论文学习笔记-MobileNet v3
『写在前面』
新一代MobileNet,性能全面提升。
作者机构:Andrew Howard等,Google。
文章标题:《Searching for MobileNetV3》
原文链接:https://arxiv.org/abs/1905.02244v2
相关repo:
目录
摘要
1 本文贡献
2 相关工作
3 高效移动端构建模块
4 网络改进
4.1 重新设计成本高昂层
4.2 非线性
激活函数
Large squeeze-and-excite
4.3 MobileNet-v3定义
5 实验
5.1 结果
5.2 分解研究
非线性激活
其他组件
5.3 MobileNet-v3 X Detection
5.4 MobileNet-v3 X Semantic Segmentation
摘要
- 结合网络设计和NAS技术提出新一代MobileNets;
- 发布了两种网络结构:MobileNetV3-Large和MobileNetV3-Small以适配不同的资源消耗场景;
- 针对语义分割任务,提出一种新的高效分割编码器LR-ASPP;
- 在移动端分类、检测、分割任务上达到新的SOAT;
- 简而言之,在分类任务上,V3-Large更准较慢,V3-Small次之较快;在检测任务上,V3-Large在与V2达到相同精度的情况下,速度提升25%;在分割任务上,V3-Large with LR-ASPP在与V2 with R-ASPP达到相同精度的情况下,速度提升30%。
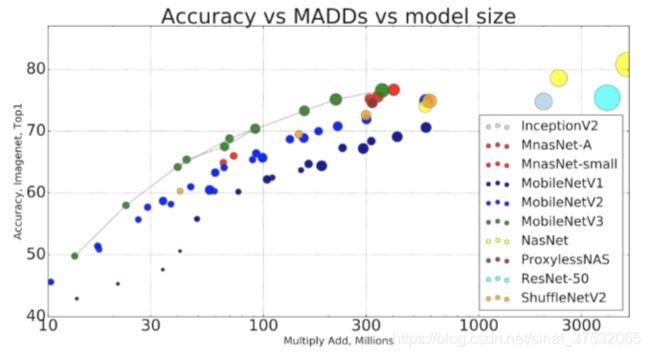
1 本文贡献
- 互补搜索技术 —— NAS & NetAdapt
- 适用于移动设备的新的有效的非线性版本 —— hard swish
- 新的高效网络设计 —— Large / Small
- 新的高效分割解码器 —— LR-ASPP
2 相关工作
- SqueezeNet:提出Fire Module设计,主要思想是先通过1x1卷积压缩通道数(Squeeze),再通过并行使用1x1卷积和3x3卷积来抽取特征(Expand),通过延迟下采样阶段来保证精度。综合来说,SqueezeNet旨在减少参数量来加速。
- 通过减少MAdds来加速的轻量模型:
- MobileNet V1:提出深度可分离卷积;
- MobileNet V2:提出反转残差线性瓶颈块;
- ShuffleNet:结合使用分组卷积和通道混洗操作;
- CondenseNet
- ShiftNet
3 高效移动端构建模块
MobileNet-v1中深度可分离卷积的理解
将传统卷积分解为空间滤波和特征生成两个步骤,空间滤波对应较轻的3x3 depthwise conv layer,特征生成对应较重的1x1 pointwise conv layer.
MobileNet-v2中反转残差线性瓶颈块的理解
- 扩张(1x1 conv) -> 抽取特征(3x3 depthwise)-> 压缩(1x1 conv)
- 当且仅当输入输出具有相同的通道数时,才进行残余连接
- 在最后“压缩”完以后,没有接ReLU激活,作者认为这样会引起较大的信息损失
- 该结构在输入和输出处保持紧凑的表示,同时在内部扩展到更高维的特征空间,以增加非线性每通道变换的表现力。
MnasNet理解
在MobileNet-v2的基础上构建,融入SENet的思想
与SE-ResBlock相比,不同点在于SE-ResBlock的SE layer加在最后一个1x1卷积后,而MnasNet的SE layer加在depthwise卷积之后,也就是在通道数最多的feature map上做Attention。
MobileNet-v3集现有轻量模型思想于一体,主要包括:
- swish非线性激活
- Squeeze and Excitation思想
- 为了减轻计算swish中传统sigmoid的代价,提出了hard sigmoid
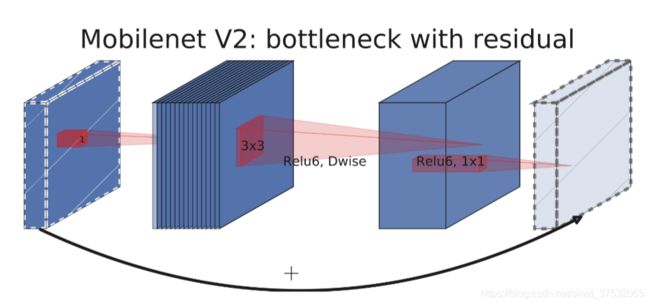
下图为MobileNet-v2 block示意图。可以看到,在其中第一个1x1卷积和输出层是不含有非线性操作的,中间3x3 depthwise卷积和最后用来压缩通道数的1x1卷积使用了ReLU6作为非线性激活。还有一点,残差连接使用相加,不是扩展(拼接)。
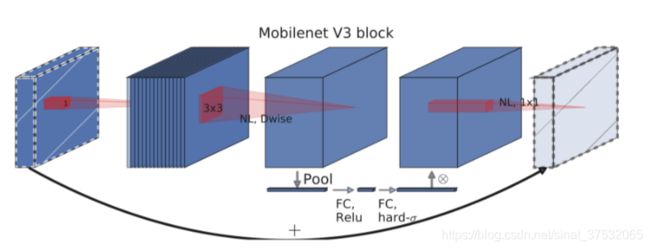
下图为MobileNet-v2 + Squeeze-and-Excite(MobileNet-v3 block)示意图。与MnasNet相同,在depthwise卷积后进行SE操作,不同点在于使用了新的非线性。
4 网络改进
4.1 重新设计成本高昂层
最靠前和最靠后的层往往具有更高的复杂性。
改进一
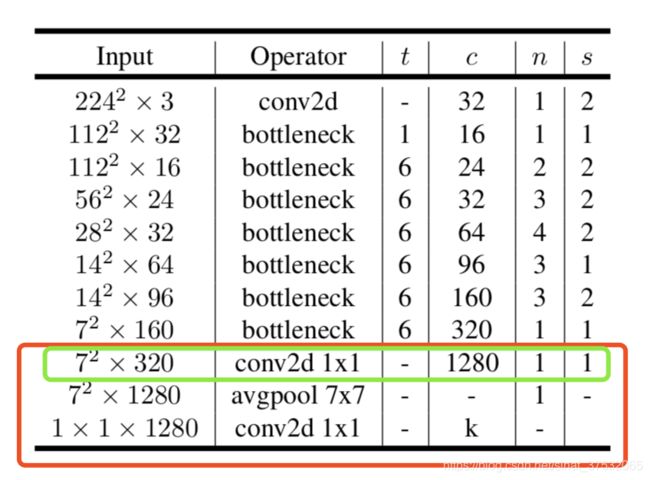
首先是最靠后部分的修改,也就是预测部分的修改。下图是MobileNet-v2的整理模型架构,可以看到,网络的最后部分首先通过1x1卷积映射到高维,然后通过GAP收集特征,最后使用1x1卷积划分到K类。所以其中起抽取特征作用的是在7x7分辨率上做1x1卷积的那一层。
再看MobileNet-v3,上图为large,下图为small。按照刚刚的思路,这里首先将特征进行Pooling,然后再通过1x1卷积抽取用于训练最后分类器的特征,最后划分到k类。作者的解释是: This final set of features is now computed at 1x1 spatial resolution instead of 7x7 spatial resolution.


通过这一次改进,节省了15%的耗时(~10ms),减少了大约3000万次乘加运算,但几乎没有损失精度。
下图为原始的预测部分和改进版预测部分的结构对比。
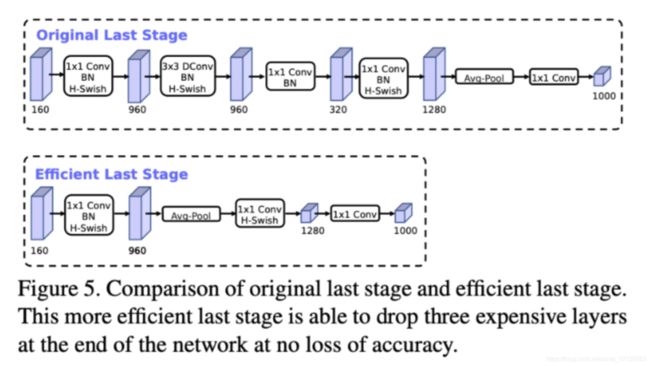
改进二
现有的移动端模型倾向于使用32个标准3*3卷积来构建最初的滤波器组,定性角度来看,这一个滤波器组起到的作用往往是检测边缘。
得益于hard swish的设计,经过试验可以在不损失精度的情况下降滤波器的个数从32减少到16。
这一改进可以节省3ms时间,1000万次乘加运算。
4.2 非线性
激活函数
swish激活函数
swish激活函数已经被证明是一种ReLU更佳的非线性激活,但是相比ReLU,它的计算更复杂,因为有sigmoid函数。为了能够在移动设备上应用swish,并降低它的计算开销,作者做了两个改进:
hard-swish
使用分段线性函数模拟sigmoid函数,具体形式是:
![]()
以下是平滑版本的Sigmoid/Swish和Hard版本的Sigmoid/Swish对比:
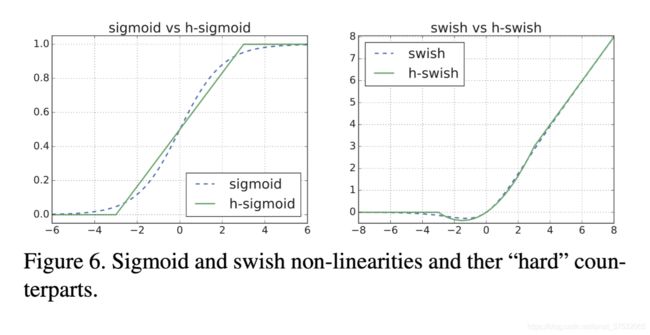
为什么是ReLU6?本文指出的是为了兼顾简单性和与Smooth版本的匹配程度,其他文章中还说到了一方面是为了量化,最多3bit;另一方面,迫使网络去学习更稀疏的特征。
作者认为,h-swish在对模型精度没有明显影响的情况下,具有诸多显著优势:
1)几乎所有的软硬件框架都提供了ReLU6的优化实现;
2)在量化模式下,减轻了不同实现下Sigmoid引起的精度误差;
3)(不足)即使使用量化版本的sigmoid,也往往比ReLU慢。在本文实验中,使用量化模式下的h-swish比使用原版swish快15%。
延迟使用h-swish
随着网络的加深,feature map分辨率逐渐变小,在此上面应用非线性激活的成本逐渐降低。所以在MobileNet-v3模型设计上,作者刻意将h-swish使用在网络靠后的部分上。
尽管使用h-swish相比ReLU还是会带来一定的延迟,但相对于其带来的精度的提升是积极的。而且量化版的h-swish还可以进一步通过软件优化:一旦将Sigmoid转化为分段线性函数,那么实际计算的时候大部分的开销都转变成对内存的访问开销,这是可以通过与前一层进行融合来消除的。
Large squeeze-and-excite
将SE layer的通道数固定为扩展层的1/4。这样做在轻微增加参数量的情况下,提高了精度,但没有带来明显的延迟。
4.3 MobileNet-v3定义
如下图所示,分large、small两款,分别针对高资源和低资源使用情况。
这些模型通过应用平台感知NAS和NetAdapt进行网络搜索,并结合本节中定义的网络改进所提出。
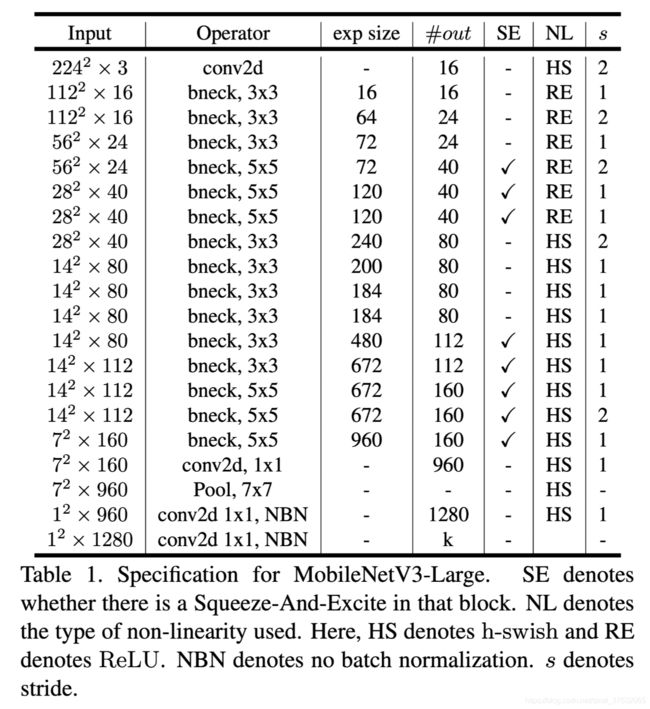 MobileNet-v3 Large
MobileNet-v3 Large
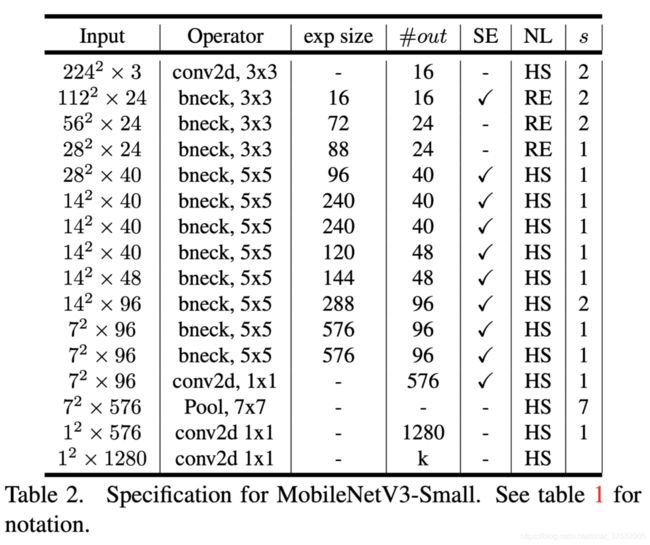 MobileNet-v3 Small
MobileNet-v3 Small
5 实验
5.1 结果
浮点模式下在ImageNet上的精度表现,以及在Pixel Phone上的耗时统计。
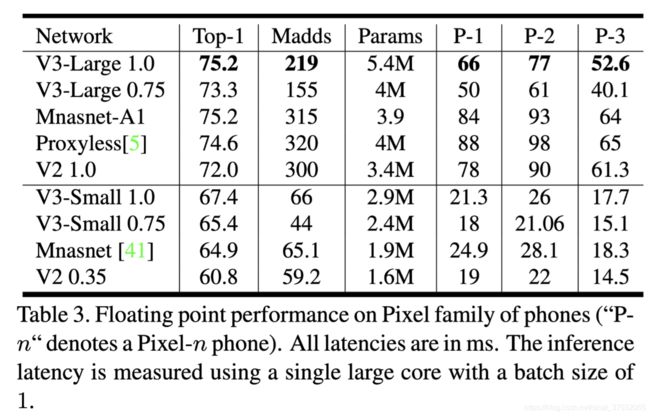
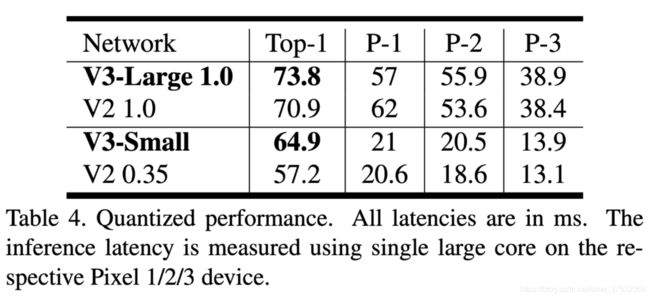
量化模式下。
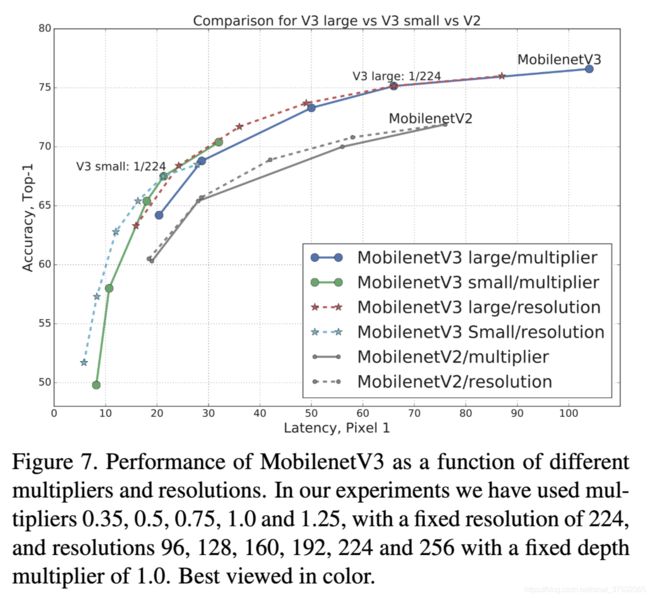
性能trade-off。一种是固定分辨率,改变通道数缩放比例(0.35, 0.5, 0.75, 1.0, 1.25);另一种是固定通道数,改变输入分辨率(96, 128, 160, 192, 224, 256)。
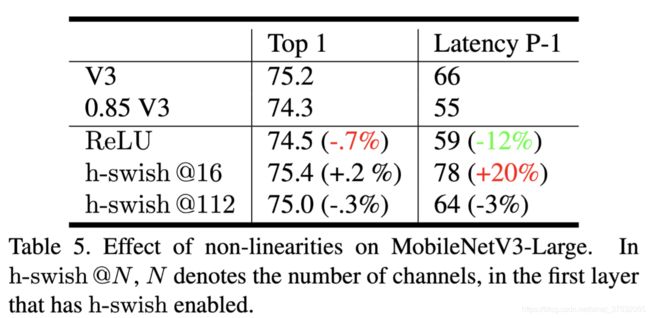
5.2 分解研究
非线性激活
在整个网络上使用h-swish可以提高0.2精度,但延迟+20%.
H-swish尽管增加了12%开销,但是相比ReLU,moves the efficient frontier up.
同时,与ReLU相比,h-swish可以通过与卷积操作融合来进一步减弱或消除延迟,但这个trick没办法用在h-swish和swish之间,因为计算sigmoid仍然是比较慢的。
其他组件
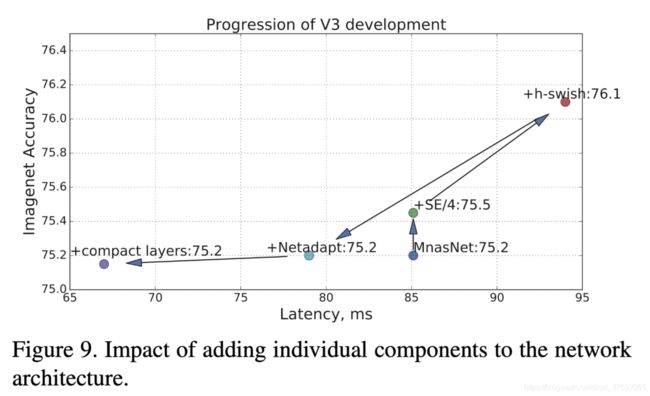
5.3 MobileNet-v3 X Detection
将MobileNet-v3作为SSD-Lite的特征提取器使用。
延续SSD-Lite的设计思路:抽取的第一个feature map是下采样16倍的尺寸,第二个是32倍。以224*224为例,第一个是14*14,第二个是7*7。
使用和其他检测文献中相近的描述:第一个层称为C4,在Large里对应第13个瓶颈块,在Small里对应第9个瓶颈块;第二个层成为C5,均对应pooling前的那一层。
最终在COCO上的表现如下图所示。
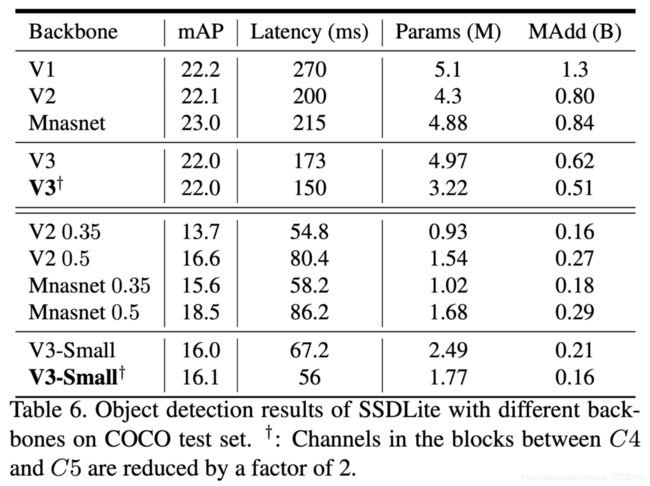
因为channel数减少,V3 large比V2快25%的同时,精度相近。
对两种型号的V3,通道减少技巧有助于降低15%的延迟的同时, 没有引起mAP损失。这表明ImageNet分类和COCO检测可能偏好不同的特征。V3-small减通道数版本反而表现更好。
与V2-0.35和Mnasnet-0.35相比,V3-small的mAP超过2.4和0.5。之所以与它们进行比较的原因是耗时/运算量相当。
5.4 MobileNet-v3 X Semantic Segmentation
基于R-ASPP,设计了轻量版R-ASPP,LR-ASPP。以类似SE模块的方式,使用了全局平均池化。使用了大步幅的池化内核,和仅仅1个1*1卷积。在V3最后一个block的基础上,使用膨胀卷积提取更深层特征。此外,从low-level引出跳跃连接以进一步捕捉细节信息。
与检测模型类似,通道数减半的trick在这里同样好使。
在Cityscapes验证集上的表现如下:

- 减少通道数的情况下保持了相似的精度,row1 vs 2,row5 vs 6;
- 提出的LR-ASPP在比R-ASPP快的同时,还改善了性能,row2vs3, row6vs7;
- 减少分割头的通道数一半,轻微降低了精度,但相比提高了速度,row3vs4,row7vs8;
- v2与v3在采取相同配置的情况下,v3可以和v2达到类似的性能,但耗时都有比较明显的提升,1vs5,2vs6,3vs7,4vs8;
- v3-small和v2-0.5性能类似,但速度更快,11vs9;
- v3-small明显比v2-0.35更好,速度相当。
在Cityscapes测试集上的表现如下:
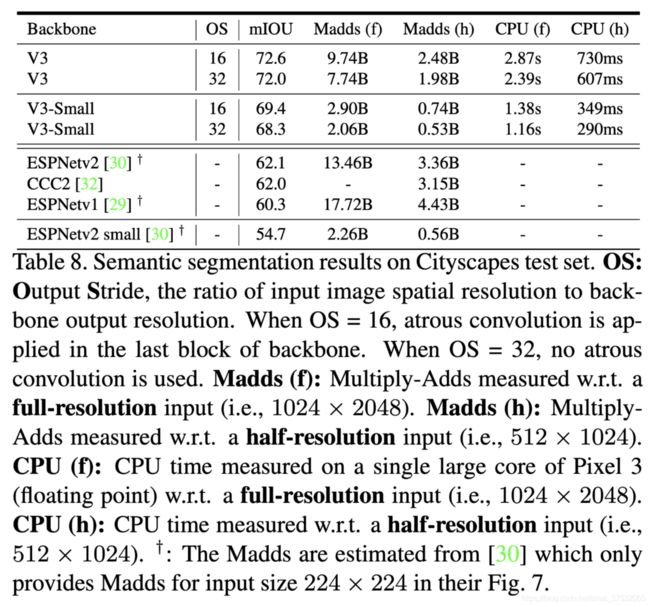
可以看到, 使用MobileNet-v3作为backbone的分割模型在mIOU上明显优于ESPNet和CCC2。而在乘加运算量上也少很多。