2- OpenCV+TensorFlow 入门人工智能图像处理-opencv入门
本章内容
- Anaconda一站式开发环境
- OPenCV基础入门(像素,图片的封装格式,编码格式)
- TensorFlow基础入门
本章主要内容
- OpenCV初识
- OpenCV文件结构
- Demo1 图片读取: 图片封装格式 压缩编码
- Demo2 图片写入: 图片质量
- Demo3 像素操作: 矩阵 颜色空间
- 课程小结
TensorFlow基础入门
- TensorFlow运算的本质
- Demo1: 变量与常量的使用
- Demo2: 四则运算for变量&常量
- Demo3: 矩阵运算基础
- Demo4: 数据初始化方式
- Demo5: 非线性回归逼近股票均线
学会Numpy和Matplotlib
OpenCV初识
opencv: open source computer vision Library
开源计算机视觉库

本质上由一系列的源代码组成。若干个模块构成了opencv
模块的介绍会专门介绍
应用场景: 指纹识别,人脸识别,虹膜识别。图像特效,磨皮美颜
跨平台,电脑,手机端。
IMAGENET 官网
95% 97%-98%
TensorFlow在语音和图像识别取的很大效果。
windows&mac下anaconda大家
- 下载并安装anaconda
- 下载并安装TensorFlow和opencv
- 下载并安装notebook
官网下载:
anaconda5已经集成了opencv和TensorFlow
一直下一步。默认。
home页面。环境是在env中管理。
create按钮,添加环境TensorFlow
点击all 搜索opencv apply
安装notebook。选中TensorFlow环境,安装notebook。
windows下
创建虚拟环境。
- anaconda5.x
- 1.4 和 1.1
- opencv3.3
- py3.6
我本地是非常老的python3.5.1然后安装了TensorFlow1.2.1gpu版本+cuda8.0
+cudnn5.1
安装了opencv opencv_python-3.2.0.7-cp35-cp35m-win_amd64.whl
但是import opencv2时遇到问题
Traceback (most recent call last):
File "", line 1, in
File "D:\softEnvDown\Anaconda2\envs\py3\lib\site-packages\cv2\__init__.py", line 7, in
from . import cv2
ImportError: DLL load failed: 找不到指定的模块。
网上说下载vs2015的依赖,可是我本地已经有了。然后找到解决方案
下载对应的python官网包。复制python3.dll进入同python.exe同级目录。
测试案例
打开jupyter notebook
绿色运行,shutdown。rename。
这一排按钮保存,添加单元格,剪切,复制。粘贴。
运行,停止按钮。
helloworld
import tensorflow as tf
hello = tf.constant('mtianyan love tensorflow!')
sess = tf.Session()
print(sess.run(hello))
sess.close()
import cv2
print('hello opencv')

opencv图片的读取和显示
import cv2
# imread:参数1: 图片的名称,参数2: 图片的类型。
# 0 gray灰度图片 1 彩色图片 ;返回当前图片内容
img = cv2.imread('image0.jpg',1)
# imshow,参数1: 窗体名称, 参数2: 要展示的图片内容
cv2.imshow('image',img)
# 程序stop
cv2.waitKey (0)
这门课学习方法,所有的知识点一定要有配套的案例。
- 案例驱动 2. 类比 3. 合理分配时间
28理论。 80%时间分配在20%核心知识上

opencv的第三方开发库,模块组织结构
release
我们选择了3.x体系。
windows版本是一个exe可以直接运行。mac上是一个framework
下载与我们对应安装的python的opencv包版本一致的版本
mac下打开时这样的
headers来讲解opencv中的几个重点模块
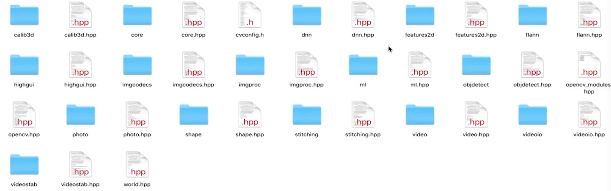
一个文件夹代表opencv中一个重要的模块
calib3d 3d内容相关。
core 核心模块,基础数据类型,绘图相关。所有基础
dnn 模块 与神经网络相关的一个模块
feature2d 与二维图形的特征提取,图像匹配等相关。
flann 和聚类相关,比如邻域搜索算法
highgui 重要,图形相关交互。重要但我们用的比较少。
imacodecs imgproc这两个很重要: 描述图像处理相关的,滤波器,颜色处理。
ml machine- learning 机器学习模块
objectect 物体检测模块
Photo 图片的处理,图片的修复去燥。
shape 很少用到
stitching 拼接模块,大图像拼接。360全景。
video videoio videostab 视频信息,视频分解图片,图片合成视频
ml模块是我们会重点学习的模块。knn 最近邻域, svm支持向量机,决策树,神经网络。
图片的写入
复习上节课的
import cv2
# 1 文件的读取 2 封装格式解析 3 数据解码 4 数据加载
# 2,3 步骤是opencv内部帮我们做的
img = cv2.imread('image0.jpg',1)
cv2.imshow('image',img)
# 图片格式: jpg png(文件的封装格式);
# 文件会由两部分组成:
# 1 文件头: 数据部分的解码信息和附加信息
# 2 文件数据(不指图片原始数据,而指图片进行压缩编码之后的数据)
# 解码器根据解码信息和附加信息将图像还原成原始数据
cv2.waitKey (0)
# 1.14M 压缩过 130k ,方便存储传输
图片的写入
import cv2
# 1 图片名称 2 图片类型为1彩色图片 返回图片内容
img = cv2.imread('image0.jpg',1)
# 参数1: 图片名称 参数2: 图片的数据(解码之后的图片原始数据)
cv2.imwrite('image1.jpg',img) # 1 name 2 data
不同图片质量的保存
图片的编码是为了减小图片的体积,提高压缩比
不同的压缩比,对应不同的图片大小。
实现不同压缩比的jpg 和 png的保存。
import cv2
# 读取图片
img = cv2.imread('image0.jpg',1)
# 第一个参数: 图片名称
# 第二个参数: 图片的原始数据
# 第三个参数: 图片的质量(0-100)
cv2.imwrite('imageTest.jpg',img,[cv2.IMWRITE_JPEG_QUALITY,0])
# 1M 100k(还行) 10k(此时图片质量验证下降) 0-100 有损压缩
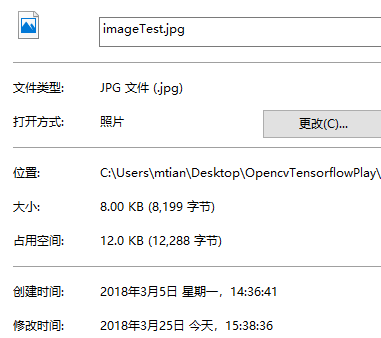

可以看到压缩前后,图片的大小压缩了有10倍
图片的质量非常差。
原始图片1m压缩10倍100k时还可以保证图片的质量。
控制到50%,压缩了大小,图片质量下降不是太多严重
png的压缩
- 无损压缩
- 透明度属性(除过可以修改rgb值还可以修改透明度)
import cv2
img = cv2.imread('image0.jpg',1)
# 名字,内容,压缩比属性
cv2.imwrite('imageTest.png',img,[cv2.IMWRITE_PNG_COMPRESSION,0])
# jpg 0 压缩比高(0-100)
# png 0 压缩比低 (0-9) 图片会变大
png的压缩为0时反倒把图片大小变大了。

像素操作基础
图像基础知识

方法之后可以看到图片由一个一个的方块组成,每一个方块代表一个像素点。
像素点到底是什么
计算机中每种颜色都可以由rgb三种分量进行合成,
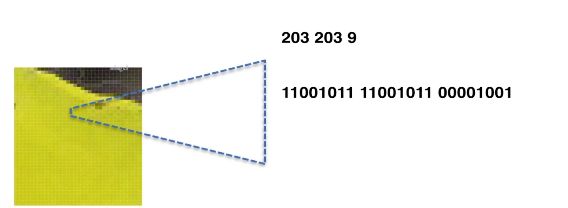
比如: 黄色,(203,203,9)
对于一个8位颜色深度的图片来说,rgb每一个颜色的分量范围在0-255
颜色深度
8位的颜色深度,表示每一个颜色分类的取值都有2的8次方这么多个。
- 像素
像素就是将图片方法之后的一个个的方块
- RGB
每种颜色都是由RGB三种分量来组成的。
- 颜色深度
对于一个8位的颜色深度来说,可以表示的颜色范围是0-255
对于一个RGB图像来说,每一个分量都有256种。合到一起就是256的三次方
对于一个8位颜色深度的rgb图像,可以表示出256的三次方这么多中颜色
一个像素点可以由rgb三种颜色表示。比如我们的计算机中可以看到黄色被分解成了三种颜色
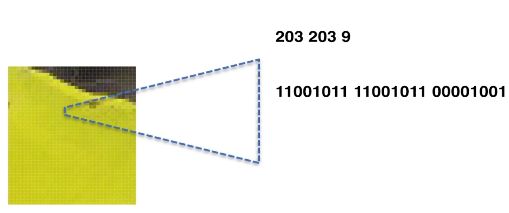
分别是红203
图片在计算机中以二进制的方式进行存储。
图片的宽高
- w h 640,480 的图片
表示图片在水平上有640个像素点,竖直上有480个像素点
- 1.14m =
730*547得到的是图片的像素。每个像素有rgb三个分量,每个分量是8位深度
将bit转换为字节(B)除以8,然后在除以1024转换为kb,除以1024转换为MB
- RGB alpha通道。png描述图片的透明度
无损压缩,描述透明信息
- RGB bgr
第一个像素的分类不是红色而是蓝色
- bgr b g
每一个颜色分量,都会称之为颜色通道。
像素: 小方块
图像的像素点个数,3,8
像素操作
读取具体的像素值。了解图片存储的坐标系结构
这个矩形描绘的是我们当前的图片
再来绘制一个坐标。
x轴表明的是我们图片的列,y轴表明的是我们图片的行

x轴是水平方向上,图片的宽度(列),y轴是竖直方向上,图片的高度(行)。
读取某一个具体的坐标,读取(100,100)这个点,它有一个唯一的x轴与y轴对应点
以一个元组来读取的,一般是rgb 但是opencv读取回来是bgr
