
本篇文章是一篇长篇的研究报告,共有近3.8万字,整合参考了很多相关的行业技术文章,集百位大佬的文章资料于一身,如有雷同,纯属崇拜您的学问!!文末已有注明转载参考的出处,特此申明本篇回答有整合其他大佬的答案以及文章,如有不同意的评论区留言,我删除,请不要言语攻击我,谢谢,我还是个宝宝!
一、语音识别的基础概念
1、定义:语音识别(Automatic Speech Recognition)是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。
2、发展ASR在近几年的流行,与以下几个关键领域的进步有关:
(1) 摩尔定律持续有效
使得多核处理器、通用计算图形处理器GPGPU、CPU/GPU集群等技术,为训练复杂模型提供了可能,显著降低了ASR系统的错误率。
(2)大数据时代
借助互联网和云计算,获得了真实使用场景的大数据训练模型,使得ASR系统更具鲁棒性(健壮性、稳定性)。
(3)移动智能时代
移动设备、可穿戴设备、智能家居设备、车载信息娱乐系统,变得越来越流行,语音交互成为新的入口。
3、研究领域分类
根据在不同限制条件下的研究任务,产生了不同的研究领域。如图:

4、语音识别任务分类

5、应用
语音交互作为新的入口,主要应用于上图中的两大类:帮助人与人的交流和人与机器的交流。

(1)帮助人与人的交流 HHC
应用场景如,如翻译系统,微信沟通中的语音转文字,语音输入等功能。
语音到语音(speech-to-speech,S2S)翻译系统,可以整合到像Skype这样的交流工具中,实现自由的远程交流。
S2S组成模块主要是,语音识别-->机器翻译-->文字转语音,可以看到,语音识别是整个流水线中的第一环。
(2)帮助人与机器的交流 HMC
应用场景如,语音搜索VS,个人数码助理PDA,游戏,车载信息娱乐系统等。
6、对话系统
要注意的是,我们上面所说的应用场景和系统讨论,都是基于【语音对话系统】的举例。
语音识别技术只是其中关键的一环,想要组建一个完整的语音对话系统,还需要其他技术。
语音对话系统:(包含以下系统的一个或多个)
(1)语音识别系统: 语音-->文字
(2)语义理解系统:提取用户说话的语音信息
(3)文字转语音系统:文字-->语音
(4)对话管理系统:1)+ 2)+3)完成实际应用场景的沟通

二、语音识别的基本原理:
1、本质:语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元
2、系统架构概述
下图是语音识别系统的组成结构,主要分4部分:
信号处理和特征提取、声学模型(AM)、语言模型(LM)和解码搜索部分。

左半部分可以看做是前端,用于处理音频流,从而分隔可能发声的声音片段,并将它们转换成一系列数值。
声学模型就是识别这些数值,给出识别结果。后面我们会详细解释。
右半边看做是后端,是一个专用的搜索引擎,它获取前端产生的输出,在以下三个数据库进行搜索:一个发音模型,一个语言模型,一个词典。
【发音模型】表示一种语言的发音声音 ,可通过训练来识别某个特定用户的语音模式和发音环境的特征。
【语言模型】表示一种语言的单词如何合并 。
【词典】列出该语言的大量单词 ,以及关于每个单词如何发音的信息。
a)信号处理和特征提取:
以音频信号为输入,通过消除噪声和信道失真对语音进行增强,将信号从时域转化到频域,并为后面的声学模型提取合适的有代表性的特征向量。
b)声学模型:
将声学和发音学的知识进行整合,以特征提取部分生成的特征为输入,并为可变长特征序列生成声学模型分数。
c)语言模型:
语言模型估计通过训练语料学习词与词之间的相互关系,来估计假设词序列的可能性,又叫语言模型分数。如果了解领域或任务相关的先验知识,语言模型的分数通常可以估计的更准确。
d)解码搜索:
综合声学模型分数与语言模型分数的结果,将总体输出分数最高的词序列当做识别结果。
3、流程:
首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特征,在此基础上建立语音识别所需的模板。而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。然后根据此模板的定义,通过查表就可以给出计算机的识别结果。显然,这种最优的结果与特征的选择、语音模型的好坏、模板是否准确都有直接的关系。
(1)语音识别系统构建过程:
1)训练:训练通常是离线完成的,对预先收集好的海量语音、语言数据库进行信号处理和知识挖掘,获取语音识别系统所需要的“声学模型”和“语言模型”
2)识别:识别过程通常是在线完成的,对用户实时的语音进行自动识别,识别过程通常又可以分为“前端”和“后端”两大模块。
A.前端:前端模块主要的作用是进行端点检测(去除多余的静音和非说话声)、降噪、特征提取等;
B.后端:后端模块的作用是利用训练好的“声学模型”和“语言模型”对用户说话的特征向量进行统计模式识别(又称“解码”),得到其包含的文字信息,此外,后端模块还存在一个“自适应”的反馈模块,可以对用户的语音进行自学习,从而对“声学模型”和“语音模型”进行必要的“校正”,进一步提高识别的准确率。
三、语音识别技术原理
1、工作原理解读:
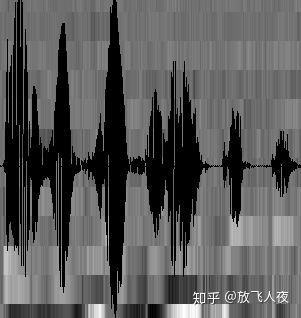
(1)声波:我们知道声音实际上是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。

(2)分帧:对声音进行分析,需要对声音分帧,也就是把声音切开一小段一小段,每小段称为一帧。帧操作一般不是简单的切开,而是使用移动窗函数来实现。帧与帧之间一般是有交叠的,就像下图:
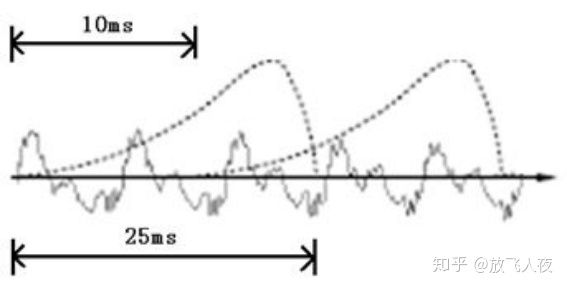
图中,每帧的长度为25毫秒,每两帧之间有10毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征。至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
接下来就要把这个矩阵变成文本了。
(3)语音识别单元
语音识别单元有单词 (句) 、音节和音素三种,具体选择哪一种,根据具体任务来定,如词汇量大小、训练语音数据的多少。

1)音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见The CMU Pronouncing Dictionary。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,在汉语里,最小的语音单位是音素,是从音色的角度分出来的,有兴趣的可以自己去了解一下哈。
2)音节:一个音素单独存在或几个音素结合起来,叫做音节。可以从听觉上区分,汉语一般是一字一音节,少数的有两字一音节(如“花儿”)和两音节一字。

3)状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
4)流程:
第一步,把帧识别成状态(难点)。
第二步,把状态组合成音素。
第三步,把音素组合成单词。

在上图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态,语音识别的结果就出来了。
那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态。比如下面的示意图,这帧在状态S3上的条件概率最大,因此就猜这帧属于状态S3。
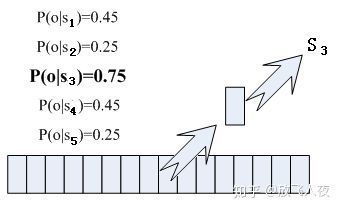
那这些用到的概率从哪里读取呢?有个叫“声学模型”的东西,里面存了一大堆参数,通过这些参数,就可以知道帧和状态对应的概率。获取这一大堆参数的方法叫做“训练”,需要使用巨大数量的语音数据,训练的方法比较繁琐,现在有很多训练模型的工具(如:CMUSphinx Open Source Speech Recognition ,Kaldi ASR)。
但这样做有一个问题:每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号,相邻两帧间的状态号基本都不相同。假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实根本没有这么多音素。如果真这么做,得到的状态号可能根本无法组合成音素。实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。
解决这个问题的常用方法就是使用隐马尔可夫模型(Hidden Markov Model,HMM)。这东西听起来好像很高深的样子,实际上用起来很简单:首先构建一个状态网络,然后从状态网络中寻找与声音最匹配的路径。
这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限,比如你设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。那如果想识别任意文本呢?把这个网络搭得足够大,包含任意文本的路径就可以了。但这个网络越大,想要达到比较好的识别准确率就越难。所以要根据实际任务的需求,合理选择网络大小和结构。
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的累积概率最大,这称之为“解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为Viterbi算法,用于寻找全局最优路径。
累积概率:
观察概率:每帧和每个状态对应的概率
转移概率:每个状态转移到自身或转移到下个状态的概率
语言概率:根据语言统计规律得到的概率
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,可以利用某门语言本身的统计规律来帮助提升识别正确率。语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
语音识别长篇研究(二)

参考文章链接如下:
https://www.jianshu.com/p/8041e1f4fdf3
https://www.jianshu.com/p/a3e2915a3783
https://www.jianshu.com/p/1cfa15eaadfe
https://www.jianshu.com/p/2c99885b9a8f
https://www.jianshu.com/p/60ef7117a612
https://www.zhihu.com/search?type=content&q=%E8%AF%AD%E9%9F%B3%E6%BF%80%E6%B4%BB%E6%A3%80%E6%B5%8B%E7%9A%84%E9%9A%BE%E7%82%B9
https://www.jianshu.com/p/350a4f447a5f
https://www.jianshu.com/p/c088c89a7f09
https://www.jianshu.com/p/45a764b53474
https://www.jianshu.com/p/7c94467f58ff
http://www.woshipm.com/pd/894645.html
https://www.jianshu.com/p/dc8954aebbef
https://www.jianshu.com/p/3edca44c3e53
https://blog.csdn.net/zhinengxuexi/article/details/89355659