AWS数据湖十年,云计算老大哥的磨刀之路

▼数据猿开启大型年终主题策划活动▼

大数据产业创新服务媒体—聚焦数据·改变商业
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

从 2006 年上线至今,AWS 已经走过了十几个年头。亚马逊在一个周围懵懂的时代里,拉开了云计算的大幕。AWS 位于 Gartner 魔力象限云计算的领导者坐标系,和竞争对手的差距拉的比较大,它在前瞻性上的优势,一直遥遥领先。
数据湖,也是亚马逊发展了近十年的一项技术。AWS 每一次变革和成长,都在云计算的历史中写下了自己的足迹,成绩令人瞩目。而云上数据湖,经过十年的酝酿,将会产生什么样的推动力呢?
AWS 的定义也不止一个,在众多的 AWS re:Invent 演讲中,我们看到了以下定义:
re:Invent 2016:What is a Data Lake? A “Data Lake” is a repository that holds raw data in its native format until it is needed by down stream analytics processes.
re:Invent 2018:Defining the AWS Data Lake Data lake is an architecture with a virtually limitless centralized storage platform capable of categorization, processing, analysis, and consumption of heterogeneous datasets。
对于数据湖的定义,业界并没有完全一致的说法。大多数人提起数据湖,也会或多或少的提到 Pentaho 公司的创始人詹姆斯·狄克逊 (James Dixon),在 2010 年的时候,他在他的一篇名为”Hadoop 和数据湖“的博客中写道:”我们创造了一个新概念:数据湖。数据湖是一种比数据集市更自然的数据存储理念,即在系统或存储库中以自然格式存储数据的方法。“
总的来说,AWS 认为”数据湖“需满足以下特征:
集中式存储,满足”a single source of truth“ 唯一真知来源原则
收集和存储任何类型的数据,包括结构化、半结构化、非结构化以及原始数据
快速轻松地执行新类型的数据分析
schema-on-read 读时校验模式,而非写时模式
低成本存储
计算和存储分离
保护数据并防止未经授权的访问
数据湖的理念非常适合现在的互联网业务。
大数据不仅体现在数据体量爆炸性增长,而且结构化数据、非结构化数据、半结构化数据混存,因此现在的各种互联网业务产生的日志文件、图像文件、点击流、社交媒体、物联网传感器等等,都可以以原始形式放入数据湖中,同时也屏蔽了底层异构数据源。这也是传统数仓做不到的。
数据可以很轻松进入数据湖,用户也可以延迟数据的采集、数据清洗、规范化的处理,在读取的时候再灵活地以各种方式分析数据,得到运营报告,或者能执行实时分析和机器学习任务从而得到关于未来的预测结果。传统的数仓,因为模型范式的要求,业务不能随便的变迁,变迁涉及到底层数据的各种变化,没法支持业务变化。对于数据湖来说,尤其像互联网行业中新的应用,不断的发生变化,它的数据模型也不断的变化。相对来说,数据湖就更加的灵活,能更快速的适应上层数据应用的变化。
现在很多企业都建立了用于报告和分析目的的数据仓库,使用各种来源的数据,包括自己的交易处理系统和其他数据库,但建立和运行数据仓库和大数据框架既复杂又昂贵。当数据量增长或者需要向更多用户提供分析和报告时,如果不想在昂贵的升级过程上投入过多人力和精力,就需要选择更现代的架构设计以实现更低成本的存储和查询。
2006 年,AWS 正式推出了 S3(Simple Storage Service),亚马逊的第一个云产品。Amazon S3 从此已成为事实上的云存储标准。
2006 年,Hadoop 推出。HDFS 是分布式存储理念的产物,MapReduce 是 Hadoop 分布式计算框架的组成部分。HDFS 提供跨集群中多个计算节点的数据分发,非常适合管理不同类型的数据源。因此,它为企业数据湖奠定了基础。
为了兼容 Hadoop 集群,AWS 在 2009 年推出了 Amazon Elastic MapReduce(EMR)数据湖架构,以跨 EC2 实例集群自动置备 HDFS。在当时,这曾是企业在 AWS 之上构建数据湖的最佳选择。
EMR 包含了几乎所有的 Hadoop 生态体系中的核心组件,能够满足用户各种各类的数据分析需求。在运维层面,AWS EMR 帮助用户自动完成了计算资源准备,操作系统安装,Hadoop 组件安装,组件配置等一系列繁琐重复的工作。
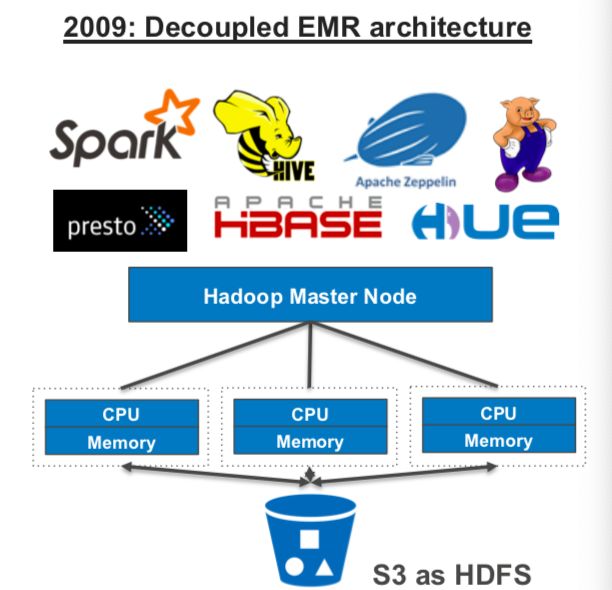
EMR 更重要的创新,是提出计算与存储分离思想, 以 S3 存储作为底层提供与 Hadoop 生态计算框架无缝集成的方案作为 HDFS 的替代,给出了不一样的可行方案。因为 S3 限于 5 GB 对象,企业需要将 HDFS 跨多个具有附加 Elastic Block Store 卷的 EC2 实例分布,企业才可以创建更大的数据湖。此后,Amazon 扩展了 S3 以支持 5 TB 对象,用户可以将数据聚合到 PB 级的存储桶中。这使得用户更容易在 S3 上而不是 HDFS 上构建更大的数据湖。
Hadoop 采用了存储计算一体化的方法。因为当时主流网络带宽只有 100Mb,通过网络远程访问数据实在是太慢了。为了解决数据的快速访问,Google 创造性地提出来了计算和存储耦合的架构,Hadoop 延续了这个架构。但是十年过去后,网络带宽增长了一百倍,已经达到了 10G 以上,IO 不再是大数据的瓶颈,计算才是,计算存储分离带来的弹性扩展和成本优势渐渐明显。
大数据和云计算,在未来的发展方向上,终于通过”数据湖“融合到了一起。
AWS 的云服务天生具有存储计算分离的特性,且能自动伸缩 CPU 和存储资源。云的优势随着时间的流逝慢慢呈现出来,AWS data lake 存储的核心也慢慢转为 S3。
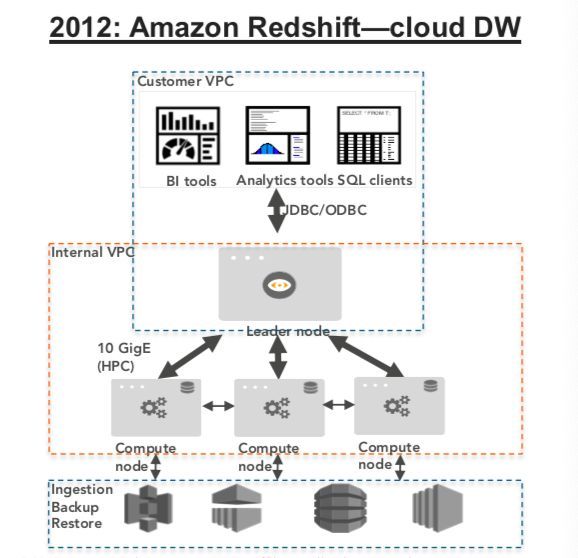
之后 AWS 于 2012 年推出了 Redshift ,业界第一款云端 MPP 架构的数据仓库云服务。随着产品的迭代,今天的 Amazon Redshift 可以通过 Spectrum 引擎将查询扩展到 Amazon S3 数据湖,带来了 EB 级数据湖分析:Redshift Spectrum 是 Redshift 的一种功能,可以帮助用户针对 Amazon S3 中的 EB 级数据运行查询,无需加载或转换任何数据。用户因此可以将 S3 用作高度可用、安全且划算的数据湖,以开放数据格式存储无限数据。
数据湖的数据分析完整流程有收集,存储,分析,应用四个大的阶段,这四个阶段也是数据湖建设的必要路径。他们之间没有绝对的先后次序,没有必要等所有数据都收集好了才开始后面的步骤,在建设阶段的初期应该就要搭建好基本的数据分析管道,后期在此基础之上再根据数据分析业务的需求进行丰富和增加。AWS 数据湖的建设过程中各个阶段所采用的技术生态系统如下图所示:
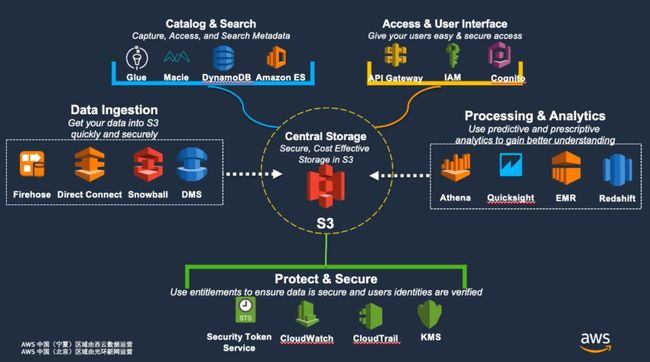
从图中可以看出除了主要的四个阶段功能服务外,AWS 数据湖还为用户提供了一系列的管理工具, 以松耦合的方式与 S3 作为核心存储的数据湖紧密集成,提供企业级整体方案。
用户可以利用 Glue Catalog、Macie,Dynamodb,Amazon ES 等工具来进行元数据管理,把数据都按照层级和业务上的逻辑关系组织起来,方便后续的分析使用。
在对外提供数据分析服务能力时,API Gateway 可以帮助用户以 API 的方式轻松暴露数据湖内部的数据和处理能力,同时搭配 IAM 和 Cognito 完成用户的身份认证和权限控制。
在安全方面,Security Token Service 负责提供临时的访问凭证,CloudWatch 则帮助监控数据湖的运行状况,事后审计的工作则有 CloudTrail 来完成。同时用户也可以使用 KMS 来托管或者生成密钥来对数据湖的数据进行加密保护。
不难看出,随着时间的演变, Amazon S3 已经作为 AWS 数据湖方案的存储核心服务。在计算与存储分离理念的基础上,AWS 的其它服务都采用了松耦合的设计与 S3 在数据湖场景进行了紧密集成与创新。这也包括数据湖构建必不可少的计算集群。
EMR 作为第一代围绕 Hadoop 生态计算组件设计的数据湖计算服务采取了“托管平台” 的设计定位,服务依托与底层服务器集群构建,意在解决开源生态集群部署与维护升级繁杂的痛点。随着云计算的进步与互联网技术的潮流演进,无服务器这一理念逐渐在被大家知道并获得广泛认可,数据湖的计算资源也经历了相同的演进路线,从集群化到无集群化。
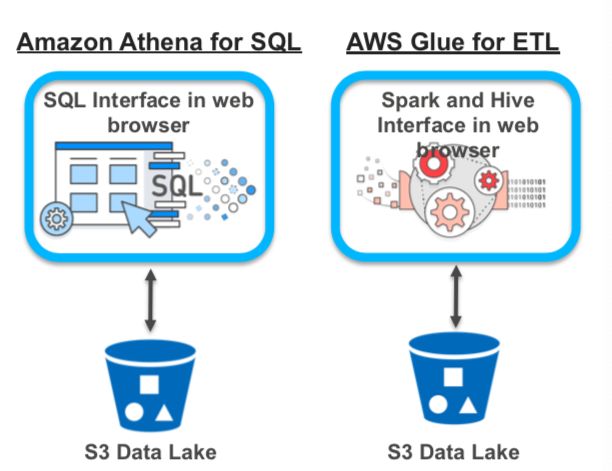
为了提升效率,降低复杂度。在面对数据湖的典型 ETL 和 Ad-hoc Query 场景时,AWS 推出了 Glue 和 Athena 两项重量级服务。他们都是基于无服务器架构的托管服务,用户不需要关心后台的计算和存储资源,只要通过访问接口进行操作即可。
其中 Glue 负责数据的元数据管理以及 ETL 的工作,用户定义好 crawler 程序,程序会解析存储在 S3 上的文件内容并推断出相应的 Schema,自动完成元数据的获取,并且该元数据可以共享给 Redshift,Athena,EMR 等数据服务使用,帮助它们快速地了解数据湖中数据的结构并加以使用。随后通过 Glue 提供的脚本或者是自己编写的脚本(支持 python 和 Scala)来完成数据的抽取,转换和加载。
Athena 主要应对 Ad-hoc Query 类需求,用户通过它运行标准的 SQL 语句就能直接查询存储在 S3 中的数据,而不用构建和管理底层的计算资源,同时也只需要为查询期间使用的资源付费。结合到列式存储,分区,压缩等手段,能进一步提高 Ad-hoc Query 的性能并降低成本。此外 Athena 还可以对接 QuickSight 完成多种类型的数据可视化任务。
2018 年,AWS 在 re:Invent 会议上首次宣布了云数据湖托管 Lake Formation,并于今年 8 月 8 日正式投入商业使用。AWS Lake Formation 简化了数据湖的创建和管理工作,以前搭建完整的数据湖需要数月的时间,通过 Lake Formation 可以很好的简化搭建操作。且无需通过用户、组或存储桶策略授予 S3 访问权限,它提供了一个集中式控制台,用于授予和审核对数据湖的访问权限。
至此,AWS 形成了一套比较成熟完整的数据湖技术体系。
我们每天产生的数据中,有 90% 的数据属于非结构化数据,并且每年以 55%至 65%的速度在增长。这些数据以前难以存储、搜索和分析,现在利用数据湖和 AI 技术,才慢慢呈现出作用。尤其是 AWS 提供了一系列的机器学习服务,以及可以轻松地在数据湖上运行的工具,为用户提供诸如个性化建议,容量规划,供应链预测等,从而使企业在激烈的竞争环境中进一步得到发展,数据湖的作用在未来也肯定越来越重要。
目前已经有了一些应用 AWS 数据湖的案例,比如,用户超三千万的小红书使用数据湖存储海量的日志数据和来自社区的图片、评论、表情等非结构化数据来分析用户的喜好。千万用户级别的流利说通过使用数据湖,建立了大型“中国人英语语音数据库”,在此基础上开发英语口语评测、英语写作打分引擎和深度自适应学习系统。
在未来,AWS 计划提供更好的可靠性,更好的扩展性,更安全合规的满足企业级需求,并做到与开源社区各种计算框架更好的集成。几年以后可能 Hadoop 退出历史舞台,不再是主流计算框架,被 spark/flink 替代,应用调度 yarn 被 k8s 替换,未来新的框架肯定会兼容 S3,S3 作为数据湖继续提供强大的存储将会是常态。
来源:InfoQ丨文:Tina
——END——

