pytorch seq2seq+attention机器翻译注
准备深入学习一下神经网络的搭建方法的时候,选了机器翻译来试试,正好查了很多资料,发现pytorch里有例子。就结合自己的理解和探究记录一下。原文实现代码:https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
其他博主的中文翻译及解释:
https://blog.csdn.net/u014514939/article/details/89410425?utm_medium=distribute.pc_relevant.none-task-blog-title-2&spm=1001.2101.3001.4242
(此处只做大致流程和细节分析,完整代码上述原文就可获取)
机器翻译流程:
喂进神经网络前的数据准备与处理
1.准备语料,也就是句子对,我找到的是英语-法语的语料,下载地址:https://download.pytorch.org/tutorial/data.zip
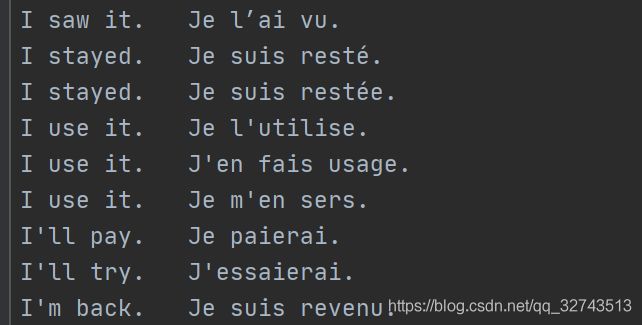
2.明确输入进神经网络的是怎样的数据,也就是怎样将数据处理成神经网络能理解的形式。我们这里不讨论one-hot、embedding等概念,只需要明白,将一个句子转化成数字来表示就可以,比如“i love you”,可能对应的向量形式就是[3,63,8],"i hate you"可能是[3,99,8],也就是句子中的每一个词都是由一个能表示他的数字来代指的(这个数字在此时并没有什么高深的意思,仅仅是个数字而已,就跟取名字一样)
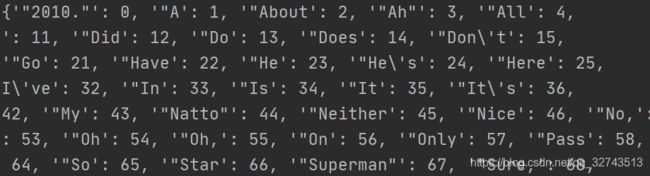
为句子加上首尾标识SOS、EOS后转化为向量:
(此处是我自己实现的代码,格式与原文有点不一样,但是表述的是这个意思)
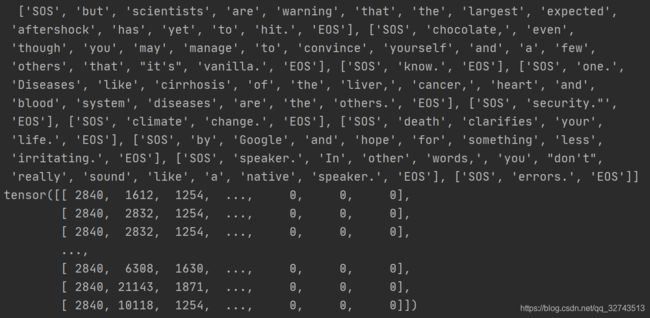
Seq2Seq训练细节
每一轮训练时数据的使用
将句子对转化为向量后,就可以将其喂进神经网络中,这个机器翻译模型在开始训练后trainIters函数里。在训练时,每次喂进一对句子向量
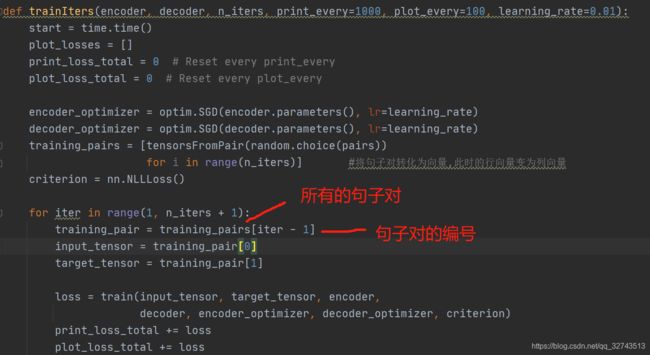
需要注意的是,原文实现的代码里,将此处喂进去的向量全部转化为了列向量喂进去,如果自己实现代码不注意会报错。
而在encoder_decoder模型训练时每次喂进去的是一个句子中的一个词。

神经网络中train的细节
encoder的输入input_tensor[ei], encoder_hidden,在原文中input_tensor[ei] 是一个tensor([1])的单一元素,encoder_hidden在初始化时大小为tensor[1,1,256]

而在输入后,input_tensor经过embedding层输出形状是tensor([1,256]),之后经过.view(1,1,-1),形状变为tensor([1,1,256]),encoder的输出也是torch.Size([1, 1, 256])

在每一轮的encoder训练完后得到的输出encoder_output,encoder_hidden,由于是单个单词训练的结果,其实从内容上看是一样的,因此,encoder_outputs[ei]相当于保留了每一步每一个单词的state。

decoder中由于名义上不知道句子的第一个开头词是什么,因此使用通用标识SOS来作为句子的第一个输入。
对于decoder的三个输入decoder_input, decoder_hidden, encoder_outputs:
decoder_input即是目标句子的此轮输入进去的单词向量,大小为tensor.size([1])
decoder_hidden是直接继承自encoder_hidden,此时的encoder_hidden是原句子最后一个单词的输出,大致来说,这样一个输出可以看做是包含了一整个句子的信息,大小是tensor.size([1,1,256])
encoder_outputs[ei]则是保存了一个句子中所有词的当时输出的状态。encoder_outputs的大小是torch.Size([10, 256])
decoder内部
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
print(342, torch.cat((embedded[0], hidden[0]), 1).size(), attn_weights)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0)) #必须有三个维度
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
print(output.size(), hidden.size(), attn_weights.size())
return output, hidden, attn_weights
这里首先要注意的是decoder的输入和输出output_size都是法语词表的大小,而具体到最后的三个输出output,hidden,attn_weight各自的大小为torch.Size([1, 79]) torch.Size([1, 1, 256]) torch.Size([1, 10])。至于output的大小原因,因为对于decoder来说,最终是为了确定在法语词表中哪个词的可能性最大,因此它最后一层实际上可以看做一个分类类别为词表大小的分类模型。
attention的问题
一般而言attention的思想用比较简单的话来说就是两个向量之间的相似度,他的方法有很多简单的乘法,点积,还有各种公式,但是我理解的便是两个向量之间越相似,方向越接近,他们点乘后就越大
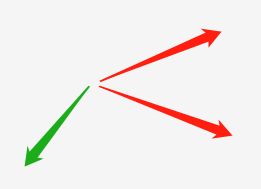
如图两个红色向量因为方向近似,相乘后会是一个正的较大的值,而绿色的和红色的方向相悖(不相似),他们乘出来会使一个负值。
而关于原文attention实现的问题,我在看的时候就很困惑觉得无法理解,查阅大量资料也没有结果,最后在某个角落找到了这种实现attention的方法其实错的,因此如果无法理解建议去看论文或者别的例子的attention实现。
查错指路:https://zhuanlan.zhihu.com/p/68637282
