详解seq2seq模型中的attention机制,并利用LuongAttention搭建中英机器翻译!
先从我的理解概括Attention机制:在面对一句话时,人们一般不会整句都看完再去理解其意义(如果这个句子较长)。在seq2seq模型中,一整个句子当作输入会给网络带来困扰,并且很有可能丢失序列中靠前的信息。而在decoder模型的输入时,我们同样利用context替换原本的输入。context则是利用这句话学习得到的权重乘以这句话,得到一个新的context。将contex与这句话相拼接,输入网络中。这样做使得seq2seq的效果大大提升。因为输入不仅包含了原本的输入序列,还利用context让网络只注意这句话中的某几个单词,而不是整个句子。最关键的利用编码器(encoder)的信息得到contex替换掉原来的输入,让网络只关心某几个单词。下面开始详细介绍,部分图选自网络,如有侵权,请联系我。
先介绍encoer_decoder架构。seq2seq 就是一个Encoder–Decoder 结构的网络。它的输入是一个序列,通过GRU或者LSTM网络得到一个向量,即encoder_output。这个encoder_output实际上代表了输入序列的信息。输出也是一个序列,通过decoder网络(GRU或者LSTM网)将encoder_output作为输入,得到一个序列。
Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。--简书
模型框架:
假设一下这个输入序列是中文,输出序列是英文。
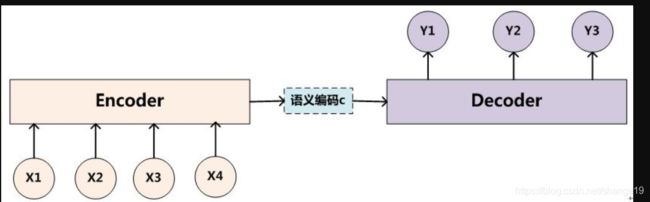
一般来说,这个是encoder网络采用GRU或者LSTM。以GRU举例,如果输入的维度是[seq_len, batch],那么就得到了[seq_len, batch, hidden_size]的encoder_output。pack_padded_sequence解释在这里:https://mp.csdn.net/postedit/102626466。
Encoder代码如下(采用pytorch):
import torch
import torch.nn as nn
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size, n_layer=1, drop_out=0):
# input_size是指单词数量,hidden_size为gru的hidden的feature
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embeddding = nn.Embedding(input_size, self.hidden_size)
self.gru = nn.GRU(self.hidden_size, self.hidden_size, bidirectional=True,
num_layers=n_layer, dropout=(0 if n_layer == 1 else drop_out))
def forward(self, input_seq, length, hidden=None):
# input_seq应该为[seq_len, batch]
# length为input_seq未补齐时的真实长度排序,最大的在前,list(int)
# embedd.shape = [seq_len, batch, hidden_size]
embedd = self.embeddding(input_seq)
pack = torch.nn.utils.rnn.pack_padded_sequence(embedd, length)
output, hidden = self.gru(pack, hidden)
output, _ = torch.nn.utils.rnn.pad_packed_sequence(output)
# encoder_output的shape=[max(length), batch, hidden_size]
# hidden_output的shape=[2, batch, hidden_size]
encoder_output = output[:, :, :self.hidden_size] + output[:, :, self.hidden_size:]
return encoder_output, hidden上面的都是最基本,接下来是重点。放出详细图:

看起来很复杂,emmmmm......... 确实比较复杂(这图谁看得懂)。LuongAttention是Luong在论文Effective Approaches to Attention-based Neural Machine Translation中提出的。我认为如果理解了这个attention机制,遍地开花的attention机制你能明白了。让我们来慢慢一步一步理解。
先放公式,不然说我不尊重作者了。
我们来计算context,即attention计算结果。Attention向量计算方法如下: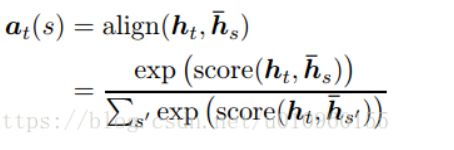
LuongAttention在多种对齐函数进行了实验,下图为LuongAttention设计的三种对齐函数: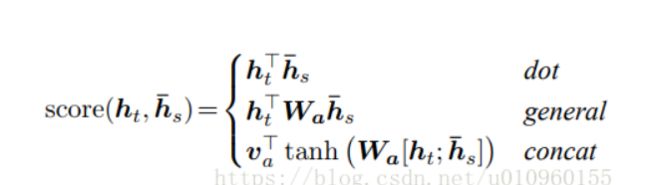
啥是对齐函数?看到这里估计更迷糊了。别急,先不看上面的图,开始解释:接着上面的网络,我们已经有了维度为
[seq_len, batch, hidden_size]的encoder_output,和[2, batch, hidden_size]的encoder_hidden(2是因为是双向单层的GRU)。我们需要得到什么?
需要得到一个权重系数与encoder_output相乘,为了计算context方便,encoder_output维度暂时转换[batch, seq_len, hidden_size]。可以看出,seq_len代表一个batch中的一个句子有几个单词。例如[0, 5, 100]即代表第0个句子中的五个单词。我们需要对这5个单词乘以不同的atten_weights。所以我们需要从encoder_output中得到一个这样的向量[batch, 5]。这个atten_weights代表了网络应该着重看重句子中的那几个单词,而不需要注意全部的单词。这就是注意力模型的精髓。现在回头看LuongAttention,我在这里只解释‘general’,另外两个本质上没有任何区别。
Decoder:
好了,现在我们需要得到atten_weights。大家可以结合开始的图看了,建议拿出纸笔,更好的理解。利用encoder_output和encoder_hidden。在decoder网络的一开始,我们将encoder_hidden传给GRU的decoder_hidden,而不是默认的随机初始化,并且利用sos标志传给GRU网络作为输入,得到了de_gru_output 和 de_gru_hidden。de_gru_output.shape为[seq_len, batch, hidden_size]。由于decoder网络的输入是一个单词接一个单词。所以seq_len=1。
现在所有计算atten_weigths的条件都有了。我们需要encoder_output(这个肯定不能少),还有de_gru_output(很多模型会把这里改成hidden之类的,无关紧要)。这个atten_weigths我们可以假设看作翻译结果的第一个英文单词,这个单词需要看中多少个中文单词。根据LuongAttention的‘general’模型,首先对encoder_output进行一层线性层,然后再将de_gru_output与结果相乘,得到的score求内积。事实上这个内积之后的score就是attn_weigths, 它的维度为[batch, max(length)]。代码如下,暂时只看general就行,其他两个模型得到的维度也是一样的:
class Attn(nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
self.hidden_size = hidden_size
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
if self.method == 'general':
self.attn = torch.nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = torch.nn.Linear(self.hidden_size * 2, hidden_size)
self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size))
def forward(self, decoder_output, encoder_output):
# 这里的output是指上次decoder的output
# encoder_output的shape=[max(length), batch, hidden_size]
# decoder_hidden的shape=[1, batch, hidden_size]
if self.method == 'general':
energy = self.general_score(decoder_output, encoder_output)
elif self.method == 'concat':
energy = self.concat_score(decoder_output, encoder_output)
elif self.method == 'dot':
energy = self.dot_score(decoder_output, encoder_output)
# energy.shape = [batch, max(length)]
energy = energy.t()
# attn_energy.shape = [batch, max(length)]
attn_energy = F.softmax(energy, dim=-1)
return attn_energy
def dot_score(self, decoder_output, encoder_output):
score = torch.sum(decoder_output * encoder_output, dim=2)
return score
def general_score(self, decoder_output, encoder_output):
attn_general = self.attn(encoder_output)
score = torch.sum(decoder_output * attn_general, dim=2)
return score
def concat_score(self, decoder_output, encoder_output):
attn_concat = self.attn(
torch.cat((decoder_output.expand(encoder_output.size(0), -1, -1), encoder_output), dim=2))
score = torch.sum(self.v * attn_concat, dim=2)
return score看到这里你就已经学完了attention机制的一大半了。这个forward返回的结果就是atten_weigths。我们将atten_weigths与encoder_output进行相乘得到context,一些编程小技巧在代码中会展示,我就不一一列举了。得到的context.shape =
[batch, 1, hidden_size]。然后变化维度与decoder的GRU得到的de_gru_output拼接,得到concat_input。然后再经过两层线性层与一层softmax,就得到了最终的输出。这就是LuongAttention机制。我认为所有的Attention机制都在于对atten_weigths的计算方式改进。就比如concat模式,将de_gru_output和encoder_output拼接起来以后经过一层激活函数为tanh的线性层,再与一个矩阵相乘(在我看来就是为了变换维度为了更好的计算)。可能利用hidden或者上一个状态的输出。还有更多的attention机制,但是一通百通,相信大家认真写一遍代码,就能完全理解了attention。
# 这个Attention模型得到context之后并不经过gru,lstm之类的,直接经过两层线性层
class LuongAttenDecoder(nn.Module):
def __init__(self, input_size, hidden_size, method, n_layer=1, drop_out=0.1):
super(LuongAttenDecoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# output_size = input_size,这两个都是代表总单词数量
self.output_size = input_size
self.n_layer = n_layer
self.embedding = nn.Embedding(self.input_size, self.hidden_size)
self.dropout_embedd = nn.Dropout(drop_out)
self.gru = nn.GRU(self.hidden_size, self.hidden_size, num_layers=n_layer, dropout=(0 if n_layer == 1 else drop_out))
self.concat = nn.Linear(self.hidden_size*2, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
self.attn_score = Attn(method, self.hidden_size)
def forward(self, input_seq, de_gru_hidden, encoder_output):
# input_seq.shape为[seq_len, batch]
# de_gru_hidden.shape为[seq_len, batch, hidden_size]
# encoder_output的shape=[max(length), batch, hidden_size]
# 由于decoder的输入,所以seq_len=1
# embedd.shape为[seq_len, batch, hidden_size]
embedd = self.embedding(input_seq)
embedd_dropout = self.dropout_embedd(embedd)
# de_gru_output.shape为[seq_len, batch, hidden_size]
de_gru_output, de_gru_hidden = self.gru(embedd_dropout, de_gru_hidden)
# attn_weigths.shape = [batch, max(length)]
attn_weigths = self.attn_score(de_gru_output, encoder_output)
# attn_weigths.shape = [batch, 1, max(length)]
attn_weigths = attn_weigths.unsqueeze(1)
# 将attn_weights与encoderoutput相乘,得到context
# context.shape = [batch, 1, hidden_size]
# 这里得到的shape应该跟embedd接近
context = torch.bmm(attn_weigths, encoder_output.transpose(0, 1))
de_gru_output = de_gru_output.squeeze(0)
context = context.squeeze(1)
concat_input = torch.cat((de_gru_output, context), dim=1)
concat_output = self.concat(concat_input)
# out.shape = [batch, output_size]
out = self.out(concat_output)
out = F.softmax(out, dim=1)
return out, de_gru_hidden
另外,基于上诉模型中英机器翻译代码及数据集(1000W条)链接如下。其中的model模型跟这个完全一致。如果还有什么问题,请在下面留言。谢谢大家的观看。