python爬虫实战之旅( 第九章:scrapy框架(上))
1.scrapy框架
1.1 什么是scrapy框架?
首先什么是框架?
框架就是一个集成了很多功能并且具有很强通用性的一个项目模板。
如何学习框架?
专门学习框架封装的各种功能的详细用法。
什么是scrapy?
是爬虫中封装好的一个框架。
scrapy的功能:
- 高性能的持久化存储;
- 异步的数据下载;
- 高性能的数据解析,分布式。
1.2 scrapy环境的安装:
pip install scrapy
1.3 scrapy的基本使用:
1.3.1 新建一个scrapy工程
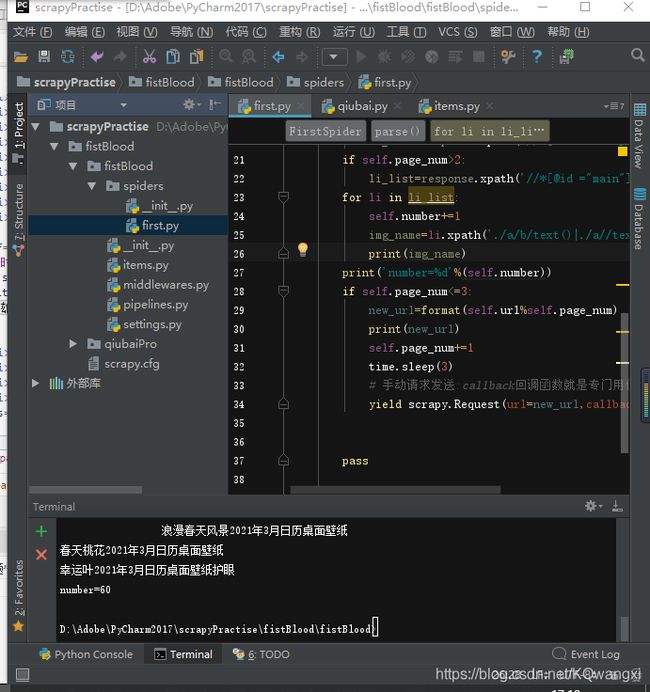
使用pycharm下方自带的控制器:Terminal
![]()
(我最开始没找到Terminal,就用的Git Bash,大概内容是相似的)进入当前新建的项目地址,然后创建一个工程:scrapy startproject xxxPro:
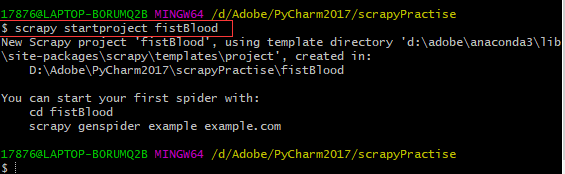
然后查看pycharm中的新建情况,就发现我们命名的“fistBlood”项目建好了:
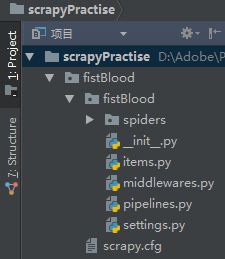
其中:
- “spiders”是一个爬虫文件夹,我们之后会在里面放入一个爬虫的源文件。
- settings是一个配置文件,可以进行相关条件的设置。
1.3.2 在spiders中创建一个具体的爬虫文件
在spiders子目录中创建一个爬虫文件,假设叫它‘first’:
scrapy genspider spiderNmae www.xxx.com
1.3.3 设置爬虫文件中的具体操作
先修改first.py文件中的内容,假设我们要求返回访问的页面代码:
import scrapy
class FirstSpider(scrapy.Spider):
#爬虫文件的名称,就是爬虫源文件的一个唯一标识
name = 'first'
#允许的域名:用来限定start urls列表中哪些url可以进行请求发送
#allowed_domains = ['www.baidu.com/']
#起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['https://www.baidu.com/',
'https://www.sogou.com']
#用于数据解析,reponse参数表示的就是请求成功后对应的响应对象
def parse(self, response):
print(response)
pass
1.3.4 执行工程
然后在Terminal端输入命令scracy crawl spiderName

查看输出时我们会发现找不到显示连接成功的<200 https://www.baidu.com/> <200 https://www.sogou.com>字样,仔细检查发现:
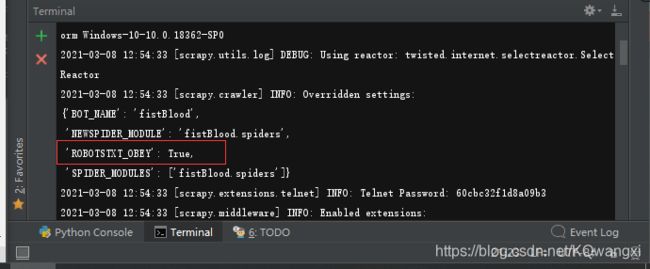
随即我们可以在‘setting’文件中找到对应的语句,这句话默认是遵守君子协议不爬取数据,所以要更改。
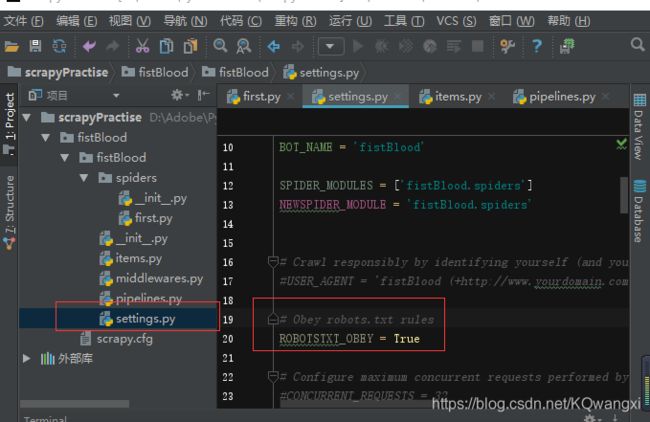
1.3.5 更改setting中的君子协议设定

1.3.6 简化返回内容
而返回的response文本内容又多又杂我们暂时我发分辨有用信息,所以可以选择用两种方法对返回内容进行化简:
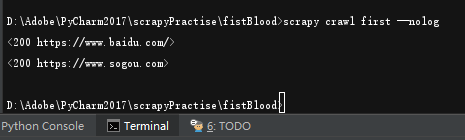
①执行语句改为 :
执行工程:
scracy crawl spiderName --nolog
(这个方法不太推荐,因为如果response带回的内容发生错误,是无法查看的)
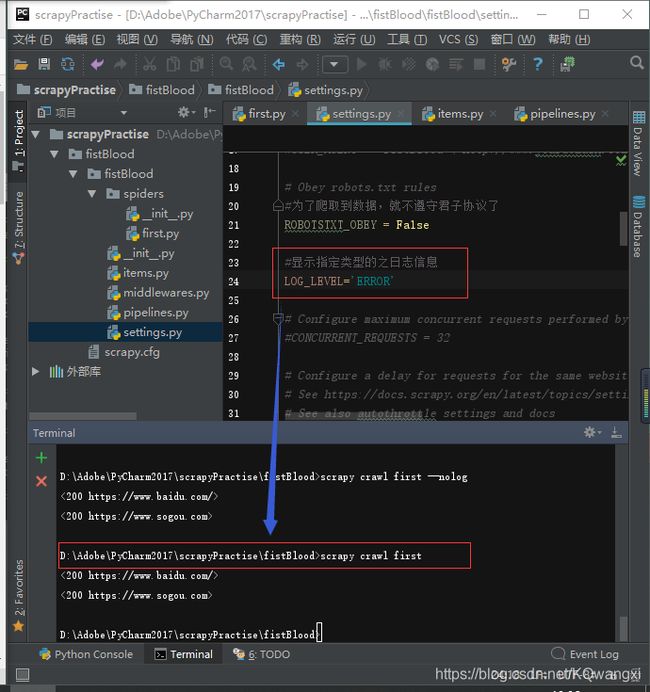
②在‘setting’文件中,加入语句:
#显示指定类型的之日志信息
LOG_LEVEL='ERROR'
1.4 scrapy的数据解析:
假设对糗事百科进行数据爬取(假设只爬取作者名称与发布内容)
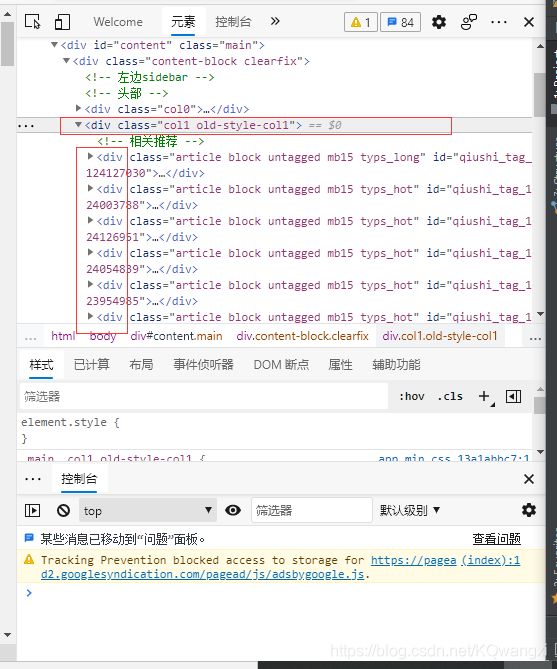
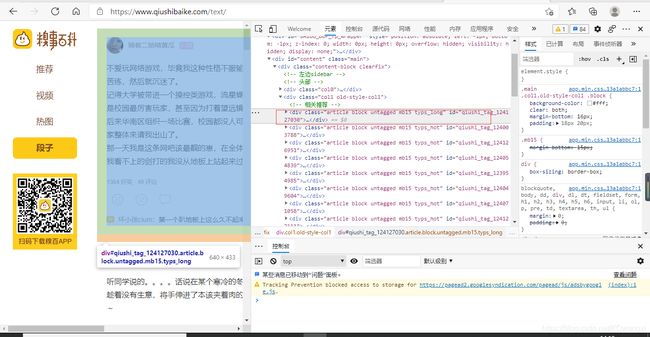
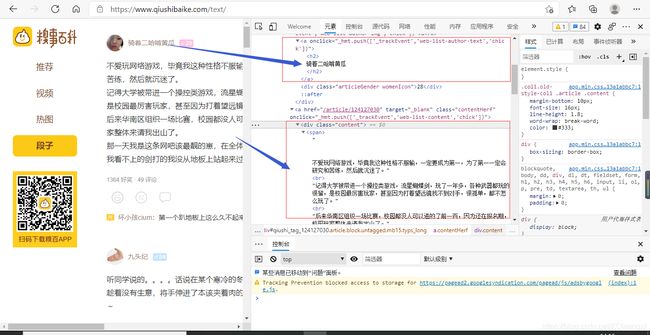
最开始爬取格式是
auther=div.xpath('./div[1]/a[2]/h2/text()')[0]
content=div.xpath('./a[1]/div/span//text()')
发现数据都存储在data的列表中
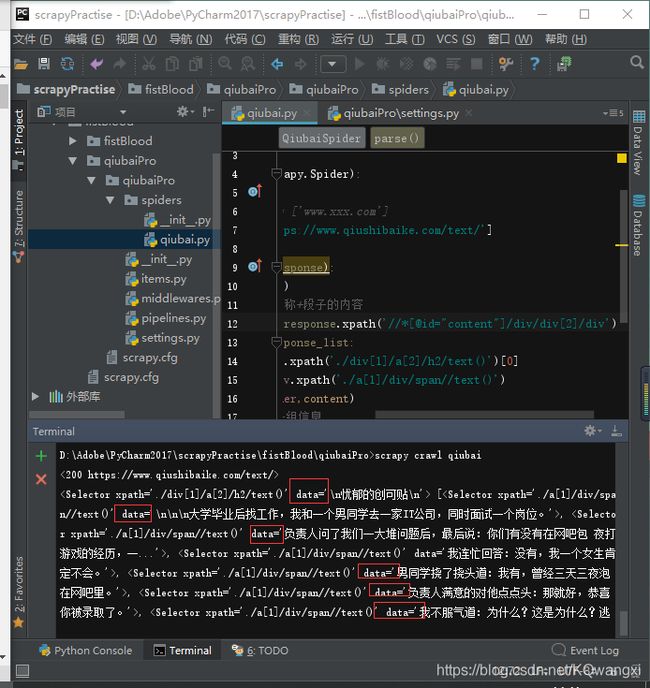
所以加了一句代码,并调用extract()函数将列表变为字符串:
auther=div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
#列表调用了extract之后,则表示将列表中每一个selector对象中data对应的字符串提取了出来
content=div.xpath('./a[1]/div/span//text()').extract()
#将列表转为字符串
content=''.join(content)
spiders中的代码部分:
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
print(response)
#解析:作者的名称+段子的内容
response_list=response.xpath('//*[@id="content"]/div/div[2]/div')
for div in response_list:
#xpath返回的是列表,但是列表元素一定是selector类型的对象
#extract可以将selector对象中的data参数存储的字符串提取出来
auther=div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
#列表调用了extract之后,则表示将列表中每一个selector对象中data对应的字符串提取了出来
content=div.xpath('./a[1]/div/span//text()').extract()
#将列表转为字符串
content=''.join(content)
print(auther,content)
#先只爬取一组信息
break
pass
同时setting中的一些代码也要更改:
#UA伪装
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.11 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
1.5 scrapy的持久化存储:
1.5.1 基于终端指令
要求:
只可以使用parse方法的返回值存储到本地的文本文件中。
注意:
持久化存储对应的文本文件的类型只可以为:‘json’,‘jsonlines’,‘jl’,‘csv’,‘xml’,‘marshal’,‘pickle’
指令:
scrapy crawl qiubai -o qiubai.csv
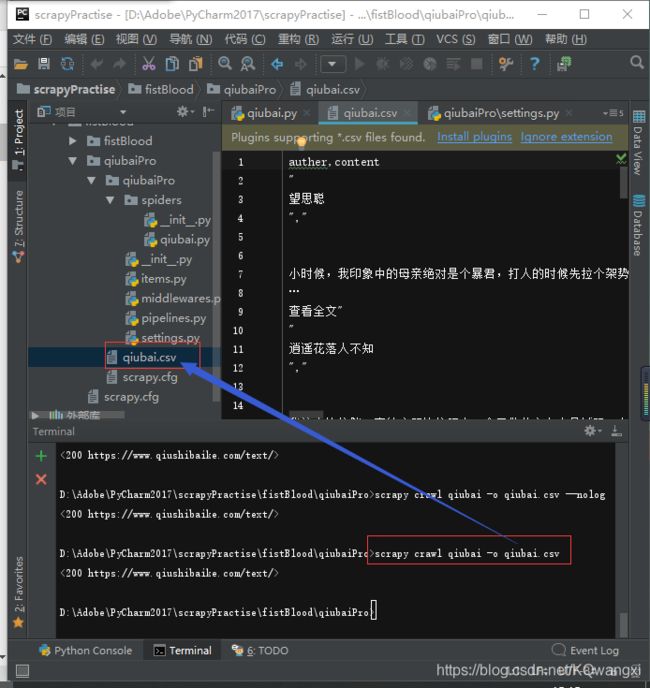
对应的spiders文件要更改返回值
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
print(response)
#解析:作者的名称+段子的内容
response_list=response.xpath('//*[@id="content"]/div/div[2]/div')
#存储所有解析到的数据
all_data = []
for div in response_list:
#xpath返回的是列表,但是列表元素一定是selector类型的对象
#extract可以将selector对象中的data参数存储的字符串提取出来
auther=div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
#列表调用了extract之后,则表示将列表中每一个selector对象中data对应的字符串提取了出来
content=div.xpath('./a[1]/div/span//text()').extract()
#将列表转为字符串
content=''.join(content)
dic ={
'auther':auther,
'content':content
}
all_data.append(dic)
return all_data
1.5.2 基于管道(更推荐)
编码流程
- 1.数据解析
#qiubai.py
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
#解析:作者的名称+段子的内容
response_list=response.xpath('//*[@id="content"]/div/div[2]/div')
#存储所有解析到的数据
all_data = []
for div in response_list:
#xpath返回的是列表,但是列表元素一定是selector类型的对象
#extract可以将selector对象中的data参数存储的字符串提取出来
auther=div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
#列表调用了extract之后,则表示将列表中每一个selector对象中data对应的字符串提取了出来
content=div.xpath('./a[1]/div/span//text()').extract()
#将列表转为字符串
content=''.join(content)
- 2.在item类中定义相关的属性
#items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class QiubaiproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
auther = scrapy.Field()
content = scrapy.Field()
pass
- 3.将解析的数据封装存储到item类型的对象
修改对应的spiders文件中的qiubai.py
#qiubai.py
import scrapy
from qiubaiPro.items import QiubaiproItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
#解析:作者的名称+段子的内容
response_list=response.xpath('//*[@id="content"]/div/div[2]/div')
#存储所有解析到的数据
all_data = []
for div in response_list:
#xpath返回的是列表,但是列表元素一定是selector类型的对象
#extract可以将selector对象中的data参数存储的字符串提取出来
auther=div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
#列表调用了extract之后,则表示将列表中每一个selector对象中data对应的字符串提取了出来
content=div.xpath('./a[1]/div/span//text()').extract()
#将列表转为字符串
content=''.join(content)
#实例化一个item对象
item= QiubaiproItem()
#封装属性
item['auther']=auther
item['content']=content
#将item提交给管道
yield item
pass
- 4.将item类型的对象提交给管道进行持久化存储的操作
#piipelines.py
from itemadapter import ItemAdapter
class QiubaiproPipeline(object):
fp = None
# 重写父类的一个方法:该方法只在开始爬虫的时候被调用一次
def open_spider(self, spider):
print('开始爬虫……')
self.fp = open('./qiubai.txt', 'w', encoding='utf-8')
#专门用来处理item类型的对象的
#该方法可以接收到爬虫文件提交过来的item对象
#该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
auther=item['auther']
content=item['content']
#a存储到本地
self.fp.write(auther+':'+content+'\n')
return item
def close_spider(self,spider):
print('结束爬虫!')
self.fp.close()
- 5.在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
- 6.在配置文件中开启管道
在settings文件约68行的位置找到下列语句并解除注释:
#settings.py
ITEM_PIPELINES = {
'qiubaiPro.pipelines.QiubaiproPipeline': 300,
#300表示的是优先级,数值越小优先级越高
}
2.基于spider的全站数据爬取
就是将网站中某板块下的全部图片名称进行爬取。值得注意的就是该网站第二页第三页相应的ul标签发生了一定的位置变化
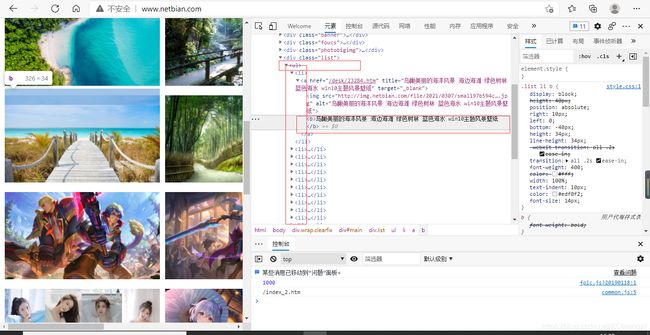
import scrapy
import time
class FirstSpider(scrapy.Spider):
#爬虫文件的名称,就是爬虫源文件的一个唯一标识
name = 'first'
#允许的域名:用来限定start urls列表中哪些url可以进行请求发送
#allowed_domains = ['www.baidu.com/']
#起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.netbian.com/']
#生成一个通用的url模板
url='http://www.netbian.com/index_%d.htm'
page_num=2
number = 0
#用于数据解析,reponse参数表示的就是请求成功后对应的响应对象
def parse(self, response):
if self.page_num<=2:
li_list=response.xpath('//*[@id="main"]/div[4]/ul/li')
if self.page_num>2:
li_list=response.xpath('//*[@id ="main"]/div[3]/ul/li')
for li in li_list:
self.number+=1
img_name=li.xpath('./a/b/text()|./a//text()').extract_first()
print(img_name)
print('number=%d'%(self.number))
if self.page_num<=3:
new_url=format(self.url%self.page_num)
print(new_url)
self.page_num+=1
time.sleep(3)
# 手动请求发送:callback回调函数就是专门用作于数据解析的
yield scrapy.Request(url=new_url,callback=self.parse)
pass
然后“scrapy crawl first”运行结果: