前言
文本已收录至我的GitHub仓库,欢迎Star: https://github.com/bin3923282...
种一棵树最好的时间是十年前,其次是现在
Tips
面试指南系列,很多情况下不会去深挖细节,是小六六以被面试者的角色去回顾知识的一种方式,所以我默认大部分的东西,作为面试官的你,肯定是懂的。
https://www.processon.com/vie...
上面的是脑图地址
叨絮
分布式系统开发,微服务架构的一种主流实现方式,当然在面试中是必不可少的拉。
然后下面是前面的文章汇总
- 2021-Java后端工程师面试指南-(引言)
- 2021-Java后端工程师面试指南-(Java基础篇)
- 2021-Java后端工程师面试指南-(并发-多线程)
- 2021-Java后端工程师面试指南-(JVM)
- 2021-Java后端工程师面试指南-(MySQL)
- 2021-Java后端工程师面试指南-(Redis)
- 2021-Java后端工程师面试指南-(Elasticsearch)
- 2021-Java后端工程师面试指南-(消息队列)
- 2021-Java后端工程师面试指南-(SSM)
什么是SpringBoot呢
简而言之,从本质上来说,Spring Boot 就是 Spring,它做了那些没有它你自己也会去做的 Spring Bean 配置。基于约定大于配置的一个理论
说说SpringBoot的特点吧
- 开发基于 Spring 的应用程序很容易。
- Spring Boot 项目所需的开发或工程时间明显减少,通常会提高整体生产力。
- Spring Boot 不需要编写大量样板代码、XML 配置和注释。
- Spring 引导应用程序可以很容易地与 Spring 生态系统集成,如 Spring JDBC、Spring ORM、Spring Data、Spring Security 等。
- Spring Boot 遵循“固执己见的默认配置”,以减少开发工作(默认配置可以修改)。
- Spring Boot 应用程序提供嵌入式 HTTP 服务器,如 Tomcat 和 Jetty,可以轻松地开发和测试 web 应用程序。(这点很赞!普通运行 Java 程序的方式就能运行基于 Spring Boot web 项目,省事很多)
说说@SpringBootApplication 这个注解吧
可以看出大概可以把 @SpringBootApplication 看作是 @Configuration、@EnableAutoConfiguration、@ComponentScan 注解的集合。根据 SpringBoot官网,这三个注解的作用分别是:
- @EnableAutoConfiguration:启用 SpringBoot 的自动配置机制
- @ComponentScan: 扫描被@Component (@Service,@Controller)注解的bean,注解默认会扫描该类所在的包下所有的类。
- @Configuration:允许在上下文中注册额外的bean或导入其他配置类。
-所以说 @SpringBootApplication 就是几个重要的注解的组合,为什么要有它?当然是为了省事,避免了我们每次开发 Spring Boot 项目都要写一些必备的注解。这一点在我们平时开发中也 经常用到,比如我们通常会提一个测试基类,这个基类包含了我们写测试所需要的一些基本的注解和一些依赖。
知道SpringBoot的钩子函数吗,如何对你项目的启动和死亡做监控。
- 启动的时候,比如CommandLineRunner 重写它的run方法,就能在启动的时候做一个钩子函数,比如链接钉钉等
- 意外宕机也是可以的, @PreDestroy 这个注解也能实现,在宕机之前回调这个方法,实现钉钉机器人等。
了解spring boot 中的spring factories 机制吗?
Spring Factories.这种机制实际上是仿照java中的SPI扩展机制实现的。
spring -core 包里定义了SpringFactoriesLoader 类,这个类实现了检索META-INF/spring.factories文件,并获取指定接口的配置的功能。 在这个类中定义了两个对外的方法:
-loadFactories 根据接口类获取其实现类的实例,这个方法返回的是对象列表
- loadFactoryNames 根据接口获取其接口类的名称,这个方法返回的是类名的列表。
说说springBoot的自动配置原理吧
首先我们知道SpringBoot项目的启动注解@SpringBootApplication 中有一个@EnableAutoConfiguration,这个就是开启springBoot的自动注册机制
可以看到,在@EnableAutoConfiguration注解内使用到了@import注解来完成导入配置的功能,而EnableAutoConfigurationImportSelector内部则是使用了SpringFactoriesLoader.loadFactoryNames方法进行扫描具有META-INF/spring.factories文件的jar包
最后再加上我们的EnableAutoConfiguration 读取我们在配置文件中的文件就可以实现自动配置了,就比如我们的springboot Admin,我们的client只要配置下配置文件就能成功了,原因就是这个
上面这些都是Spring Boot中的自动配置相关类;在启动过程中会解析对应类配置信息。每个Configuation类都定义了相关bean的实例化配置。都说明了哪些bean可以被自动配置,什么条件下可以自动配置,并把这些bean实例化出来。如果我们自定义了一个starter的话,也要在该starter的jar包中提供 spring.factories文件,并且为其配置org.springframework.boot.autoconfigure.EnableAutoConfiguration对应的配置类。所有框架的自动配置流程基本都是一样的,判断是否引入框架,获取配置参数,根据配置参数初始化框架相应组件
说说SpringBoot的启动流程吧
其实这块很大一部分和spring的启动流程有重叠的,但是,我们还是从头到尾来过一遍,当复习了。
SpringBoot的启动主要是通过实例化SpringApplication来启动的,启动过程主要做了以下几件事情:配置属性、获取监听器,发布应用开始启动事件初、始化输入参数、配置环境,输出banner、创建上下文、预处理上下文、刷新上下文(加载tomcat容器)、再刷新上下文、发布应用已经启动事件、发布应用启动完成事件。
实例化SpringApplication时做了什么
- 推断WebApplicationType,主要思想就是在当前的classpath下搜索特定的类
- 搜索META-INF\spring.factories文件配置的ApplicationContextInitializer的实现类
- 搜索META-INF\spring.factories文件配置的ApplicationListenerr的实现类
- 推断MainApplication的Class
SpringApplication的run方法做了什么?
- 创建一个StopWatch并执行start方法,这个类主要记录任务的执行时间
- 配置Headless属性,Headless模式是在缺少显示屏、键盘或者鼠标时候的系统配置
- 在文件META-INF\spring.factories中获取SpringApplicationRunListener接口的实现类EventPublishingRunListener,主要发布SpringApplicationEvent
- 把输入参数转成DefaultApplicationArguments类
- 创建Environment并设置比如环境信息,系统熟悉,输入参数和profile信息
- 打印Banner信息
- 创建Application的上下文,根据WebApplicationTyp来创建Context类,如果非web项目则创建AnnotationConfigApplicationContext,在构造方法中初始化AnnotatedBeanDefinitionReader和ClassPathBeanDefinitionScanner
- 在文件META-INF\spring.factories中获取SpringBootExceptionReporter接口的实现类FailureAnalyzers
- 准备application的上下文
- 初始化ApplicationContextInitializer
- 执行Initializer的contextPrepared方法,发布ApplicationContextInitializedEvent事件
- 如果延迟加载,在上下文添加处理器LazyInitializationBeanFactoryPostProcessor
- 执行加载方法,BeanDefinitionLoader.load方法,主要初始化了AnnotatedGenericBeanDefinition
- 执行Initializer的contextLoaded方法,发布ApplicationContextInitializedEvent事件
- 刷新上下文(后文会单独分析refresh方法),在这里真正加载bean到容器中。如果是web容器,会在onRefresh方法中创建一个Server并启动。
refresh方法 和spring的有点不同
srping中的onrefesh方法是空的,这个里面是需要去加载web容器的如tomcat jetty等,具体的方法还是一样的,这边就不说了,可以去看ssm那篇
说说SpringCloud容器和SpringBoot容器的关系呗
首先说一点就是 如果是SpringBoot呢?他是可以单独使用的,而SpringCloud是不能单独使用的,它必须依赖SpringBoot。
在我们SpringCloud的项目中呢,整个项目的容器分为三层
- BootStrap Spring 容器:由SpringCloud 监听器创建,用来初始化 SpringCloud 上下文
- SpringBoot Spring 容器:由SpringBoot创建,也是项目中常用的Spring容器。
- 微服务 Spring相关容器:Feign和Ribbon配置类对应的上下文,由配置容器抽象工厂 NamedContextFactory 创建,用于容器隔离。
主要流程
首先 SpringBoot 项目启动,触发监听器,如果引入了SpringCloud 中的BootstrapApplicationListener,则开始初始化 SpringCloud 相关的上下文:Bootstrap ApplicationContext,将其设置为祖先容器,然后继续创建其子容器:SpringBoot Application。
说说分布式系统开发的痛点,业界是怎么设计的这些解决方案
首先分布式系统开发,目前主流的架构就是微服务架构,如果说你做微服务架构的话,无论你怎么去选型,怎么去设计,首先你总归要碰到以下的几个问题
- 这么多的服务,客户端如何去访问,你就好比说我们几百个服务,难道前端要在代码中调用几百个地址,而况服务地址多了,我们也不好去管理这些ip和端口,
- 服务与服务之间,如何去通信,那是不是得处理我们服务内部之间的调用方式,
- 服务挂了怎么办,你不能因为一个服务挂了,导致整个项目出现问题,导致服务雪崩吧
- 服务与服务是如何做到服务的发现与注册的,你不能说那个服务挂了,我是如何去通知其他服务的。也就是服务的治理
说说你们公司的SpringCloud的组件吧
- Spring Cloud 核心组件:Eureka 服务发现和注册中心
- Spring Cloud 核心组件:Feign 服务与服务直接的调用
- Spring Cloud 核心组件:Ribbon 负载均衡
- Spring Cloud 核心组件:Hystrix 熔断 降级
- Spring Cloud 核心组件:Zuul SpringCloudGateway 服务网关
聊聊Eureka吧
首先什么是Eureka
首先,eureka在springcloud中充当服务注册功能,相当于dubbo+zk里面得zk,但是比zk要简单得多,zk可以做得东西太多了,包括分布式锁,分布式队列都是基于zk里面得四种节点加watch机制通过长连接来实现得,但是eureka不一样,eureka是基于HTTprest来实现的,就是把服务的信息放到一个ConcurrentHashMap中,然后服务启动的时候去读取这个map,来把所有服务关联起来,然后服务器之间调用的时候通过信息,进行http调用。eureka包括两部分,一部分就是服务提供者(对于eureka来说就是客户端),一部分是服务端,客户端需要每个读取每个服务的信息,然后注册到服务端,很明显了,这个服务端就是接受客户端提供的自身的一些信息。 目前eureka是ap的 但是呢 zk是cp的,至于分布式理论下次有空再聊哈。
聊聊eureka中一些重要的概念呗
在Eureka的服务治理中,会涉及到下面一些概念:
- 服务注册:Eureka Client会通过发送REST请求的方式向Eureka Server注册自己的服务,提供自身的元数据,比如ip地址、端口、运行状况指标的url、主页地址等信息。Eureka Server接收到注册请求后,就会把这些元数据信息存储在一个双层的Map中。
- 服务续约:在服务注册后,Eureka Client会维护一个心跳来持续通知Eureka Server,说明服务一直处于可用状态,防止被剔除。Eureka Client在默认的情况下会每隔30秒发送一次心跳来进行服务续约。
- 服务同步:Eureka Server之间会互相进行注册,构建Eureka Server集群,不同Eureka Server之间会进行服务同步,用来保证服务信息的一致性。
- 获取服务:服务消费者(Eureka Client)在启动的时候,会发送一个REST请求给Eureka Server,获取上面注册的服务清单,并且缓存在Eureka Client本地,默认缓存30秒。同时,为了性能考虑,Eureka Server也会维护一份只读的服务清单缓存,该缓存每隔30秒更新一次。
- 服务调用:服务消费者在获取到服务清单后,就可以根据清单中的服务列表信息,查找到其他服务的地址,从而进行远程调用。Eureka有Region和Zone的概念,一个Region可以包含多个Zone,在进行服务调用时,优先访问处于同一个Zone中的服务提供者。
- 服务下线:当Eureka Client需要关闭或重启时,就不希望在这个时间段内再有请求进来,所以,就需要提前先发送REST请求给Eureka Server,告诉Eureka Server自己要下线了,Eureka Server在收到请求后,就会把该服务状态置为下线(DOWN),并把该下线事件传播出去。
- 服务剔除:有时候,服务实例可能会因为网络故障等原因导致不能提供服务,而此时该实例也没有发送请求给Eureka Server来进行服务下线,所以,还需要有服务剔除的机制。Eureka Server在启动的时候会创建一个定时任务,每隔一段时间(默认60秒),从当前服务清单中把超时没有续约(默认90秒)的服务剔除。
- 自我保护:既然Eureka Server会定时剔除超时没有续约的服务,那就有可能出现一种场景,网络一段时间内发生了异常,所有的服务都没能够进行续约,Eureka Server就把所有的服务都剔除了,这样显然不太合理。所以,就有了自我保护机制,当短时间内,统计续约失败的比例,如果达到一定阈值,则会触发自我保护的机制,在该机制下,Eureka Server不会剔除任何的微服务,等到正常后,再退出自我保护机制。
从这些概念中,就可以知道大体的流程,Eureka Client向Eureka Server注册,并且维护心跳来进行续约,如果长时间不续约,就会被剔除。Eureka Server之间进行数据同步来形成集群,Eureka Client从Eureka Server获取服务列表,用来进行服务调用,Eureka Client服务重启前调用Eureka Server的接口进行下线操作。
说说Eureka的一些原理和服务流程
服务提供者
1、启动后,向注册中心发起register请求,注册服务
2、在运行过程中,定时向注册中心发送renew心跳,证明“我还活着”。
3、停止服务提供者,向注册中心发起cancel请求,清空当前服务注册信息。
服务消费者
1、启动后,从注册中心拉取服务注册信息
2、在运行过程中,定时更新服务注册信息。
3、服务消费者发起远程调用:
注册中心
1、启动后,从其他节点拉取服务注册信息(节点之间的数据同步)。
2、运行过程中,定时运行evict任务,剔除没有按时renew的服务(包括非正常停止和网络故障的服务)。
3、运行过程中,接收到的register、renew、cancel请求,都会同步至其他注册中心节点。
聊聊Eureka的存储机制
既然是服务注册中心,必然要存储服务的信息,我们知道ZK是将服务信息保存在树形节点上。而下面是Eureka的数据存储结构:
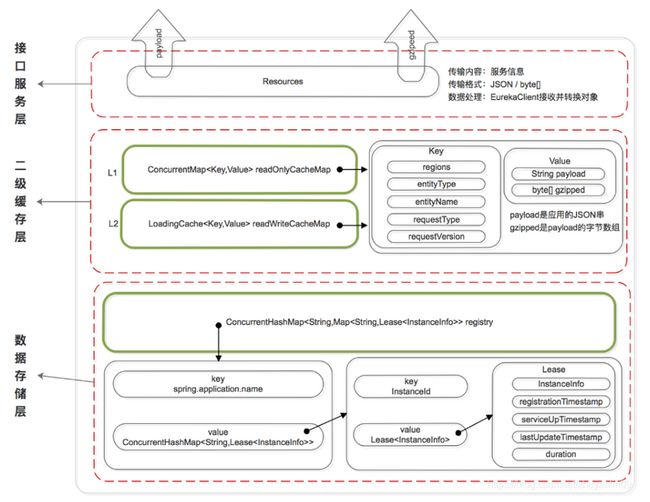
Eureka的数据存储分了两层:数据存储层和缓存层。Eureka Client在拉取服务信息时,先从缓存层获取(相当于Redis),如果获取不到,先把数据存储层的数据加载到缓存中(相当于Mysql),再从缓存中获取。值得注意的是,数据存储层的数据结构是服务信息,而缓存中保存的是经过处理加工过的、可以直接传输到Eureka Client的数据结构。
Eureka实现了二级缓存来保存即将要对外传输的服务信息,数据结构完全相同。
一级缓存:ConcurrentHashMap
二级缓存:Loading
Eureka的服务续约机制
服务注册后,要定时(默认30S,可自己配置)向注册中心发送续约请求,告诉注册中心“我还活着”。
注册中心收到续约请求后:
1、更新服务对象的最近续约时间,即Lease对象的lastUpdateTimestamp;
2、同步服务信息,将此事件同步至其他的Eureka Server节点。
Eureka服务注销机制
服务正常停止之前会向注册中心发送注销请求,告诉注册中心“我要下线了”。
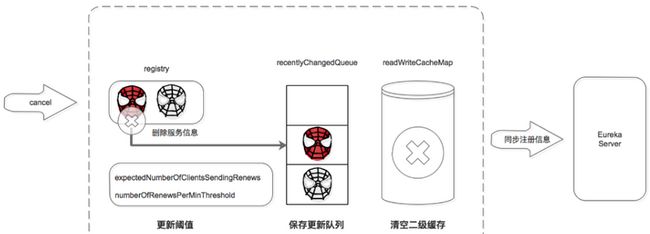
注册中心服务接收到cancel请求后:
1、删除服务信息,将服务信息从registry中删除;
2、更新队列,将此事件添加到更新队列中,供Eureka Client增量同步服务信息使用。
3、清空二级缓存,即readWriteCacheMap,用于保证数据的一致性。
4、更新阈值,供剔除服务使用。
5、同步服务信息,将此事件同步至其他的Eureka Server节点。
Eureka自我保护
Eureka自我保护机制是为了防止误杀服务而提供的一个机制。Eureka的自我保护机制“谦虚”的认为如果大量服务都续约失败,则认为是自己出问题了(如自己断网了),也就不剔除了;反之,则是Eureka Client的问题,需要进行剔除。而自我保护阈值是区分Eureka Client还是Eureka Server出问题的临界值:如果超出阈值就表示大量服务可用,少量服务不可用,则判定是Eureka Client出了问题。如果未超出阈值就表示大量服务不可用,则判定是Eureka Server出了问题。
聊聊feign是啥
Feign是一种声明式、模板化的HTTP客户端(仅在Application Client中使用)。声明式调用是指,就像调用本地方法一样调用远程方法,无需感知操作远程http请求。 Spring Cloud的声明式调用, 可以做到使用 HTTP请求远程服务时能就像调用本地方法一样的体验,开发者完全感知不到这是远程方法,更感知不到这是个HTTP请求。Feign的应用,让Spring Cloud微服务调用像Dubbo一样,Application Client直接通过接口方法调用Application Service,而不需要通过常规的RestTemplate构造请求再解析返回数据。它解决了让开发者调用远程接口就跟调用本地方法一样,无需关注与远程的交互细节,更无需关注分布式环境开发。
聊聊Feign的原理呗
我们来想想平时我们使用feign的时候,会是一个怎么样的流程
- 添加了 Spring Cloud OpenFeign 的依赖
- 在 SpringBoot 启动类上添加了注解 @EnableFeignCleints
- 按照 Feign 的规则定义接口 DemoService, 添加@FeignClient 注解
- 在需要使用 Feign 接口 DemoService 的地方, 直接利用@Autowire 进行注入
- 使用接口完成对服务端的调用
那我们基于这些步骤来分析分析,本文并不会说非常深入去看每一行的源码
- SpringBoot 应用启动时, 由针对 @EnableFeignClient 这一注解的处理逻辑触发程序扫描 classPath中所有被@FeignClient 注解的类, 这里以 XiaoLiuLiuService 为例, 将这些类解析为 BeanDefinition 注册到 Spring 容器中
- Sping 容器在为某些用的 Feign 接口的 Bean 注入 XiaoLiuLiuService 时, Spring 会尝试从容器中查找 XiaoLiuLiuService 的实现类
- 由于我们从来没有编写过 XiaoLiuLiuService 的实现类, 上面步骤获取到的 XiaoLiuLiuService 的实现类必然是 feign 框架通过扩展 spring 的 Bean 处理逻辑, 为 XiaoLiuLiuService 创建一个动态接口代理对象, 这里我们将其称为 XiaoLiuLiuServiceProxy 注册到spring 容器中。
- Spring 最终在使用到 XiaoLiuLiuService 的 Bean 中注入了 XiaoLiuLiuServiceProxy 这一实例。
- 当业务请求真实发生时, 对于 XiaoLiuLiuService 的调用被统一转发到了由 Feign 框架实现的 InvocationHandler 中, InvocationHandler 负责将接口中的入参转换为 HTTP 的形式, 发到服务端, 最后再解析 HTTP 响应, 将结果转换为 Java 对象, 予以返回。
其实就是基于aop代理和面向切面编程,把那些重复的东西,帮我们封装了起来,然后再结合一起其他的组件如负载均衡Ribbon等。
Hystrix是什么
在分布式系统中,每个服务都可能会调用很多其他服务,被调用的那些服务就是依赖服务,有的时候某些依赖服务出现故障也是很正常的。
Hystrix 可以让我们在分布式系统中对服务间的调用进行控制,加入一些调用延迟或者依赖故障的容错机制。
Hystrix 通过将依赖服务进行资源隔离,进而阻止某个依赖服务出现故障时在整个系统所有的依赖服务调用中进行蔓延;同时Hystrix 还提供故障时的 fallback 降级机制。
总而言之,Hystrix 通过这些方法帮助我们提升分布式系统的可用性和稳定性。
hystrix实现原理
hystrix语义为“豪猪”,具有自我保护的能力。hystrix的出现即为解决雪崩效应,它通过四个方面的机制来解决这个问题
- 隔离(线程池隔离和信号量隔离):限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用。
- 优雅的降级机制:超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。
- 融断:当失败率达到阀值自动触发降级(如因网络故障/超时造成的失败率高),熔断器触发的快速失败会进行快速恢复。
- 缓存:提供了请求缓存、请求合并实现。
- 支持实时监控、报警、控制(修改配置)
聊聊hystrix的隔离机制
- 线程池隔离模式:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
- 信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
聊聊hystrix的融断机制 和降级
熔断器模式定义了熔断器开关相互转换的逻辑。
- 服务的健康状况 = 请求失败数 / 请求总数。熔断器开关由关闭到打开的状态转换是通过当前服务健康状况和设定阈值比较决定的。
- 当熔断器开关关闭时,请求被允许通过熔断器。 如果当前健康状况高于设定阈值,开关继续保持关闭。如果当前健康状况低于设定阈值,开关则切换为打开状态。当熔断器开关打开时,请求被禁止通过。当熔断器开关处于打开状态,经过一段时间后,熔断器会自动进入半开状态,这时熔断器只允许一个请求通过。当该请求调用成功时,熔断器恢复到关闭状态。若该请求失败,熔断器继续保持打开状态,接下来的请求被禁止通过。
- 熔断器的开关能保证服务调用者在调用异常服务时,快速返回结果,避免大量的同步等待,并且熔断器能在一段时间后继续侦测请求执行结果,提供恢复服务调用的可能。
降级需要对下层依赖的业务分级,把产生故障的丢了,换一个轻量级的方案,是一种退而求其次的方法,说白了就是我们代码中经常用到的fallback,比如说直接返回一个静态的常量之类的。
什么是网关
网关是整个微服务API请求的入口,负责拦截所有请求,分发到服务上去。可以实现日志拦截、权限控制、解决跨域问题、限流、熔断、负载均衡,隐藏服务端的ip,黑名单与白名单拦截、授权等,常用的网关有zuul(netflix的,但是已经停更了)和spring cloud gateway (springcloudalibaba)。这里主要讲springcloud gateway,springcloud gateway是一个全新的项目,其基于spring5.0 以及springboot2.0和项目Reactor等技术开发的网关,其主要的目的是为微服务架构提供一种简单有效的API路由管理方式.
综上:一般情况下,网关一般都会提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、容灾、日志、监控这些功能。
聊聊Spring Cloud Gateway的大致流程
- 路由的配置转换为routeDefinition
- 获取请求对应的路由规则, 将RouteDefinition转换为Route
- 执行Predicate判断是否符合路由, 以及执行相关的过滤(全局过滤器以及路由过滤器)
- 负载均衡过滤器负责将请求中的serviceId转换为具体的服务实例Ip
其实网关其实还有很多说的,因为网关企业级的网关分类比较多,比如我们的对外网关 对内网关,对合作伙伴的网关等
网关的设计方案
- 基于Nginx+Lua+ OpenResty的方案,可以看到Kong,orange都是基于这个方案
- 基于Netty、非阻塞IO模型。 通过网上搜索可以看到国内的宜人贷等一些公司是基于这种方案,是一种成熟的方案。
- 基于Node.js的方案。 这种方案是应用了Node.js天生的非阻塞的特性。
- 基于java Servlet的方案。 zuul基于的就是这种方案,这种方案的效率不高,这也是zuul总是被诟病的原因。
最后问一个问题,mysql分库分表下的数据迁移问题
问题场景:就是比如说我们一开始设计架构的时候,我们并不知道这个项目能火,但是突然老板拿到了融资,然后数据量起来,原来的架构抗不住了,这个时候需要分库分表了,你怎么去迁移,怎么保证迁移之后的数据一致性
停机部署法
大致思路就是,挂一个公告,半夜停机升级,然后半夜把服务停了,跑数据迁移程序,进行数据迁移。 步骤如下:
- 出一个公告,比如“今晚00:00~6:00进行停机维护,暂停服务”
- 写一个迁移程序,读db-old数据库,通过中间件写入新库
- 然后测试一下数据的一致性
大家不要觉得这种方法low,我其实一直觉得这种方法可靠性很强。而且我相信大部分公司一定不是什么很牛逼的互联网公司,如果你们的产品凌晨1点的用户活跃数还有超过1000的,你们握个爪!毕竟不是所有人都在什么电商公司的,大部分产品半夜都没啥流量。所以此方案,并非没有可取之处。
但是此方案有一个缺点,累!不止身体累,心也累!你想想看,本来定六点结束,你五点把数据库迁移好,但是不知怎么滴,程序切新库就是有点问题。于是,眼瞅着天就要亮了,赶紧把数据库切回老库。第二个晚上继续这么干,简直是身心俱疲。 ps:这里教大家一些技巧啊,如果你真的没做过分库分表,又想吹一波,涨一下工资,建议答这个方案。因为这个方案比较low,low到没什么东西可以深挖的,所以答这个方案,比较靠谱。
双写部署法
- 首先我们用canal去监听我们需要分库分表的那个表,就是上线之后的那些事务操作,然后把它放到队列里面,存起来,先不消费。
- 启动一个程序把旧数据同步到分库分表的数据库,这里有一个问题怎么区分新旧数据,就是当这个项目启动的时候,算出最大的id,这个之前的就是老数据了,或者是按更新时间排序,再这个时间之前的就是老数据,之后的就是新数据了。
- 最后把迁移数据下线,再去消费队列,完成数据的迁移
- 测试验证数据是否正常
结束
下面我们来看看分布式的理论和Zk,对于分布式系统开发还是需要明白的。
日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是 真粉。创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见
微信 搜 "六脉神剑的程序人生" 回复888 有我找的许多的资料送给大家