摘要:Vue的相关技术原理成为了前端岗位面试中的必考知识点,掌握 Vue 对于前端工程师来说更像是一门“必修课”。
本文原作者为尹婷,擅长前端组件库研发和微信机器人。
我们发现, Vue 越来越受欢迎了。
不管是BAT大厂,还是创业公司,Vue都被广泛的应用。对比Angular 和 React,三者都是非常优秀的前端框架,但从 GitHub 上来看,Vue 已经达到了 170 万的 Star。Vue的相关技术原理也成为了前端岗位面试中的必考知识点,掌握 Vue 对于前端工程师来说更像是一门“必修课”。为此,华为云社区邀请了90后前端开发工程师尹婷带来了《Vue3.0新特性介绍以及搭建一个vue组件库》的分享。
了解Vue3.0先从六大特性说起
Vue.js 是一个JavaScriptMVVM库,是一套构建用户界面的渐进式框架。在2019年10月05日凌晨,Vue3的源代码alpha。目前已经发布正式版,作者表示, Vue 3.0具有六大特性:Tree Shaking;Composition;Fragment;Teleport;Suspense;渲染Performance。渲染Performance主要是框架内部的性能优化,相对比较底层,本文会主要为大家介绍前四个特性的解读。
Tree Shaking
大多数编译器都会为我们的代码进行一个死代码的去除工作。首先我们要了解一下,什么是死代码呢?
以下几个特性的代码,我们把它称之为死代码:代码不会被执行,不可到达;代码执行的结果不会被用到;代码只会影响死变量(只写不读)。比如我们给一个变量赋值,但是并没有去用这个变量,那么这就是一个死变量。这就是在我们定义阶段会把它去除的一部分,比如说roll up消除死代码的工作。

如上图示例,左边是开发的源码提供的两个函数,但最终只用到了baz函数。在最后打包的时候,会把foo函数去除掉,只把baz这个函数打包进浏览器里面运行。Tree Shaking是消除死代码的一种方式,更关注于无用模块的消除,消除那些引用了但并没有被使用的模块。
左边这块代码,export有两个函数,一个是post,一个是get,但是在我们生产里边真正使用到只有post。那么rollup在打包之后,就会直接消除掉get的函数,然后只把post的函数打包进入我们的生产里。除了rollup支持这个特性外,webpack也支持。
接下来,我们看一下VUE3.0对Tree Shaking的支持都做了哪些事情?

首先以VUE2和VUE3对nextTick的使用进行对比:VUE2把nextTick挂载到VUE实例上的一个global API式;VUE3先把nextTick模块剔除,在要使用的时候,再把这个模块引入。
通过这个对比,我们可以看到使用VUE2的时候,即使没有nextTick或者其他方法,但由于它是一个GLOBA API,它一定会被挂载到一个实例上,最后打包生产代码的时候,会把这个函数给打包进去,这一段代码进而也会影响到文件体积。在VUE3.0如果不需要这个模块的话,最后打包的这个文件里边就不会有这一块代码。通过这种方式就减少了最后生产代码的体积。
当然,不只是nextTick,在VUE3.0内部也做了其他很多tree-shaking。例如:如果不使用keep-alive组件或v-show指令,它会少引入很多跟keep-alive或者v-show不相关的包。

上图为Vue2.0的这段代码,左边是引入utils函数,然后把这个函数指为mixins。这一段代码是在Vue2里边是最常用到的,但这段代码是有问题的。
如果对这个项目不熟悉,第一次看到这个代码的时候,由于不知道这个utils里边有哪些属性和方法,也就是说这个mixins对于开发者就是个黑盒。很容易遇到一种场景:在开发组件初期,应用了mixins的一个方法,现在不需要使用该方法了,在删除的过程发现不知道其他的地方是否引用过mixins其他的属性和方法。
Composition
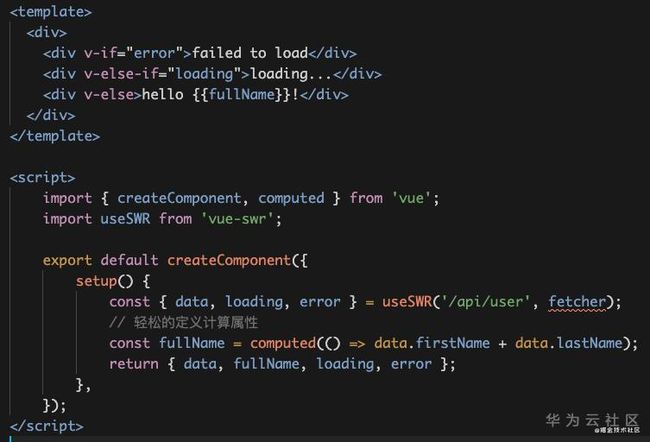
如果使用的是Vue3.0 的Composition,该怎么规避这个问题呢?如上图所示,假设它是一个组件实例,我们使用useMouse函数并返回了X和Y两个变量。从左边代码可以看到useMouse函数就是根,它监听了鼠标的移动事件之后,返回了鼠标的XY坐标。通过这种方式来组织代码,就可以很明确的知道这个函数返回的变量和改变的值。

接下来我们再看一个Composition的例子:左边是在Vue2中最常用的一段代码,首先在data里边声明first name和last name,然后在回帖的时候去请求接口,拿到接口返回到值,在computed之后获取他的full Name。那么,这段代码的问题是什么呢?
这里的computed,因为我们不知道返回的full Name的逻辑是什么。在获取了data之后,是希望通过data的返回值来拿到它的first name和last name,然后来获取它的full name。但是这一段代码的逻辑在获取接口之后就已经断掉,这就是Vue2.0 设计不合理的一个地方,导致我们的逻辑是分裂派的,分裂在个配置下。那么,如果用Composition的话,怎么样实现呢?
请求接口之后,直接拿到它的返回数据,然后把这个返回数据的值赋给computed函数里,这里就可以拿到full Name。通过这段代码可以看到,逻辑是更加的聚合了。

如何做到使用useMouse函数,里边的变量也是可响应的。在Vue 3.0中提供了两个函数:reactive和ref。reactive可以传一个对象进去,然后这个函数返回之后的state,是可响应的;ref是直接传一个值进去,然后返回到看法对象,它也是可响应的。如果我们在setup函数里边返回一个可响应值的对象,是可以在字符串模板渲染的时候使用。比如,有时候我们直接在修改data的时候,视图也会相应的改变。
Vue2中,一般会采用mixins来复用逻辑代码,但存在一些问题:例如代码来源不清晰、方法属性等冲突。基于此,在vue3中引入了Composition API(组合API),使用纯函数分隔复用代码,和React中的hooks的概念很相似。
Composition的优点是暴露给模板的属性来源清晰,它是从函数返回的;第二,可以进行逻辑重用;第三,返回值可以被任意的命名,不存在秘密空间的冲突;第四,没有创建额外的组件实力带来的性能损耗。
以前我们如果想要获取一个响应式的data,我们必须要把这个data放在component里边,然后在data里边进行声明,这样的话才能使这个对象是可响应的,现在可直接使用reactive和ref函数就可以使被保变成可响应的。
Fragment

在书写vue2时,由于组件必须只有一个根节点,很多时候会添加一些没有意义的节点用于包裹。Fragment组件就是用于解决这个问题的(这和React中的Fragment组件是一样的)。
Fragment其实就是在Vue2的一个组间里边,它的template必须要有一个根的DIV把它包住,然后再写里边的you。在Vue3,我们就不需要这个根的DIV来把这个组件包住了。上图就是2和3的对比。
Teleport

Teleport其实就是React中的Portal。Portal 提供了一种将子节点渲染到存在于父组件以外的 DOM 节点的优秀的方案。Teleport提供一个Teleport的组件,会指定一个目标的元素,比如说这里指定的是body,然后Teleport任何的内容都会渲染到这个目标元素中,也就是说下面的这一部分Teleport代码,它会直接渲染到body。
那么关于Teleport应用的位置,我们可以为大家举个例子来说明一下。比如说我们在做组件的时候,经常会实现一个dialog。dialog的背景是一个黑的铺满全屏DIV,我们对它的布局是position: absolute。如果父级元素是relative布局,我们的这个背景层就会受它的父元素的影响。那么此时,如果用Teleport直接把父组件定为body,这样它就不会再受到副组件元素样式的影响,就可以确认一个我们想要的黑色背景画。
下面我写一下react和vue的diff算法的比对,我是一边写代码,一边写文章,整理一下思路。注:这里只讨论tag属性相同并且多个children的情况,不相同的tag直接替换,删除,这没啥好写的。
用这个例子来说明:
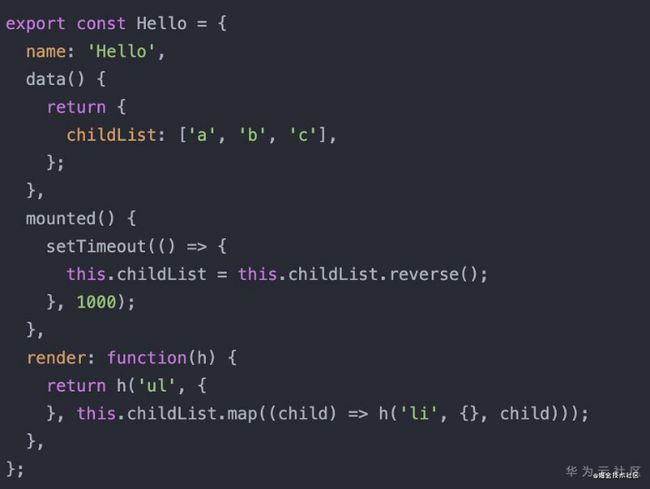
简单diff,把原有的删掉,把更新后的插入。

变化前后的标签都是li,所以只用比对vnodeData和children即可,复用原有的DOM。
先只从这个例子出发,我只用遍历旧的vnode,然后把旧的vnode和新的vnode patch就行。

这样就省掉移除和新增dom的开销,现在的问题是,我的例子刚好是新旧vnode数量一样,如果不一样就有问题,示例改成这样:

实现思路改成:先看看是旧的长度长,还是新的长,如果旧的长,我就遍历新的,然后把多出来的旧节点删掉,如果新的长,我就遍历旧的,然后多出来的新vnode加上。

仍然有可优化的空间,还是下面这幅图:

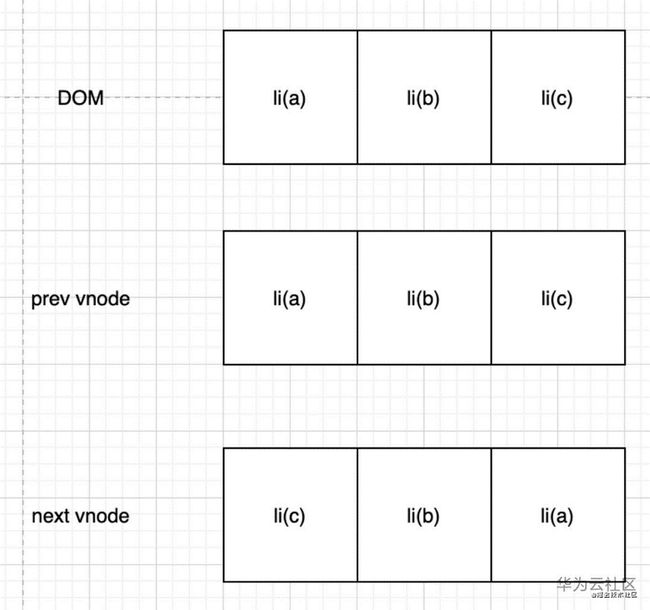
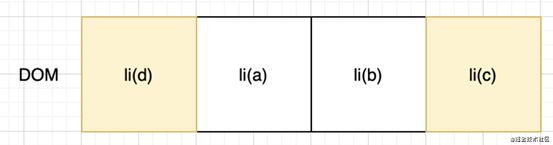
通过我们上面的diff算法,实现的过程会比对 preve vnode和next vnode,标签相同,则只用比对vnodedata和children。发现
标签的子节点(文本节点a,b,c)不同,于是分别删除文本节点a,b,c,然后重新生成新的文本节点c,b,a。但是实际上这几个
只是位置不同,那优化的方案就是复用已经生成的dom,把它移动到正确的位置。
怎么移动?我们使用key来将新旧vnode做一次映射。
首先我们找到可以复用的vnode,可以做两次遍历,外层遍历next vnode,内层遍历prev vnode

如果next vnode和prev vnode只是位置移动,vnodedata和children没有任何变动,调用patchVnode之后不会有任何dom操作。
接下来只需要把这个key相同的vnode移动到正确的位置即可。我们的问题变成了怎么移动。
首先需要知道两个事情:
· 每一个prev vnode都引用了一个真实dom节点,每个next vnode这个时候都没有真实dom节点。
· 调用patchVnode的时候会把prevVnode引用的真实Dom的引用赋值给nextVnode,就像这样:

还是拿上面的例子,外层遍历next vnode,遍历第一个元素的时候, 第一个vnode是li©,然后去prev vnode里找,在最后一个节点找到了,这里外层是第一个元素,不做任何移动的操作,我们记录一下这个vnode在prevVnode中的索引位置lastIndex,接下来在遍历的时候,如果j 这里多说一句,dom操作的api里,只有insertBefore(),没有insertAfter()。也就是说只有把某个dom插入到某个元素前面这个方法,没有插入到某个元素后面这个方法,所以我们只能用insertBefore()。那么思路就变成了,当j 当j>=lastIndex的时候,说明这个顺序是正确的的,不用移动,然后把lastIndex = j; 同样的问题,如果新旧vnode的元素数量一样,那就已经可以工作了。接下来要做的就是新增节点和删除节点。 首先是新增节点,整个框架中将vnode挂载到真实dom上都调用patch函数,patch里调用createElm来生成真实dom。按照上面的实现,如果nextVnode中有一个节点是prevVnode中没有的,就有问题: 在prevVnode中找不到li(d),那我们需要调用createElm挂在这个新的节点,因为这里的节点需要超入到li(b)和li©之间,所以需要用insertBefore()。在每次遍历nextVnode的时候用一个变量find=false表示是否能够在prevVnode中找到节点,如果找到了就find=true。如果内层遍历后find是false,那说明这是一个新的节点。 我们的createElm函数需要判断一下第四个参数,如果没有就是用appendChild直接把元素放到父节点的最后,如果有第四个参数,则需要调用insertBefore来插入到正确的位置。 接下来要做的是删除prevVnode多余节点: 在nextVnode中已经没有li(d)了,我们需要在执行完上面所讲的所有流程后在遍历一次prevVnode,然后拿到nextVnode里去找,如果找不到相同key的节点,那就说明这个节点已经被删除了,我们直接用removeChild方法删除Dom。 完整的代码:https://github.com/TingYinHelen/tempo/blob/main/src/platforms/web/patch.js在react-diff分支(目前有可能代码仓库还没有开源,等我实现更完善的时候会开源出来,项目结构可能有变化,看tempo仓库就行) 这里我的代码实现的diff算法很明显看出来时间复杂度是O(n2)。那么这里在算法上依然又可以优化的空间,这里我把nextChildren和prevChildren都设计成了数组的类型,这里可以把nextChildren、prevChildren设计成对象类型,用户传入的key作为对象的key,把vnode作为对象的value,这样就可以只循环nextChildren,然后通过prevChildren[key]的方式找到prevChidren中可复用的dom。这样就可以把时间复杂度降到O(n)。 以上就是react的diff算法的实现。 先说一下上面代码的问题,举个例子,下面这个情况: 如果按照react的方法,整个过程会移动2次: 但是通过肉眼来看,其实只用把li©移动到第一个就行,只需要移动1一次。 首先找到四个节点vnode:prev的第一个,next的第一个,prev的最后一个,next的最后一个,然后分别把这四个节点作比对:1. 把prev的第一个节点和next的第一个比对;2. 把prev的最后一个和next的最后一个比对;3.prev的第一个和next的最后一个;4. next的第一个和prev的最后一个。如果找到相同key的vnode,就做移动,移动后把前面的指针往后移动,后面的指针往前移动,直到前后的指针重合,如果key不相同就只patch更新vnodedata和children。下面来走一下流程: 现在比对的图变成了下面这样: 这个时候的真实DOM: 继续比对 这个时候真实DOM: 现在最新的比对图: 继续比对 真实的DOM变成了这样: 比对的图变成这样: 继续比对: 这就完成了常规的比对,还有不常规的,如下图: 经过1,2,3,4次比对后发现,没有相同的key值能够移动。 这种情况我们没有办法,只有用老办法,用newStartIndex的key拿去依次到prev里的vnode,直到找到相同key值的老的vnode,先patch,然后获取真实dom移动到正确的位置(放到oldStartIndex前面),然后在prevChildren中把移动过后的vnode设置为undefined,在下次指针移动到这里的时候直接跳过,并且next的start指针向右移动。 接下来就是新增节点: 这种排列方法,按照上面的方法,经过1,2,3,4比对后找不到相同key,然后然后用newStartIndex到老的vnode中去找,仍然找不着,这个时候说明是一个新节点,把它插入到oldStartIndex前面 最后是删除节点,我把他作为课后作业,同学可以自己实现最后的删除的算法。 完整代码在 https://github.com/TingYinHelen/ tempo的vue分支。 PS.本文部分内容参考自《比对一下react,vue2.x,vue3.x的diff算法》。 本文分享自华为云社区《90后小姐姐带你了解Vue3.0新特性》,原文作者:技术火炬手。
也就是说,只把prevVnode中后面的元素往前移动,原本顺序是正确的就不变。
现在我们的diff的代码变成了这样:
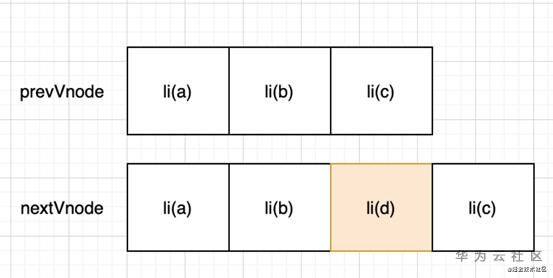

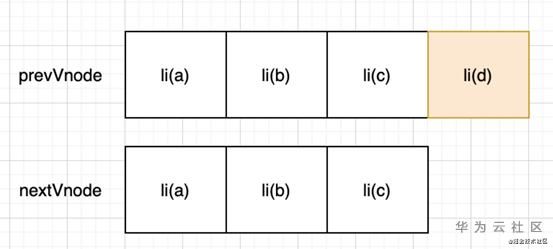

vue的diff算法

li©是第一个节点,不需要移动,lastIndex=2
li(b), j=1, j
于是vue2这么来设计的:


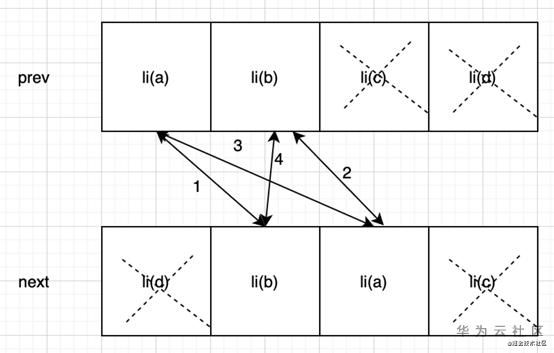


li(b)和li(b)的key相同,patch,都是前指针相同所以不移动,移动指针
这个时候前指针就在后指针后面了,这个比对就结束了。

function updateChildren (elm, prevChildren, nextChildren) {
let oldStartIndex = 0;
let oldEndIndex = prevChildren.length - 1;
let newStartIndex = 0;
let newEndIndex = nextChildren.length - 1;
while (oldStartIndex <= oldEndIndex && newStartIndex <= newEndIndex) {
let oldStartVnode = prevChildren[oldStartIndex];
let oldEndVnode = prevChildren[oldEndIndex];
let newStartVnode = nextChildren[newStartIndex];
let newEndVnode = nextChildren[newEndIndex];
if (oldStartVnode === undefined) {
oldStartVnode = prevChildren[++oldStartIndex];
}
if (oldEndVnode === undefined) {
oldEndVnode = prevChildren[--oldEndIndex];
}
if (oldStartVnode.key === newStartVnode.key) {
patchVnode(newStartVnode, oldStartVnode);
oldStartIndex++;
newStartIndex++;
} else if (oldEndVnode.key === newEndVnode.key) {
patchVnode(newEndVnode, oldEndVnode);
oldEndIndex--;
newEndIndex--;
} else if (oldStartVnode.key === newEndVnode.key) {
patchVnode(newEndVnode, oldStartVnode);
elm.insertBefore(oldStartVnode.elm, oldEndVnode.elm.nextSibling);
newEndIndex--;
oldStartIndex++;
} else if (oldEndVnode.key === newStartVnode.key) {
patchVnode(newStartVnode, oldEndVnode);
elm.insertBefore(oldEndVnode.elm, oldStartVnode.elm);
oldEndIndex--;
newStartIndex++;
} else {
const idxInOld = prevChildren.findIndex(child => child.key === newStartVnode.key);
if (idxInOld >= 0) {
elm.insertBefore(prevChildren[idxInOld].elm, oldStartVnode.elm);
prevChildren[idxInOld] = undefined;
newStartIndex++;
}
}
}
}
