多显卡实时分析的实现原理
读取摄像头数据 一机多卡实现数据并行推理
- I.走过的弯路
-
- 弯路一:thread实现数据并行
- 弯路二:torch的distributed模块
- II.使用distribute封装识别接口时遇到的问题
-
- 负载不均衡
- 数据分配
- III.解决方案
I.走过的弯路
本人因为项目需求,服务器连接了200多路摄像头,需要使用多张显卡去并行推理,读取到的图片数据存储在queen里,前期实现此需求时走了两条弯路 1)使用python的thread线程,实现数据并行 2)使用ptorch的distributed模块实现并行
弯路一:thread实现数据并行
服务器两张显卡 gpu_ids[0, 1], 使用python的thread模块开启两个进程,每个进程分别去加载同样的model和cfg文件
- 遇到的问题

该问题在于cuda的初始化只能加载一次,不能共享CUDA张量,可以将原本cuda类型的张量转为cpu类型的张量,这种做法虽然可行,但推理时间加长,违背我们的初衷。
弯路二:torch的distributed模块
既然涉及到了distributed模块,需要从浅及深去了解
I.模型并行和数据并行
模型并行:
网络太大,一张显卡显存放不下,加载模型节点时进行拆分,然后进行模型的并行训练

具体在代码中,对不同的网络序列指定不同的GPU去加载
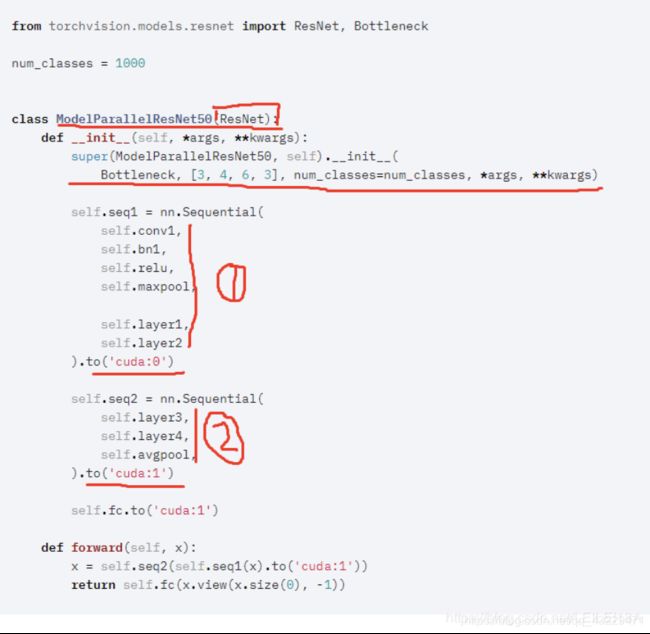
数据并行:
数据并行的操作是要求我们将数据划分成多份,然后发送给多个GPU进行并行计算。
主要涉及到的知识点包括:
- DataParallel和distributed
- 通信方式
- distributed的启动方式
1.DataParallel和distributed:pytorch中为我们提供了两个数据并行的方法。
DataParallel
系统通过将整个小型批处理加载到主线程上,然后将子小型批处理分散到整个GPU网络中来工作。
具体流程图如下:

DataParallel大体步骤如下:
① 将输入一个 batch 的数据均分成多份,分别送到对应的 GPU 进行计算,与 Module 相关的所有数据也都会以浅复制的方式复制多份
② 每个 GPU 在单独的线程上将针对各自的输入数据独立并行地进行 forward 计算。然后在主GPU上收集网络输出,并通过将网络输出与批次中每个元素的真实数据标签进行比较来计算损失函数值
③ 损失值分散给各个GPU,每个GPU进行反向传播以计算梯度
④ 最后,在主GPU上归约梯度、进行梯度下降,并更新主GPU上的模型参数。由于模型参数仅在主GPU上更新,而其他从属GPU此时并不是同步更新的,所以需要将更新后的模型参数复制到剩余的从属 GPU 中,以此来实现并行。
所以DataParallel会有一个数据结果和梯度汇总的GPU,可以通过output_device=gpus[0]来指定,DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总,DataParallel会将定义的网络模型参数默认放在GPU 0上,所以dataparallel实质是可以看做把训练参数从GPU拷贝到其他的GPU同时训练,这样会导致内存和GPU使用率出现很严重的负载不均衡现象,即GPU 0的使用内存和使用率会大大超出其他显卡的使用内存,因为在这里GPU0作为master来进行梯度的汇总和模型的更新,再将计算任务下发给其他GPU,所以他的内存和使用率会比其他的高。
DataParallel的缺点:
1)冗余数据副本
- 数据从主机复制到主GPU,然后将子微型批分散在其他GPU上
2)在前向传播之前跨GPU进行模型复制
- 由于模型参数是在主GPU上更新的,因此模型必须在每次正向传递的开始时重新同步
3)每批的线程创建/销毁开销
- 并行转发是在多个线程中实现的(这可能只是PyTorch问题)
4)梯度减少流水线机会未开发
- 在Pytorch 1.0数据并行实现中,梯度下降发生在反向传播的末尾。
5)在主GPU上不必要地收集模型输出output
6)GPU利用率不均
- 在主GPU上执行损失loss计算
- 梯度下降,在主GPU上更新参数
distributed
torch 就会自动将其分配给n个进程,分别在 n 个 GPU 上运行,不再有主GPU,每个GPU执行相同的任务。
具体流程图如下:
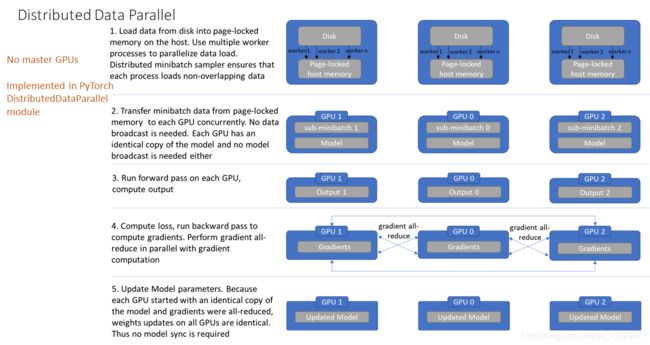
distributed大体步骤如下:
① 将数据地址加载到内存中,通过几个multiple worker将数据换分成几个子集,并确保各个子集无重叠的数据
② 在每个GPU上copy模型,独立训练每个子集,无需数据的广播
③ 在每个GPU上前向传播,计算output
④ 计算loss,反向传播计算梯度,各个GPU将梯度汇总到rank=0的进程中汇总平均,再由其广播到其他的进程中
⑤ 各个进程的参数更新
由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。
而在 DataParallel 中,全程维护一个 optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU。
相较于 DataParallel,torch.distributed 传输的数据量更少,因此速度更快,效率更高。
2.torch.distributed通信方式
torch.distributed支持三种后端,每个都有不同的能力,下表展示了那个函数对使用CPU/CUDA张量是可以得到的。MPI只有在构建PyTorch的实现支持CUDA时才支持它。

使用后端的选择:
* GPU的分布式训练使用NCCL后端
* CPU分布式训练使用Gloo后端
* GPU host使用无限制宽带互连:
-使用NCCL,因为它是目前唯一支持无限制宽带和GPUDirect的后端。
* GPU hosts使用以太网互连:
-使用NCCL,因为它目前提供最佳分布式GPU训练性能,特别对于多进程单点或者多点分布式训练。如果你遇到任何NCCL的问题,使用Gloo作为应急计划选项。(注意对于GPU目前Gloo比NCCL运行的慢)
* CPU hosts用无限制带宽连接:
-如果无限制带宽支持IB上的IP,使用Gloo,否则,使用MPI作为替代,我们计划在即将更新的版本中加入Gloo的无限制带宽支持。
-CPU hosts with Ethernet interconnect
* 用以太网连接的GPU:
-Use Gloo, unless you have specific reasons to use MPI.
-使用Gloo,除非你有特殊的原因需要使用MPI。
3.distributed的启动方式
① torch.distributed.launch 启动器
用于在命令行或通过shell脚本分布式地执行 python 文件。在执行过程中,启动器会将当前进程的(其实就是 GPU的)index 通过参数传递给 python,我们可以这样获得当前进程的 index:
parser = argparse.ArgumentParser()
parser.add_argument(’–local_rank’, default=-1, type=int, help=‘node rank for distributed training’)
args = parser.parse_args()
print(args.local_rank)
该启动方式会读取默认的环境变量作为配置, 具体可以参考mmdetection的分布式训练代码
② torch.multiprocessing.spawn辅助启动
使用torch.multiprocessing 进行多进程控制,可以绕开 torch.distributed.launch 自动控制开启和退出进程的一些小毛病
使用时,只需要调用 torch.multiprocessing.spawn,torch.multiprocessing 就会帮助我们自动创建进程。如下面的代码所示,spawn 开启了 nprocs=2个进程,每个进程执行 main_worker 并向其中传入 local_rank(当前进程 index)和 args(即 2 和 myargs)作为参数:
import torch.multiprocessing as mp
mp.spawn(main_worker, nprocs=2, args=(2, myargs))
这里,我们直接将原本需要 torch.distributed.launch 管理的执行内容,封装进 main_worker 函数中,其中 proc 对应 local_rank(当前进程 index),进程数 nprocs 对应 2, args 对应 myargs:
def main_worker(local_rank, nprocs, args):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=2, rank=local_rank)
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
.....
在上面的代码中值得注意的是,由于没有 torch.distributed.launch 读取的默认环境变量作为配置,我们需要手动为 init_process_group 指定参数:
dist.init_process_group(backend=‘nccl’, init_method=‘tcp://127.0.0.1:23456’, world_size=2, rank=local_rank)
在使用时,直接使用 python 运行就可以了:
python xxx.py
II.使用distribute封装识别接口时遇到的问题
负载不均衡
采用torch.multiprocessing.spawn辅助启动时,主进程0也就是我的0显卡上显存占用会非常大。代码如下:
class BODY():
def __init__(self, input_buffer):
self.config = '/home/xxx/model/default/cfg/retinanet.py'
self.launcher = 'pytorch'
self.checkpoint = '/home/xxx/model/default/weights/2.2.1.A.pth'
self.nprocs = torch.cuda.device_count()
def main_worker(self, local_rank,nprocs, input_buffer):
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(local_rank)
# distributed
if isinstance(self.config, str):
config = mmcv.Config.fromfile(self.config)
elif not isinstance(config, mmcv.Config):
raise TypeError('config must be a filename or Config object, '
f'but got {type(config)}')
if self.launcher == 'none':
distributed = False
else:
distributed = True
dis.init_process_group(backend='nccl',init_method= 'tcp://127.0.0.1:23459', world_size=self.nprocs, rank=local_rank )
torch.cuda.set_device(local_rank)
config.model.pretrained = None
model = build_detector(config.model, test_cfg=config.test_cfg)
if self.checkpoint is not None:
checkpoint = load_checkpoint(model,self.checkpoint)
if 'CLASSES' in checkpoint['meta']:
model.CLASSES = checkpoint['meta']['CLASSES']
else:
warnings.simplefilter('once')
warnings.warn('Class names are not saved in the checkpoint\'s '
'meta data, use COCO classes by default.')
model.CLASSES = get_classes('coco')
model.cfg = config
model.eval()
model.cuda(local_rank)
cfg = model.cfg
model = MMDistributedDataParallel(
model.cuda(),
device_ids=[torch.cuda.current_device()],
broadcast_buffers=False)
results, img_list_path = inference_multi_detector(model, cfg, input_buffer)
try:
print('len results', len(results))
except:
pass
if __name__ == '__main__':
im_list = []
image_path = '/home/aiadmin/ai_server/model/default/dis_test/test_image/'
imamgs = os.listdir(image_path)
for image in imamgs:
im = cv2.imread(image_path + image)
im_list.append(im)
body = BODY(im_list)
while True:
mp.spawn(body.main_worker, nprocs=body.nprocs, args=(body.nprocs, im_list))
当程序运行起来时,显存占用如下:
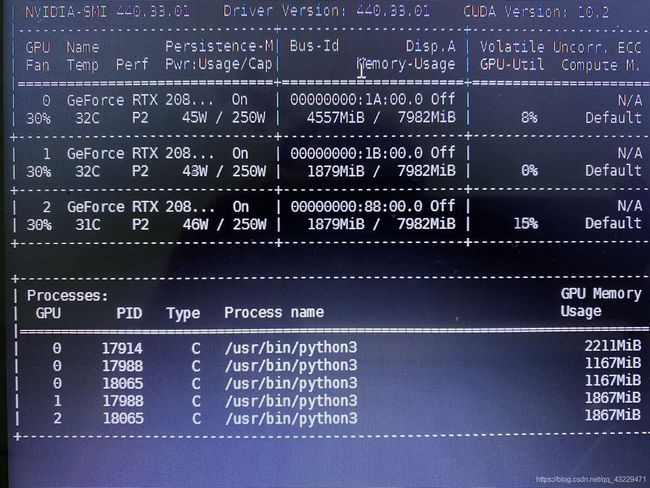
相当于开启了5个进程去分析,但是self.nprocs = torch.cuda.device_count()服务器只有三张显卡,希望小伙伴们可以解答我的疑惑
数据分配
没有使用DistributedDataParallel,数据没有划分成各个子数据集,每张显卡都会跑一遍数据。即使使用了DistributedDataParallel,如何在保证只调用一次主进程的情况下去实时的分析数据,也是个问题
III.解决方案
采取独立的线程去开启分析接口,每个分析接口传入不同的device
model = init_detector(self.config_file, self.checkpoint_file, device='cuda:0') # or cuda:n
两个独立的线程去栈里读取图片并分析
就此,问题解决,虽然绕了很多弯路,但也学到了很多知识,年底有点时间,会把这段时间学到的其他知识点慢慢记录下来。