曾几何时你想要在某网站找自己想要的信息,因为不能批量操作而不得不手动复制粘贴,耗费大量时间。后来你得知了有种叫做“爬虫”的东西,可以快速批量的抓取想要的数据和信息,但是了解了它的原理之后又望而却步,需要会编程,需要写代码,学习成本相对较高,而且低级入门的爬取水平并不能很好的达到想要的结果。今天就和大家分享一下如何用工具来爬取我们想要的数据和信息。这篇文章还有另外一个名字:爬取了陈奕迅的5万歌词,看看Eason到底在唱什么。
文章结构
目标:爬取Eason的所有歌词,进行词频分析得到答案
操作方法:① 找寻数据目标站点 ② 选取爬虫工具 ③ 获取数据 ④ 数据清洗 ⑤ 词频分析 ⑥ 结论描述
1.寻找目标站点
在QQ音乐的官网搜索陈奕迅然后点击他的歌词模块,这样这就算找到需要的数据源了,接下来到第二部选取好用的爬虫工具对这些数据进行爬取。
2.选取爬虫工具
①这里介绍的我经常用的“八爪鱼”工具,下载安装好八爪鱼后,打开操作界面:如下图

②这里使用适合初学者的向导模式,点击之后进行爬取配置
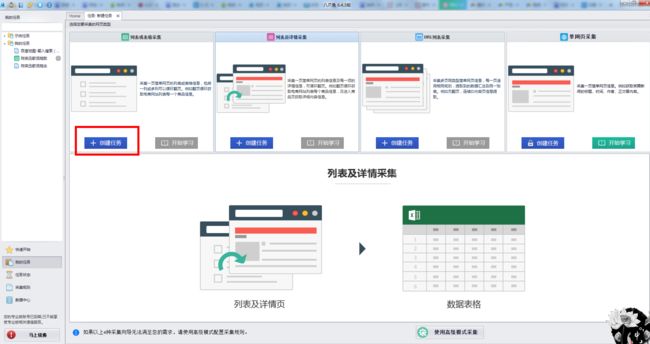
③选择第一个模式进行单页可循环采集,第一步和第二步分别是建立任务描述和输入数据源网址,网址就是刚才QQ音乐官网搜索陈奕迅点击歌词模块后的跳转链接

④选中至少两个想要抓取的元素,软件会自动抓取其他相同类型的信息
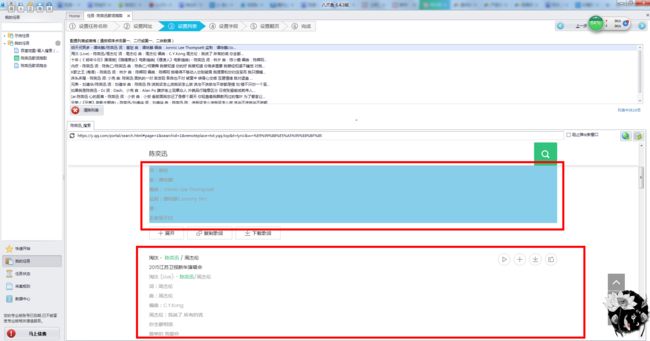
⑤这里设置字段,选中下面刚才抓取的数据,给字段命名,例如:陈奕迅歌词信息

⑥最后选中翻页按钮,设置翻页次数,一般翻页次数大于原本的页数就可以了

4.获取数据
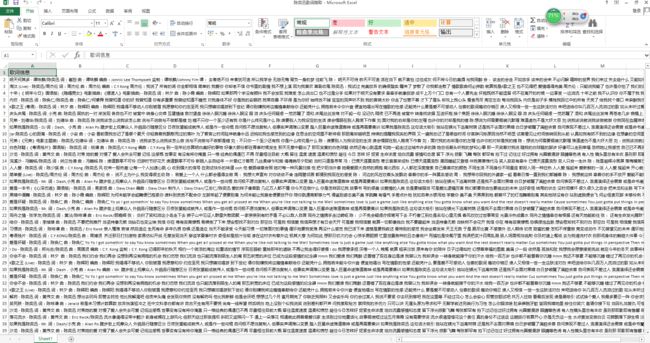
①最后选择采集方式,进行采集

②一段时间后,得到采集的数据
4.数据清洗
并不是爬取的数据马上就可以拿来用,例如上面excel中的数据,由于爬取方式的粗略导致其中作词,作曲,以及作词人,作曲人这些都包含在爬出的数据里面,这些就属于要清理掉的。其次数据源本来就可能存在问题,例如QQ音乐陈奕迅歌词模块的 第20页竟然出现了 吴克群的 N首歌曲,按照既定的规则,这些歌词也会被爬取,但是并不是我们需要的,所以也应该被清理掉。

5.词频分析
这里给大家推荐几个智能的语意分析系统
Rost:http://www.cncrk.com/downinfo/54638.html
图悦:http://www.picdata.cn/
语义分析系统:http://ictclas.nlpir.org/nlpir/
Tagul:https://tagul.com/
腾讯文智:http://nlp.qq.com/semantic.cgi
Tagxedo词云:http://www.tagxedo.com/
这里我们使用上面第三个(这个语义分析系统相对好用,但是有字数限制,这里简单作为举例用,文本数据很多建议用第一个):

但是个人感觉上面的语义分析工具都不好用,IBM的人工智能沃森分析了鲍勃·迪伦所有歌曲,给出的结论是:鲍勃·迪伦的歌曲里流露出两种情绪,枯萎的爱情和流逝的光阴。真是好文艺,好强大。
6.结论描述
这个语义分析系统可以分析出Eason所有歌曲里面的词频和流露出的情绪,虽然没有沃森那么高级,但也算是一个好用的工具。其它的功能感兴趣的同学可以自己去体验下。

写在最后:得到数据源的方式有很多种,无论是粘贴复制,自己写爬虫还是使用工具,重点还是数据的分析和处理,对得到的数据进行各种维度的分析,设计出分析模型。最后分析出什么结论,指导并解决了什么问题才是数据分析的灵魂。