【PyTorch】5 姓氏生成RNN实战——使用语言生成名称
生成名称与字符级RNN
- 1. 准备数据
- 2. 建立网络
- 3. 准备训练
- 4. 训练网络
- 5. 测试
- 6. 全部代码
- 总结
这是官方NLP From Scratch的一个教程(2/3),原中文链接,本文是其详细的注解
1. 准备数据
准备数据过程与上篇姓氏分类RNN实战不同之处在于:
all_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1 # Plus EOS marker
此部分代码如下:
import unicodedata
import string
import glob
import os
all_letters = string.ascii_letters + " .,;'-" # abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'
n_letters = len(all_letters) + 1 # 59
category_lines = {
}
all_categories = []
def unicodeToAscii(s):
Ascii = []
for c in unicodedata.normalize('NFD', s):
if unicodedata.category(c) != 'Mn' and c in all_letters:
Ascii.append(c)
return ''.join(Ascii)
def findFiles(path):
return glob.glob(path)
def readLines(filename):
lines = open(filename, 'r', encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
path = '... your path\\data\\'
if __name__ == '__main__':
for filename in findFiles(path + 'names\\*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))
结果:
# categories: 18 ['Arabic', 'Chinese', 'Czech', 'Dutch', 'English', 'French', 'German', 'Greek', 'Irish', 'Italian', 'Japanese', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Scottish', 'Spanish', 'Vietnamese']
O'Neal
2. 建立网络
此部分定义:
- class model(nn.Module)
- def randomChoice(l): # 从列表中随机选取一项
- def randomTrainPair(): # 从类别中随机获得一个类别和随机的line
关于nn.Dropout(0.1)函数,带Dropout的网络可以防止出现过拟合,该层的神经元在每次迭代训练时会随机有10% 的可能性被丢弃
3. 准备训练
对于每个时间步(即,对于训练词中的每个字母),网络的输入将为(category, current letter, hidden state),而输出将为(next letter, next hidden state)。 因此,对于每个训练集,我们都需要类别,一组输入字母和一组输出/目标字母
关于find(str, beg=0, end=len(str)-1)函数,检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1
此部分定义:
- def categortTensor(category): # 类别的one-hot vector
- def inputTensor(line): # 输入的首字母到尾字母的one-hot矩阵(不包括EOS)
- def targetTensor(line): # 目标的第二个字母尾部(EOS)的LongTensordef randomTrainingExample(): # 随机提取(类别,行)对,并将其转换为所需的(类别,输入,目标)张量
4. 训练网络
.unsqueeze_(-1):增加一个维度
训练过程:
0m 17s (5000 5.0%) 2.9710
0m 34s (10000 10.0%) 1.9783
0m 51s (15000 15.0%) 2.7877
1m 8s (20000 20.0%) 2.6203
1m 24s (25000 25.0%) 2.9135
1m 41s (30000 30.0%) 2.5772
1m 58s (35000 35.0%) 2.4687
2m 14s (40000 40.0%) 2.5871
2m 31s (45000 45.0%) 2.1578
2m 48s (50000 50.0%) 2.1146
3m 6s (55000 55.00000000000001%) 2.2784
3m 22s (60000 60.0%) 1.7463
3m 39s (65000 65.0%) 2.5518
3m 56s (70000 70.0%) 1.3736
4m 13s (75000 75.0%) 2.3050
4m 29s (80000 80.0%) 2.4178
4m 46s (85000 85.0%) 2.3863
5m 3s (90000 90.0%) 3.1919
5m 20s (95000 95.0%) 2.6269
5m 37s (100000 100.0%) 2.3016
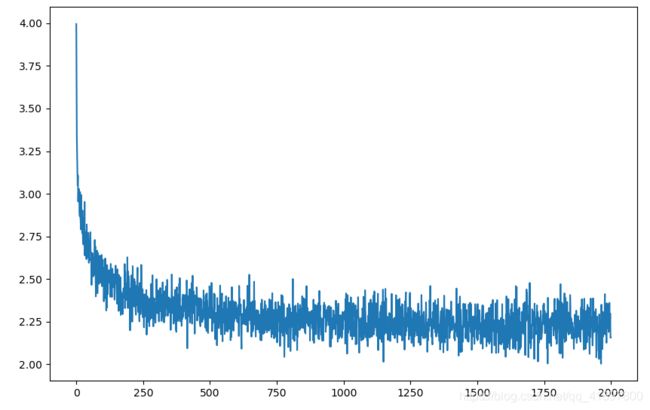
Loss变化如图所示:
5. 测试
print(sample('English','Y'))
print(sample('English', 'S'))
print(sample('English', 'C'))
Yande
Santeng
Chambennt
print(sample('Chinese','Y'))
print(sample('Chinese', 'S'))
print(sample('Chinese', 'C'))
Yue
Sha
Cha
print(sample('Korean','Y'))
print(sample('Korean', 'S'))
print(sample('Korean', 'C'))
You
Sho
Chun
print(sample('Russian','Y'))
print(sample('Russian', 'S'))
print(sample('Russian', 'C'))
Yanhov
Shimhon
Chinhinh
6. 全部代码
import unicodedata
import string
import glob
import os
all_letters = string.ascii_letters + " .,;'-" # abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'
n_letters = len(all_letters) + 1 # 59
category_lines = {
}
all_categories = []
def unicodeToAscii(s):
Ascii = []
for c in unicodedata.normalize('NFD', s):
if unicodedata.category(c) != 'Mn' and c in all_letters:
Ascii.append(c)
return ''.join(Ascii)
def findFiles(path):
return glob.glob(path)
def readLines(filename):
lines = open(filename, 'r', encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Net, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, category, input, hidden):
input_combined = torch.cat((category, input, hidden), 1)
hidden = self.i2h(input_combined)
output = self.i2o(input_combined)
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
import random
def randomChoice(l): # 从列表中随机选取一项
return l[random.randint(0, len(l) - 1)]
def randomTrainPair(): # 从类别中随机获得一个类别和随机的line
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
return category, line
def categortTensor(category): # 类别的one-hot vector
index = all_categories.index(category)
tensor = torch.zeros(1, n_categories)
tensor[0][index] = 1
return tensor
def inputTensor(line): # 输入的首字母到尾字母的one-hot矩阵(不包括EOS)
tensor = torch.zeros(len(line), 1, n_letters)
for i in range(len(line)):
letter = line[i]
tensor[i][0][all_letters.find(letter)] = 1
return tensor
def targetTensor(line): # 目标的第二个字母尾部(EOS)的LongTensor
letter_indexes = [all_letters.find(line[i]) for i in range(1, len(line))]
letter_indexes.append(n_letters - 1) # EOS
return torch.LongTensor(letter_indexes)
def randomTrainingExample(): # 随机提取(类别,行)对,并将其转换为所需的(类别,输入,目标)张量
category, line = randomTrainPair()
category_tensor = categortTensor(category)
input_line_tensor = inputTensor(line)
target_line_tensor = targetTensor(line)
return category_tensor, input_line_tensor, target_line_tensor
def train(category_tensor, input_line_tensor, target_line_tensor):
target_line_tensor.unsqueeze_(-1)
hidden = model.initHidden()
model.zero_grad()
loss = 0
for i in range(input_line_tensor.size()[0]):
output, hidden = model(category_tensor, input_line_tensor[i], hidden) # torch.Size([1, 18]) torch.Size([1, 59]) torch.Size([1, 128])
l = criterion(output, target_line_tensor[i])
loss += l
loss.backward()
for p in model.parameters():
p.data.add_(-learning_rate * p.grad.data)
return output, loss.item() / input_line_tensor.size()[0]
import time
import math
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def sample(category, start_letter='A'):
with torch.no_grad():
categort_tensor = categortTensor(category)
input = inputTensor(start_letter)
hidden = model.initHidden()
output_name = start_letter
for i in range(max_length):
output, hidden = model(categort_tensor, input[0], hidden)
topv, topi = output.data.topk(1)
topi = topi[0][0]
if topi == n_letters - 1:
break
else:
letter = all_letters[topi]
output_name += letter
input = inputTensor(letter)
return output_name
import matplotlib.pyplot as plt
path = '... your path\\data\\'
if __name__ == '__main__':
for filename in findFiles(path + 'names\\*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
model = Net(n_letters, 128, n_letters)
# 以下为训练
# criterion = nn.NLLLoss()
# learning_rate = 0.005
#
# n_iters = 100000
# print_every = 5000
# plot_every = 50
# all_losses = []
# total_loss = 0 # Reset every plot_every iters
#
# start = time.time()
#
# for iter in range(1, 1 + n_iters):
# output, loss = train(*randomTrainingExample())
# total_loss += loss
#
# if iter % print_every == 0:
# print('{} ({} {}%) {:.4f}'.format(timeSince(start), iter, iter / n_iters * 100, loss))
# if iter % plot_every == 0:
# all_losses.append(total_loss / plot_every)
# total_loss = 0
#
# torch.save(model.state_dict(), '... your path\\model_2.pth')
# plt.figure()
# plt.plot(all_losses)
# plt.show()
# 以下为测试
model.load_state_dict(torch.load('... your path\\model_2.pth'))
max_length = 20
print(sample('Russian', 'Y'))
print(sample('Russian', 'W'))
print(sample('Russian', 'L'))
总结
上篇姓氏分类RNN实战完成的是:
- 分类
- 每个单词的各个字母分别输入,最后取output
本篇完成的工作是:
- 预测与生成
- 多了一个类别的输入
- 每个单词的各个字母取output,与下一个字母计算损失