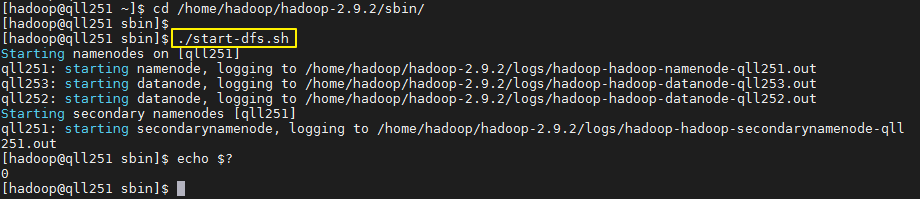
2)启动hdfs:./sbin/start-dfs.sh,即启动HDFS分布式存储
3)启动yarn:./sbin/start-yarn.sh 即,启动分布式计算
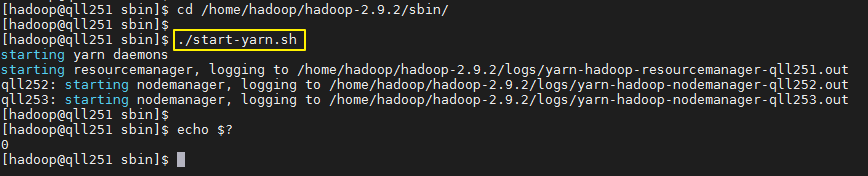
注意:
其实我们也可以使用 start-all.sh脚本依次启动HDFS分布式存储及分布式计算。
/home/hadoop/hadoop-2.9.2/sbin/start-all.sh #启动脚本
/home/hadoop/hadoop-2.9.2/sbin/stop-all.sh # 关闭脚本
4)启动历史服务
Hadoop自带历史服务器,可通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器

开启后,可以通过Web页面查看历史服务器:
http://192.168.1.251:19888

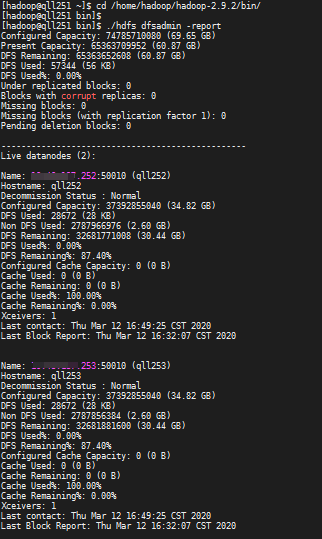
10、我们验证下搭建的集群服务运行是否正常
1)查看HDFS分布式文件系统状态:
2)Web查看HDFS: http://192.168.1.251:50070

3)Web查看hadoop集群状态: http://192.168.1.251:8088

4)Web查看历史服务器:http://192.168.1.251:

总结
本文的思路是:以安装部署Apache Hadoop2.x版本为主线,来介绍Hadoop2.x的架构组成、各模块协同工作原理、技术细节。安装不是目的,通过安装认识Hadoop才是目的。

往期精彩
◆ 干货 | 手把手教你如何搭建一个私有云盘
◆ 干货 | Linux平台搭建网关服务器
◆ 干货 | Linux主流发行版配置IP总结
◆ 硬核科普服务器硬盘组成与基本原理
◆ 一文带你速懂虚拟化KVM和XEN
◆ 什么是集群?看完这篇你就知道啦!
