扩展卡尔曼滤波EKF用于多源传感器融合
1.Kalman Filters
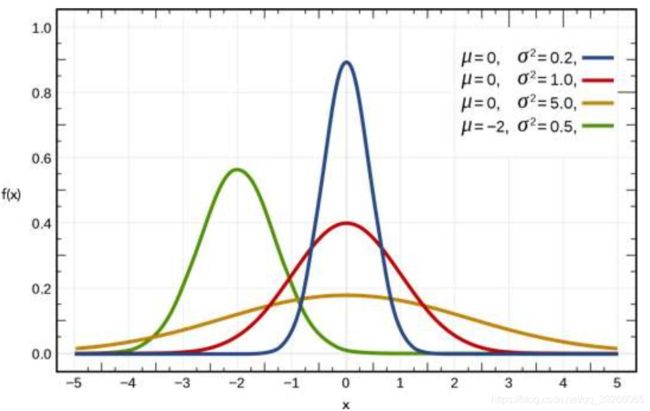
在跟踪一辆运行的车时,当 σ \sigma σ越小,表明确定因素越多。
测量值更新使用贝叶斯规则,而预测是全概率公式,也是一种加权平均,他们之间通过高斯实现。
假设我们已知先验告诉我们有辆车的位置分布如下黑色线所示,一个较宽的高斯分布,其均值为 μ \mu μ。而测量值信息告诉的车辆位置如蓝色线所示,其均值为 v v v,测量值拥有更小的协方差。相比较,该例子中测量值所给出的位置信息更多。

因此,利用先验和测量值信息,所得到的新的高斯分布如下,均指在两者之间,但相比较组成他的两个高斯分布来说更加确定!他的协方差更小!因为它获得了更多的信息。

Motion update即预测值,也就是简单的相加。因为在运动过程中丢失了确定信息,所以其不确定性更大, σ \sigma σ越大。

了解了一维中的卡尔曼滤波后,接下来扩展到二维:

可以通过 t = 0 , 1 , 2 t=0,1,2 t=0,1,2时刻得到车辆的速度,因此可以做出一个当 t = 3 t=3 t=3时很好的预测,此时的传感器并没有真正的得到速度信息,其只有位置信息,而速度是通过位置推断得到。
在卡尔曼滤波中,即使传感器没有直接的速度信息,也可以得到目标的速度,然后去预测将来的位置信息!
创建一个二维的估计,一个是位置还有一个则是速度,速度可以为负值。如果初始知道位置,但是并不知道速度,此时用一个高斯分布在正确的位置附近去表示速度,接下来去预测位置,假设速度为1,则 x = 2 x=2 x=2。因此如下红色部分则为预测的位置信息!
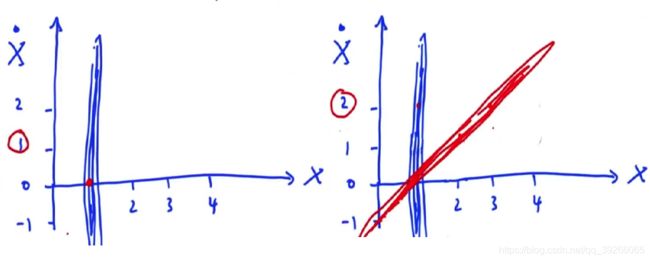
可以得到位置信息与速度之间的关系,而观测信息并不能告诉我们速度,而是关于位置的信息:

通过该测量信息可以估计速度,和当前的位置,此时便可以估计下一时刻的位置信息。
综上可以得到卡尔曼滤波:
p k = p k − 1 + Δ t v k − 1 {p_k} ={p_{k-1}} + \Delta t\color{royalblue} {v_{k-1}} pk=pk−1+Δtvk−1 v k = v k − 1 {v_k} = \color{royalblue}{v_{k-1}} vk=vk−1矩阵形式:
x ^ k = [ 1 Δ t 0 1 ] x ^ k − 1 = F k x ^ k − 1 \color{deeppink}{\mathbf{\hat{x}}_k} = \begin{bmatrix} 1 & \Delta t \\ 0 & 1 \end{bmatrix} \color{royalblue}{\mathbf{\hat{x}}_{k-1}} \\ = \mathbf{F}_k \color{royalblue}{\mathbf{\hat{x}}_{k-1}} x^k=[10Δt1]x^k−1=Fkx^k−1
参考资料:1.卡尔曼滤波简介 2.Sensor Fusion 课程
2. Lidar and Radar Fusion with Kalman Filters in C++
Lesson Map and Fusion Flow

扩展的卡尔曼滤波能够处理更加复杂的运动模型和测量模型,上图为一个整体的流程。有两个传感器:LIDAR和RADAR,由传感器提供信息用于估算状态,这个状态包含了2D位置和速度。
每次收到传感器的测量数据,估算函数将会被触发,分为两部分,状态预测(PREDICT)和测量值更新(Update)。在预测过程中,预测到行人的状态和协方差。测量值更新方式取决于传感器类型,这里有两种传感器,如果当前测量由LASER产生,仅仅使用标准的卡尔曼滤波去更新行人的状态。然而RADAR测量值涉及到非线性函数,因此需要使用其他的方法去处理,例如扩展的卡尔曼滤波。
Refresh Estimation Problem
卡尔曼滤波就是由简单无限循环预测和更新的步骤组成,然而当存在两个传感器的时候,每个传感器都有它自己的预测和更新的计划。换句话说,对于行人的位置和速度更新是异步的。

接下来通过一个例子去看看它是如何工作的。行人在时间 k k k的状态分布的均指为 X X X,协方差为 P P P,在 k + 1 k+1 k+1时刻,我们仅仅接收到了 l a s e r laser laser的测量数据,在测量值更新前第一件事需要去做一个预测,关于行人从 k k k时刻到 k + 1 k+1 k+1时刻的位置,第二件事是测量值更新,在这里我们结合行人的预测状态和新的 l a s e r laser laser测量值,现在我们更加相信行人在 t + 1 t+1 t+1时刻的位置。
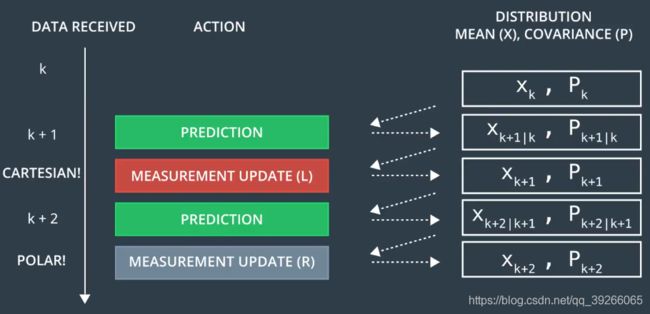
现在当收到 r a d a r radar radar在 t + 2 t+2 t+2时刻的测量值,首先我们再一次预测行人从 k + 1 k+1 k+1到 k + 2 k+2 k+2时刻的状态,此时 r a d a r radar radar是和 l a s e r laser laser完全一样的作用,所改变的是测量值更新步骤。 l a s e r laser laser提供的测量值是在笛卡尔坐标系下,而 r a d a r radar radar提供的测量值在极坐标系下,因此我们需要使用不同的测量值更新方法。
Kalman Filter Intuition
我们的任务是跟踪一个行人的状态 X X X,由位置 p p p和速度 v v v组成。
x = ( p v ) x=\begin{pmatrix} p \\ v\\ \end{pmatrix} x=(pv)
当设计一个卡尔曼滤波,需要去定义两个线性方程。
状态转换函数:表示状态从 k − 1 k-1 k−1到 k k k时刻是如何变化的。
x ′ = f ( x ) + v = F x + B u + v = F x + v , v ∽ N ( 0 , Q ) x'=f(x)+v=Fx+Bu+v=Fx+v,v\backsim N(0,Q) x′=f(x)+v=Fx+Bu+v=Fx+v,v∽N(0,Q)
测量函数:表示测量值是如何计算的,以及他和预测状态 X X X之间的关系。
z = h ( x ′ ) + w = H x + w z=h(x')+w=Hx+w z=h(x′)+w=Hx+w
其中 f ( x ) , F x , h ( x ′ ) f(x),Fx,h(x') f(x),Fx,h(x′)属于我们模型中确定的部分,而 v , w v,w v,w则代表随机部分,换句话说,随机噪声影响了预测和测量值更新步骤。因此通过使用一个匀速线性运动模型 p ′ = p + v Δ t p'=p+v\Delta t p′=p+vΔt,行人上一时刻的位置加上速度乘上时间。因为速度是匀速的,所以新的速度和上一时刻相同 v ′ = v v'=v v′=v。因此可以通过矩阵去描述:
( p ′ v ′ ) = ( 1 Δ t 0 1 ) ( p v ) \begin{pmatrix} p' \\ v'\\\end{pmatrix}=\begin{pmatrix} 1 & \Delta t \\ 0&1\\\end{pmatrix}\begin{pmatrix} p \\ v\\\end{pmatrix} (p′v′)=(10Δt1)(pv)
对于测量函数,我们的车辆仅仅感受到行人的位置 z = p ′ z=p' z=p′,因此它可以由如下矩阵表示:
z = ( 1 0 ) ( p ′ v ′ ) z=\begin{pmatrix} 1 & 0\\\end{pmatrix}\begin{pmatrix} p' \\ v'\\\end{pmatrix} z=(10)(p′v′)
正如我们所知道的,卡尔曼滤波算法由预测(预测我们的状态和协方差)和测量更新(矫正),在矫正部分使用最新的测量值去更新估计的状态和它的不确定性。

State Prediction
以上则完成了一维的卡尔曼滤波,接下来扩展到二维:

如上图所示,变成一个四维的状态向量: x = ( p x p y v x v y ) x=\begin{pmatrix} p_x \\ p_y \\ v_x \\v_y\\\end{pmatrix} x=⎝⎜⎜⎛pxpyvxvy⎠⎟⎟⎞同理,使用一个相同的匀速线性运动模型: { p x ′ = p x + v x Δ t + v p x p y ′ = p y + v y Δ t + v p y v x ′ = v x + v v x v y ′ = v y + v v y \begin{cases} p'_x=p_x+v_x\Delta t+v_{px} \\ p'_y=p_y+v_y\Delta t+v_{py} \\v'_x=v_x+v_{vx}\\v'_y=v_y+v_{vy}\end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧px′=px+vxΔt+vpxpy′=py+vyΔt+vpyvx′=vx+vvxvy′=vy+vvy因此可以得到如下的状态转换方程: ( p x ′ p y ′ v x ′ v y ′ ) = ( 1 0 Δ t 0 0 1 0 Δ t 0 0 1 0 0 0 0 1 ) ( p x p y v x v y ) + ( v p x v p y v v x v v y ) \begin{pmatrix} p'_x \\p'_y\\v'_x\\v'_y\\\end{pmatrix}=\begin{pmatrix} 1&0&\Delta t&0 \\ 0&1&0&\Delta t\\0&0&1&0\\0&0&0&1\end{pmatrix}\begin{pmatrix} p_x\\p_y \\ v_x\\v_y\\\end{pmatrix}+\begin{pmatrix} v_{px}\\v_{py}\\v_{vx}\\v_{vy}\\\end{pmatrix} ⎝⎜⎜⎛px′py′vx′vy′⎠⎟⎟⎞=⎝⎜⎜⎛10000100Δt0100Δt01⎠⎟⎟⎞⎝⎜⎜⎛pxpyvxvy⎠⎟⎟⎞+⎝⎜⎜⎛vpxvpyvvxvvy⎠⎟⎟⎞
除此之外,观测时间间隔也不再是常数,而是不断变化的!

上面的等式可以简化为 x ′ = F x + n o i s e x'=Fx+noise x′=Fx+noise
- 运动噪声和过程噪声指的是相同的情况:预测位置时对象位置的不确定性。 该模型假定速度在两个时间间隔之间是恒定的,但实际上我们知道物体的速度会由于加速度而发生变化。 该模型通过过程噪声包括了这种不确定性。
两次时间间隔越大不确定性也就越大,随机噪声会随着预测时间之间的间隙增加而增加。 - 测量噪声是指传感器测量中的不确定性。
Process Covariance Matrix
首先如何用运动学方程去表达加速度,然后使用该信息去推导协方差矩阵 Q , μ ∽ N ( 0 , Q ) Q,\mu\backsim N(0,Q) Q,μ∽N(0,Q)。我们拥有同一个行人初始和最终的速度,从运动学方程中可以根据上一时刻的状态变量推导出当前的位置和速度,包括速度的变化(加速度)。
a = Δ v Δ t = v k + 1 − v k Δ t a={\Delta v \over \Delta t}={v_{k+1}-v_k \over \Delta t} a=ΔtΔv=Δtvk+1−vk
因为速度并不是匀速的,并且加速度是不知道的,因此可以将它添加到噪声 μ \mu μ的部分。
{ p x ′ = p x + v x Δ t + μ p x p y ′ = p y + v y Δ t + μ p y v x ′ = v x + μ v x v y ′ = v y + μ v y ⟹ { p x ′ = p x + v x Δ t + a x Δ t 2 2 p y ′ = p y + v y Δ t + a y Δ t 2 2 v x ′ = v x + a x Δ t v y ′ = v y + a y Δ t \begin{cases} p'_x=p_x+v_x\Delta t+\mu_{px} \\ p'_y=p_y+v_y\Delta t+\mu_{py} \\v'_x=v_x+\mu_{vx}\\v'_y=v_y+\mu_{vy}\end{cases} \Longrightarrow \begin{cases} p'_x=p_x+v_x\Delta t+{a_x\Delta t^2 \over 2}\\ p'_y=p_y+v_y\Delta t+{a_y\Delta t^2 \over 2}\\v'_x=v_x+a_x\Delta t\\v'_y=v_y+a_y\Delta t\end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧px′=px+vxΔt+μpxpy′=py+vyΔt+μpyvx′=vx+μvxvy′=vy+μvy⟹⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧px′=px+vxΔt+2axΔt2py′=py+vyΔt+2ayΔt2vx′=vx+axΔtvy′=vy+ayΔt
噪声 μ \mu μ可以分为两部分:
μ = { a x Δ t 2 2 a y Δ t 2 2 a x Δ t a y Δ t = ( Δ t 2 2 0 0 Δ t 2 2 Δ t 0 0 Δ t ) ( a x a y ) = G a \mu=\begin{cases}{a_x\Delta t^2 \over 2}\\{a_y\Delta t^2 \over 2}\\a_x\Delta t\\a_y\Delta t\end{cases}= \begin{pmatrix} {\Delta t^2 \over 2} & 0\\ 0&{\Delta t^2 \over 2} \\ \Delta t&0 \\0&\Delta t\\\end{pmatrix}\begin{pmatrix} a_x \\ a_y\\\end{pmatrix}=Ga μ=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧2axΔt22ayΔt2axΔtayΔt=⎝⎜⎜⎛2Δt20Δt002Δt20Δt⎠⎟⎟⎞(axay)=Ga G G G是一个 4 ∗ 2 4*2 4∗2的不包括随机变量的矩阵,而 a a a是一个 2 ∗ 1 2*1 2∗1的包含随机加速度的部分。在我们噪声向量的基础上,可以定义一个新的协方差矩阵Q,该协方差矩阵由噪声向量的期望值定义。
Q = E [ μ μ T ] = E [ G a a T G T ] Q=E[\mu\mu^T]=E[Gaa^TG^T] Q=E[μμT]=E[GaaTGT] Q = G E [ a a T ] G T = G ( σ a x 2 σ a x y σ a x y σ a y 2 ) G T = G Q v G T Q=GE[aa^T]G^T=G\begin{pmatrix} \sigma^2_{ax} & \sigma_{axy} \\ \sigma_{axy} & \sigma^2_{ay}\\\end{pmatrix}G^T=GQ_vG^T Q=GE[aaT]GT=G(σax2σaxyσaxyσay2)GT=GQvGT因为G是不含有随机变量的,因此可以将其移到期望值计算的外边,我们假设 a x ax ax和 a y ay ay是互不相关的噪声,因此 σ a x y = 0 \sigma_{axy}=0 σaxy=0,最终所得到的协方差矩阵Q为:
Q = G Q v G T = ( Δ t 4 4 σ a x 2 0 Δ t 3 2 σ a x 0 0 Δ t 4 4 σ a y 0 Δ t 3 2 σ a y 2 Δ t 3 2 σ a x 2 0 Δ t 2 σ a x 2 0 0 Δ t 3 2 σ a y 2 0 Δ t 2 σ a y 2 ) Q=GQ_vG^T=\begin{pmatrix} {\Delta t^4 \over 4}\sigma^2_{ax} &0& {\Delta t^3 \over 2} \sigma_{ax}&0 \\ 0& {\Delta t^4 \over 4}\sigma_{ay} & 0& {\Delta t^3 \over 2} \sigma^2_{ay}\\ {\Delta t^3 \over 2} \sigma^2_{ax}&0&\Delta t^2 \sigma^2_{ax}&0\\0& {\Delta t^3 \over 2} \sigma^2_{ay}&0&\Delta t^2 \sigma^2_{a_y}\\\end{pmatrix} Q=GQvGT=⎝⎜⎜⎜⎛4Δt4σax202Δt3σax2004Δt4σay02Δt3σay22Δt3σax0Δt2σax2002Δt3σay20Δt2σay2⎠⎟⎟⎟⎞
Laser Measurements
以上,我们已经定义了运动模型,接下来定义2D激光传感器的测量模型,测量值向量 z z z,测量矩阵 H H H,协方差矩阵 R R R。虽然激光雷达给出的点云数据,但可以通过目标检测得到目标的位置 ( p x , p y ) (p_x,p_y) (px,py)。
z = ( p x p y ) = ( 1 0 0 0 0 1 0 0 ) ( p x ′ p y ′ v x ′ v y ′ ) z=\begin{pmatrix} p_x \\ p_y \\\end{pmatrix}=\begin{pmatrix} 1&0&0&0 \\ 0&1&0&0\\\end{pmatrix}\begin{pmatrix} p'_x \\ p'_y \\ v'_x \\v'_y\\\end{pmatrix} z=(pxpy)=(10010000)⎝⎜⎜⎛px′py′vx′vy′⎠⎟⎟⎞对于激光传感器,我们有一个2D测量向量。 每个位置分量 ( p x , p y ) (p_x,p_y) (px,py)都受到随机噪声的影响,因此我们的噪声向量 w w w由着和 z z z一样的维度,因此得到测量值噪声的协方差矩阵 R R R为:
R = E [ w w t ] = ( σ p x 2 0 0 σ p y 2 ) R=E[ww^t]=\begin{pmatrix} \sigma^2_{px}&0 \\0&\sigma^2_{py} \\\end{pmatrix} R=E[wwt]=(σpx200σpy2)矩阵R代表我们从激光传感器接收到的位置测量结果中的不确定性。通常,随机噪声测量矩阵的参数将由传感器制造商提供。
Radar Measurements
接下来我们将结合 r a d a r radar radar测量值到卡尔曼滤波中,即使 l a s e r laser laser已经提供了高精度的行人位置,但是仍然没有一个办法可以直接观察到他的速度,这便是 r a d a r radar radar可以使用多普勒效应做的事情。 r a d a r radar radar可以直接测量移动物体的径向速度,但是相比 l a s e r laser laser传感器, r a d a r radar radar有较低的空间分辨率。

在 r a d a r radar radar中,状态量和运动方程同 l a s e r laser laser中一样,但是其坐标系不同, x x x轴代表车辆的运动方向, y y y轴则是运动方向的左侧。
RANGE: ρ \rho ρ代表从雷达原点到行人之间的距离;
BEARING: φ \varphi φ代表这条射线与 x x x轴即运动方向的角度;
RADIAL VELOCITY: ρ ˙ \dot{\rho} ρ˙代表在该条射线方向下的速度。
因为其三者是互不相关的,因此其测量值的协方差矩阵为 3 ∗ 3 3*3 3∗3的对角矩阵。
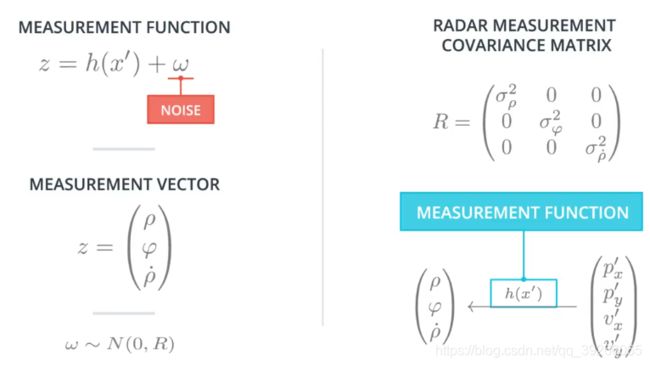
来自激光雷达 H H H矩阵和来自雷达的 h ( x ) h(x) h(x)方程实际上是在完成相同的工作; 在更新步骤中它们都需要解决 y = z − H x ′ y = z-Hx' y=z−Hx′。但是对于雷达来说,没有将状态向量 x x x映射到极坐标的 H H H矩阵,因此需要手动计算映射以将笛卡尔坐标转换为极坐标。
这是 h h h函数,它指定如何将预测的位置和速度映射到 ρ , φ , ρ ˙ \rho,\varphi,\dot{\rho} ρ,φ,ρ˙的极坐标。

此处 h h h为一个非线性函数,不再适合卡尔曼滤波!
Extended Kalman Filter
如果我们将此高斯映射到非线性函数,其结果不再是一个高斯分布。因此需要线性化 h ( x ) h(x) h(x)函数,这种关键的思想被叫做扩展卡尔曼滤波。
因此我们必须近似测量值函数 h h h通过一个线性函数,该线性函数是原始高斯均值位置的切线!此时所得到结果便符合高斯分布。

因此如何线性化一个非线性函数?扩展的卡尔曼滤波使用的方法叫做一阶泰勒展开式。
h ( x ) ≈ h ( μ ) + ∂ h ( μ ) ∂ x ( x − μ ) h(x)\approx h(\mu)+{∂h(\mu)\over ∂x}(x-\mu) h(x)≈h(μ)+∂x∂h(μ)(x−μ)
线性化 h ( x ) h(x) h(x)函数的雅可比矩阵如下:

EKF Algortihm Generalization

我们将 u u u设为0。高斯分布的不确定性出现在 Q Q Q矩阵中。对于一个非线性函数,需要计算其雅可比矩阵 F j , H j F_j,H_j Fj,Hj将其线性化。
对于扩展的卡尔曼滤波,首先是线性化非线性的预测和测量值函数,然后使用同样的原理去估计状态值。